|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
Tutaj porównamy ze sobą kilka sposobów obsługi tekstu w językach C i C++.
| C | C++ |
| Reprezentacja tekstu | |
Na końcu łańcucha tekstowego umieszczany jest kod NUL: "JANEK" → 'J','A','N','E','K','\0' |
Tak samo jak w C |
| Plik nagłówkowy | |
#include <cstring> |
#include <string> |
| Zmienna tekstowa s | |
Tablica znakowa char:
char s[100]; // Stały rozmiar
char s[ ] = "tekst"; // Rozmiar tekstu + 1
char s[100] = {'J','A','N','\0'}; // stały rozmiar
|
Zmienna klasy string.
string s; // Rozmiar dynamiczny
string s("...tekst..."); // Rozmiar dynamiczny
string s = {'J','A','N','\0'}; // Rozmiar dynamiczny
|
| Liczba znaków tekstu s | |
d = strlen(s); //s - tablica char z tekstem
//zakończonym znakiem NUL
|
d = s.length( ); // s - zmienna string |
| Dostęp do znaków tekstu s | |
s[indeks] |
s[indeks] s.at(indeks) |
| Odczyt tekstu ze strumienia do zmiennej s | |
Jeden wyraz: cin >> s; // ss - tablica char Cały wiersz: cin.getline(s,n); |
Jeden wyraz: cin >> s; // s - zmienna string Cały wiersz: getline(cin,s); |
| Wprowadzanie nowego tekstu t do zmiennejs | |
strcpy(s,"...tekst...");
strcpy(s,t); //t - tablica char z tekstem.
//Nie może być większa od s.
|
s = "...tekst..."; s = t; // t - zmienna string |
| Łączenie tekstów | |
strcat(s,t); // s,t - tablice char strcpy(s,t); strcat(s,u); // s,t,u - tablice char |
s += t; // s,t - zmienne string s = t + u; // s,t,u - zmienne string; |
| Zmniejszenie rozmiaru tekstu s do n znaków | |
s[n] = '\0'; // Rozmiar tablicy s >= n+1! |
s.resize(n); |
| Zwiększenie rozmiaru tekstu s do n znaków z wypełnieniem znakiem '+' | |
| for(i = length(s); i < n; i++) s[i] =
'+'; s[n] = '\0'; // Rozmiar tablicy s >= n+1! |
s.resize(n,'+'); |
| Dodanie znaku c na końcu tekstu a | |
d = strlen(s);
s[d] = c;
s[d+1] = '\0'; // Tablica s musi
// pomieścić nowy tekst
|
a += z; |
| Usunięcie ostatniego znaku tekstu | |
s[strlen(s)-1] = '\0'; |
s.pop_back( ); |
| Wstawienie znaku c na początku tekstu | |
for(i = strlen(s); i > 0; i--) s[i] = s[i-1]; s[0] = c; // tablica s musi pomieścić nowy tekst |
s = c + s; |
| Wstawienie znaku c na pozycję p w tekście s | |
for(i = strlen(s); i > p; i--) s[i] = s[i-1]; s[p] = c; // tablica s musi pomieścić nowy tekst |
s.insert(p,1,c); |
| Dodanie nowego tekstu t na początku tekstu | |
strcpy(u,s); // u - pomocnicza tablica char
strcpy(s,t) // t - tablica char
// z dołączanym tekstem
strcat(s,u);
|
s = t + s; |
| Zmiana kolejności znaków tekstu na odwrotną | |
for(j = strlen(s) - 1,i = 0; i < j; i++,j--)
{
x = s[i]; // x - zmienna pomocnicza char
s[i]= s[j];
s[j] = x;
}
Operator przecinek pozwala wykonać
obie instrukcje jako jedną.
|
for(j = s.length( )-1,i = 0; i < j; i++,j--) swap(s[i],s[j]); Operator przecinek pozwala wykonać obie instrukcje jako jedną. Funkcja swap( ) zamienia zawartości podanych zmiennych. W tym przypadku zmiennymi są znaki na pozycjach i oraz j. |
W systemie dziesiętnym mamy
10 cyfr: 0,1,2,3,4,5,6,7,8,9.
Podstawa systemu wynosi 10. Oznaczmy ją symbolicznie jako p. Cyfr jest zawsze
tyle, ile wynosi podstawa systemu.
Wartość liczby dziesiętnej (tzn. o podstawie p = 10)
reprezentuje ciąg cyfr. Cyfry znajdują się na pozycjach, których wartości są
kolejnymi potęgami podstawy systemu p (czyli tutaj liczby 10).
Wartości te nazywamy wagami pozycji
| ... | 1000 | 100 | 10 | 0 | |
| Wagi pozycji | ... | p3=103 | p2=102 | p1=101 | p0=100 |
| cyfry | ... | C | C | C | C |
| Numery pozycji | ... | 3 | 2 | 1 | 0 |
Wartość liczby jest równa sumie iloczynów cyfr przez wagi pozycji na których cyfry się znajdują. Na przykład:
| ... | 1000 | 100 | 10 | 1 |
|
|
| Wagi pozycji | ... | p3=103 | p2=102 | p1=101 | p0=100 |
|
| cyfry | ... | 7 | 2 | 3 | 9 |
= 7 × 1000 + 2 × 100 + 3 × 10 + 9 × 1 |
| Numery pozycji | ... | 3 | 2 | 1 | 0 |
|
Co się stanie, jeśli liczbę 7239 podzielimy stałoliczbowo przez podstawę systemu (czyli 10)? Otrzymamy:
7239 : 10 = 723 i reszta 9
Zwróć uwagę, iż cyfry liczby przesunęły się o jedną pozycję w prawo, a reszta z dzielenia jest ostatnią cyfrą. Wykonujemy zatem następne dzielenia, aż otrzymamy wynik 0:
7239 : 10 |
= |
723 |
i reszta 9 |
723 : 10 |
= |
72 |
i reszta 3 |
72 : 10 |
= |
7 |
i reszta 2 |
7 : 10 |
= |
0 |
i reszta 7 |
Otrzymaliśmy jako reszty z dzieleń cyfry liczby, ale w kolejności odwrotnej, czyli od końca. Aby w łańcuchu tekstowym cyfry znalazły się we właściwej kolejności musimy je wstawiać kolejno na początek tekstu lub na koniec i po zakończeniu przetwarzania odwrócić kolejność znaków (ten drugi sposób jest bardziej efektywny, gdyż przestawianie znaków wykonujemy tylko jeden raz). Zasada przetwarzania jest zatem następująca:
Łańcuch wyjściowy zerujemy.
Wartość W dzielimy całkowitoliczbowo przez podstawę p systemu pozycyjnego, w
którym chcemy otrzymać reprezentację liczby. Jako nowe W przyjmujemy wynik
dzielenia. Reszta z dzielenia jest kolejną od końca cyfrą reprezentacji liczby.
Wartość reszty zamieniamy na znak ASCII cyfry i dodajemy na początku łańcucha
wyjściowego. Jeśli wartość W jest większa od zera, to operację powtarzamy. W
przeciwnym razie kończymy przetwarzanie. W łańcuchu jest reprezentacja liczby.
Zobaczmy jak to działa dla kilku konwersji:
7239 : 8 |
= |
904 |
i reszta 7 |
904 : 8 |
= |
113 |
i reszta 0 |
113 : 8 |
= |
14 |
i reszta 1 |
14 : 8 |
= |
1 |
i reszta 6 |
1 : 8 |
= |
0 |
i reszta 1 |
723910 = 161078
7239 : 4 |
= |
1809 |
i reszta 3 |
1809 : 4 |
= |
452 |
i reszta 1 |
452 : 4 |
= |
113 |
i reszta 0 |
113 : 4 |
= |
28 |
i reszta 1 |
28 : 4 |
= |
7 |
i reszta 0 |
7 : 4 |
= |
1 |
i reszta 3 |
1 : 4 |
= |
0 |
i reszta 1 |
723910 = 13010134
7239 : 3 |
= |
2413 |
i reszta 0 |
2413 : 3 |
= |
804 |
i reszta 1 |
804 : 3 |
= |
268 |
i reszta 0 |
268 : 3 |
= |
89 |
i reszta 1 |
89 : 3 |
= |
29 |
i reszta 2 |
29 : 3 |
= |
9 |
i reszta 2 |
9 : 3 |
= |
3 |
i reszta 0 |
3 : 3 |
= |
1 |
i reszta 0 |
1 : 3 |
= |
0 |
i reszta 1 |
723910 = 1002210103
7239 : 2 |
= |
3619 |
i reszta 1 |
3619 : 2 |
= |
1809 |
i reszta 1 |
1809 : 2 |
= |
904 |
i reszta 1 |
904 : 2 |
= |
452 |
i reszta 0 |
452 : 2 |
= |
226 |
i reszta 0 |
226 : 2 |
= |
113 |
i reszta 0 |
113 : 2 |
= |
56 |
i reszta 1 |
56 : 2 |
= |
28 |
i reszta 0 |
28 : 2 |
= |
14 |
i reszta 0 |
14 : 2 |
= |
7 |
i reszta 0 |
7 : 2 |
= |
3 |
i reszta 1 |
3 : 2 |
= |
1 |
i reszta 1 |
1 : 2 |
= |
0 |
i reszta 1 |
723910 = 11100010001112
Jeśli podstawa systemu p jest większa od 10, to jest pewien drobny problem. W takim przypadku liczba cyfr jest również większa od 10 i jako brakujące cyfry przyjęto litery alfabetu A, B, C.... Kod ASCII dla cyfry 0...9 otrzymujemy przez dodanie 48. Kody ASCII cyfr literowych otrzymamy przez dodanie 55 (sprawdź to) do wartości cyfry.
7239 : 12 |
= |
603 |
i reszta 3 |
→ cyfra 3 |
603 : 12 |
= |
50 |
i reszta 3 |
→ cyfra 3 |
50 : 12 |
= |
4 |
i reszta 2 |
→ cyfra 2 |
4 : 12 |
= |
0 |
i reszta 4 |
→ cyfra 4 |
723910 = 423312
7239 : 16 |
= |
452 |
i reszta 7 |
→ cyfra 7 |
452 : 16 |
= |
28 |
i reszta 4 |
→ cyfra 4 |
28 : 16 |
= |
1 |
i reszta 12 |
→ cyfra C |
1 : 16 |
= |
0 |
i reszta 1 |
→ cyfra 1 |
723910 = 1C4716
Maksymalnym systemem pozycyjnym, który tą metodą można osiągnąć jest system o podstawie 36, który posiada cyfry:
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Chińczycy mają tutaj przewagę z uwagi na posiadanie kilku tysięcy znaków w swoim alfabecie :).
Przejdźmy do algorytmu:
Dane wejściowe:
a – tablica znakowa, w której znajdzie się wynik przetwarzania
p – podstawa systemu docelowego 2...36
W – wartość liczby
Dane wyjściowe:
a – łańcuch znaków ASCII z reprezentacją liczby
Lista kroków:
K01: a[0] ← '\0'
K02: r ← reszta z W : p
K03: W ← W : p
K04: Jeśli r > 9, to
c ← r + 55
inaczej
c ← r + 48
K05: d ← strlen(a)
K06: a[d] ← c
K07: a[d + 1] ← '\0'
K08: Jeśli W > 0,
to idź do kroku K02
K09: Zmień kolejność znaków w a
K10: Zakończ
Program:
// Konwersja liczby na tekst
//--------------------------
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char a[20],x;
int p,W,r,c,d,i,j;
cout << "p = "; cin >> p;
cout << "W = "; cin >> W;
a[0] = '\0';
do
{
r = W % p;
W /= p;
if(r > 9) c = r + 55;
else c = r + 48;
d = strlen(a);
a[d] = c;
a[d+1] = '\0';
} while(W);
for(j = strlen(a)-1,i = 0; i < j; i++,j--)
{
x = a[i]; a[i]= a[j]; a[j] = x;
}
cout << endl << a << endl << endl;
return 0;
}
|
| p = 3 W = 7239 100221010 |
| p = 16 W = 7239 1C47 |
Dane wejściowe:
a – zmienna string, w której znajdzie się wynik przetwarzania
p – podstawa systemu docelowego 2...36
W – wartość liczby
Dane wyjściowe:
a – łańcuch znaków ASCII z reprezentacją liczby
Lista kroków:
K01: a.clear( )
K02: r ← reszta z W : p
K03: W ← W : p
K04: Jeśli r > 9,
to
c ← r + 55
inaczej
c ← r + 48
K05: a ← c + a
K06: Jeśli W > 0,
to idź do kroku K02
K07: Zakończ
Program:
// Konwersja liczby na tekst
//--------------------------
#include <iostream>
#include <string>
using namespace std;
int main()
{
string a;
int p,W,r;
char c;
cout << "p = "; cin >> p;
cout << "W = "; cin >> W;
a.clear();
do
{
r = W % p;
W /= p;
if(r > 9) c = r + 55;
else c = r + 48;
a = c + a;
} while(W);
cout << endl << a << endl << endl;
return 0;
}
|
| p = 4 W = 7239 1301013 |
| p = 12 W = 7239 4233 |
W C++ istnieje funkcja to_string( ) konwertująca liczby typu całkowitego i zmiennoprzecinkowego na łańcuch tekstowy string. Funkcja jako parametr przyjmuje dowolne wyrażenie liczbowe. Wynikiem jest łańcuch tekstowy reprezentujący wartość tego wyrażenia jako string. Uruchom program:
// Konwersja liczby na tekst
//--------------------------
#include <iostream>
#include <string>
using namespace std;
int main()
{
cout << to_string(1286) << endl
<< to_string(-3127-55) << endl
<< to_string(75.63) << endl
<< to_string(1.5e10) << endl << endl;
return 0;
}
|
| 1286 -3127 75.630000 15000000000.000000 |
Do czego taka funkcja może się nam przydać? Wyobraźmy sobie, iż chcemy wstawić do jakiegoś łańcucha tekstowego wiek użytkownika. Mamy trzy zmienne: imie (zmienna string, w której przechowywane jest imię użytkownika), wiek (zmienna int z jego wiekiem) oraz wynik (zmienna string, w której chcemy umieścić imię i wiek). Nie możemy tego zrobić tak:
wynik = imie + wiek;
Dlaczego? Ponieważ operator dodawania oznacza tutaj łączenie tekstów (konkatencję). A zmienna wiek nie jest tekstem, nie składa się ze znaków ASCII, tylko z binarnej wartości. Zatem komputer nie może połączyć jej z tekstem w zmiennej imie i otrzymamy błąd kompilacji. Musimy liczbę w zmiennej wiek przetworzyć na tekst, czyli ciąg znaków cyfr, które będą reprezentowały wartość tej liczby jako tekst. Do tego celu wykorzystamy właśnie funkcję to_string( ), która w wyniku zwraca odwołanie do bufora znakowego z cyframi wartości przekazanej w jej parametrze przy wywołaniu. Uruchom program:
// Konwersja liczby na tekst
//--------------------------
#include <iostream>
#include <string>
using namespace std;
int main()
{
setlocale(LC_ALL,"");
string imie("Małgorzata");
string wynik;
int wiek = 21;
wynik = imie + " ma lat "
+ to_string(wiek)
+ '.';
cout << wynik << endl << endl;
return 0;
}
|
Małgorzata ma lat 21. |
Wartość w liczby zapisanej ciągiem n cyfr c przy podstawie p obliczamy wg wzoru:
w = cn-1 · pn-1 + cn-2 · pn-2 + cn-3 · pn-3 + ... + c2 · p2 + c1 · p1 + c0 · p0
matematycznie:
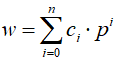
Indeksy przy cyfrach są numerami pozycji, na których te cyfry stoją w zapisie liczby. Pozycje numerujemy od 0 poczynając od ostatniej do pierwszej. Zauważ, iż numery pozycji są również wykładnikami potęgi podstawy. Tworzymy iloczyny cyfr przez podstawę podniesioną do potęgi numeru numeru pozycji cyfry, po czym te iloczyny sumujemy. Podstawa podniesiona do potęgi o wykładniku równym numerowi pozycji jest wagą tej pozycji:
| p = 10 | ||||
| wagi: | 103 | 102 | 101 | 100 |
| 1000 | 100 | 10 | 1 | |
| cyfry: | 7 | 8 | 5 | 3 |
| pozycje: | 3 | 2 | 1 | 0 |
785310 = 7 · 103 + 8 · 102 + 5 · 101 + 3 · 100 785310 = 7 · 1000 + 8 · 100 + 5 · 10 + 3 · 1 785310 = 7000 + 800 + 50 + 3 = 7852 |
Ta sama zasada obowiązuje dla wszystkich systemów pozycyjnych:
| p = 8 | ||||
| wagi: | 83 | 82 | 81 | 80 |
| 512 | 64 | 8 | 1 | |
| cyfry: | 6 | 7 | 5 | 3 |
| pozycje: | 3 | 2 | 1 | 0 |
67538 = 6 · 83 + 7 · 82 + 5 · 81 + 3 · 80 67538 = 6 · 512 + 7 · 64 + 5 · 8 + 3 · 1 67538 = 3072 + 448 + 40 + 3 = 356310 |
| p = 2 | ||||
| wagi: | 23 | 22 | 21 | 20 |
| 8 | 4 | 2 | 1 | |
| cyfry: | 1 | 1 | 0 | 1 |
| pozycje: | 3 | 2 | 1 | 0 |
11012 = 1 · 23 + 1 · 22 + 0 · 21 + 1 · 20 11012 = 1 · 8 + 1 · 4 + 0 · 1 + 1 · 1 11012 = 8 + 4 + 0 + 1 = 1310 |
| p = 16 | ||||
| wagi: | 163 | 162 | 161 | 160 |
| 4096 | 256 | 16 | 1 | |
| cyfry: | E | F | 8 | 4 |
| pozycje: | 3 | 2 | 1 | 0 |
E = 14; F = 15 EF8416 = 14 · 163 + 15 · 162 + 8 · 161 + 4 · 160 EF8416 = 14 · 4096 + 15 · 256 + 8 · 16 + 4 · 1 EF8416 = 57344 + 3840 + 128 + 4 = 6131610 |
Jednakże ten sposób obliczania wartości liczby pozycyjnej nie jest wygodny, ponieważ wymaga potęgowania. Załóżmy dla prostoty, iż nasza liczba składa się z 4 cyfr (zawsze będziemy to mogli później dowolnie rozszerzyć):
w = p3 · c3 + p2 · c2 + p1 · c1 + p0 · c0
Ponieważ p0 = 1, wzór możemy uprościć:
w = p3 · c3 + p2 · c2 + p1 · c1 + c0
Wyciągamy p przed nawias:
w = p · (p2 · c3 + p · c2 + c1) + c0
Ponownie wyciągamy p przed nawias:
w = p · (p · (p · c3 + c2) + c1) + c0
Potęgi zniknęły ze wzoru. Wartość liczby będziemy teraz obliczać krokowo. Na początku za w przyjmiemy wartość pierwszej cyfry:
w = c3
Teraz kolejno aż do wyczerpania wszystkich cyfr wykonujemy operację: w mnożymy przez p i dodajemy kolejną cyfrę liczby:
w = p · w + c2 = p · c3 + c2 w = p · w + c1 = p · (p · c3 + c2) + c1 w = p · w + c0 = p · (p · (p · c3 + c2) + c1) + c0
Zwróć uwagę, iż po wyczerpaniu cyfr otrzymaliśmy ten sam wzór.
Opisana metoda nosi nazwę schematu Hornera i była pierwotnie opracowana do efektywnego wyliczania wartości wielomianów. Zobaczmy, jak to działa:
p = 8, L = 67538 w = 6 w = 8 · 6 + 7 = 55 w = 8 · 55 + 5 = 445 w = 8 · 445 + 3 = 3563; ostatnia cyfra, kończymy. 67538 = 3563
p = 2; L = 11012 w = 1 w = 2 · 1 + 1 = 3 w = 2 · 3 + 0 = 6 w = 2 · 6 + 1 = 13 11012 = 13
p = 16; L = EF8416 w = 14 w = 16 · 14 + 15 = 239 w = 16 · 239 + 8 = 3832 w = 16 · 3832 + 4 = 61316 EF8416 = 61316
Doszliśmy do momentu, gdy możemy utworzyć algorytm obliczania wartości liczby pozycyjnej podanej w postaci ciągu znaków ASCII. Najpierw stworzymy funkcję, która przekształca znak ASCII cyfry w jej wartość. Ponieważ będzie się to odnosiło do systemów pozycyjnych o podstawach od 2 do 36, to cyframi mogą być znaki 0...9 oraz A...Z lub a...z. Zasada jest następująca:
Dane wejściowe: c – znak ASCII cyfry: 0...9 lub A...Z lub
a...z
Dane wyjściowe: wartość liczbowa cyfry c
Lista kroków: K01: Jeśli c ≤ '9', to zakończ z wynikiem c - 48 K02: Jeśli c ≤ 'Z', to zakończ z wynikiem c - 55 K03: Zakończ z wynikiem c - 87
Kod C++:
// Funkcja zamieniająca znak cyfry
// na jej wartość liczbową
//--------------------------------
int cyfra(char c)
{
if(c <= '9') return c - 48;
if(c <= 'Z') return c - 55;
return c - 87;
}
|
Dane wejściowe:
p – podstawa systemu pozycyjnego (2...36)
s – łańcuch tekstu zawierający cyfry liczby
cyfra( ) – funkcja zamieniająca znak cyfry w jej wartość liczbową
Dane wyjściowe:
w – wartość liczby
Lista kroków:
K01: w ← cyfra(s[0])
K02: i ← 1
K03: Dopóki s[i] ≠ 0:
wykonuj kroki K04..K05
K04: w ← p · w + cyfra(s[i])
K05: i ← i + 1
K06: Zakończ
Program C++ (tablica char)
// Zamiana łańcucha w liczbę
//--------------------------
#include <iostream>
using namespace std;
// Funkcja zamieniająca znak cyfry
// na jej wartość liczbową
//--------------------------------
int cyfra(char c)
{
if(c <= '9') return c - 48;
if(c <= 'Z') return c - 55;
return c - 87;
}
int main()
{
setlocale(LC_ALL,"");
char s[100]; // Tablica na cyfry liczby
int i, w, p;
cout << "Podstawa p = "; cin >> p;
cout << "Liczba L = "; cin >> s;
cout << endl;
// Schemat Hornera
w = cyfra(s[0]);
for(i = 1; s[i]; i++)
w = p * w + cyfra(s[i]);
cout << "Wartość L = " << w
<< endl << endl;
return 0;
}
|
| Podstawa p = 16 Liczba L = ef84 Wartość L = 61316 |
Program C++ (string)
// Zamiana łańcucha w liczbę
//--------------------------
#include <iostream>
#include <string>
using namespace std;
// Funkcja zamieniająca znak cyfry
// na jej wartość liczbową
//--------------------------------
int cyfra(char c)
{
if(c <= '9') return c - 48;
if(c <= 'Z') return c - 55;
return c - 87;
}
int main()
{
setlocale(LC_ALL,"");
string s; // Cyfry liczby
int i, w, p;
cout << "Podstawa p = "; cin >> p;
cout << "Liczba L = "; cin >> s;
cout << endl;
// Schemat Hornera
w = cyfra(s[0]);
for(i = 1; s[i]; i++)
w = p * w + cyfra(s[i]);
cout << "Wartość L = " << w
<< endl << endl;
return 0;
}
|
| Podstawa p = 2 Liczba L = 1101 Wartość L = 13 |
Przerób programy tak, aby potrafiły obliczać wartości liczb 64 bitowych bez znaku.
| Tekst: |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
| Szyfr |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
? |
? |
? |
Jak widzisz, szyfrowanie liter A...W nie sprawia problemu. Co jednak z literami X, Y i Z. Otóż umówmy się, iż alfabet szyfru zawija się i po literze Z znów mamy: A, B, C:
| Tekst: |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
| Szyfr |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
A |
B |
C |
Zatem X szyfrujemy jako A, Y jako B i Z jako C.
Zaszyfrujmy szyfrem Cezara tekst KROKODYL AREK:
| Tekst: |
K |
R |
O |
K |
O |
D |
Y |
L |
|
A |
R |
E |
K |
| Szyfr |
N |
U |
R |
N |
R |
G |
B |
O |
|
D |
U |
H |
N |
KROKODYL AREK → NURNRGBO DUHN
Tekst stał się nieczytelny. Przy rozszyfrowywaniu postępujemy odwrotnie: literę szyfru zastępujemy literą leżącą w alfabecie o trzy pozycje wcześniej. Tutaj podobnie musimy zawinąć alfabet, aby przed literą A znalazły się litery X, Y i Z:
| Szyfr |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
| Tekst: |
X |
Y |
Z |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
Otrzymaliśmy szyfr: DWDNXMHPB:
| Szyfr |
D |
W |
D |
N |
X |
M |
H |
P |
B |
| Tekst: |
A |
T |
A |
K |
U |
J |
E |
M |
Y |
DWDNXMHPB → ATAKUJEMY
Przejdźmy do szczegółów technicznych. Szyfrowanie będzie polegało na zamianie kodu ASCII znaku tekstu na kod ASCII znaku szyfru. Wykorzystamy operację modulo, ponieważ pozwoli ona nam zawijać kody liter.
Najpierw omówimy operacje dodawania i odejmowania modulo (reszta z dzielenia całkowitoliczbowego - operator %).
Operacja a % m (a modulo m) daje w wyniku resztę z dzielenia całkowitoliczbowego a przez m. Zakładamy, że a i m są liczbami nieujemnymi, a m jest większe od 0. Na przykład:
16 % 3 = 1
3 mieści się całkowitą liczbę razy 5 w 16:
3 × 5 = 15 i do 16 brakuje 1,
1 jest tym, co pozostaje po odjęciu 3 × 5 = 15 od 16. Dlatego nazywamy to resztą z dzielenia. Zobaczmy kilka przykładów:
10 % 3 = 1, bo 10 - 3 × 3 = 10 - 9 = 1 10 % 4 = 2, bo 10 - 2 × 4 = 10 - 8 = 2 10 % 5 = 0, bo 10 - 2 × 5 = 10 - 10 = 0 10 % 6 = 4, bo 10 - 1 × 6 = 10 - 6 = 4
Drugi argument operatora % nazywamy modułem. Reszta z dzielenia jest zawsze mniejsza od modułu. Dlaczego? Bo gdyby była równa lub większa, to by oznaczało, iż moduł mieści się więcej razy w dzielonej liczbie. Zobaczmy wszystkie reszty z dzielenia różnych liczb przez moduł m = 6:
13 % 6 = 1 (13 - 2 × 6 = 13 - 12 = 1) 20 % 6 = 2 (20 - 3 × 6 = 20 - 18 = 2) 27 % 6 = 3 (27 - 4 × 6 = 27 - 24 = 3) 34 % 6 = 4 (34 - 5 × 6 = 34 - 30 = 4) 41 % 6 = 5 (41 - 6 × 6 = 41 - 36 = 5) 48 % 6 = 0 (48 - 6 × 8 = 48 - 48 = 0)
Reszta z dzielenia może przyjąć wartości: a % m = 0 ... m - 1.
Reszta z dzielenia jest równa 0, gdy moduł m dzieli a całkowitą liczbę razy.
Jeśli pierwszym argumentem operatora % jest wyrażenie a + b, a i b nieujemne, to wynikiem będzie liczba mniejsza od modułu:
(a + b) % m = 0 ... m - 1
Dodawanie poddane działaniu reszty z dzielenia nazywamy dodawaniem modulo. Zobaczmy kilka przykładów:
...
(5 + 3) % 10 = 8
(6 + 3) % 10 = 9
(7 + 3) % 10 = 0
(8 + 3) % 10 = 1
(9 + 3) % 10 = 2
...
Jak to zastosować do szyfrowania szyfrem Cezara? Prześledź poniższe wyprowadzenie:
Mamy kod znaku tekstu t. Ma on zakres od 65 (A) do 90 (Z). Najpierw kod ten zmieniamy tak, aby otrzymać wartości 0...25:
t' ← t - 65
Za moduł przyjmujemy liczbę 26 – to liczba liter A ... Z.
Teraz dodajemy 3, czyli przesuwamy się o 3 pozycje do przodu. W wyniku dostaniemy wartości 3...28:
t" ← t' + 3
Jest to nasza suma, poddajemy ją operacji modulo 26. W ten sposób wartości równe lub większe od modułu (czyli 26...28) wrócą na początek 0...2:
t''' ← t" % 26
I wracamy z powrotem do kodu ASCII:
t'''' ← t''' + 65
Złóżmy to w jedno wyrażenie i otrzymamy wzór na kod znaku szyfru Cezara c:
c ← (t - 65 + 3) % 26 + 65 c ← (t - 62) % 26 + 65
Sprawdźmy:
t = kod(G) = 71 c = (71 - 62) % 26 + 65 c = 9 % 26 + 65 c = 9 + 65 c = 74 : kod litery J
t = kod(Y) = 89 c = (89 - 62) % 26 + 65 c = 27 % 26 + 65 c = 1 + 65 c = 66 : kod litery B
Jeśli pierwszym argumentem operatora % będzie wyrażenie a - b, a i b nieujemne, to wynikiem jest:
(a - b) % m = -m + 1 ... m - 1
Aby pozbyć się wartości ujemnych, do różnicy dodajemy m:
(a - b + m) % m = 0 ... m - 1
Jest to prawdziwe, gdy |a - b| < m.
Sprawdźmy, m = 10:
...
(0 - 3 + 10) % 10 = 7
(1 - 3 + 10) % 10 = 8
(2 - 3 + 10) % 10 = 9
(3 - 3 + 10) % 10 = 0
(4 - 3 + 10) % 10 = 1
...
Tutaj postępujemy podobnie, mamy kod znaku szyfru c, który jest literą ASCII o kodzie 65...90. Kod sprowadzamy do przedziału 0...25:
c' ← c - 65
Odejmujemy 3, aby przesunąć kod o 3 pozycje w tył. Otrzymujemy wynik w przedziale -3..22. Do wyniku odejmowania dodajemy moduł 26, aby zniwelować ewentualną wartość ujemną. Otrzymamy wynik w przedziale 23...48:
c" ← c' - 3 + 26 c" ← c' + 23
Teraz operacja reszty z dzielenia przez 26 da nam wynik w przedziale 0...25:
c''' ← c'' % 26
Wracamy do kodu ASCII:
c'''' ← c''' + 65
Składamy wzór:
t = (c - 65 - 3 + 26) % 26 + 65 t = (c - 42) % 26 + 65
Sprawdźmy:
c = Kod(G) = 71 t = (71 - 42) % 26 + 65 t = 29 % 26 + 65 t = 3 + 65 t = 68 : kod litery D
c = Kod(B) = 66 t = (66 - 42) % 26 + 65 t = 24 % 26 + 65 t = 24 + 65 t = 89 : kod litery Y
t - kod ASCII znaku tekstu
c - kod ASCII znaku szyfru Cezara
Szyfrowanie: c ← (t - 62) % 26 + 65
Rozszyfrowywanie: t = (c - 42) % 26 + 65
Teraz jesteśmy gotowi do konstrukcji algorytmu. Umówmy się, iż pierwszy znak tekstu na pozycji 0 będzie informował o operacji, którą należy wykonać. Jeśli znakiem będzie 1, to tekst zostanie zaszyfrowany począwszy od znaku na pozycji 1. Jeśli będzie to dowolny inny znak, to tekst będzie rozszyfrowywany.
Dane wejściowe:
S -tekst do szyfrowania/rozszyfrowania. S[0] oznacza operację do
wykonania: S[0] = '1' - szyfrowanie, S[0] ≠ '1' - rozszyfrowywanie
Dane
wyjściowe:
S - tekst przetworzony
Lista kroków:
K01: i ← 1
K02: Dopóki S[i] ≠ 0:
wykonuj kroki K03...K05
K03: Jeśli S[i] < 'A' lub S[i] > 'Z,
to idź do kroku K05
K04: Jeśli S[0] = '1',
to S[i] ← (S[i] - 62) % 26 + 65
Inaczej S[i] ← (S[i] - 42) % 26 + 65
K05: i ← i + 1
K06: Zakończ
Program C++:
// Szyfr Cezara
//--------------------------
#include <iostream>
#include <string>
using namespace std;
int main()
{
setlocale(LC_ALL,"");
string S;
int i;
cout << "Wpisz poniżej tekst:" << endl;
getline(cin,S);
cout << endl;
for(i = 1; S[i]; i++)
if((S[i] >= 'A') && (S[i] <= 'Z'))
{
if(S[0] == '1')
S[i] = (S[i] - 62) % 26 + 65;
else
S[i] = (S[i] - 42) % 26 + 65;
}
if(S[0] == '1') S[0] = '0';
else S[0] = '1';
cout << S << endl << endl;
return 0;
}
|
Wpisz poniżej tekst: 1ALA MA BOCIANA I DWA SZARE SZCZURKI 0DOD PD ERFLDQD L GZD VCDUH VCFCXUNL |
Wpisz poniżej tekst: 0DOD PD ERFLDQD L GZD VCDUH VCFCXUNL 1ALA MA BOCIANA I DWA SZARE SZCZURKI |
Opisany tutaj algorytm szyfru Cezara nie jest jedynym. Zaprojektuj go tak, aby nie było w nim operacji reszty z dzielenia. Wykorzystaj instrukcję warunkową i operatory porównań.
Program wykorzystuje klasę string. Zmień program tak, aby korzystał z tablicy char o odpowiedniej pojemności. Zwróć uwagę, iż specjalnie nie użyto żadnej funkcji składowej klasy string, dzięki czemu konwersja będzie prosta.
Najprostszym przykładem szyfru przestawieniowego jest utworzenie tekstu wspak, czyli w odwrotnej kolejności:
AREK → KERA KERA → AREK
Zwróć uwagę, iż taki szyfr jest symetryczny, z tekstu jawnego otrzymujemy szyfr, a z szyfru tekst jawny.
Cechą charakterystyczną szyfrów przestawieniowych jest to, iż szyfrogram zawiera te same znaki, co tekst jawny, lecz ustawione w innej kolejności.
Odwracanie wspak będzie polegało na zamianie liter: pierwsza z ostatnią, druga z przedostatnią i tak dalej, aż dojdziemy do połowy tekstu. Dalej liter nie zamieniamy, gdyż są one już zamienione.
Dane wejściowe: s: tekst do zaszyfrowania/rozszyfrowania
Dane wyjściowe: s: tekst zaszyfrowany/rozszyfrowany
Lista kroków:
K01: i ← 0
K02: j ← długość tekstu s - 1
K03: Dopóki i < j:
wykonuj kroki K04...K06
K04 Zamień miejscami s[i] z s[j]
K05: i ← i + 1
K06: j ← j - 1
K07: Zakończ
Program C++ dla cstring
// Szyfr przestawieniowy #1
//-------------------------
#include <iostream>
#include <cstring>
using namespace std;
void PL(char * t)
{
while(*t)
{
switch((unsigned char)*t)
{
case 164 : *t = 165; break;
case 143 : *t = 198; break;
case 168 : *t = 202; break;
case 157 : *t = 163; break;
case 227 : *t = 209; break;
case 224 : *t = 211; break;
case 151 : *t = 140; break;
case 141 : *t = 143; break;
case 189 : *t = 175; break;
case 165 : *t = 185; break;
case 134 : *t = 230; break;
case 169 : *t = 234; break;
case 136 : *t = 179; break;
case 228 : *t = 241; break;
case 162 : *t = 243; break;
case 152 : *t = 156; break;
case 171 : *t = 159; break;
case 190 : *t = 191; break;
default : break;
}
t++;
}
}
int main()
{
char s[100],x;
int i,j;
setlocale(LC_ALL,"");
cout << "Wpisz tekst poniżej:" << endl << endl;
cin.getline(s ,100); PL(s); // Odczytujemy tekst
cout << endl;
for(i = 0, j = strlen(s)-1; i < j; i++,j--)
{
x = s[i]; s[i] = s[j]; s[j] = x;
}
cout << s << endl << endl;
return 0;
}
|
Wpisz tekst poniżej: Krokodyl Arek lubi naleśniki z truskawkami na śniadanie einadainś an imakwaksurt z ikinśelan ibul kerA lydokorK |
Wpisz tekst poniżej: einadainś an imakwaksurt z ikinśelan ibul kerA lydokorK Krokodyl Arek lubi naleśniki z truskawkami na śniadanie |
Program C++ dla string
// Szyfr przestawieniowy #1
//-------------------------
#include <iostream>
#include <string>
using namespace std;
void PL(string & t)
{
unsigned i,len = t.length();
for(i = 0; i < len; i++)
switch((unsigned char) t[i])
{
case 164 : t[i] = 165; break;
case 143 : t[i] = 198; break;
case 168 : t[i] = 202; break;
case 157 : t[i] = 163; break;
case 227 : t[i] = 209; break;
case 224 : t[i] = 211; break;
case 151 : t[i] = 140; break;
case 141 : t[i] = 143; break;
case 189 : t[i] = 175; break;
case 165 : t[i] = 185; break;
case 134 : t[i] = 230; break;
case 169 : t[i] = 234; break;
case 136 : t[i] = 179; break;
case 228 : t[i] = 241; break;
case 162 : t[i] = 243; break;
case 152 : t[i] = 156; break;
case 171 : t[i] = 159; break;
case 190 : t[i] = 191; break;
default : break;
}
}
int main()
{
string s;
int i,j;
setlocale(LC_ALL,"");
cout << "Wpisz tekst poniżej:" << endl << endl;
getline(cin ,s); PL(s); // Odczytujemy tekst
cout << endl;
for(i = 0, j = s.length() - 1; i < j; i++,j--)
swap(s[i],s[j]);
cout << s << endl << endl;
return 0;
}
|
Wpisz tekst poniżej: Ala ma miśka akśim am alA |
Kolejny szyfr polega na podziale tekstu na kolejne pary znaków i przestawienie znaków w każdej parze:
Kubuś Puchatek (Ku)(bu)(ś )(Pu)(ch)(at)(ek) (uK)(un)( ś)(uP)(hc)(ta)(ke) uKun śuPhctake
Jeśli w ostatniej parze brakuje znaku (jeśli tekst posiada nieparzystą liczbę znaków), to nie przestawiamy w niej liter. Szyfr jest symetryczny i rozszyfrowanie polega na powtórzeniu operacji szyfrowania.
Dane wejściowe: s: tekst do zaszyfrowania/rozszyfrowania
Dane wyjściowe: s: tekst zaszyfrowany/rozszyfrowany
Lista kroków:
K01: n ← długość s
K02: Jeśli n jest nieparzyste,
to n ← n - 1
K03: i ← 1
K04: Dopóki i < n:
wykonuj kroki K05...K06
K05: s[i] ↔ S[i - 1]
K06: i ← i + 2
K07: Zakończ
Program C++ dla cstring
// Szyfr przestawieniowy #2
//-------------------------
#include <iostream>
#include <cstring>
using namespace std;
void PL(char * t)
{
while(*t)
{
switch((unsigned char)*t)
{
case 164 : *t = 165; break;
case 143 : *t = 198; break;
case 168 : *t = 202; break;
case 157 : *t = 163; break;
case 227 : *t = 209; break;
case 224 : *t = 211; break;
case 151 : *t = 140; break;
case 141 : *t = 143; break;
case 189 : *t = 175; break;
case 165 : *t = 185; break;
case 134 : *t = 230; break;
case 169 : *t = 234; break;
case 136 : *t = 179; break;
case 228 : *t = 241; break;
case 162 : *t = 243; break;
case 152 : *t = 156; break;
case 171 : *t = 159; break;
case 190 : *t = 191; break;
default : break;
}
t++;
}
}
int main()
{
char s[100];
int i,n;
setlocale(LC_ALL,"");
cout << "Wpisz tekst poniżej:" << endl << endl;
cin.getline(s ,100); PL(s); // Odczytujemy tekst
cout << endl;
n = strlen(s); // Liczba znaków tekstu
if(n % 2) n--; // n w liczbę parzystą
for(i = 1; i < n; i += 2)
swap(s[i], s[i - 1]); // Zamiana
cout << s << endl << endl;
return 0;
}
|
Wpisz tekst poniżej: Miś Puchatek i Prosiaczek to dwaj dobrzy przyjaciele iM śuPhctakei P oriscaez kotd aw jodrbyzp zrjycaeiel |
Wpisz tekst poniżej: iM śuPhctakei P oriscaez kotd aw jodrbyzp zrjycaeiel Miś Puchatek i Prosiaczek to dwaj dobrzy przyjaciele |
Program C++ dla string
// Szyfr przestawieniowy #2
//-------------------------
#include <iostream>
#include <string>
using namespace std;
void PL(string & t)
{
unsigned i,len = t.length();
for(i = 0; i < len; i++)
switch((unsigned char) t[i])
{
case 164 : t[i] = 165; break;
case 143 : t[i] = 198; break;
case 168 : t[i] = 202; break;
case 157 : t[i] = 163; break;
case 227 : t[i] = 209; break;
case 224 : t[i] = 211; break;
case 151 : t[i] = 140; break;
case 141 : t[i] = 143; break;
case 189 : t[i] = 175; break;
case 165 : t[i] = 185; break;
case 134 : t[i] = 230; break;
case 169 : t[i] = 234; break;
case 136 : t[i] = 179; break;
case 228 : t[i] = 241; break;
case 162 : t[i] = 243; break;
case 152 : t[i] = 156; break;
case 171 : t[i] = 159; break;
case 190 : t[i] = 191; break;
default : break;
}
}
int main()
{
string s;
int i,n;
setlocale(LC_ALL,"");
cout << "Wpisz tekst poniżej:" << endl << endl;
getline(cin ,s); PL(s); // Odczytujemy tekst
cout << endl;
n = s.length();
if(n % 2) n--; // n w liczbę parzystą
for(i = 1; i < n; i += 2)
swap(s[i], s[i - 1]); // Zamiana
cout << s << endl << endl;
return 0;
}
|
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
