|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|

Mikroprocesor komputera komunikuje się z pamięcią poprzez złącza, które są widoczne u spodu modułu pokazanego na obrazku powyżej. Oczywiście nie będziemy wchodzić w szczegóły techniczne, wyjaśnimy jedynie podstawy działania pamięci.
Bity przechowywane w pamięci są zorganizowane w grupy po 8 bitów, które nazywamy bajtami. Bajty przechowywane są w numerowanych komórkach. Numery komórek nazywamy adresami. Wygląda to następująco:

Komórek w pamięci jest bardzo dużo (współcześnie miliardy), adresy są zatem zwykle duże. W języku C++ przyjęto, że adres 0 (NULL) nie wskazuje żadnej komórki. Oczywiście fizyczna komórka o adresie 0 może istnieć w przestrzeni adresowej komputera, ale w C++ nie jest używana.
Mikroprocesor komunikuje się z pamięcią za pomocą tzw. magistral (ang. buses). Magistrala jest grupą linii sygnałowych (linie sygnałowe przenoszą sygnały - w przypadku współczesnych komputerów są to sygnały binarne kodowane napięciami: 5V stan wysoki 1, 0V stan niski 0).
Mamy trzy rodzaje magistral:
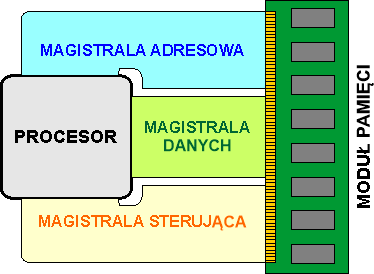
Powyższy rysunek przedstawia sposób dostępu mikroprocesora do modułu pamięci za pomocą magistral. Nie sugeruj się grubością magistral – to tylko schemat poglądowy.
Magistralą adresową mikroprocesor przekazuje adres komórki pamięci, do której chce uzyskać dostęp. Adres jest w postaci dwójkowej, a każda linia magistrali przekazuje 1 bit tego adresu. Od liczby linii adresowych zależy rozmiar przestrzeni adresowej, czyli liczby komórek, które procesor jest w stanie zaadresować. Przestrzeń ta we współczesnych komputerach sięga wielu gigabajtów (miliardów komórek).
Magistrala danych jest dwukierunkowa, tzn. mogą nią biegnąć informacje od procesora do pamięci lub odwrotnie. Dane są binarne. Szerokość magistrali zależy od fizycznych parametrów komputera, współcześnie jest to zwykle 64 bity (w mikroprocesorach 64 bitowych).
Magistrala sterująca określa tryb pracy pamięci: odczyt lub zapis danych. Składa się najczęściej tylko z kilku linii sterujących.
Teraz krótko opiszemy uproszczony sposób pracy pamięci komputerowej (w rzeczywistości jest to dużo bardziej skomplikowane).
Gdy procesor potrzebuje zapisać informację w pamięci, wykonuje następujące czynności:
Gdy mikroprocesor potrzebuje odczytać informację z pamięci, wykonuje następujące czynności:
Jeśli chcesz poznać więcej informacji na temat pamięci, to przeczytaj osobny artykuł w naszym serwisie:
Program komputerowy składa się z ciągu instrukcji umieszczonych w pamięci operacyjnej. Mikroprocesor wykonując program adresuje te instrukcje i pobiera je z komórek pamięci, po czym rozpoznaje pobraną instrukcję i wykonuje określoną przez nią operację.
Jeśli chciałbyś głębiej poznać to zagadnienie i pobawić się prostym komputerem, to proponuję przejść do artykułu "Przykładowa Maszyna Cyfrowa II".
Gdy w programie zostaje napotkane wywołanie funkcji, mikroprocesor wykonuje "skok" do adresu zawierającego pierwszą instrukcję tej funkcji i rozpoczyna wykonywanie jej kodu. Ale pojawia się tutaj problem. Po wykonaniu kodu funkcji procesor powinien powrócić do miejsca za wywołaniem. Ponieważ funkcja może być wielokrotnie wywoływana w różnych miejscach programu, adresy powrotu będą różne. Należy je zatem zapamiętać. Do tego celu służy właśnie stos (ang. stack). Jest to struktura danych tworzona przez procesor w pamięci komputera. Możesz ją sobie wyobrazić jako stos książek. Gdy wstawiamy coś na stos, to trafia to na szczyt. Gdy pobieramy coś ze stosu, to bierzemy kolejno ze szczytu.
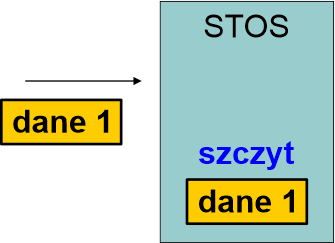
Przykład: Zapisujemy na stosie trzy dane: kolejno dane 1, dane 2 i dane 3.

Dane 1 trafią na szczyt stosu. Szczyt przesunie się w pamięci.
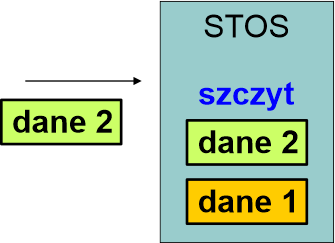
Dane 2 również trafią na szczyt stosu, czyli znajdą się ponad danymi 1.
Dane 3 trafiają na szczyt stosu. Zwróć uwagę, iż na stosie są one w odwrotnej kolejności:
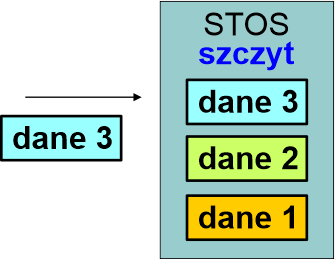
Jeśli teraz pobierzemy kolejno dane ze szczytu stosu, to otrzymamy je w odwrotnej kolejności:

Zauważ, iż na szczycie stosu znajduje się zawsze dana, która została tam umieszczona ostatnio. Do czego to się przydaje? Otóż zastosowanie stosu jest ogromne. Na stosie umieszczane są nie tylko adresy powrotne, ale również zmienne lokalne, parametry i wyniki funkcji. Jak to wygląda?
Gdy w programie komputer napotyka wywołanie funkcji, umieszcza na stosie parametry funkcji oraz adres powrotny, który wskazuje następną instrukcję w programie za wywołaniem funkcji. Następnie procesor wykonuje skok do kodu funkcji, który może zarezerwować na stosie miejsce na zmienne lokalne, jeśli kod funkcji takie zawiera. Wykonany jest kod funkcji. Gdy kod jest zakończony, procesor usuwa ze stosu wszystkie zmienne lokalne (dlatego przestają one istnieć w programie). Na stos jest przesyłany wynik funkcji (jeśli taki jest), po czym procesor wykonuje skok pod adres powrotny, który wskazuje kod programu wywołującego funkcję (tuż za jej wywołaniem). Kod ten pobiera wynik i usuwa wszystkie dane, które trafiły na stos przy wywołaniu funkcji, w ten sposób stos zostaje wyczyszczony i jest gotowy na kolejne wywołanie.
Jeśli w trakcie wykonywania funkcji wystąpi kolejne wywołanie funkcji, to jej dane trafią na szczyt stosu ponad danymi funkcji podstawowej. Dzięki temu nie będą się nawzajem zakłócać. Przeanalizujmy prosty program:
// Rekurencja
//----------------
#include <iostream>
using namespace std;
void f(int a)
{
cout << "Poziom: " << a << endl;
if(a < 9) f(a + 1);
}
int main()
{
f(0);
return 0;
}
|
Poziom: 0 Poziom: 1 Poziom: 2 Poziom: 3 Poziom: 4 Poziom: 5 Poziom: 6 Poziom: 7 Poziom: 8 Poziom: 9 |
W programie znajduje się pojedyncza funkcja z jednym parametrem:
void f(int a)
{
cout << "Poziom: " << a << endl;
if(a < 9) f(a);
}
Funkcja wyświetla wartość parametru, następnie sprawdza jego wartość i jeśli parametr jest mniejszy od 9, ponownie wywołuje samą siebie lecz z parametrem zwiększonym o 1. Nic skomplikowanego, jak widać. Teraz przeanalizujmy zawartość stosu w czasie pracy tego programu.
Zaczynamy od funkcji głównej, w której jest wywołanie funkcji f( ) z parametrem 0: Na stos trafia adres powrotny z f( ) do main( ) oraz parametr 0:
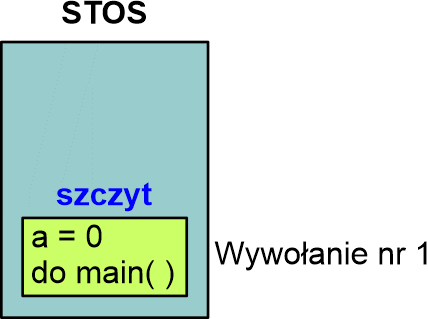
Następnie komputer przechodzi do kodu funkcji f( ) i zaczyna go wykonywać. Wypisuje w oknie konsoli wartość parametru, po czym sprawdza, czy parametr jest mniejszy od 9. Przy pierwszym wywołaniu parametr a ma wartość 0, zatem warunek a < 9 jest prawdziwy i instrukcja if wywoła funkcję f( ) z parametrem zwiększonym o 1. Ponieważ jest to wywołanie z kodu funkcji f( ) to na szczyt stosu trafi nowy adres powrotny oraz parametr a = 1. Stos będzie wyglądał następująco:
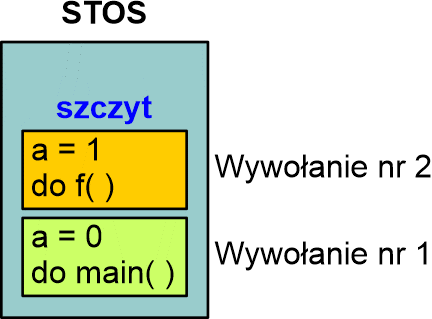
Zwróć uwagę, iż poprzednie dane są wciąż na stosie, ponieważ funkcja f( ) wywołana z main( ) nie zakończyła jeszcze pracy, lecz wywołała samą siebie. Nastąpiło tzw. wywołanie zagnieżdżone (ang. nested call). Komputer wykonuje kod funkcji f( ) z nowym parametrem a = 1. Zauważ, iż przy takim wywołaniu kod funkcji f( ) jest taki sam, lecz dane na stosie są inne, dlatego funkcja może się wykonywać inaczej. Po wypisaniu parametru a sprawdzana jest jego wartość przez instrukcję if i jeśli jest wciąż mniejsza od 9, to nastąpi kolejne wywołanie zagnieżdżone f( ) z parametrem o 1 większym, czyli 2. Stos będzie wyglądał następująco:

Proces ten będzie kontynuowany, aż do wywołania f( ) z parametrem 9. Stos przyjmie wtedy postać:

Co stanie się teraz? Jesteśmy na 10 wywołaniu funkcji f( ), a parametr a = 9. Funkcja wyświetli wartość parametru w oknie konsoli, po czym nastąpi przejście do instrukcji warunkowej if. Tym razem warunek a < 9 będzie fałszywy i instrukcja if nie dokona kolejnego wywołania funkcji f( ). Bieżąca funkcja f( ) zakończy działanie. Komputer wróci za miejsce wywołania tej funkcji na niższy poziom, po czym usunie ze stosu adres powrotny i dane. Stos będzie wyglądał następująco:

Wciąż program znajduje się w funkcji f( ) w tym miejscu:
... if(a < 9) f(a + 1);X ^
a zatem na końcu funkcji f( ). Ponieważ nie ma dalszych instrukcji, funkcja f( ) kończy działanie i wraca za miejsce wywołania na niższy poziom, a dane ze stosu są usuwane. Proces ten będzie kontynuowany, aż do powrotu do funkcji głównej main( ), po czym program zakończy się.
// Rekurencja nieskończona
//------------------------
#include <iostream>
using namespace std;
void f(void)
{
f();
}
int main()
{
f();
return 0;
}
|
Process returned -1073741571 (0xC00000FD) |
Co się stało? W pewnym momencie system przerywa wykonywanie tego programu i zwraca kod błędu 0xC00000FD. Sprawdźmy, co oznacza ten błąd:
0xC00000FD - STACK OVERFLOW (przepełnienie stosu)
Stos został w całości zapełniony adresami powrotnymi i przy kolejnym wywołaniu funkcji f( ) komputer nie mógł już zapisać na stosie jej adresu powrotnego. Dlatego program zakończył się z błędem. Na to musimy uważać przy rekurencji.
Po co nam rekurencja? Otóż okazuje się, iż wiele problemów upraszcza się przy jej zastosowaniu. Na przykład policzmy rekurencyjnie silnię. Definicja jest rekurencyjna:

Jak to odczytać? Prosto: 0! = 1, natomiast dla argumentów większych lub równych 1: n! = n · (n - 1)! Widzisz tutaj rekurencję? Spróbujmy obliczyć 6! wg definicji:
6! = 6 · (6 - 1)! = 6 · 5!
Teraz rozwijamy kolejne silnie, aż dojdziemy do przypadku 0!:
6! = 6·(5·4!) = 6·5·4! 6! = 6·5·(4·3!) = 6·5·4·3! 6! = 6·5·4·(3·2!) = 6·5·4·3·2! 6! = 6·5·4·3·(2·1!) = 6·5·4·3·2·1! 6! = 6·5·4·3·2·(1·0!) = 6·5·4·3·2·1·1 = 720
Tworząc funkcję rekurencyjną, najpierw sprawdzamy warunek zakończenia rekurencji, a dopiero później wywołujemy rekurencyjnie funkcję, ale ze zmienionym argumentem. W przeciwnym razie ryzykujemy wpadnięcie w nieskończoną rekurencję, co zakończy się błędem przepełnienia stosu.
Przeanalizujmy poniższy program:
// Rekurencja
// Silnia
//------------
#include <iostream>
using namespace std;
unsigned long long silnia(unsigned n)
{
// Sprawdzamy warunek wyjścia z rekurencji
if(!n) return 1;
// Wchodzimy w rekurencję
return n * silnia(n - 1);
}
int main()
{
int n;
cout << "Obliczanie silni" << endl
<< "----------------" << endl << endl
<< "n = ";
cin >> n;
cout << endl
<< "silnia(" << n << ") = "
<< silnia(n) << endl << endl;
return 0;
}
|
Obliczanie silni ---------------- n = 15 silnia(15) = 1307674368000 |
Program składa się z funkcji silnia( ), która wylicza rekurencyjnie wartość silni. Funkcja jest wywoływana z paramem typu unsigned, czyli całkowitym w 32-bitowym kodzie BNC. Funkcja zwraca wartość typu unsigned long long, czyli całkowitą BNC 64-bitową. Silnia rośnie bardzo szybko i wynik obliczeń przekracza zakres liczb 64-bitowych BNC już dla niewielkich wartości parametru:
Zakres 64-bitowych liczb BNC: 0... |
18'446'744'073'709'551'615 |
|
19! = |
121'645'100'408'832'000 |
OK |
20! = |
2'432'902'008'176'640'000 |
OK |
21! = |
51'090'942'171'709'440'000 |
za dużo
|
Dla parametru n =21 program zwróci bladną wartość (14197454024290336768), ponieważ wynik nie mieści się w 64-bitowej liczbie NBC i zostaje obcięty do ostatnich 64 bitów. Jeśli tego nie rozumiesz, wróć do początkowych rozdziałów o kodowaniu liczb.
Funkcja silnia( ) składa się z dwóch części. W pierwszej sprawdzamy warunek zakończenia rekurencji, czyli czy parametr n jest równy 0:
if(!n) return 1;
W takim przypadku funkcja kończy działanie i zwraca jako wynik wartość 1. Nie występuje tutaj wywołanie rekurencyjne.
W drugiej części pojawia się rekurencja:
return n * silnia(n - 1);
Zanim funkcja zakończy działanie i zwróci wynik, wywołuje samą siebie z parametrem n mniejszym o 1. Wynik nie zostanie zwrócony, aż wywołana funkcja nie wyliczy (n - 1)! W wywołanej funkcji występuje ten sam proces i silnia( ) jest rekurencyjnie wykonywana aż do osiągnięcia przez parametr wartości 0. Wtedy wywołania rekurencyjne kończą się i następują powroty z kolejnymi wartościami silni aż do poziomu podstawowego, w którym wyliczana jest ostateczna wartość silni i zwracana do programu głównego. Wygląda to następująco:
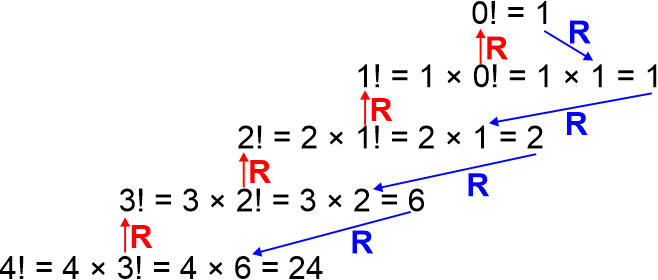
Kolorem czerwonym są oznaczone wywołania rekurencyjne, kolorem niebieskim są oznaczone powroty z wywołań rekurencyjnych z wynikiem funkcji. Z tego diagramu widać wyraźnie, iż funkcja podstawowa zakończy działanie dopiero po powrotach ze wszystkich wywołań rekurencyjnych. Przeanalizuj to dokładnie, aż wszystko będzie dla ciebie zrozumiałe.
Dane wejściowe: dwie nieujemne liczby całkowite a i b.
Dane wyjściowe: a = NWD liczb a i b.
K01: Dopóki b ≠ 0,
wykonuj kroki K02...K04
K02: r ← a mod b
K03: a ← b
K04: b ← r
K05: Zakończ
Przyjrzyj się dokładnie temu algorytmowi. Zapiszmy go w nieco innej postaci, która jest równoważna:
K01: Jeśli b = 0,
to zakończ z wynikiem a
K02: r ← a mod b
K03: a ← b
K04: b ← r
K05: Wróć do kroku K01
Zwróć uwagę, iż znalezienie NWD wymaga wykonania cyklicznego tych samych operacji, aż do wykrycia, iż b = 0. Wtedy wykonywanie jest przerywane, a wynik znajduje się w a. Taką postać algorytmu da się łatwo przetworzyć na postać rekurencyjną:

Jeśli b = 0, to wynikiem jest a. W przeciwnym razie wynikiem jest NWD z parametrem a zamienionym na b, i parametrem b zamienionym na resztę z dzielenia a przez b.
Uruchom program:
// Rekurencja
// Algorytm Euklidesa
//-------------------
#include <iostream>
using namespace std;
unsigned NWD(unsigned a, unsigned b)
{
// Sprawdzamy warunek wyjścia z rekurencji
if(!b) return a;
// Wchodzimy w rekurencję
return NWD(b, a % b);
}
int main()
{
unsigned a,b;
cout << "Obliczanie NWD" << endl
<< "--------------" << endl << endl
<< "a b = ";
cin >> a >> b;
cout << endl
<< "NWD(" << a << "," << b << ") = "
<< NWD(a,b) << endl << endl;
return 0;
}
|
Obliczanie NWD -------------- a b = 36 24 NWD(36,24) = 12 |
W algorytmie wyjściowym występowała pętla, którą zastąpiliśmy rekurencją. Wersja rekurencyjna jest zwykle wolniejsza i zajmuje więcej pamięci (dlaczego?).

Dwie pierwsze liczby to kolejno 0 i 1. Każda następna jest sumą dwóch poprzedzających. Otrzymujemy ciąg:
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 ...
Ciąg Fibonacciego jest ciekawy dlatego, iż jego implementacja rekurencyjna daje bardzo pouczający przykład, iż w pewnych sytuacjach rekurencja może prowadzić do bardzo nieefektywnego algorytmu. Uruchom poniższy program:
// Rekurencja
// Ciąg Fibonacciego
//------------------
#include <iostream>
#include <iomanip>
using namespace std;
unsigned long long fib(unsigned i)
{
// Sprawdzamy warunek wyjścia z rekurencji
if(i <= 1) return i;
// Wchodzimy w rekurencję
return fib(i - 2) + fib(i - 1);
}
int main()
{
unsigned i;
cout << "Obliczanie Liczb Fibonacciego" << endl
<< "-----------------------------" << endl << endl;
for(i = 0; i <= 50; i++)
cout << "fib(" << setw(2) << i << ") = "
<< setw(11) << fib(i) << endl;
cout << endl;
return 0;
}
|
Obliczanie Liczb Fibonacciego ----------------------------- fib( 0) = 0 fib( 1) = 1 fib( 2) = 1 fib( 3) = 2 fib( 4) = 3 fib( 5) = 5 fib( 6) = 8 fib( 7) = 13 fib( 8) = 21 fib( 9) = 34 fib(10) = 55 fib(11) = 89 fib(12) = 144 fib(13) = 233 fib(14) = 377 fib(15) = 610 fib(16) = 987 fib(17) = 1597 fib(18) = 2584 fib(19) = 4181 fib(20) = 6765 fib(21) = 10946 fib(22) = 17711 fib(23) = 28657 fib(24) = 46368 fib(25) = 75025 fib(26) = 121393 fib(27) = 196418 fib(28) = 317811 fib(29) = 514229 fib(30) = 832040 fib(31) = 1346269 fib(32) = 2178309 fib(33) = 3524578 fib(34) = 5702887 fib(35) = 9227465 fib(36) = 14930352 fib(37) = 24157817 fib(38) = 39088169 fib(39) = 63245986 fib(40) = 102334155 fib(41) = 165580141 fib(42) = 267914296 fib(43) = 433494437 fib(44) = 701408733 fib(45) = 1134903170 fib(46) = 1836311903 fib(47) = 2971215073 fib(48) = 4807526976 fib(49) = 7778742049 fib(50) = 12586269025 Process returned 0 (0x0) execution time : 297.294 s |
Przy wykonaniu programu zwróć uwagę na czas wyznaczania kolejnych liczb Fibonacciego. Pierwsze kilkadziesiąt program wyznacza szybko. Problemy pojawiają się przy fib(40) i dalszych? Dlaczego? Otóż tutaj musimy napisać kilka słów o tzw. złożoności obliczeniowej (ang. computational complexity).
Komputer udostępnia dwa zasoby: szybkość obliczeń oraz pojemność pamięci. Złożoność obliczeniowa służy do określania zapotrzebowania algorytmu na te zasoby komputera. Wyraża się dwoma parametrami: złożonością czasową (ang. time complexity) oraz złożonością pamięciową (ang. space complexity).
Złożoność czasowa powiązana jest z czasem rozwiązywania problemu dla określonej liczby danych. Jednakże nie można jej wyrażać w jednostkach czasu. Powodem jest to, iż komputery posiadają różną prędkość wykonywania obliczeń, która jest zależna od ich procesorów. Np. dla powiedzmy 100 danych jeden komputer wykona dany algorytm w 1 sekundę, a wolniejszy będzie potrzebował np. 12 sekund. Mamy zatem niejednoznaczność. Aby ją usunąć, złożoność wyrażamy liczbą operacji głównych, które należy wykonać, aby rozwiązać dany problem. Operacja główna to ta, która bezpośrednio wpływa na czas wykonania algorytmu i może się składać z wielu operacji elementarnych. Poniższy przykład wyjaśni, o co tutaj chodzi:
Obliczanie sumy n kolejnych liczb naturalnych:
K01: Czytaj n
K02: Suma ← 0
K03: i ← 1
K04: Jeśli i > n,
to idź do K08
K05: Suma ← Suma + i
K06: i ← i + 1
K07: Idź do K04
K08: Pisz suma
K09: Zakończ
Oznaczmy czasy wykonania poszczególnych kroków przez tKi. Policzmy ile razy każda z operacji jest wykonywana dla kilku wartości n:
n |
1 |
2 |
3 |
4 |
5 |
tK01 |
1 |
1 |
1 |
1 |
1 |
tK02 |
1 |
1 |
1 |
1 |
1 |
tK03 |
1 |
1 |
1 |
1 |
1 |
tK04 |
2 |
3 |
4 |
5 |
6 |
tK05 |
1 |
2 |
3 |
4 |
5 |
tK06 |
1 |
2 |
3 |
4 |
5 |
tK07 |
1 |
2 |
3 |
4 |
5 |
tK08 |
1 |
1 |
1 |
1 |
1 |
tK09 |
1 |
1 |
1 |
1 |
1 |
Zwróć uwagę, iż ilość wykonań operacji w krokach czarnych nie zależy od n. Operacje w krokach czerwonych są wykonywane w ilości proporcjonalnej do n. Możemy teraz wyliczyć czas wykonywania się algorytmu (jeśli znamy czasy poszczególnych operacji):

Operacje czarne wykonują się w czasie niezależnym od n. Możemy zatem uprościć wzór wprowadzając ich czas sumaryczny:

Zauważ teraz, iż przy wzroście n różnica pomiędzy (n + 1) a n staje się względnie coraz mniejsza, np. 1001 ≈ 1000. Pozwala to jeszcze bardziej uprościć nasz wzór:

Przy dużych n czas stały tc odgrywa coraz mniejsze znaczenie. Można go zatem pominąć:
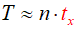
Widać teraz wyraźnie, iż czas wykonania tego algorytmu jest proporcjonalny do liczby obiegów pętli, czyli do n. Zatem za operację główną przyjmujemy pojedynczy obieg pętli.
Złożoność pamięciowa określa zapotrzebowanie na pamięć w algorytmie. Podany powyżej algorytm ma stałą złożoność pamięciową niezależną od n, ponieważ potrzebuje tylko trzech zmiennych: n, Suma oraz i.
W celu ułatwienia posługiwania się złożonościami wprowadzono tzw. klasy złożoności (ang. comptational complexity classes), które klasyfikują złożoność obliczeniową algorytmu w zależności od liczby przetwarzanych przez niego danych. Klasę oznacza się tzw. notacją Omikron. Nie będziemy tutaj podawać jej definicji, aby nie wydłużać rozdziału. Opiszemy jedynie kilka popularnych klas złożoności:
O(1) – złożoność stała: czas wykonania algorytmu jest stały (zajętość pamięci jest stała) dla dowolnej liczby danych wejściowych.
O(n) – złożoność liniowa: czas wykonania algorytmu (lub zajętość pamięci) jest proporcjonalny do liczby przetwarzanych danych. Tak typowo zachowują się algorytmy z jedną pętlą.
O(n2) – złożoność kwadratowa: czas wykonania algorytmu (lub zajętość pamięci) jest proporcjonalny do kwadratu liczby przetwarzanych danych. Tak typowo zachowują się algorytmy z pętlami zagnieżdżonymi.
O(2n) – złożoność wykładnicza: czas wykonania algorytmu (lub zajętość pamięci) wzrasta wykładniczo wraz ze wzrostem liczby danych.
O(n!) – złożoność typu silnia: tego typu algorytmy traktuje się jako nieobliczalne dla większych n, ponieważ silnia bardzo szybko rośnie.
Więcej na temat złożoności obliczeniowej podamy na dalszych lekcjach.
Przykłady:
Pewien komputer wykonuje algorytmy klasy: a) O(1), b) O(n), c) O(n2) i d) O(2n) dla n = 100 danych w czasie 1 sekundy. Ile wyniesie czas wykonania, gdy liczba danych wzrośnie do 1000?
Układamy proporcje:
a) O(1): złożoność stała, zatem czas się nie zmieni i pozostanie równy 1 sekundę.
b) O(n): złożoność liniowa, czas wykonania proporcjonalny do n:
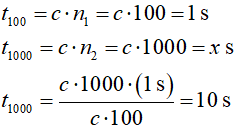
c) O(n2)
: złożoność kwadratowa, czas wykonania proporcjonalny do kwadratu z n:

c – stała proporcjonalności
d) O(2n):
złożoność wykładnicza, czas wykonania proporcjonalny do 2n:
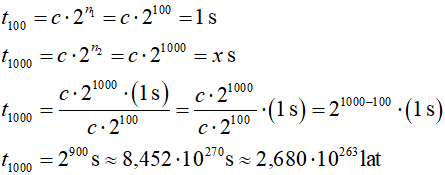
c – stała proporcjonalności
Ostatni algorytm jest praktycznie nieobliczalny dla tej liczby danych, czas obliczeń jest dłuższy tryliardy tryliardów tryliardów ... razy od wieku naszego wszechświata, takich algorytmów należy unikać!!!
Wróćmy do naszych liczb Fibonacciego. Otóż okazuje się, iż klasa czasowej złożoność rekurencyjnego algorytmu wyliczania tych liczb jest wykładnicza O(2n). Dzieje się tak dlatego, ponieważ algorytm wielokrotnie powtarza obliczenia. Oto drzewko wywołań dla n = 6:
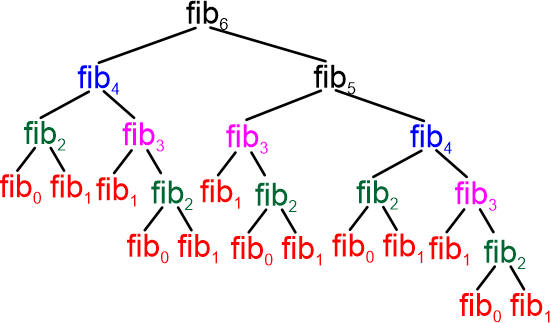
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
