|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
ProblemW łańcuchu s należy wyznaczyć wszystkie wystąpienia wzorca p. |
Zadanie znajdowania wzorca w łańcuchu rozwiązuje algorytm opracowany przez J. H. Morrisa i V. R. Pratta w 1977 roku. Algorytm działa w czasie liniowym O(n+m), gdzie n jest długością przeszukiwanego łańcucha, a m jest długością poszukiwanego wzorca. W algorytmie Morrisa-Pratta (w skrócie algorytm MP) wykorzystuje się tablicę Π, której tworzenie opisane jest w rozdziale o wyszukiwaniu maksymalnego prefikso-sufiksu. Korzysta się przy tym z następującej własności łańcuchów tekstowych:
Załóżmy, iż poszukujemy pierwszego wystąpienie wzorca p w danym łańcuchu tekstowym s. W trakcie porównywania kolejnych znaków łańcucha ze znakami wzorca natrafiliśmy na sytuację, w której pewien prefiks wzorca p, o długości b znaków, pasuje do prefiksu okna w łańcuchu s przed pozycją i-tą, jednakże znak s[i] (oznaczony na rysunku symbolem A) różni się od znaku p[b] (oznaczony symbolem B), który znajduje się we wzorcu tuż za pasującym prefiksem:
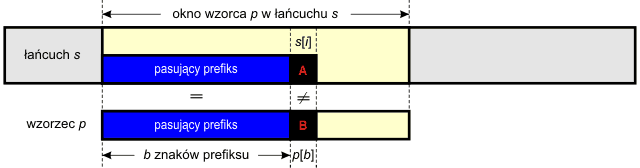
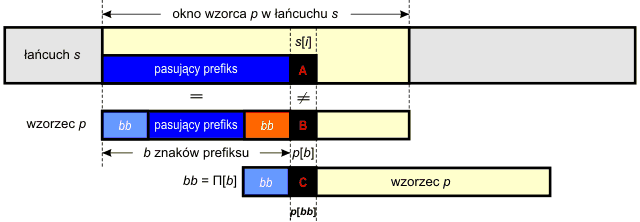
Algorytm N w takiej sytuacji przesuwa okno wzorca o jedną pozycję w prawo względem przeszukiwanego tekstu i rozpoczyna od początku porównywanie znaków wzorca p ze znakami okna nie korzystając zupełnie z faktu zgodności części znaków. To marnotrawstwo prowadzi w efekcie do klasy złożoności obliczeniowej O(n2). Tymczasem okazuje się, iż wykorzystując fakt istnienia pasującego prefiksu, możemy pominąć pewne porównania znaków bez żadnej szkody dla wyniku poszukiwań. Otóż po stwierdzeniu niezgodności okno wzorca przesuwamy, tak aby przed znakiem s[i] znalazł się maksymalny prefikso-sufiks prefiksu wzorca p:
Dzięki temu podejściu pomijamy niepotrzebne porównania znaków oraz unikamy cofania się indeksu i (przesuwa się jedynie okno wzorca).
Dla każdego prefiksu wzorca szerokość maksymalnego prefikso-sufiksu można wyznaczyć przed rozpoczęciem wyszukiwania – do tego właśnie celu generujemy tablicę Π algorytmem MP podanym w poprzednim rozdziale. Dla danej długości prefiksu b możemy z tej tablicy odczytać szerokość maksymalnego prefikso-sufiksu tego prefiksu. W naszym przypadku będzie to:
bb = Π[b]
Teraz porównujemy znak wzorca p[bb] (oznaczony na rysunku symbolem C) ze znakiem s[i] (symbol A). Jeśli wciąż mamy niezgodność, to procedurę powtarzamy, aż do wyczerpania się prefikso-sufiksów – w takim przypadku okno wzorca oraz indeks i przesuwamy o jedną pozycję w prawo.
Jeśli otrzymamy zgodność, to pasujący prefiks zwiększa swoją długość o 1 znak. Przesuwamy również indeks i o 1, ponieważ znak na tej pozycji został już całkowicie wykorzystany przez algorytm MP.
Jeśli prefiks obejmie cały wzorzec (b = |s|), to znaleziona zostanie pozycja wzorca w s i będzie ona równa i - b+1. W przeciwnym razie poszukiwania kontynuujemy.
Zwróć uwagę, iż algorytm MP nigdy nie cofa indeksu i. Dzięki tej własności algorytm umożliwia przetwarzanie danych sekwencyjnych – np. wyszukiwanie położenia wzorca w dużym pliku, który fizycznie może nie mieścić się w pamięci operacyjnej komputera – każdy znak pliku jest odczytywany tylko jeden raz.
K01: Wyznacz tablicę Π ; wyznaczamy tablicę maksymalnych prefikso-sufiksów K02: pp ← -1 ; wstępna pozycja wzorca ustawiona na -1 K03: b ← 0 ; wstępną długość prefikso-sufiksu ustawiamy na 0 K04: Dla i = 0, 1, …|s|-1: ; pętla wyznacza znaki łańcucha do porównania wykonuj kroki K05…K10 ; ze znakami wzorca K05: Dopóki (b > -1)(p[b] ≠ s[i]), ; Szukamy we wzorcu p rozszerzalnego wykonuj b ← Π[b] ; prefiksu pasującego do prefiksu okna wzorca. ; Pętlę K05 przerywamy, jeśli znajdziemy ; rozszerzalny prefiks lub napotkamy wartownika -1 K06: b ← b+1 ; Rozszerzamy prefiks o 1 znak. Jeśli prefiks był ; wartownikiem, to otrzymuje wartość 0. K07: Jeśli b < |p|, ; Jeśli prefiks nie obejmuje całego wzorca, to następny obieg pętli K04 ; to kontynuujemy pętlę K04, czyli porównujemy ; znak p[b] z kolejnym znakiem łańcucha s. K08: pp ← i-b+1 ; wyznaczamy pozycję wzorca p w łańcuchu s K09: Pisz pp ; wyprowadzamy tę pozycję K10: b ← Π[b] ; redukujemy b do długości prefikso-sufiksu wzorca K11: Jeśli pp = -1, ; jeśli wzorzec p nie występuje w s, wyprowadzamy -1 to pisz -1 K12: Zakończ
Uwaga: Porównaj algorytm MP wyszukiwania wzorca z algorytmem wyznaczania tablicy Π[0] i wyciągnij wnioski.
|
Uwaga: Zanim uruchomisz program, przeczytaj wstęp do tego artykułu, w którym wyjaśniamy funkcje tych programów oraz sposób korzystania z nich. |
| Program generuje 79 znakowy łańcuch zbudowany z pseudolosowych kombinacji liter A i B oraz 5 znakowy wzorzec wg tego samego schematu. Następnie program wyznacza tablicę długości maksymalnych prefikso-sufiksów kolejnych prefiksów wzorca i wykorzystuje ją do znalezienia wszystkich wystąpień wzorca w łańcuchu. |
Pascal// Wyszukiwanie wzorca algorytmem MP
// Data: 3.06.2008
// (C)2020 mgr Jerzy Wałaszek
//----------------------------------
program prg;
const
N = 79; // długość łańcucha s
M = 5; // długość wzorca p
var
s, p : ansistring;
PI : array [0..M] of integer;
i, b, pp : integer;
begin
randomize;
// generujemy łańcuch s
s := '';
for i := 1 to N do
s := s+chr(65+random(2));
// generujemy wzorzec
p := '';
for i := 1 to M do
p := p+chr(65+random(2));
// dla wzorca obliczamy tablicę PI[]
PI[0] := -1;
b := -1;
for i := 1 to M do
begin
while(b > -1) and (p[b+1] <> p[i]) do
b := PI[b];
inc(b); PI[i] := b;
end;
// wypisujemy wzorzec p
writeln(p);
// wypisujemy łańcuch s
writeln(s);
// poszukujemy pozycji wzorca w łańcuchu
pp := 0; b := 0;
for i := 1 to N do
begin
while(b > -1) and (p[b+1] <> s[i]) do
b := PI[b];
inc(b);
if b = M then
begin
while pp < i-b do
begin
write(' '); inc(pp);
end;
write('^'); inc(pp);
b := PI[b];
end
end;
writeln;
end. |
C++// Wyszukiwanie wzorca algorytmem MP
// Data: 3.06.2008
// (C)2020 mgr Jerzy Wałaszek
//----------------------------------
#include <iostream>
#include <string>
#include <cstdlib>
#include <ctime>
using namespace std;
const int N = 79; // długość łańcucha s
const int M = 5; // długość wzorca p
int main()
{
string s, p;
int PI[M+1], i, b, pp;
srand(time(NULL));
// generujemy łańcuch s
s = "";
for(i = 0; i < N; i++)
s += 65+rand() % 2;
// generujemy wzorzec
p = "";
for(i = 0; i < M; i++)
p += 65+rand() % 2;
// dla wzorca obliczamy tablicę PI[]
PI[0] = b = -1;
for(i = 1; i <= M; i++)
{
while((b > -1) && (p[b] != p[i-1]))
b = PI[b];
PI[i] = ++b;
}
// wypisujemy wzorzec
cout << p << endl;
// wypisujemy łańcuch s
cout << s << endl;
// poszukujemy pozycji wzorca w łańcuchu
pp = b = 0;
for(i = 0; i < N; i++)
{
while((b > -1) && (p[b] != s[i]))
b = PI[b];
if(++b == M)
{
while(pp < i-b+1)
{
cout << " "; pp++;
}
cout << "^"; pp++;
b = PI[b];
}
}
cout << endl;
return 0;
} |
Basic' Wyszukiwanie wzorca algorytmem MP
' Data: 3.06.2008
' (C)2020 mgr Jerzy Wałaszek
'----------------------------------
Const N = 79 ' długość łańcucha s
Const M = 5 ' długość wzorca p
Dim As String s, p
Dim As Integer PI(M), i, b, pp
Randomize
' generujemy łańcuch s
s = ""
For i = 1 To N
s += Chr(65+Cint(Rnd))
Next
' generujemy wzorzec
p = ""
For i = 1 To M
p += Chr(65+Cint(Rnd))
Next
' dla wzorca obliczamy tablicę PI[]
PI(0) = -1: b = -1
For i = 1 To M
While (b > -1) And _
(Mid(p, b+1, 1) <> Mid(p, i, 1))
b = PI(b)
Wend
b += 1: PI(i) = b
Next
' wypisujemy wzorzec p
Print p
' wypisujemy łańcuch s
Print s
' poszukujemy pozycji wzorca w łańcuchu
pp = 0: b = 0
For i = 1 To N
While (b > -1) And _
(Mid(p, b+1, 1) <> Mid(s, i, 1))
b = PI(b)
Wend
b += 1
If b = M Then
While pp < i-b
Print " ";: pp += 1
Wend
Print "^";: pp += 1
b = PI(b)
End If
Next
Print
End |
Python
(dodatek)# Wyszukiwanie wzorca algorytmem MP
# Data: 7.03.2024
# (C)2024 mgr Jerzy Wałaszek
#----------------------------------
import random
N = 79 # długość łańcucha s
M = 5 # długość wzorca p
# generujemy łańcuch s
s = ""
for i in range(N):
s += chr(random.randrange(65, 67))
# generujemy wzorzec
p = ""
for i in range(M):
p += chr(random.randrange(65, 67))
# dla wzorca obliczamy tablicę PI[]
tpi = [-1]
b = -1
for i in range(1, M+1):
while (b > -1) and (p[b] != p[i-1]):
b = tpi[b]
b += 1
tpi.append(b)
# wypisujemy wzorzec p
print(p)
# wypisujemy łańcuch s
print(s)
# poszukujemy pozycji wzorca w łańcuchu
pp = 0
b = 0
for i in range(N):
while (b > -1) and (p[b] != s[i]):
b = tpi[b]
b += 1
if b == M:
while pp < i-b+1:
print(" ", end="")
pp += 1
print("^", end="")
pp += 1
b = tpi[b]
print()
|
| Wynik: |
BBABA
BBBBAAABAABABBBABABAAABABBBABABAAABBAAABABBBBAAABAAAABBABBAABABBBBBBABAAABBBABA
^ ^ ^ ^
|
JavaScript<html>
<head>
<title>
MP
</title>
</head>
<body>
<div style="overflow-x: auto;"
align="center">
<table
border="0"
cellpadding="4"
style="border-collapse:
collapse">
<tr>
<td nowrap>
<form
name="frm"
style="text-align:
center;
background-color:
#E7E7DA">
<b>
Wyszukiwanie wzorca
algorytmem MP
<br/></b>
(C)2026
mgr Jerzy Wałaszek
<hr>
<input
type="button"
value="Wykonaj"
name="B1"
onclick="main()">
<hr>
<b>Wynik:</b>
<div id="out">.</div>
</form>
</td>
</tr>
</table>
</div>
<script type=text/javascript
language=javascript>
function main()
{
var N = 79; // długość s
var M = 5; // długość p
var s, p, i, b, pp, t;
var PI = new Array(M + 1);
// generujemy łańcuch s
s = "";
for(i = 0; i < N; i++)
s += String.fromCharCode(
65 + Math.floor(
Math.random() * 2));
// generujemy wzorzec p
p = "";
for(i = 0; i < M; i++)
p += String.fromCharCode(
65 + Math.floor(
Math.random() * 2));
// dla wzorca obliczamy
// tablicę PI[]
PI[0] = b = -1;
for(i = 1; i <= M; i++)
{
while((b>-1) &&
(p.charAt(b) !=
p.charAt(i - 1)))
b = PI[b];
PI[i] = ++b;
}
// wypisujemy wzorzec
t = "<pre> " + p + "<br/> ";
// wypisujemy łańcuch s
t += s + " <br/> " +
"<span style=" +
"'color:red'>";
// poszukujemy pozycji
// wzorca w łańcuchu
pp = b = 0;
for(i = 0; i < N; i++)
{
while((b>-1) &&
(p.charAt(b) !=
s.charAt(i)))
b = PI[b];
if(++b == M)
{
while(pp < i - b + 1)
{
t += " ";
pp++;
}
t += "^";
pp++;
b = PI[b];
}
}
t += "</span></span></pre>";
document.getElementById("out")
.innerHTML = t;
}
</script>
</body>
</html>
|
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
