|
Serwis Edukacyjny Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
Podany w poprzednim rozdziale algorytm sortowania kubełkowego jest bardzo uproszczony i pozwala sortować tylko liczby całkowite. Teraz opiszemy pełny algorytm sortowania kubełkowego pozbawiony tych ograniczeń. Najpierw kilka założeń i definicji:
Sortujemy zbiór d[ ] liczb rzeczywistych. Niech wmin oznacza dolny kres wartości elementów d[ ], a wmax niech oznacza kres górny. Wartości te tworzą przedział liczbowy <wmin, wmax>, w który wpadają wszystkie elementy zbioru. Przedział dzielimy na m segmentów, które nazwiemy kubełkami. W tym celu obliczamy szerokość kubełka:

Poszczególne kubełki to:
| dla i = 0,1,...,m: [wmin + i • szkb , wmin + (i +1) • szkb] |
czyli
| K[0] : | <wmin , wmin + szkb) |
| K[1] : | <wmin + szk , wmin + 2 • szkb) |
| ... | |
| K[m - 1] : | <wmin + (m - 1) • szkb, wmax) |
| K[m] : | <wmax , wmax + szkb) |
Ponieważ poszczególne kubełki tworzą przedziały prawostronnie otwarte, potrzebujemy ostatniego kubełka K[m] dla wartości maksymalnej wmax, którą mogą osiągać elementy w sortowanym zbiorze. Wynika stąd, iż kubełków będzie m + 1 ponumerowanych kolejno od 0 do m.
Liczba d[j] należy do i-tego kubełka, jeśli spełniona jest nierówność:
| wmin + i •
szkb
|
A stąd otrzymujemy wzór na numer kubełka:
 |
Po wyznaczeniu przedziału kubełków, zerujemy kubełki (tzn. tworzymy w nich puste listy elementów). Następnie przeglądamy kolejno wszystkie elementy zbioru, wyznaczamy dla nich odpowiednie kubełki i wstawiamy te elementy to kubełków. Operację wstawiania do kubełka wykonujemy, tak aby wewnątrz kubełka elementy tworzyły listę posortowaną. Jeśli kubełków będzie odpowiednio dużo, to zawierać będą niewiele elementów, zatem operacja tworzenia listy uporządkowanej nie zajmie dużo czasu.
Po wykonaniu przebiegu dystrybucyjnego w poszczególnych kubełkach będziemy posiadali uporządkowane listy elementów. Wykonujemy przebieg zbierający - przeglądamy poszczególne kubełki pobierając z list przechowywane w nich elementy i umieszczając je w zbiorze wynikowym. W efekcie otrzymamy zbiór posortowany.
Przykład:
Dla zobrazowania zasady sortowania kubełkowego posortujemy tą metodą poniższy zbiór liczb:
| { 23/4 11/4 4/5 41/2 14/5 1/2 } |
Określamy zakres wartości elementów zbioru:
| wmin = 1/2 wmax = 41/2 |
Ustalamy liczbę kubełków m = 4.
Wyliczamy szerokość kubełka:
 |
Wyznaczamy zakresy kolejnych kubełków:
| K[0] : <1/2, 11/2) K[1] : <11/2, 21/2) K[2] : <21/2, 31/2) K[3] : <31/2, 41/2) K[4] : <41/2, 51/2) |
Poszczególne elementy zbioru umieszczamy w kubełkach, których numery wyznaczamy ze wzoru:
 |
| 23/4 : i = [ | 23/4 - 1/2 | ] = [21/4] = 2 |
| 1 | ||
| 11/4 : i = [ | 11/4 - 1/2 | ] = [3/4] = 0 |
| 1 | ||
| 4/5 : i = [ | 4/5 - 1/2 | ] = [3/10] = 0 |
| 1 | ||
| 41/2 : i = [ | 41/2 - 1/2 | ] = [4] = 4 |
| 1 | ||
| 14/5 : i = [ | 14/5 - 1/2 | ] = [13/10] = 1 |
| 1 | ||
| 1/2 : i = [ | 1/2 - 1/2 | ] = [0] = 0 |
| 1 |
Kubełki mają następującą zawartość:
| K[0] : | [ 1/2, 11/2) | : | 1/2 | , 4/5 | , 11/4 |
| K[1] : | [11/2, 21/2) | : | 14/5 | ||
| K[2] : | [21/2, 31/2) | : | 23/4 | ||
| K[3] : | [31/2, 41/2) | : | |||
| K[4] : | [41/2, 51/2) | : | 41/2 |
Pobieramy elementy z kolejnych kubełków i umieszczamy je w zbiorze wynikowym. Zbiór jest posortowany.
| { 1/2 4/5 11/4 14/5 23/4 41/2 } |
Elementy umieszczane w kolejnych kubełkach muszą być posortowane rosnąco. Do sortowania wykorzystamy naturalny w tym przypadku algorytm sortowania przez wstawianie. Dla listy przyjmuje on następującą postać:
| L[ ] | - tablica elementów, z których zbudowana jest lista. Każdy element posiada pole następnik oraz pole dane. |
| K[ ] | - tablica nagłówków list. Elementy K[ ] są liczbami całkowitymi. |
| ine | - indeks nowego elementu w tablicy L[ ], który będzie dodany do listy kubełka, ine ∈ N |
| ikb | - indeks kubełka w tablicy K[ ], do listy którego dodajemy element, ikb ∈ N |
| we | - wartość dodawanego elementu, we ∈ R |
Na liście kubełka K[ikb] zostaje umieszczony nowy element o wartości pola dane równej we. Lista jest posortowana rosnąco
| ip | - indeks poprzedniego elementu na liście, ip ∈ C |
| ib | - indeks bieżącego elementu na liście, ib ∈ C |
| K01: | L[ine].następnik ← 0; L[ine].dane ← we | Inicjujemy nowy element listy |
| K02: | ip ← 0; ib ← K[ikb] | Inicjujemy wskaźniki poprzedniego elementu oraz bieżącego |
| K03: | Dopóki (ib > 0) ∧ (L[ib].dane
< we) wykonuj: ip ← ib ib ← L[ib].następnik |
Szukamy miejsca wstawienia nowego elementu na liście skojarzonej z kubełkiem |
| K04: | Jeśli ip = 0, to: L[ine].następnik ← ib; K[ikb] ← ine idź do kroku K07 |
Jeśli wskaźnik poprzedniego elementu listy jest równy 0, to pętla z kroku 3 nie wykonała ani jednego obiegu. Dzieje się tak w dwóch przypadkach:
wstawić na początek listy. Po tej operacji przechodzimy na koniec algorytmu do kroku 7 |
| K05: | Jeśli ib = 0, to: L[ip].następnik ← ine Idź do kroku K07 |
Jeśli wskaźnik bieżącego elementu jest równy 0, to nowy element należy wstawić na koniec listy - za elementem wskazywanym przez wskaźnik ip. Po tej operacji przechodzimy do kroku 7 |
| K06: | L[ip].następnik ←
ine L[ine].następnik ← ib |
Jeśli nie wystąpiły dwie poprzednie sytuacje, to pozostaje jedynie wstawienie nowego elementu pomiędzy elementy wskazywane przez ip oraz ib. |
| K07: | ine ← ine + 1 Zakończ |
Zwiększamy wskaźnik wolnej pozycji w tablicy elementów list L[ ] i kończymy algorytm. |
| n | - liczba elementów do posortowania; n ∈ N |
| d[ ] | - tablica n-elementowa z elementami rzeczywistymi do posortowania. Indeks pierwszego elementu wynosi 1. |
| wmin | - najmniejszy element w tablicy d[ ]; wmin ∈ R |
| wmax | - największy element w tablicy d[ ]; wmax ∈ R |
| d[ ] | - tablica z posortowanymi rosnąco elementami |
| L[ ] | - | n-elementowa tablica elementów list. Każdy element posiada całkowite pole następnik oraz rzeczywiste pole dane. Indeksy elementów rozpoczynają się od wartości 1. |
| K[ ] | - | tablica (n + 1) elementowa zawierająca nagłówki list kubełków. Każdy element jest liczbą całkowitą. Indeksy elementów rozpoczynają się od wartości 0. |
| szkb | - | szerokość przedziału objętego przez kubełek, szkb ∈ R |
| ikb | - | wyznaczony dla danego elementu numer kubełka, ikb ∈ C |
| ine | - | indeks wolnej pozycji w tablicy L[ ]; ine ∈ N |
| i,j | - | zmienne licznikowe pętli; i,j Î C |
| we | - | wartość sortowanego elementu; we ∈ R |
| K01: | Dla i = 0,1,...,n: wykonuj: K[i] ← 0 |
| K02: |
 |
| K03: | ine ← 1 |
| K04: | Dla i = 1,2,...,n: wykonuj kroki K05...K07 |
| K05: | we ← d[i] |
| K06: |
 |
| K07: | Wstaw wartość we na listę kubełka K[ikb] |
| K08: | j ← 1 |
| K09: | Dla ikb = 0,1,...,n: wykonuj kroki K10...K13 |
| K10: | i ← K[ikb] |
| K11: | Dopóki i > 0: wykonuj kroki K12...K14 |
| K12: | d[j] ← L[i].dane |
| K13: | j ← j + 1 |
| K14: | i ← L[i].następnik |
| K15: | Zakończ |
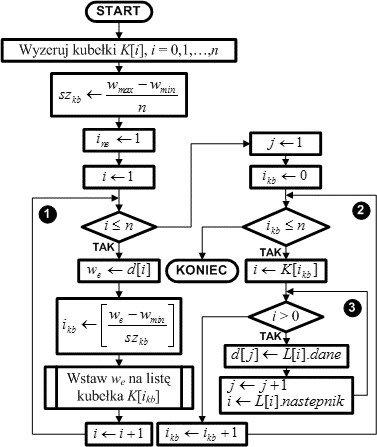
Pierwszą operacją algorytmu jest wyzerowanie nagłówków list K[ ]. Następnie obliczamy szerokość przedziału kubełka i zapamiętujemy ją w zmiennej szkb.
Elementy list będziemy tworzyli kolejno w tablicy L[ ]. Ustawiamy zmienną ine na pierwszy element tej tablicy. Zmienna ta pełni rolę wskaźnika wolnego elementu w puli L[ ].
Rozpoczynamy pętlę nr 1, której zadaniem jest umieszczenie wszystkich elementów zbioru d[ ] w listach kubełków K[ ]. Element i-ty z d[ ] zapamiętujemy w zmiennej roboczej we (aby zmniejszyć ilość odwołań do tablicy d[ ]). Obliczamy numer kubełka ikb, do którego trafi pobrany element we. Następnie wartość we wstawiamy na listę K[ikb] za pomocą procedury wstawiania elementu na listę uporządkowaną. Pętla nr 1 jest kontynuowana dotąd, aż wszystkie elementy zbioru d[ ] znajdą się na odpowiednich listach kubełków K[ ]. Operacja dystrybucji (rozrzucenia) elementów zostaje zakończona.
Druga faza algorytmu ma za zadanie pozbierać elementy z poszczególnych list uporządkowanych zawartych w kubełkach K[ ].
Zmienna j pełni rolę indeksu wstawianych do d[ ] elementów. Dlatego przyjmuje wartość 1 - początek tablicy d[ ].
Pętla nr 2 wyznacza kolejne kubełki K[ ].
Pętla wewnętrzna nr 3 przegląda elementy listy danego kubełka i zapisuje je do zbioru d[ ].
Po zakończeniu pętli nr 2 w zbiorze d[ ] mamy posortowane elementy. Algorytm jest zakończony.
C++// Sortowanie kubełkowe 2
//-----------------------
// (C)2012 mgr Jerzy Wałaszek
// I Liceum Ogólnokształcące
// w Tarnowie
#include <iostream>
#include <iomanip>
#include <cstdlib>
#include <time.h>
using namespace std;
const int N = 40;
const double WMIN = -1000.0;
const double WMAX = 1000.0;
int main()
{
struct
{
unsigned nastepnik;
double dane;
} L[N + 1];
double d[N],we,szkb;
int K[N + 1],ikb,ine,ip,ib,i,j;
// 2 cyfry po przecinku
cout.precision(2);
// format stałoprzecinkowy
cout.setf(ios::fixed);
cout << " Sortowanie Kubelkowe II \n"
"------------------------------\n"
" (C)2005 mgr Jerzy Walaszek \n\n"
"Przed sortowaniem:\n\n";
// Generujemy zawartość tablicy d[]
// i wyświetlamy ją
srand((unsigned)time(NULL));
for(i = 0; i < N; i++)
{
d[i] = WMIN +
(double)rand() /
(double)(RAND_MAX+1) *
(WMAX - WMIN);
cout << setw(8) << d[i];
}
cout << endl << endl;
// Zerujemy kubełki
for(i = 0; i <= N; i++)
K[i] = 0;
// Obliczamy szerokość kubełka
szkb = (WMAX - WMIN) / N;
ine = 1;
// Rozrzucamy poszczególne
// elementy d[i] na listach K[]
for(i = 0; i < N; i++)
{
we = d[i];
ikb = (int)((we - WMIN) / szkb);
L[ine].nastepnik = 0;
L[ine].dane = we;
ip = 0; ib = K[ikb];
while((ib > 0) && (L[ib].dane < we))
{
ip = ib;
ib = L[ib].nastepnik;
}
if(!ip)
{
L[ine].nastepnik = ib;
K[ikb] = ine;
}
else if(!ib) L[ip].nastepnik = ine;
else
{
L[ip].nastepnik = ine;
L[ine].nastepnik = ib;
}
ine++;
}
// wybieramy dane z kubełków
// i umieszczamy je w d[]
j = 0;
for(ikb = 0; ikb <= N; ikb++)
{
i = K[ikb];
while(i)
{
d[j++] = L[i].dane;
i = L[i].nastepnik;
}
}
// Koniec. Wyświetlamy wyniki
cout << "Po sortowaniu:\n\n";
for(i = 0; i < N; i++)
cout << setw(8) << d[i];
cout << endl << endl;
system("pause");
return 0;
}
|
Pascal// Sortowanie kubełkowe 2
//-----------------------
// (C)2012 mgr Jerzy Wałaszek
// I Liceum Ogólnokształcące
// w Tarnowie
const
N = 40;
WMIN = -1000.0;
WMAX = 1000.0;
// Tutaj definiujemy typ elementów listy
type
TElement = record
nastepnik : cardinal;
dane : real;
end;
// Tutaj deklarujemy zmienne
var
d : array[1..N] of real;
L : array[1..N] of TElement;
K : array[0..N] of integer;
we,szkb : real;
ikb,ine,ip,ib,i,j : integer;
begin
writeln(' Sortowanie Kubelkowe II ');
writeln('--------------------------');
writeln('(C)2005 mgr Jerzy Walaszek');
writeln;
// Generujemy zawartość tablicy d[]
// i wyświetlamy ją
randomize;
writeln('Przed sortowaniem:');
writeln;
for i := 1 to N do
begin
d[i] := WMIN +
random() * (WMAX - WMIN);
write(d[i]:8:2);
end;
writeln;
writeln;
// Zerujemy kubełki
for i := 0 to N do
K[i] := 0;
// Obliczamy szerokość kubełka
szkb := (WMAX - WMIN) / N;
ine := 1;
// Rozrzucamy poszczególne
// elementy d[i] na listach K[]
for i := 1 to N do
begin
we := d[i];
ikb := round((we - WMIN) / szkb);
L[ine].nastepnik := 0;
L[ine].dane := we;
ip := 0; ib := K[ikb];
while (ib > 0) and
(L[ib].dane < we) do
begin
ip := ib;
ib := L[ib].nastepnik;
end;
if ip = 0 then
begin
L[ine].nastepnik := ib;
K[ikb] := ine
end
else if ib = 0 then
L[ip].nastepnik := ine
else
begin
L[ip].nastepnik := ine;
L[ine].nastepnik := ib;
end;
inc(ine);
end;
// wybieramy dane z kubełków
// i umieszczamy je w d[]
j := 1;
for ikb := 0 to N do
begin
i := K[ikb];
while i > 0 do
begin
d[j] := L[i].dane;
inc(j); i := L[i].nastepnik;
end;
end;
// Koniec. Wyświetlamy wyniki
writeln('Po sortowaniu:');
writeln;
for i := 1 to N do
write(d[i]:8:2);
writeln;
writeln;
writeln('Nacisnij Enter...');
readln;
end.
|
Basic' Sortowanie kubełkowe 2
'-----------------------
' (C)2012 mgr Jerzy Wałaszek
' I Liceum Ogólnokształcące
' w Tarnowie
CONST N = 40
CONST WMIN = -1000
CONST WMAX = 1000
' Tutaj definiujemy typ elementów listy
TYPE TElement
nastepnik AS UINTEGER
dane AS DOUBLE
END TYPE
' Tutaj deklarujemy zmienne
DIM AS DOUBLE d(N),we,szkb
DIM AS TElement L(N)
DIM AS INTEGER K(0 TO N),ikb,ine,ip,ib,i,j
PRINT " Sortowanie Kubelkowe II "
PRINT "------------------------------"
PRINT " (C)2005 mgr Jerzy Walaszek "
PRINT
' Generujemy zawartość
' tablicy d[] i wyświetlamy ją
RANDOMIZE
PRINT "Przed sortowaniem:"
PRINT
FOR i = 1 TO N
d(i) = WMIN + RND(1) * (WMAX - WMIN)
PRINT USING "#####.##"; d(i);
NEXT
PRINT
PRINT
' Zerujemy kubełki
FOR i = 0 TO N
K(i) = 0
NEXT
' Obliczamy szerokość kubełka
szkb = (WMAX - WMIN) / N
ine = 1
' Rozrzucamy poszczególne
' elementy d[i] na listach K[]
FOR i = 1 TO N
we = d(i)
ikb = INT((we - WMIN) / szkb)
L(ine).nastepnik = 0
L(ine).dane = we
ip = 0: ib = K(ikb)
WHILE (ib > 0) AND (L(ib).dane < we)
ip = ib
ib = L(ib).nastepnik
WEND
IF ip = 0 THEN
L(ine).nastepnik = ib
K(ikb) = ine
ELSEIF ib = 0 THEN
L(ip).nastepnik = ine
ELSE
L(ip).nastepnik = ine
L(ine).nastepnik = ib
END IF
ine += 1
NEXT
' wybieramy dane z kubełków
' i umieszczamy je w d[]
j = 1
FOR ikb = 0 TO N
i = K(ikb)
WHILE i > 0
d(j) = L(i).dane
j += 1
i = L(i).nastepnik
WEND
NEXT
' Koniec. Wyświetlamy wyniki
PRINT "Po sortowaniu:"
PRINT
FOR i = 1 TO N
PRINT USING "#####.##"; d(i);
NEXT
PRINT
PRINT
PRINT "Nacisnij dowolny klawisz..."
SLEEP
END
|
Python
(dodatek)# Sortowanie kubełkowe 2
#-----------------------
# (C)2012 mgr Jerzy Wałaszek
# I Liceum Ogólnokształcące
# w Tarnowie
import random
n = 40
wmin = -999.0
wmax = 999.0
class List:
def __init__(self):
self.nastepnik = 0
self.dane = 0.0
l = [List() for _ in range(n + 1)]
d = [0.0] * n
k = [0] * (n + 1)
print(" Sortowanie Kubełkowe II")
print("--------------------------")
print("(C)2026 mgr Jerzy Wałaszek")
print()
print("Przed sortowaniem:")
print()
# Generujemy zawartość tablicy d[]
# i wyświetlamy ją
for i in range(n):
d[i] = random.uniform(wmin,wmax)
print("%8.2f" % d[i], end="")
print()
print()
# Obliczamy szerokość kubełka
szkb = (wmax - wmin) / n
ine = 1
# Rozrzucamy poszczególne
# elementy d[i] na listach K[]
for i in range(n):
we = d[i]
ikb = int((we - wmin) / szkb)
l[ine].nastepnik = 0
l[ine].dane = we
ip = 0
ib = k[ikb]
while ib and l[ib].dane < we:
ip = ib
ib = l[ib].nastepnik
if not ip:
l[ine].nastepnik = ib
k[ikb] = ine
elif not ib:
l[ip].nastepnik = ine
else:
l[ip].nastepnik = ine
l[ine].nastepnik = ib
ine += 1
# wybieramy dane z kubełków
# i umieszczamy je w d[]
j = 0
for ikb in range(n + 1):
i = k[ikb]
while i:
d[j] = l[i].dane
j += 1
i = l[i].nastepnik
# Koniec. Wyświetlamy wyniki
print("Po sortowaniu:")
print()
for i in range(n):
print("%8.2f" % d[i], end="")
print()
print()
input("Naciśnij Enter...")
|
| Wynik: |
Sortowanie Kubełkowe II
--------------------------
(C)2026 mgr Jerzy Wałaszek
Przed sortowaniem:
102.41 -165.06 507.17 -9.04 -42.09 167.02 -564.50 -673.01 321.34 -641.40
-303.40 337.81 -918.70 -235.13 294.05 203.94 -846.23 60.33 206.31 -698.58
571.51 -744.34 -213.95 256.22 380.58 474.06 -205.19 -806.32 655.63 -358.31
-719.41 2.28 854.49 -548.88 505.31 566.92 163.62 -639.59 -706.80 866.58
Po sortowaniu:
-918.70 -846.23 -806.32 -744.34 -719.41 -706.80 -698.58 -673.01 -641.40 -639.59
-564.50 -548.88 -358.31 -303.40 -235.13 -213.95 -205.19 -165.06 -42.09 -9.04
2.28 60.33 102.41 163.62 167.02 203.94 206.31 256.22 294.05 321.34
337.81 380.58 474.06 505.31 507.17 566.92 571.51 655.63 854.49 866.58
Naciśnij Enter...
|
JavaScript<html>
<head>
</head>
<body>
<div style="overflow-x: auto;"
align="center">
<table
border="0"
cellpadding="4"
style="border-collapse:
collapse">
<tr>
<td nowrap>
<form
name="frm"
style="text-align:
center;
background-color:
#E7E7DA">
<b>
Sortowanie
Kubełkowe II
</b><br/>
(C)2026 mgr
Jerzy Wałaszek
<hr/>
<input
onclick="main()"
value="Sortuj"
name="B1"
type="button">
<hr/>
<div id="out">.</div>
</form>
</td>
</tr>
</table>
</div>
<script language="javascript">
// Sortowanie kubełkowe II
//------------------------
// (C)2005 mgr Jerzy Wałaszek
// I Liceum Ogólnokształcące
// im. K. Brodzińskiego
// w Tarnowie
var N = 40;
var WMIN = -1000;
var WMAX = 1000;
var d = new Array();
var L = new Array();
var K = new Array();
var we,szkb,ikb,ine;
var ip,ib,i,j,t;
for(i = 1; i <= N; i++)
L[i] = new Object();
function main()
{
// Generujemy zawartość
// tablicy d[]
// i wyświetlamy ją
t = "Przed sortowaniem:" +
"<br/><br/>";
for(i = 0; i < N; i++)
{
d[i] = WMIN +
Math.random() *
(WMAX - WMIN);
t += d[i].toFixed(2) +
" ";
if(!((i + 1) % 10))
t += "<br/>";
}
t += "<br/>";
// Zerujemy kubełki
for(i = 0; i <= N; i++)
K[i] = 0;
// Obliczamy szerokość
// kubełka
szkb = (WMAX - WMIN) / N;
ine = 1;
// Rozrzucamy poszczególne
// elementy d[i]
// na listach K[]
for(i = 0; i < N; i++)
{
we = d[i];
ikb = Math.floor(
(we - WMIN) / szkb);
L[ine].nastepnik = 0;
L[ine].dane = we;
ip = 0;
ib = K[ikb];
while((ib > 0) &&
(L[ib].dane < we))
{
ip = ib;
ib = L[ib].nastepnik;
}
if(!ip)
{
L[ine].nastepnik = ib;
K[ikb] = ine;
}
else if(!ib)
L[ip].nastepnik = ine;
else
{
L[ip].nastepnik = ine;
L[ine].nastepnik = ib;
}
ine++;
}
// wybieramy dane z kubełków
// i umieszczamy je w d[]
j = 0;
for(ikb = 0; ikb <= N; ikb++)
{
i = K[ikb];
while(i)
{
d[j++] = L[i].dane;
i = L[i].nastepnik;
}
}
// Koniec. Wyświetlamy wyniki
t += "Po sortowaniu:" +
"<br/><br/>";
for(i = 0; i < N; i++)
{
t += d[i].toFixed(2) +
" ";
if(!((i + 1) % 10))
t += "<br/>";
}
document.getElementById("out")
.innerHTML = t;
}
</script>
</body>
</html> |
| Cechy Algorytmu Sortowania Kubełkowego | |
| klasa złożoności obliczeniowej optymistyczna | O(n) |
| klasa złożoności obliczeniowej typowa | |
| klasa złożoności obliczeniowej pesymistyczna ? | |
| Sortowanie w miejscu | NIE |
| Stabilność | NIE |
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
