|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
| SPIS TREŚCI REMANENT |
|
| Podrozdziały |
Naturalny kod binarny pozwala kodować liczby naturalne oraz liczbę zero. Niestety, nie można w nim zapisywać liczb ujemnych. W naszym systemie liczby ujemne zapisujemy z pomocą znaku minus, który stawiamy przed pierwszą cyfrą. Jest to dodatkowy symbol. Jednakże w świecie komputerów istnieją tylko bity, które mogą przyjmować dwie różne wartości: 0 lub 1. Nie możemy zatem po prostu zapisać liczby -5 jako -101, ponieważ wymagałoby to nowej wartości dla bitów. Musimy zastosować pewną umowę, która pozwoli reprezentować liczby ujemne wyłącznie za pomocą bitów, czyli zer i jedynek. W ten sposób powstanie nowy kod binarny.
Umówmy się, że najstarszy bit liczby będzie tzw. bitem znaku, tzn. nie będzie miał przydzielonej wagi jak inne bity, lecz będzie sygnalizował, czy liczba jest dodatnia "0" lub ujemna "1".
Załóżmy, że mamy kod 8-bitowy b7b6b5b4b3b2b1b0. W takim kodzie bity od b6 do b0 reprezentują wartość liczby w kodzie NBC, natomiast bit b7 określa znak tej liczby:
Dla 8 bitów możemy zapisywać liczby od -127 (111111111) do +127 (011111111). Na przykład -5 zapiszemy jako 10000101.
Otrzymaliśmy kod, który nazywamy kodem znak-moduł. Chociaż jest to kod prosty w budowie i łatwy do zrozumienia, to jednak nie jest powszechnie stosowany. Dlaczego? Powodem jest to, iż wykonywanie operacji arytmetycznych wymaga analizowania znaków liczb. Na przykład przy dodawaniu liczby dodatniej i ujemnej, musimy wykonać faktycznie odejmowanie, gdyż inaczej wynik będzie zły. Komplikuje to układy arytmetyczne komputerów, a zatem zwiększa ich koszt. Wymyślono zatem inny sposób reprezentacji liczb całkowitych, który nie wymaga zmian w układach arytmetycznych, należy jedynie inaczej interpretować wyniki. Kod realizujący ten wymóg nazywa się kodem uzupełnień do dwóch, U2.
Tutaj, podobnie jak w kodzie znak-moduł, najstarszy bit posiada inne znaczenie od pozostałych bitów liczby. Jest to bit znaku, lecz tym razem ma on swoją wagę, która jest ujemną potęgą 2 o wykładniku będącym numerem pozycji bitu. W efekcie wagi pozycji liczby U2 są takie same jak w kodzie NBC, tylko waga najstarszego bitu jest ujemna. Zobaczmy jak to działa na liczbach 4-bitowych:
| Waga | -8(-23) | 4(22) | 2(21) | 1(20) |
| Bit | b3 | b2 | b1 | b0 |
| Pozycja | 3 | 2 | 1 | 0 |
Jeśli najstarszy bit jest równy 0, to mamy zwykłą liczbę NBC, np.:
0110(U2)= 4 + 2 = 6
Jest to liczba dodatnia.
Jeśli najstarszy bit jest równy 1, to w wartości liczby pojawia się waga ujemna. Zwróć uwagę, że waga ta na moduł jest zawsze o 1 większa od sumy pozostałych wag. Z tego powodu przeważa ona wartość liczby w stronę liczb ujemnych:
1110(U2)+ -8 + 4 + 2 = -2
Wartość liczby jest sumą wag pozycji, na których stoją bity 1. Czyli dokładnie tak samo jak w kodzie NBC. Stąd najmniejszą liczbą jest taka, w której 1 stoi na pozycji znaku (wartość ujemna) , a wszystkie pozostałe bity mają wartość 0:
1000(U2) = -8 = -23 10000(U2) = -16 = -24 100000(U2) = -32 = -25... 10000000(U2) = -128 = -27
Dla n-bitowej liczby jest to -2n - 1.
Największą wartość otrzymamy dla liczby, w której bit znaku ma wartość 0 (brak wagi ujemnej), a wszystkie pozostałe bity mają stan 1 (suma wszystkich wag dodatnich):
0111(U2) = 7 = 23 - 1 01111(U2) = 15 = 24 - 1 011111(U2) = 31 = 25 - 1... 01111111(U2) = 127 = 27 - 1
Dla n-bitowej liczby jest to 2n - 1 - 1.
Otrzymujemy zatem zakres n-bitowych liczb U2 od -2n - 1 do 2n - 1 - 1.
Liczby U2 można dodawać dokładnie tak samo jak liczby NBC, lecz wynik należy interpretować w kodzie U2. Dla przykładu wykonamy proste dodawanie dwóch liczb U2 4-bitowych:
0111(U2)= 7 0111(NBC)= 7 1101(U2)= -8 + 5 = -3 1101(NBC)= 13
Dodajemy liczby NBC:
7 + 13 = 20 = 10100(NBC)
Wynik jest 5-bitowy. Ograniczamy go do 4 bitów:
0100(NBC)= 4 = 0100(U2)= 4
Otrzymaliśmy wynik 4, który jest wynikiem dodawania 7 + (-3) = 4. Jak widzisz, wynik jest poprawny, pomimo wykonania działania na zwykłych liczbach naturalnych NBC. Zatem liczby U2 pozwalają reprezentować liczby całkowite dodatnie i ujemne. Dodatkowo operacje arytmetyczne na liczbach U2 można wykonywać dokładnie tak samo jak na liczbach NBC, wynik musi być interpretowany jako liczba U2. Więcej na ten temat znajdziesz w tym artykule.
Kod U2 jest standardowo używany do reprezentacji liczb całkowitych w komputerach. W języku C++ mamy do dyspozycji następujące typy danych (kolorem czerwonym zaznaczono część nazwy typu, którą można pominąć):
| Nazwa typu | Liczba bajtów | Liczba bitów | Zakres |
| signed char | 1 | 8 | -128...127 |
| short int | 2 | 16 | -32768...32767 |
| int | 4 | 32 | -2147483648...2147483647 |
| long long int | 8 | 64 | -9223372036854775808...9223372036854775807 |
Zwykle nie będziesz musiał przeliczać wartości dziesiętnych na binarne, ponieważ zawsze robi to za ciebie komputer i chwała mu za to. Lecz musisz pamiętać o własnościach liczb binarnych, np. o dopuszczalnych zakresach oraz o rozmiarze danych w pamięci.
Poniższy program wypisuje rozmiary typów danych całkowitych dla twojego kompilatora:
C++// Sprawdzenie typów danych U2
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0012
//----------------------------
#include <iostream>
#include <windows.h>
#include <iomanip>
using namespace std;
int main()
{
signed char cnv,cpv;
short snv,spv;
int inv,ipv;
long long lnv,lpv;
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
// Wartości minimalne
// i maksymalne
cpv = spv = ipv =
lpv = 0xffffffffffffffffL;
cpv = (unsigned char) cpv >> 1;
spv = (unsigned short) spv >> 1;
ipv = (unsigned) ipv >> 1;
lpv = (unsigned long long) lpv >> 1;
cnv = ~cpv;
snv = ~spv;
inv = ~ipv;
lnv = ~lpv;
// Wyniki
cout <<
"Liczby całkowite w C++\n"
"----------------------\n\n"
"Nazwa typu Bajty Bity Zakres\n"
"----------------------------\n";
cout << left << setw(11)
<< "signed char" << right
<< setw(5)
<< sizeof(signed char)
<< setw(5)
<< sizeof(signed char) * 8
<< " "
<< (int) cnv << "... "
<< (int) cpv << endl;
cout << left << setw(11)
<< "short" << right
<< setw(5)
<< sizeof(short)
<< setw(5)
<< sizeof(short) * 8
<< " "
<< snv << "... " << spv << endl;
cout << left << setw(11)
<< "int" << right
<< setw(5)
<< sizeof(int)
<< setw(5)
<< sizeof(int) * 8
<< " "
<< inv << "... " << ipv << endl;
cout << left << setw(11)
<< "long long" << right
<< setw(5)
<< sizeof(long long)
<< setw(5)
<< sizeof(long long)* 8
<< " "
<< lnv << "... " << lpv
<< endl << endl;
system("pause");
return 0;
}
|
| Wynik |
Liczby całkowite w C++ ---------------------- Nazwa typu Bajty Bity Zakres ------------------------------ signed char 1 8 -128... 127 short 2 16 -32768... 32767 int 4 32 -2147483648... 2147483647 long long 8 64 -9223372036854775808... 9223372036854775807 |
Jak zamienić liczbę dziesiętną na liczbę U2? Jeśli koniecznie musisz coś takiego zrobić, to najprostszym rozwiązaniem jest poniższy program. Zamienia on liczby dziesiętne dodatnie i ujemne na ich odpowiedniki w kodzie U2. Liczba bitów powinna wynosić od 1 do 64.
C++// Konwersja na kod U2
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0013
//---------------------------
#include <iostream>
#include <windows.h>
using namespace std;
int main()
{
int nb;
long long n;
unsigned long long m;
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Konwersja na kod U2\n"
"-------------------\n\n"
"Liczba bitów U2 : ";
cin >> nb;
if((nb < 1) || (nb > 64))
cout << "Zła liczba bitów !!!";
else
{
cout << "Liczba dziesiętna: ";
cin >> n;
cout << "Liczba U2 : ";
// ustawiamy maskę
m = 1L << (nb - 1);
// Wyświetlamy kolejne
// bity liczby U2
while(m)
{
cout << ((m & n) > 0);
m >>= 1;
}
}
cout << endl << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Konwersja na kod U2 ------------------- Liczba bitów U2 : 4 Liczba dziesiętna: -5 Liczba U2 : 1011 |
| Konwersja na kod U2 ------------------- Liczba bitów U2 : 8 Liczba dziesiętna: -25 Liczba U2 : 11100111 |
| Konwersja na kod U2 ------------------- Liczba bitów U2 : 12 Liczba dziesiętna: -1000 Liczba U2 : 110000011000 |
| Konwersja na kod U2 ------------------- Liczba bitów U2 : 125 Zła liczba bitów !!! |
Python
(dodatek) # Konwersja na kod U2
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0013
# Python version
#---------------------------
print("Konwersja na kod U2\n"
"-------------------\n")
nb = int(input("Liczba bitów U2 : "))
# W Pythonie znika limit 64 bitów
if nb < 1:
print("Zła liczba bitów !!!")
else:
n = int(input("Liczba dziesiętna : "))
print("Liczba U2 : ",
end="")
# Ustawiamy maskę dla
# najstarszego bitu (znaku)
m = 1 << (nb - 1)
# Wyświetlamy kolejne
# bity liczby U2
while m > 0:
# Operator & w Pythonie dla
# liczb ujemnych działa na
# ich nieskończonej
# reprezentacji U2, co daje
# prawidłowy wynik bitowy.
print(1 if (m & n) else 0,
end="")
m >>= 1
print("\n")
input("Naciśnij Enter...")
|
Jeśli nie masz możliwości użyć tego programu, to konwersji można dokonać na kilka sposobów. Ponieważ zakładam, iż umiesz już konwertować liczby dziesiętne na kod NBC (opis w poprzednim rozdziale) , wykorzystajmy tę umiejętność dla kodu U2.
Kody U2 mają określoną liczbę bitów, ponieważ najstarszy bit jest zawsze bitem znakowym i posiada wagę ujemną. Załóżmy, że chcesz zapisać w 8-bitowym kodzie U2 liczbę 55. Najpierw konwertujesz 55 na kod NBC:
55 = 32 + 16 + 4 + 2 + 1 = 110111(NBC)
Liczba NBC ma tylko 6 bitów. Uzupełniasz zatem bity do 8 przez dodanie dwóch bitów 0 na początku zapisu liczby:
55 = 00110111(U2)
Gotowe.
Załóżmy teraz, że chcesz przekonwertować liczbę -44 na 8-bitowy kod U2. Tym razem masz liczbę ujemną. W kodzie 8-bitowym U2 bit znakowy ma wagę (-27) = -128. Ile należy dodać do -128, aby otrzymać -44?
-128 + x = -44 x = 128 - 44 x = 84
84 jest wartością pozostałych bitów liczby U2. Zamieniamy 84 na kod NBC:
84 = 64 + 16 + 4 = 1010100(NBC)
Otrzymana liczba NBC ma 7 bitów, dodajesz zatem bit znakowy 1 (ponieważ liczba ma być ujemna) i otrzymujesz wynik:
-44 = 11010100(U2)
Kod U2 pozwala kodować liczby całkowite dodatnie, ujemne oraz zero. Jest on zatem bardziej uniwersalny od kodu NBC. Nie oznacza to jednak, iż wypiera go całkowicie z obliczeń komputerowych. Zauważ, że liczby U2 mają o połowę mniejszy zakres wartości dodatnich (konsekwencja bitu znakowego) od liczb NBC o tej samej liczbie bitów:
| Liczba bitów |
Zakres NBC |
Zakres U2 |
| 4 | 0...15 | -8...7 |
| 8 | 0...255 | -128...127 |
| 16 | 0...65535 | -32768...32767 |
| 32 | 0... 4294967295 | -2147483648...2147483647 |
| 64 | 0... 18446744073709551615 | -9223372036854775808...9223372036854775807 |
Czasem musimy operować na dużych liczbach dodatnich. W takim przypadku kod NBC da nam ich większy zakres.
Operacja dodawania liczb U2 daje poprawne wyniki pod warunkiem, że wyniki te mieszczą się w zakresie liczb U2. W przeciwnym razie mamy nadmiar lub niedomiar i wynik jest błędny. Kiedy przy dodawaniu możemy otrzymać nadmiar lub niedomiar? Otóż wtedy, gdy wynik dodawania na moduł rośnie. A dzieje się tak tylko wtedy, gdy obie dodawane liczby posiadają ten sam znak. Jeśli znak wyniku jest taki sam jak znak dodawanych liczb, to wynik jest poprawny. Jeśli znak wyniku jest różny od znaku dodawanych liczb, to mamy nadmiar/niedomiar. Na przykład 8-bitowe liczby U2 posiadają poprawny zakres wartości od -128 do 127. Komputer dodaje te liczby tak, jakby były liczbami NBC, a wynik interpretuje w kodzie U2. Po to właśnie przyjęto kod U2, aby nie zmieniać zasad wykonywania operacji arytmetycznych. Sprawdźmy:
115 = 01110011(U2,NBC) -25 = 11100111(U2) = 231 jako NBC (115 - 25)(U2) = (115 + 231)(NBC) = 346(NBC) = 101011010(NBC)
Odrzucamy 9-ty bit wyniku i otrzymujemy:
01011010(U2) = 90 115 - 25 = 90
Wynik jest poprawny.
Teraz wykonajmy podobne działanie na dwóch liczbach dodatnich:
115 = 01110011(U2,NBC) 25 = 00011001(U2,NBC) (115 = 25)(U2) = (115 + 25)(NBC) = 140(NBC) = 10001100(NBC) 10001100(U2) = -128 + 16 + 8 = -104 115 + 25 = -104
W kodzie U2 wynik ma inny znak niż znaki obu dodawanych liczb, wystąpił zatem nadmiar/niedomiar i wynik jest nieprawidłowy.
Podsumujmy:
|
Jeśli suma dwóch dodatnich liczb U2 jest ujemna,
to wynik jest nieprawidłowy.
Jeśli suma dwóch ujemnych liczb U2 jest dodatnia, to wynik jest nieprawidłowy. W przeciwnym razie wynik jest prawidłowy. |
Poniższy program dodaje dwie 8-bitowe liczby U2 i sprawdza poprawność wyniku.
C++// Dodawanie liczb U2
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0014
//---------------------------
#include <iostream>
#include <windows.h>
using namespace std;
int main()
{
int x;
// Zmienne 8-bitowe U2
signed char a,b,r;
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Dodawanie 8-bitowych liczb U2\n"
"-----------------------------\n\n"
"Wpisz 2 liczby od -128 do 127\n\n";
// dane wczytujemy jako liczby
// 32-bitowe i przepisujemy je do
// zmiennych 8-bitowych U2
cout << "Liczba nr 1: ";
cin >> x;
a = x;
cout << "Liczba nr 2: ";
cin >> x;
b = x;
cout << endl;
// Wykonujemy dodawanie
// i wyświetlamy wynik
r = a + b;
cout << (int)a << " + "
<< (int)b << " = "
<< (int)r;
// Sprawdzamy poprawność wyniku
// Jeśli obie liczby a i b mają
// te same znaki,
// to poniższe wyrażenie
// jest prawdziwe
if((a ^ b ^ 0x80) & 0x80)
{
// Jeśli wynik ma inny znak
// od znaku liczby a, to
// poniższe wyrażenie jest
// prawdziwe i oznacza błędny
// wynik dodawania
if((a ^ r) & 0x80)
cout <<
" Błąd - wynik poza zakresem !!!";
}
cout << endl << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Dodawanie 8-bitowych liczb U2 ----------------------------- Wpisz 2 liczby od -128 do 127 Liczba nr 1: 115 Liczba nr 2: -25 115 + -25 = 90 |
| Dodawanie 8-bitowych liczb U2 ----------------------------- Wpisz 2 liczby od -128 do 127 Liczba nr 1: -115 Liczba nr 2: 100 -115 + 100 = -15 |
| Dodawanie 8-bitowych liczb U2 ----------------------------- Wpisz 2 liczby od -128 do 127 Liczba nr 1: 100 Liczba nr 2: 40 100 + 40 = -116 Błąd - wynik poza zakresem !!! |
| Dodawanie 8-bitowych liczb U2 ----------------------------- Wpisz 2 liczby od -128 do 127 Liczba nr 1: -75 Liczba nr 2: -84 -75 + -84 = 97 Błąd - wynik poza zakresem !!! |
Python
(dodatek) # Dodawanie liczb U2
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0014
#---------------------------
def i_b8(x):
return x & 0xFF
def b8_i(x):
if x > 127:
return x - 256
else:
return x
print("Dodawanie 8-bitowych liczb U2\n"
"-----------------------------\n\n"
"Wpisz 2 liczby od -128 do 127\n")
# dane wczytujemy jako int
# i zmieniamy na 8-bitowe U2
a = i_b8(int(input("Liczba nr 1: ")))
b = i_b8(int(input("Liczba nr 2: ")))
print()
# Wykonujemy dodawanie U2
# i wyświetlamy wynik U2
r = b8_i(a + b)
a = b8_i(a)
b = b8_i(b)
print(f"{a} + {b} = {r}", end="")
# Sprawdzamy poprawność wyniku
# Jeśli obie liczby a i b mają
# te same znaki,
# to poniższe wyrażenie
# jest prawdziwe
if (a ^ b ^ 0x80) & 0x80:
# Jeśli wynik ma inny znak
# od znaku liczby a, to
# poniższe wyrażenie jest
# prawdziwe i oznacza błędny
# wynik dodawania
if (a ^ r) & 0x80:
print(" Błąd - "
"wynik poza zakresem !!!",
end="")
print()
print()
input("Naciśnij Enter...")
|
Odejmowanie jest po prostu dodawaniem liczby przeciwnej, zatem po uwzględnieniu tego faktu reszta reguł jest identyczna jak dla dodawania:
|
Jeśli odjemnik ma inny znak od odjemnej, a wynik
ma ten sam znak co odjemnik, to wynik jest błędny.
W przeciwnym razie wynik jest poprawny. |
Przy mnożeniu liczb U2 poprawność wyniku można sprawdzić tą samą metodą, którą podaliśmy dla liczb NBC:
Poniższy program mnoży dwie 64-bitowe liczby NBC i sprawdza poprawność wyniku.
C++// Mnożenie liczb U2
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0015
//---------------------------
#include <iostream>
#include <windows.h>
using namespace std;
int main()
{
long long a,b,r;
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Mnożenie 64-bitowych liczb U2\n"
"-----------------------------\n\n";
// Odczytujemy dane wejściowe
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
// Wykonujemy mnożenie
r = a * b;
// Wypisujemy wynik
cout << a << " * "
<< b << " = "
<< r;
// Sprawdzamy nadmiar
if (b && (a != r / b))
cout <<
" Wynik błędny, NADMIAR !!!";
else
cout << " Wynik prawidłowy";
cout << endl << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Mnożenie 64-bitowych liczb
U2 ------------------------------ a = -234 b = 576 -234 * 576 = -134784 Wynik prawidłowy |
| Mnożenie 64-bitowych liczb
U2 ----------------------------- a = -25675599 b = 557657657575 -25675599 * 557657657575 = 4128549678534539191 Wynik błędny, NADMIAR !!! |
Dzielenie liczb U2 w C++ jest zawsze dzieleniem całkowitoliczbowym (w Pythonie są dwa operatory dzielenia: / - dzielenie normalne i // - dzielenie całkowite) i obowiązują tutaj te same zasady, co przy liczbach NBC:
|
Jeśli wykonujesz mnożenie i dzielenie liczb
całkowitych U2, dzielenie umieszczaj na końcu
wyrażenia.
Nie dziel liczby na moduł mniejszej przez liczbę na moduł większą, gdyż w wyniku otrzymasz zawsze 0. |
Przykładowy program przelicza stopnie Fahrenheita na stopnie Celsjusza i na odwrót. Wczytana liczba jest traktowana jako temperatura w stopniach Celsjusza lub w stopniach Fahrenheita. Wykorzystujemy wzory:
Wyniki będą zaokrąglone do liczb całkowitych.
C++// Działania na liczbach U2
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0016
//---------------------------
#include <iostream>
#include <windows.h>
using namespace std;
int main()
{
int t,tc,tf;
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Przeliczanie pomiędzy °C a °F\n"
"-----------------------------\n\n";
// Odczytujemy Temperaturę
cout << "Temperatura = "; cin >> t;
cout << endl;
// Przeliczamy
tc = (5 * (t - 32)) / 9;
tf = (9 * t) / 5 + 32;
// Wypisujemy wyniki
cout << t << "°C = "
<< tf << "°F" << endl << endl
<< t << "°F = "
<< tc << "°C" << endl << endl;
system("pause");
return 0;
}
|
| Wynik |
| Przeliczanie pomiędzy °C a °F ----------------------------- Temperatura = 0 0°C = 32°F 0°F = -17°C |
Python
(dodatek) # Działania na liczbach U2
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0016
# ---------------------------
print("Przeliczanie pomiędzy "
"°C a °F\n"
"----------------------"
"-------\n")
# Odczytujemy Temperaturę
t = int(input("Temperatura = "))
print()
# Przeliczamy z użyciem //
tc = (5 * (t - 32)) // 9
tf = (9 * t) // 5 + 32
# Wypisujemy wyniki
print(f"{t}°C = {tf}°F\n")
print(f"{t}°F = {tc}°C\n")
print()
input("Naciśnij Enter...")
|
Liczba losowa (ang. random number) jest liczbą otrzymaną w wyniku pewnego procesu losowego, np. losowania, rzutu monetą, kostką, rozdania potasowanych kart itp. Cechą podstawową liczby losowej jest to, iż jej konkretnej wartości nie możemy w żaden sposób określić przed losowaniem, możemy jedynie określić jej zakres, np. podczas rzutu kostką wiemy, że wynikiem może być od 1 do 6 oczek, pomijając przypadki, gdy kość się rozpadnie lub zatrzyma na krawędzi, czego również nie da się wcześniej przewidzieć. Wartości liczb losowych pojawiają się z pewnym prawdopodobieństwem, które im jest wyższe, tym częściej dana liczba pojawia się w wynikach. Rachunkiem prawdopodobieństwa nie będziemy się tutaj zajmować, jednak liczby losowe są czasem stosowane w obliczeniach, zatem warto coś o nich wiedzieć.
Prawdziwa liczba losowa jest trudna do otrzymania na komputerze bez dodatkowego wyposażenia. Wymaga ona procesu, którego wyniku nie da się określić, a wszystkie operacje wykonywane przez komputer są ściśle określone. Starano się to rozwiązać za pomocą różnych dodatkowych urządzeń, np. generatorów szumu, które wykorzystują procesy kwantowe zachodzące w półprzewodnikach, jednakże takie urządzenia nie są standardowym wyposażeniem i nie każdy użytkownik ma do nich dostęp. Dlatego często zadowalamy się namiastką liczb losowych – liczbami pseudolosowymi (ang. pseudorandom numbers). Słowo "pseudo" pochodzi z języka łacińskiego i oznacza "jakby", czyli liczby pseudolosowe to jakby liczby losowe. Przypominają one liczby losowe, mogą posiadać ich niektóre własności, np. częstość występowania, lecz są otrzymywane na drodze algorytmicznej. Oznacza to, iż znając sposób ich tworzenia oraz jedną z nich, możemy wyliczyć wszystkie następne, zatem nie ma tutaj żadnej losowości. Pomimo tej wady (a może zalety), liczby pseudolosowe mają ogromne zastosowanie w informatyce, począwszy od gier a skończywszy na szyfrowaniu i symulacjach.
Liczby pseudolosowe tworzy się za pomocą funkcji zwanych generatorami liczb pseudolosowych. Generatorów pseudolosowych wymyślono mnóstwo. Aby zrozumieć ich działanie, przeanalizujmy prostą funkcję o postaci:
Gdzie:
| Xn+1 – następna liczba
pseudolosowa Xn – poprzednia liczba pseudolosowa a – mnożnik c – przyrost m – moduł |
W funkcji występuje działanie modulo, czyli reszta z dzielenia dwóch liczb całkowitych. W języku C++ realizuje je operator arytmetyczny %:
| 5 % 3 = 2, ponieważ 3 mieści się w 5 jeden raz i zostaje reszta 2. |
Następna liczba pseudolosowa Xn + 1 powstaje z liczby poprzedniej Xn. Oznacza to, iż liczby te nie są dowolne, lecz tworzą ciąg:
Ciąg ten również nie jest nieskończony, ponieważ w funkcji występuje reszta z dzielenia przez m. Reszty z dzielenia mogą przyjmować wartości tylko w przedziale od 0 do m - 1. Zatem wszystkich możliwych wartości jest co najwyżej m. Co więcej, wartości te powtarzają się po wygenerowaniu m liczb:
Pierwszą liczbę X0 tego ciągu nie obliczamy, lecz określamy. Nazywa się ona ziarnem pseudolosowym (ang. pseudorandom seed) i powinna mieć wartość od 0 do m - 1. Z ziarna powstają wszystkie kolejne liczby ciągu. Po wygenerowaniu m liczb pseudolosowych kolejną liczbą jest z powrotem ziarno pseudolosowe i cały ciąg powtarza się. Liczby pseudolosowe tworzą zamknięty pierścień wartości. Ziarno określa pozycję startową w tym pierścieniu:
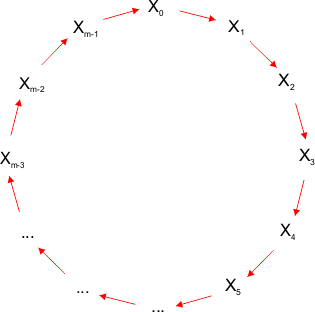
Aby funkcja wygenerowała wszystkie liczby w przedziale od 0 do m - 1, należy odpowiednio dobrać jej współczynniki. Procedura jest następująca:
Podsumujmy:
a = 27 c = 11 m = 26
Funkcja generatora ma wzór:
Jako X0 możemy przyjąć dowolną liczbę od 0 do 25. Przyjęcie innej wartości nic nie da, ponieważ operacja modulo i tak sprowadzi wynik do zakresu od 0 do 25.
Poniższy program generuje liczby pseudolosowe wg tej funkcji.
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0017
//---------------------------
#include <iostream>
#include <windows.h>
using namespace std;
int main()
{
// Współczynniki generatora
// pseudolosowego
const int a = 27;
const int c = 11;
const int m = 26;
// Liczba pseudolosowa
int x;
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Generator pseudolosowy od 0 do 25\n"
"---------------------------------\n\n";
// Wczytujemy ziarno pseudolosowe
cout << "X0 = "; cin >> x;
cout << endl;
// Generujemy 26 liczb pseudolosowych
for(int i = 0; i < 26; i++)
{
// Wyznaczamy kolejną
// liczbę pseudolosową
x = (a * x + c) % m;
// Wyświetlamy jej wartość
cout << x << " ";
}
cout << endl << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Generator pseudolosowy od
0 do 25 --------------------------------- X0 = 0 11 22 7 18 3 14 25 10 21 6 17 2 13 24 9 20 5 16 1 12 23 8 19 4 15 0 |
| Generator pseudolosowy od
0 do 25 --------------------------------- X0 = 10 21 6 17 2 13 24 9 20 5 16 1 12 23 8 19 4 15 0 11 22 7 18 3 14 25 10 |
| Generator pseudolosowy od
0 do 25 --------------------------------- X0 = 20 5 16 1 12 23 8 19 4 15 0 11 22 7 18 3 14 25 10 21 6 17 2 13 24 9 20 |
Python
(dodatek) # Liczby pseudolosowe
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0017
# ---------------------------
# Współczynniki generatora
a = 27
c = 11
m = 26
print("Generator pseudolosowy "
"od 0 do 25\n"
"-----------------------"
"----------\n")
# Wczytujemy ziarno
x = int(input("X0 = "))
print()
# Generujemy 26 liczb
for i in range(26):
# Kolejna liczba (modulo m)
x = (a * x + c) % m
# Wyświetlamy w jednej linii
print(x, end=" ")
print("\n")
input("Naciśnij Enter...")
|
Przyglądnij się dokładnie wynikom otrzymanym w tym programie. Ostatnią liczbą jest zawsze ziarno pseudolosowe, zatem ciąg kolejnych 26 liczb będzie taki sam. Liczby są pomieszane, dlatego funkcja opisana powyżej często nazywa się funkcją mieszającą lub haszującą (ang. hashing function). Jeśli poprawnie dobierzemy współczynniki a, c i m, to każda liczba w tym ciągu pojawi się dokładnie jeden raz. Aby liczby wyglądały jak losowe, moduł m powinien być duży, wtedy powtórka liczby ciągu wystąpi dopiero po wygenerowaniu dużej ich ilości.
Funkcji pseudolosowej nie musimy sami tworzyć, o ile nie jest to konieczne. W języku C++ (w Pythonie korzystamy z biblioteki random) dostępny jest generator liczb pseudolosowych, z którego zawsze możesz skorzystać.
Poniższy program generuje 10 liczb pseudolosowych za pomocą wbudowanego generatora pseudolosowego.
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0018
//---------------------------
#include <iostream>
#include <windows.h>
#include <cstdlib>
#include <iomanip>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Wbudowany generator pseudolosowy\n"
"--------------------------------\n\n";
// Generujemy 10 liczb pseudolosowych
for(int i = 0; i < 10; i++)
cout << setw(6) << rand() << endl;
cout << endl << endl;
system("pause");
return 0;
}
|
| Wynik |
| Wbudowany generator pseudolosowy -------------------------------- 41 18467 6334 26500 19169 15724 11478 29358 26962 24464 |
Python
(dodatek) # Liczby pseudolosowe
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0018
#---------------------------
import random
print("Wbudowany generator "
"pseudolosowy\n"
"--------------------"
"------------\n")
# Generujemy 10 liczb
# pseudolosowych
# od 0 do 32767
for i in range(10):
r = random.randint(0, 32767)
print(f"{r:6}")
print("\n")
input("Naciśnij Enter...")
|
Uruchom program kilka razy i porównaj otrzymane wyniki. Za każdym razem otrzymujesz ten sam ciąg wartości (w C++, w Pythonie to nie występuje, ale możemy takie zachowanie symulować). Dzieje się tak dlatego, iż ziarno pseudolosowe jest zawsze inicjowane na tę samą wartość przy uruchomieniu programu. Skoro tak, to generowany ciąg pseudolosowy staruje zawsze od tej samej liczby początkowej. Aby otrzymywać inne ciągi liczb pseudolosowych, musisz zmieniać wartość ziarna pseudolosowego przy starcie. Nie zmieni to następstwa generowanych liczb, ale ich punkt startowy.
Poniższy program pozwala ci określić ziarno pseudolosowe.
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0019
//---------------------------
#include <iostream>
#include <windows.h>
#include <cstdlib>
#include <iomanip>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
int x;
cout <<
"Ziarno wbudowanego "
"generatora pseudolosowego\n"
"-------------------"
"-------------------------\n\n";
// Odczytujemy wartość
// ziarna pseudolosowego
cout << "Podaj ziarno od 0 do "
<< RAND_MAX << endl << endl
<< "X0 = ";
cin >> x;
cout << endl;
// Ustawiamy nowe
// ziarno pseudolosowe
srand(x);
// Generujemy 10 liczb
// pseudolosowych na podstawie
// nowego ziarna
for(int i = 0; i < 10; i++)
cout << setw(6) << rand()
<< endl;
cout << endl << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Ziarno wbudowanego generatora
pseudolosowego -------------------------------------------- Podaj ziarno od 0 do 32767 X0 = 0 38 7719 21238 2437 8855 11797 8365 32285 10450 30612 |
| Ziarno wbudowanego generatora
pseudolosowego -------------------------------------------- Podaj ziarno od 0 do 32767 X0 = 1 41 18467 6334 26500 19169 15724 11478 29358 26962 24464 |
| Ziarno wbudowanego generatora
pseudolosowego -------------------------------------------- Podaj ziarno od 0 do 32767 X0 = 2 45 29216 24198 17795 29484 19650 14590 26431 10705 18316 |
Python
(dodatek) # Liczby pseudolosowe
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0019
#---------------------------
import random
print("Ziarno wbudowanego "
"generatora pseudolosowego\n"
"-------------------"
"-------------------------\n")
print("Nowe ziarno od 0 do 32767\n")
x = int(input("X0 = "))
print()
# Ustawiamy nowe
# ziarno generatora
random.seed(x)
# Generujemy 10 liczb
# pseudolosowych na bazie ziarna
for i in range(10):
r = random.randrange(0, 32768)
print(f"{r:6}")
print("\n")
input("Naciśnij Enter...")
|
Aby przy każdym uruchomieniu programu otrzymywać różne ciągi pseudolosowe, powinniśmy zapewnić różne wartości ziarna pseudolosowego. W praktyce jako ziarno pseudolosowe używamy wartości czasu odczytanej z wewnętrznego zegara, w który wyposażony jest każdy współczesny komputer osobisty. Wartość ta zmienia się co sekundę, zatem przy każdym uruchomieniu programu będzie inna. (W Pythonie robione to jest automatycznie, nie musisz ustawiać ziarna pseudolosowego przy uruchamianiu programu, chyba że chcesz otrzymywać ten sam ciąg liczb pseudolosowych.)
Poniższy program pokazuje, jak można to zrobić:
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0020
//---------------------------
#include <iostream>
#include <windows.h>
#include <cstdlib>
#include <iomanip>
#include <ctime>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Uprzypadkowienie wbudowanego "
"generatora liczb pseudolosowych\n"
"-----------------------------"
"-------------------------------\n\n";
// Ustawiamy nowe
// ziarno pseudolosowe z zegara
srand(time(nulptr));
// Generujemy 10 liczb pseudolosowych
// na podstawie nowego ziarna
for(int i = 0; i < 10; i++)
cout << setw(6)<< rand()<< endl;
cout << endl << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Uprzypadkowienie wbudowanego generatora liczb
pseudolosowych ------------------------------------------------------------ 1519 12568 436 2376 30534 3152 10392 6205 14274 6661 |
| Uprzypadkowienie wbudowanego generatora liczb
pseudolosowych ------------------------------------------------------------ 1711 24132 5846 13087 16501 5453 30186 30104 5418 4373 |
| Uprzypadkowienie wbudowanego generatora
liczb pseudolosowych ------------------------------------------------------------ 1865 5019 26262 29951 9766 26169 12632 23594 27798 10326 |
Wbudowany generator języka C++ generuje liczby pseudolosowe w zakresie od 0 do 32767 (stała RAND_MAX). Zakres ten określa 15-bitowe liczby NBC. Wewnętrznie liczby pseudolosowe są tworzone na 32 bitach, a funkcja rand() zwraca 15 najmłodszych bitów wygenerowanej liczby pseudolosowej. Ma to na celu zwiększenie ich przypadkowości. 32 bity daje nam okres ponad 4 miliardów liczb, czyli ciąg ten zaczyna się powtarzać po wygenerowaniu 4 miliardów liczb pseudolosowych.
Jak zwiększyć zakres generowanych liczb pseudolosowych do 30 bitów? Rozwiązanie jest proste: należy wywołać funkcję rand() dwukrotnie z odpowiednio przesuniętymi bitami w lewo i połączyć wyniki operatorem bitowej alternatywy (w Pythonie nie ma ograniczeń na górny zakres liczb pseudolosowych):
rand() | (rand() << 15) |
Zwiększy to zakres generowanych liczb do 1073741823 (230 - 1). Lepsze rozwiązanie pokażemy dalej.
Funkcja rand() nadaje się do generowania niezbyt dużych liczb pseudolosowych. Aby otrzymać liczby z innego zakresu niż 0...32767 stosujemy prosty wzór (w Pythonie używasz po prostu random.randint(a, b) lub random.randrange(a, b+1):
L = A + rand() % (B - A + 1) |
Wynikiem są liczby pseudolosowe z zakresu od A do B.
Poniższy program wyświetla wyniki rzutów kostką w postaci tabeli 6 × 6:
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0021
//---------------------------
#include <iostream>
#include <windows.h>
#include <cstdlib>
#include <iomanip>
#include <ctime>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout << "Rzuty kostką\n"
"------------\n\n";
// Ustawiamy nowe ziarno
// pseudolosowe z zegara
srand(time(nulptr));
// Generujemy 6 serii
// rzutów kostką
for(int j = 0; j < 6; j++)
{
cout << " ";
for(int i = 0; i < 6; i++)
cout << 1 + rand() % 6 << " ";
cout << endl;
}
cout << endl;
system("pause");
return 0;
}
|
| Wyniki |
| Rzuty kostką ------------ 1 3 2 5 5 2 5 1 4 1 5 5 3 4 4 3 6 5 4 3 6 6 3 6 1 5 5 1 3 2 2 6 2 5 3 5 |
| Rzuty kostką ------------ 6 5 2 6 1 4 5 5 5 4 1 2 1 5 2 5 6 4 4 1 5 6 3 6 5 6 3 4 3 3 4 1 2 4 2 2 |
Python
(dodatek) # Liczby pseudolosowe
# (C)2026 mgr Jerzy Wałaszek
# Metody numeryczne 0021
#---------------------------
import random
print("Rzuty kostką\n"
"------------\n")
# Python automatycznie
# ustawia ziarno z czasu
# systemowego przy starcie
# Generujemy 6 serii
for j in range(6):
print(" ", end="")
# W każdej serii 6 rzutów
for i in range(6):
# rzut kostką od 1 do 6
k = random.randint(1, 6)
print(k, end=" ")
# przejście do nowej linii
print()
print("\n")
input("Naciśnij Enter...")
|
W języku C++ od wersji 11 istnieje cała biblioteka obiektów związanych z generacją liczb pseudolosowych. Dostęp do jej funkcji uzyskuje się po dołączeniu do programu pliku nagłówkowego <random>.
Standardowy generator liczb pseudolosowych języka C++ posiada wiele ograniczeń, z których najbardziej bolesnym jest mały zakres generowanych liczb (0...RAND_MAX, RAND_MAX = 32767). Oczywiście ograniczenie to można ominąć losując kilka liczb pseudolosowych i łącząc je w jedną liczbę. Jest to jednak niewygodne. W takich wypadkach pomocna może być biblioteka obiektowa random. Udostępnia ona różne generatory liczb pseudolosowych oraz różne rozkłady liczbowe. Tutaj krótko opiszemy podstawowe zasady pracy z obiektami pseudolosowymi.
Generator pseudolosowy jest klasą C++. Istnieją typy ogólne tych klas oraz typy zaadaptowane do określonych rodzajów generatorów pseudolosowych:
| default_random_engine | : | wybrany generator pseudolosowy, który daje dobre wyniki w typowych, prostych zastosowaniach. |
| minstd_rand | : | prosty, liniowy generator
multiplikatywny LCG: x = x * 48271 % 2147483647 |
| minstd_rand0 | : | prosty, liniowy generator
multiplikatywny LCG: x = x * 16807 % 2147483647 |
| mt19937 | : | generator pseudolosowy typu Mersenne Twister. Daje w wyniku liczby 32-bitowe. |
| mt19937_64 | : | generator pseudolosowy typu Mersenne Twister. Daje w wyniku liczby 64-bitowe. |
| ranlux24_base | generator pseudolosowy typu Ranlux o podstawie 24-bitowej. Daje w wyniku liczby 32-bitowe. | |
| ranlux48_base | generator pseudolosowy typu Ranlux o podstawie 48-bitowej. Daje w wyniku liczby 64-bitowe. | |
| ranlux24 | generator pseudolosowy typu Ranlux o podstawie 24-bitowej z przyspieszonym postępem. Daje w wyniku liczby 32-bitowe. | |
| ranlux48 | generator pseudolosowy typu Ranlux o podstawie 48-bitowej z przyspieszonym postępem. Daje w wyniku liczby 64-bitowe. | |
| knuth_b | generator pseudolosowy typu Knuth-B. Daje w wyniku liczby 32-bitowe. |
Każda klasa generatora posiada funkcje składowe:
| (konstruktor) | : | tworzy obiekt danej klasy i inicjuje jego elementy składowe, tak aby był gotowy do użytku. Jako parametr dla konstruktora przekazuje się ziarno typu całkowitego bez znaku. |
| min() | : | zwraca minimalną wartość generowanych liczb pseudolosowych. |
| max() | : | zwraca maksymalną wartość generowanych liczb pseudolosowych. |
| seed(v) | inicjuje na nową wartość wewnętrzne ziarno pseudolosowe wg wartości v. | |
| operator() | generuje kolejną liczbę pseudolosową i zwraca ją jako wynik operatora nawiasy ( ). | |
| discard() | generuje kolejną liczbę pseudolosową, lecz nie zwraca jej. |
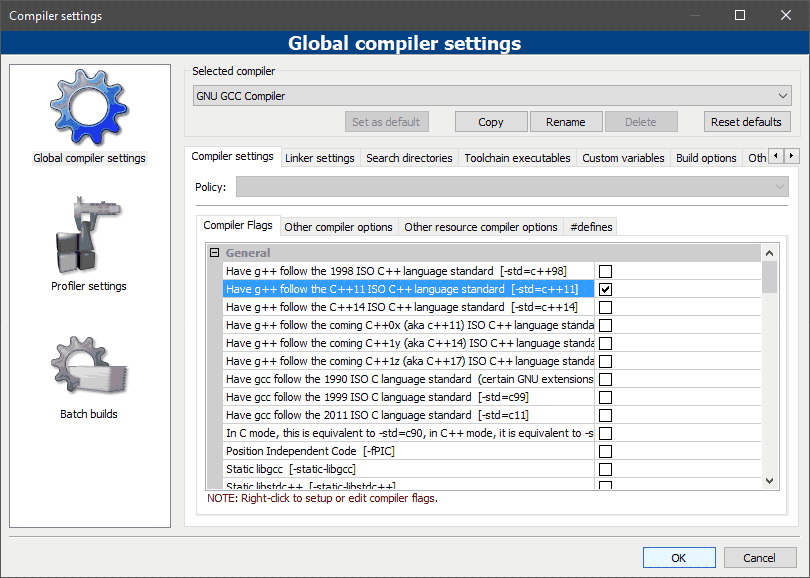
Zobaczmy, jak to działa w praktyce. Najpierw musisz włączyć obsługę standardu 11 języka C++ w swoim kompilatorze. Jeśli korzystasz ze środowiska Code::Blocks, to z menu wybierz opcję Settings→Compiler i w okienku dialogowym zaznacz wskazaną opcję kompilatora:
Poniższy program tworzy różne generatory liczb pseudolosowych i wyświetla informacje o zakresach tworzonych przez nie liczb.
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0022
//---------------------------
#include <iostream>
#include <windows.h>
#include <ctime>
#include <random>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Zakresy bibliotecznych "
"generatorów pseudolosowych\n"
"-----------------------"
"--------------------------\n\n";
// Tworzymy klasy
// generatorów pseudolosowych
default_random_engine dgen(time(nullptr));
minstd_rand mgen(time(nullptr));
minstd_rand0 m0gen(time(nullptr));
mt19937 mtgen(time(nullptr));
mt19937_64 mt64gen(time(nullptr));
ranlux24_base rl24gen(time(nullptr));
ranlux48_base rl48gen(time(nullptr));
knuth_b kbgen(time(nullptr));
// Wyświetlamy zakresy
// liczb pseudolosowych
// dla każdego generatora
cout
<< "Standardowy : "
<< dgen.min() << "... "
<< dgen.max() << endl
<< "Multiplikatywny LCG : "
<< mgen.min() << "... "
<< mgen.max() << endl
<< "Multiplikatywny LCG 0 : "
<< m0gen.min() << "... "
<< m0gen.max() << endl
<< "Mersenne Twister : "
<< mtgen.min() << "... "
<< mtgen.max() << endl
<< "Mersenne Twister 64 : "
<< mt64gen.min() << "... "
<< mt64gen.max() << endl
<< "Ranlux 24-bitowy : "
<< rl24gen.min() << "... "
<< rl24gen.max() << endl
<< "Ranlux 48-bitowy : "
<< rl48gen.min() << "... "
<< rl48gen.max() << endl << endl;
system("pause");
return 0;
}
|
| Wynik |
| Zakresy bibliotecznych generatorów
pseudolosowych ------------------------------------------------- Standardowy : 1... 2147483646 Multiplikatywny LCG : 1... 2147483646 Multiplikatywny LCG 0 : 1... 2147483646 Mersenne Twister : 0... 4294967295 Mersenne Twister 64 : 0... 18446744073709551615 Ranlux 24-bitowy : 0... 16777215 Ranlux 48-bitowy : 0... 281474976710655 |
Następny program generuje 15 liczb pseudolosowych za pomocą wybranego generatora pseudolosowego. Generator możesz zmienić na inny.
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0023
//---------------------------
#include <iostream>
#include <windows.h>
#include <ctime>
#include <random>
#include <iomanip>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"Generacja liczb pseudolosowych "
"generatorem Mersenne Twister 64\n"
"-------------------------------"
"-------------------------------\n\n";
// Tworzymy generator pseudolosowy
// Mersenne Twister 64
mt19937_64 mt64gen(time(nullptr));
// Wyświetlamy 15 liczb
// pseudolosowych
for(int i = 0; i < 15; i++)
cout << setw(22) << mt64gen()
<< endl;
cout << endl;
system("pause");
return 0;
}
|
| Wynik |
| Generacja liczb pseudolosowych generatorem
Mersenne Twister 64 -------------------------------------------------------------- 10537470712149690863 16289189653767349705 17446861035845780457 8462092411226512412 11670304320697365710 89603159830766338 11893928287530825151 4391792179446479643 5359857403735253840 939567318540422672 1708525228151313803 7177467170986783977 12812186784476095291 9706571523780530581 17589396534050711681 |
Jeśli chcesz otrzymywać liczby z zakresu A...B, to możesz zastosować podany wcześniej wzór:
Istnieje jednak lepszy sposób, który wykorzystuje rozkład. Rozkład określa prawdopodobieństwo pojawienia się określonej wartości w zakresie generowanych liczb. Jeśli prawdopodobieństwo każdej wartości w zakresie jest takie samo, to mamy do czynienia z rozkładem jednorodnym (ang. uniform distribution). Rozkład nazywamy dyskretnym, jeśli w podanym zakresie liczby mogą przyjmować tylko wybrane wartości (np. całkowite).
Biblioteka random udostępnia mnóstwo różnych rozkładów, których dokładne omówienie wykracza poza ramy tego artykułu.
Rozkład w bibliotece random jest klasą. Zasady użycia są następujące:
Poniższy program generuje 200 liczb pseudolosowych o rozkładzie jednorodnym.
C++// Liczby pseudolosowe
// (C)2019 mgr Jerzy Wałaszek
// Metody numeryczne 0024
//---------------------------
#include <iostream>
#include <windows.h>
#include <ctime>
#include <random>
#include <iomanip>
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
cout <<
"200 liczb pseudolosowych od 1 "
"do 999 o rozkładzie jednorodnym\n"
"------------------------------"
"-------------------------------\n\n";
// Tworzymy klasę szablonową int
// rozkładu jednorodnego
uniform_int_distribution<int> dist(1,999);
// Tworzymy standardowy
// generator pseudolosowy
default_random_engine gen(time(nullptr));
// Wyświetlamy 200 liczb pseudolosowych
int c = 0;
for(int i = 0; i < 200; i++)
{
cout << setw(4)<< dist(gen);
if(++c == 10)
{
c = 0; cout << endl;
}
}
cout << endl;
system("pause");
return 0;
}
|
| Wynik |
| 200 liczb pseudolosowych od 1 do 999 o
rozkładzie jednorodnym ------------------------------------------------------------- 573 919 35 724 241 623 106 20 82 683 348 233 137 86 408 63 412 421 587 607 258 98 355 342 460 672 321 263 826 787 566 971 51 926 816 717 123 672 934 280 408 420 474 933 267 81 139 854 987 419 480 307 248 827 297 164 85 819 579 958 700 226 399 256 436 158 283 405 259 162 122 32 698 944 703 57 552 928 498 45 951 516 167 871 772 782 119 133 770 156 788 844 272 726 856 927 678 644 892 503 124 696 332 919 855 357 369 751 227 387 956 786 707 827 193 582 829 395 10 11 861 638 255 437 80 473 237 53 380 314 874 728 443 586 624 196 813 612 530 778 965 817 821 334 548 610 647 386 437 806 781 806 756 60 961 360 142 748 270 435 143 857 623 427 801 409 388 656 922 956 252 54 40 442 825 103 297 195 91 642 191 549 537 140 565 425 247 305 938 687 132 996 955 424 24 668 189 463 479 275 |
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
