|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
ProblemW łańcuchu s należy wyszukać wszystkie słowa podwójne. Przez słowo podwójne (ang. square word) będziemy rozumieli łańcuch tekstowy, który możemy rozdzielić na dwa identyczne podłańcuchy. Przykład: ABBCABBC – jest słowem podwójnym zbudowanym z dwóch identycznych podsłów ABBC ABBCABBD – nie jest słowem podwójnym |
Pierwsze rozwiązanie polega na bezpośrednim sprawdzaniu każdego podsłowa łańcucha s, czy jest ono słowem podwójnym. Złożoność obliczeniowa takiego podejścia jest klasy O(n3). Słowo podwójne musi się składać z parzystej liczby znaków – inaczej nie da się go podzielić na dwa podsłowa. Sprawdzanie polega na porównywaniu ze sobą znaków pierwszej i drugiej połówki. Jeśli są zgodne, słowo jest podwójne.
K01: m ← |s| K02: Dla i = 0, 1, …, n-2: ; przeglądamy łańcuch s wykonuj kroki K03…K07 K03: n ← 2 ; rozpoczynamy od słowa o długości 2 K04: Dopóki i = n ≤ m: wykonuj kroki K05…K07 K05: j ← i+n div 2 ; j wskazuje pierwszy znak ; drugiej połówki słowa K06: Jeśli s[i:j] = s[j:i+n], ; sprawdzamy, to pisz s[i:i+n] ; czy słowo jest podwójne K07: n ← n+2 ; przechodzimy do następnego słowa K08: Zakończ
|
Uwaga: Zanim uruchomisz program, przeczytaj wstęp do tego artykułu, w którym wyjaśniamy funkcje tych programów oraz sposób korzystania z nich. |
| Program generuje 20 znakowy łańcuch zbudowany ze znaków {A, B}, wyszukuje w nim wszystkie słowa podwójne i wypisuje je z odpowiednim przesunięciem. |
Pascal// Wyszukiwanie słów podwójnych
// Data: 23.07.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------
program prg;
const M = 20; // długość łańcucha s
var
s : ansistring;
i, j, n : integer;
begin
// generujemy łańcuch s
randomize;
s := '';
for i := 1 to M do
s := s+chr(65+random(2));
// wypisujemy łańcuch s
writeln(s);
// szukamy słów podwójnych
for i := 1 to M-1 do
begin
n := 2;
while i+n <= M+1 do
begin
j := i+n div 2;
if copy(s, i, j-i) = copy(s, j, j-i) then
begin
for j := 2 to i do write(' ');
writeln(copy(s, i, n));
end;
inc(n, 2);
end;
end;
writeln;
end. |
C++// Wyszukiwanie słów podwójnych
// Data: 23.07.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------
#include <iostream>
#include <string>
#include <cstdlib>
#include <ctime>
using namespace std;
int main()
{
const int M = 20; // długość łańcucha s
string s;
int i, j, n;
// generujemy łańcuch s
srand(time(NULL));
s = "";
for(i = 0; i < M; i++)
s += char(65+rand()%2);
// wypisujemy łańcuch s
cout << s << endl;
// szukamy słów podwójnych
for(i = 0; i < M-1; i++)
for(n = 2; i+n <= M; n += 2)
{
j = i+n/2;
if(s.substr(i, j-i) == s.substr(j, j-i))
{
for(j = 0; j < i; j++)
cout << " ";
cout << s.substr(i, n) << endl;
}
}
cout << endl;
return 0;
} |
Basic' Wyszukiwanie słów podwójnych
' Data: 23.07.2008
' (C)2020 mgr Jerzy Wałaszek
'-----------------------------
Const M = 20 ' długość łańcucha s
Dim As String s
Dim As Integer i, j, n
' generujemy łańcuch s
Randomize
s = ""
For i = 1 To M
s += Chr(65+Cint(Rnd))
Next
' wypisujemy łańcuch s
Print s
' szukamy słów podwójnych
For i = 1 To M-1
n = 2
While i+n <= M+1
j = i+n\2
If Mid(s, i, j-i) = Mid(s, j, j-i) Then
For j = 2 To i
Print " ";
Next
Print Mid(s, i, n)
End If
n += 2
Wend
Next
Print
End |
Python
(dodatek)# Wyszukiwanie słów podwójnych
# Data: 20.03.2024
# (C)2024 mgr Jerzy Wałaszek
#---------------------------
import random
M = 20 # długość łańcucha s
# generujemy łańcuch s
s = ""
for i in range(M):
s += chr(random.randrange(65, 67))
# wypisujemy łańcuch s
print(s)
# szukamy słów podwójnych
for i in range(M-1):
n = 2
while(i+n <= M):
j = i+n//2
if s[i:j] == s[j:j+n//2]:
for k in range(i):
print(" ", end="")
print(s[i:i+n])
n += 2
print()
|
| Wynik: |
BABABBABBABBABBABAAB
BABA
ABAB
BABBAB
BABBABBABBAB
ABBABB
ABBABBABBABB
BB
BBABBA
BBABBABBABBA
BABBAB
BABBABBABBAB
ABBABB
BB
BBABBA
BABBAB
ABBABB
BB
BBABBA
BABBAB
BB
BABA
AA
|
JavaScript<html>
<head>
<title>
Słowa
podwójne
</title>
</head>
<body>
<div style="overflow-x: auto;"
align="center">
<table
border="0"
cellpadding="4"
style="border-collapse:
collapse">
<tr>
<td nowrap>
<form
name="frm"
style="text-align: center;
background-color:
#E7E7DA">
<b>
Wyszukiwanie słów
podwójnych
</b><br/>
(C)2026 mgr
Jerzy Wałaszek
<hr>
<input
type="button"
value="Wykonaj"
name="B1"
onclick="main();">
<hr>
<b>Wynik:</b>
<div
align="center"
class="small">
<table
border="0"
cellpadding="0"
style="border-collapse:
collapse">
<tr>
<td
valign="top">
<pre id="out">.</pre>
</td>
</tr>
</table>
</div>
</form>
</td>
</tr>
</table>
</div>
<script type=text/javascript
language=javascript>
// Wyszukiwanie słów podwójnych
// Data: 23.07.2008
// (C)2008 mgr Jerzy Wałaszek
//---------------------------
function main()
{
// długość łańcucha s
let M = 20;
let s,i,j,k,n,t;
// generujemy łańcuch s
s = ""
for(i = 0; i < M; i++)
s += String
.fromCharCode(65 +
Math.floor(
Math.random() * 2));
// wypisujemy łańcuch s
t = "<b>" + s + "<br/>";
// szukamy słów podwójnych
for(i = 0; i < M - 1; i++)
for(n = 2; i + n <= M; n += 2)
{
j = i + n / 2;
if(s.substr(i, j - i) ==
s.substr(j, j - i))
{
for(k = 0; k < i; k++)
t += " ";
t += "<span style=" +
"'color: Red'>" +
s.substr(i, j - i) +
"</span>";
t += "<span style=" +
"'color: Blue'>" +
s.substr(j, j- i) +
"</span><br/>";
}
}
document.getElementById("out")
.innerHTML = t + "</b>";
}
</script>
</body>
</html>
|
Pierwszy algorytm posiada sześcienną klasę złożoności obliczeniowej O(n3), gdzie n jest długością przeszukiwanego łańcucha s. W praktyce jednak działa on szybciej, ponieważ niezgodność fragmentów łańcucha zwykle wykrywana jest na początku po kilku testach. Zaletą jest prostota algorytmu.
Jeśli wykorzystamy w odpowiedni sposób algorytm Morrisa-Pratta, to możemy zredukować klasę złożoności obliczeniowej do kwadratowej O(n2). W algorytmie MP jest wyznaczana dla wzorca s tablica Π zawierająca maksymalne szerokości prefikso-sufiksów. Na przykład, jeśli weźmiemy prefiks s[0:i], to Π[i] zawiera szerokość prefikso-sufiksu tego prefiksu:
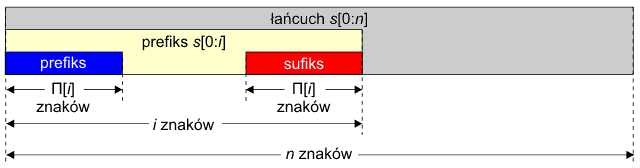
Na początek rozważymy wykrywanie słów podwójnych leżących na początku łańcucha s, a później uogólnimy tę operację na dowolną pozycję wewnątrz łańcucha. Ponieważ tablica Π jest tworzona dynamicznie w algorytmie MP, możemy w trakcie tego procesu badać jej zawartość. Jeśli i jest długością prefiksu s, to Π[i] jest długością prefikso-sufiksu dla tego prefiksu (patrz, rysunek powyżej). Mogą wystąpić trzy możliwe sytuacje:
1. Długość prefikso-sufiksu jest mniejsza od długości połowy prefiksu, czyli Π[i] < i/2:
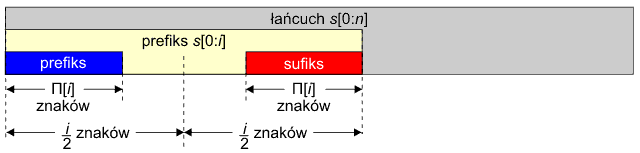
W tym przypadku nie można utworzyć słowa podwójnego o szerokości i.
2. Długość prefikso-sufiksu jest równa długości połowy prefiksu, czyli Π[i] = i/2:
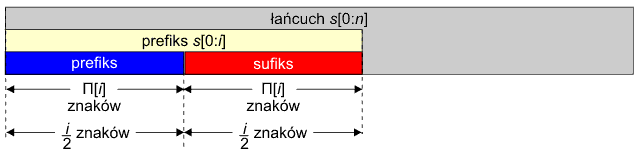
Prefiks s[0:i] jest słowem podwójnym, ponieważ składa się z dwóch, dokładnie takich samych podłańcuchów – prefiksu i sufiksu tworzących prefikso-sufiks.
3. Długość prefikso-sufiksu jest większa od długości połowy prefiksu, czyli Π[i] > i/2:
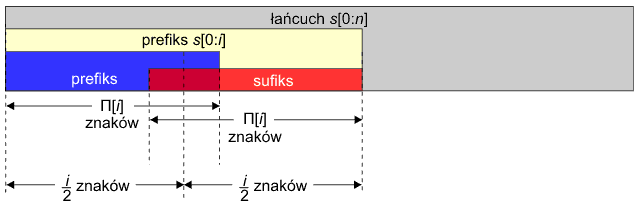
Zastanówmy się, kiedy prefiks s[0:i] może być słowem podwójnym. W tym celu przyjrzyjmy się poniższemu rysunkowi poglądowemu:
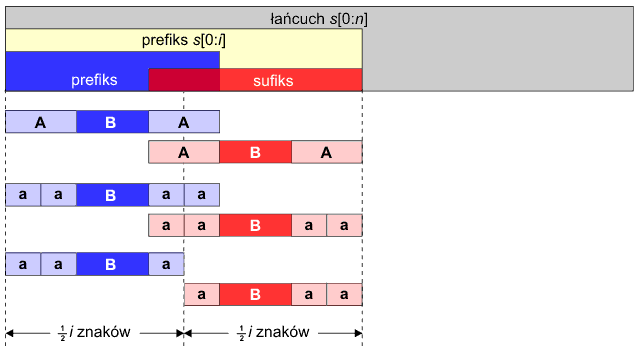
Symbolem A oznaczmy pokrywający się fragment prefikso-sufiksu. Ponieważ prefiks i sufiks są sobie równe w prefikso-sufiksie, fragment A występuje również na początku prefiksu oraz na końcu sufiksu. Aby mogło powstać słowo podwójne o długości i znaków, i musi być parzyste. Dalej wspólny fragment A sam musi być słowem podwójnym – w przeciwnym razie początki dwóch podsłów byłyby różne. Podzielmy zatem fragment A na dwa fragmenty oznaczone małą literką a. Z ostatniego przykładu widzimy wyraźnie, iż pozostały obszar B musi być podłańcuchem pustym – w przeciwnym razie nie otrzymamy równości podsłowa lewego i prawego:
aaBa ≠ aBaa, jeśli B ≠ Ø
Sytuacja taka wystąpi, gdy szerokość pokrywającego się fragmentu A będzie dokładnie równa 1/3 i, czyli: 3Π[i] = 2i
Ostatni przypadek wystąpi, gdy zachodzi nierówność: 3Π[i] > 2i. Pokażemy, iż w takim razie prefiks s[0:i] jest słowem podwójnym, jeśli pokrywający się fragment prefikso-sufiksu sam jest słowem podwójnym. Przyjrzyjmy się poniższemu rysunkowi poglądowemu:
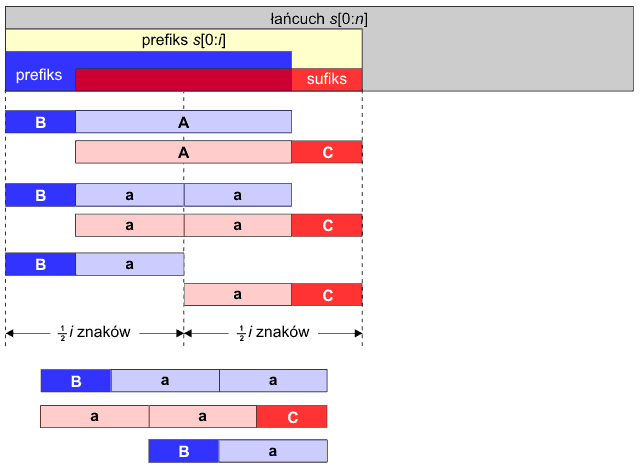
Na początku prefiksu pozostaje fragment B. Następnie mamy pokrywający się fragment A i na końcu sufiksu pozostaje fragment C o tej samej długości co fragment B. Pokrywający się fragment A musi być słowem podwójnym – dzielimy go zatem na dwie połówki oznaczone małymi literami a. Otrzymujemy dwa podsłowa Ba oraz aC. Aby prefiks s[0:n] był słowem podwójnym, musi zachodzić równość:
Ba = aC
Przyrównujemy do siebie prefiks i sufiks prefikso-sufiksu. Fragment B jest również prefiksem podsłowa a, natomiast fragment C jest również sufiksem podsłowa a. Z tego prostego spostrzeżenia bezpośrednio wynika poszukiwana równość Ba = aC.
Pozostaje jedynie problem sprawdzenia, czy fragment A jest słowem podwójnym. Zwróć jednakże uwagę, iż jest on zawsze krótszy od prefiksu s[0:i] oraz jest zawsze prefiksem podłańcucha s[0:i]. Zatem algorytm już wcześniej sprawdzał, czy ten prefiks był słowem podwójnym. Dlatego wystarczy zapamiętać ten fakt w osobnej tablicy (nie zwiększymy złożoności czasowej, jednakże zwiększymy złożoność pamięciową) – lub po prostu sprawdzić, czy A jest słowem podwójnym (zwiększa się złożoność czasowa). W dodatkowej tablicy zapamiętujemy jedynie fakt, czy podsłowo A jest podwójne, zatem może to być tablica logiczna. Co więcej nie ma sensu zapamiętywać informacji o słowach zbudowanych z nieparzystej liczby znaków. Pozwala to zmniejszyć o połowę wielkość tej tablicy.
Podsumowując stwierdzamy:
Wyszukanie wszystkich słów podwójnych w łańcuchu s sprowadza się do wyszukiwania tych słów w kolejnych sufiksach poczynając od niewłaściwego (obejmującego cały łańcuch) i kończąc na sufiksie dwuznakowym. Algorytm MP działa w czasie liniowym, natomiast operacja przeszukania wszystkich sufiksów łańcucha s będzie wymagała kwadratowej złożoności obliczeniowej. Złożoność pamięciowa algorytmu jest liniowa.
K01: n ← |s| ; wyznaczamy długość łańcucha s K02: Dla j = 0, 1, …, n-1: ; przeglądamy sufiksy s[j:n] wykonuj kroki K03…K17 K03: Π[0] ← -1 ; algorytmem MP wyznaczamy kolejne K04: b ← -1 ; maksymalne prefikso-sufiksy dla K05: Dla i = 1, 2, …, n-j: ; danego sufiksu s[j:n] wykonuj kroki K06…K17 K06: Dopóki (b > -1) ∧ (s[j+b] ≠ s[j+i-1]): wykonuj b ← Π[b] K07: b ← b+1 K08: Π[i] ← b K09: b2 ← b shr 1 ; podwójna szerokość prefikso-sufiksu K10: Jeśli i nieparzyste, ; słowo podwójne posiada to następny obieg pętli K05 ; parzystą liczbę liter K11: P[i shr 1] ← false ; inicjujemy element tablicy P K12: Jeśli b2 < i, ; przypadek nr 1 to następny obieg pętli K05 K13: Jeśli b2 = i, ; przypadek nr 2 to idź do kroku K16 K14: Jeśli b2+b < i shl 1, ; przypadek nr 3 z B ≠ Ø to następny obieg pętli K05 K15: Jeśli P[(b2-i) shr 1] = false, ; przypadek nr 3 to następny obieg pętli K05 ;-obszar wspólny nie ; jest słowem podwójnym K16: P[i shr 1] ← true; ; zapamiętujemy, iż s[j:j+i] ; jest słowem podwójnym K17: Pisz s[j:j+i] ; wyprowadzamy znalezione słowo podwójne K18: Zakończ
|
Uwaga: Zanim uruchomisz program, przeczytaj wstęp do tego artykułu, w którym wyjaśniamy funkcje tych programów oraz sposób korzystania z nich. |
| Program generuje 20 znakowy łańcuch zbudowany ze znaków {A, B}, wyszukuje w nim wszystkie słowa podwójne i wypisuje je z odpowiednim przesunięciem. |
Pascal// Wyszukiwanie słów podwójnych
// Data: 9.08.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------
program prg;
const N = 20; // długość łańcucha s
var
s : ansistring;
i, j, k, b, b2 : integer;
PI : array [0..N] of integer;
P : array [0..N shr 1] of boolean;
begin
// generujemy łańcuch s
randomize;
s := '';
for i := 1 to N do
s := s+chr(65+random(2));
// wypisujemy łańcuch s
writeln(s);
// szukamy słów podwójnych
for j := 1 to N-1 do
begin
PI[0] := -1; b := -1;
for i := 1 to N-j+1 do
begin
while(b > -1) and (s[j+b] <> s[j+i-1]) do
b := PI[b];
inc(b); PI[i] := b; b2 := b shl 1;
if i and 1 = 0 then
begin
P[i shr 1] := false;
if(b2 < i) then continue;
if(b2 > i) then
begin
if b2+b < (i shl 1) then continue;
if not (P[(b2-i) shr 1]) then continue;
end;
P[i shr 1] := true;
for k := 2 to j do write(' ');
writeln(copy(s, j, i));
end;
end;
end;
writeln;
end. |
C++// Wyszukiwanie słów podwójnych
// Data: 9.08.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------
#include <iostream>
#include <string>
#include <cstdlib>
#include <ctime>
using namespace std;
const int N = 20; // długość łańcucha s
int main()
{
string s;
int i, j, k, b, b2, PI[N+1];
bool P[(N >> 1)+1];
// generujemy łańcuch s
srand(time(NULL));
s = "";
for(i = 0; i < N; i++)
s += char(65+rand() % 2);
// wypisujemy łańcuch s
cout << s << endl;
// szukamy słów podwójnych
for(j = 0; j < N-1; j++)
{
PI[0] = b = -1;
for(i = 1; i <= N-j; i++)
{
while((b > -1) && (s[j+b] != s[j+i-1]))
b = PI[b];
PI[i] = ++b; b2 = b << 1;
if(!(i & 1))
{
P[i >> 1] = false;
if(b2 < i) continue;
if(b2 > i)
{
if(b2+b < (i << 1)) continue;
if(!P[(b2-i) >> 1]) continue;
}
P[i >> 1] = true;
for(k = 0; k < j; k++)
cout << " ";
cout << s.substr(j, i) << endl;
}
}
}
cout << endl;
return 0;
} |
Basic' Wyszukiwanie słów podwójnych
' Data: 9.08.2008
' (C)2020 mgr Jerzy Wałaszek
'-----------------------------
Const N = 20 ' długość łańcucha s
Dim As String s
Dim As Integer i, j, k, b, b2, PI(N)
Dim As Byte P(N Shr 1)
' generujemy łańcuch s
Randomize
s = ""
For i = 1 To N
s += Chr(65+Cint(Rnd))
Next
' wypisujemy łańcuch s
Print s
' szukamy słów podwójnych
For j = 1 To N-1
PI(0) = -1: b = -1
For i = 1 To N-j+1
While (b > -1) And _
(Mid(s, j+b, 1) <> Mid(s, j+i-1, 1))
b = PI(b)
Wend
b += 1: PI(i) = b: b2 = b Shl 1
if(i And 1) = 0 Then
P(i Shr 1) = 0
if(b2 < i) Then Continue For
if(b2 > i) Then
If b2+b < (i Shl 1) Then Continue For
If P((b2-i) Shr 1) = 0 Then _
Continue For
End If
P(i Shr 1) = 1
For k = 2 To j
Print " ";
Next
Print Mid(s, j, i)
End If
Next
Next
Print
End |
Python
(dodatek)# Wyszukiwanie słów podwójnych
# Data: 21.03.2024
# (C)2024 mgr Jerzy Wałaszek
#-----------------------------
import random
N = 20 # długość łańcucha s
# tworzymy tablice
t_pi = [0] * (N+1)
t_p = [False] * ((N >> 1)+16)
# generujemy łańcuch s
s = ""
for i in range(N):
s += chr(random.randrange(65, 67))
# wypisujemy łańcuch s
print(s)
# szukamy słów podwójnych
for j in range(N-1):
t_pi[0] = -1
b = -1
for i in range(1, N-j+1):
while (b > -1) and \
(s[j+b] != s[j+i-1]):
b = t_pi[b]
b += 1
t_pi[i] = b
b2 = b << 1
if not (i & 1):
t_p[i >> 1] = False
if b2 < i: continue
if b2 > i:
if b2+b < i << 1:
continue
if not t_p[(b2-i) >> 1]:
continue
t_p[i >> 1] = True
for k in range(j):
print(" ", end="")
print(s[j:j+i])
print()
|
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
