|
Serwis Edukacyjny
Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny
Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu |
©2026 mgr Jerzy Wałaszek
|
Z funkcją spotkałeś się już na samym początku tego kursu: była to funkcja główna programu main( ), od której komputer rozpoczyna wykonywanie napisanego przez ciebie kodu. Funkcje są jakby małymi programami, które mogą posiadać swój własny zestaw zmiennych i do których inne funkcje mogą przekazywać dane poprzez parametry. Dodatkowo funkcja może zwracać wynik swoich obliczeń.
W języku C wszystko, co nie należy do elementów własnych języka, musi zostać zdefiniowane przed pierwszym użyciem. Nie inaczej jest z funkcjami. Zanim będziesz mógł skorzystać z dobrodziejstw jakiejś funkcji, musisz ją sobie wcześniej odpowiednio zdefiniować. Definicja funkcji posiada następującą składnię:
typ nazwa(lista parametrów)
{
treść funkcji
}
|
| typ | – | Określa typ zwracanego przez funkcję wyniku. Może to być jeden z poznanych już typów: char, int, unsigned, float lub wskaźnik do danych char *, int *, unsigned *, float *. Jeśli funkcja nic nie zwraca, to stosujemy typ void. | |
| nazwa | – | Określa nazwę, poprzez którą
będziesz się odwoływał do kodu tej funkcji z innych
miejsc w programie. Zasady tworzenia nazw dla
funkcji są identyczne jak dla zmiennych:
|
|
| lista parametrów |
– | Określa dane, które będą
przekazywane do funkcji. Lista parametrów może być
pusta, jeśli funkcja nie potrzebuje żadnych danych.
Lista parametrów zbudowana jest jako ciąg definicji
poszczególnych parametrów:
Parametry możesz traktować jak zmienne, którym nadano określone wartości przy wywołaniu funkcji. Więcej na ten temat znajdziesz dalej w rozdziale |
|
| treść funkcji | – | Zawiera definicje zmiennych oraz instrukcje, które mają być wykonane w ramach funkcji. Jeśli funkcja zwraca jakiś wynik, to ciąg instrukcji należy zakończyć instrukcją return wartość. Jeśli funkcja nie zwraca żadnej wartości (jest typu void), to funkcję można zakończyć poleceniem return bez żadnego parametru. Również taka funkcja kończy się po wykonaniu ostatniej zawartej w niej instrukcji. |
Uruchom program:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 12.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
// Funkcja oblicza ado potęgi b
//------------------------------
float potega(float a, int b)
{
int j;
float x = 1;
for(j = 0; j < b; j++) x *= a;
return x;
}
int main()
{
float p = -3.5;
int i;
setlocale(LC_ALL,"");
for(i = 0; i <= 9; i++)
printf("%4.1f^%d = %9.2f\n",p,i,potega(p,i));
return 0;
}
|
W programie definiujemy funkcję, która liczy potęgę b pierwszego argumentu a, czyli ab. Funkcja ma dwa parametry, które wewnątrz niej noszą nazwy:
Funkcja potega( ) oblicza a do potęgi b przez wykonanie b mnożeń, których wynik jest składowany w zmiennej x. Gdy wynik jest gotowy, instrukcja return kończy działanie funkcji i zwraca x jako jej wartość.
W funkcji main( ) wywołujemy w pętli funkcję potega( ) z odpowiednimi parametrami, a zwrócone wyniki wyświetlamy w oknie konsoli.
Zwróć uwagę, że użycie funkcji upraszcza kod funkcji main( ).
Jeśli wewnątrz funkcji utworzysz zmienne, to będą to zmienne lokalne (ang. local variables), czyli prywatne dla tej funkcji. Oznacza to, że w innych funkcjach mogą istnieć zmienne o takiej samej nazwie i nie będą one ze sobą kolidowały. Jak to rozumieć? Bardzo prosto. Wyobraź sobie, że istnieją dwie rodziny, np. Kowalskich i Matysiaków. W obu rodzinach jest córka, która ma na imię Matylda. Jednak nie jest to ta sama Matylda, pomimo tego, że nosi to samo imię. Jedna to Matylda Kowalska, a druga to Matylda Matysiak. Teraz odnieśmy to do funkcji. Załóżmy, że mamy dwie funkcje o nazwach f1( ) i f2( ). W każdej z tych funkcji tworzymy zmienną o nazwie a. Jednak nie jest to ta sama zmienna: jedna to zmienna a z funkcji f1( ), a druga to zmienna a z funkcji f2( ). Teraz jasne?
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 13.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
void fxxx( ) // jakaś funkcja
{
int a = 10;
printf("W funkcji fxxx a = %d\n\n",a);
// Jeśli funkcja jest typu void, to
// return nie jest potrzebne
}
int main()
{
int a = 99;
setlocale(LC_ALL,"");
printf("W funkcji main a = %d\n\n",a);
fxxx( );
printf("W funkcji main a = %d\n\n",a);
return 0;
}
|
W programie tworzymy funkcję fxxx( ) (nie chciało mi się wymyślać wyszukanej nazwy). Wewnątrz tej funkcji definiujemy zmienną lokalną o nazwie a i nadajemy jej wartość 10, która następnie jest wyświetlana.
Wykonanie programu rozpocznie się od funkcji main( ), w której też definiujemy zmienną lokalną o nazwie a i nadajemy jej wartość 99. Następnie wywołujemy funkcję fxxx( ), która wyświetli swoją zmienną a. Aby pokazać, że funkcja fxxx( ) nie zmieniła wartości zmiennej a wewnątrz funkcji main( ), każemy jeszcze raz wyświetlić zawartość zmiennej a. Otrzymujemy:
| W funkcji main a = 99 W funkcji fxxx a = 10 W funkcji main a = 99 |
Jak widzisz, w funkcji main( ) zmienna a dalej zawiera liczbę 99. Wynika z tego, że w funkcji fxxx( ) zmienna a była inną zmienną od zmiennej a w funkcji main( ).
Zmienne lokalne są bardzo mądrym rozwiązaniem. Programista nie musi sprawdzać, czy dana nazwa była już gdzieś wcześniej użyta w programie.
Lokalność dotyczy również nazw parametrów, czyli danych, które otrzymuje funkcja od programu ją wywołującego. Parametr funkcji jest dla niej zmienną lokalną i nie koliduje z nazwami zmiennych zdefiniowanymi w innych funkcjach. Traktuj parametry jak zmienne, które otrzymały jakąś wartość. Parametry można nawet zmieniać wewnątrz funkcji.
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 13.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
// Oblicza największy wspólny dzielnik a i b
//------------------------------------------
unsigned nwd(unsigned a, unsigned b)
{
unsigned r;
while(b)
{
r = a % b;
a = b;
b = r;
}
return a;
}
int main()
{
unsigned a,b,c;
setlocale(LC_ALL,"");
printf("Skracanie ułamkow\n"
"-----------------\n\n");
printf("licznik = "); scanf("%u",&a);
printf("mianownik = "); scanf("%u",&b);
c = nwd(a,b);
printf("\n\n%u/%u = %u/%u\n\n",a,b,a/c,b/c);
return 0;
}
|
Powyższy program skraca ułamki. Ułamki skracamy obliczając największy wspólny dzielnik licznika i44mianownika, a następnie dzieląc licznik i mianownik przez nwd( ). Do obliczania nwd( ) stosujemy algorytm Euklidesa z resztami z dzielenia. Zwróć uwagę, że w funkcji nwd( ) parametry a i b są zmieniane tak, jakby to były zwykłe zmienne (którymi właściwie są). Zmiana tych parametrów nie wpływa na zmianę zmiennych a i b w funkcji main( ).
Czasem pożądane jest, aby funkcje w programie miały dostęp do pewnej zmiennej. O takiej zmiennej mówimy, że jest zmienną globalną (ang. global variable). Zmienna globalna musi być zdefiniowana przed wszystkimi funkcjami, w których ma być do niej dostęp.
Zmienne lokalne tracą swoje życie, gdy funkcja kończy działanie – są one tworzone tylko na czas wykonywania kodu funkcji. Zmienna globalna jest dostępna przez cały czas działania programu, przechowuje zatem swoją wartość pomiędzy kolejnymi wywołaniami funkcji.
Trochę naciągany przykład (ponieważ nie wymaga koniecznie zmiennych globalnych):
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 14.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
// Zmienne globalne
//-----------------
float a,b,c;
char d;
// Funkcja wyświetla wyniki obliczeń
//----------------------------------
void p( )
{
printf("\n%9.3f %c %9.3f = %9.3f\n",a,d,b,c);
}
int main()
{
setlocale(LC_ALL,"");
printf("Liczba nr 1 = "); scanf("%f",&a);
printf("Liczba nr 2 = "); scanf("%f",&b);
d = '+'; c = a + b; p( );
d = '-'; c = a - b; p( );
d = 'x'; c = a * b; p( );
d = ':'; c = a / b; p( );
return 0;
}
|
Program jest prostym kalkulatorem. Najpierw wczytuje dwie liczby do zmiennych globalnych a i b. Następnie wykonuje nad tymi liczbami cztery podstawowe działania arytmetyczne, zapisując wynik w zmiennej globalnej c oraz znak operacji w zmiennej globalnej d. Na koniec wywoływana jest funkcja p( ), która na podstawie zmiennych globalnych prezentuje jednolicie wyniki tych obliczeń. Bez zmiennych globalnych musielibyśmy przekazywać do funkcji p( ) cztery parametry.
Doświadczeni programiści twierdzą, nie bez racji, że liczba zmiennych globalnych powinna wynosić zero, ponieważ ich wprowadzenie wymaga od programisty śledzenia ich użycia w programie. Każda funkcja może zmienić zawartość zmiennej globalnej, co nie jest bezpieczne. Uwagi te odnoszą się do dużych programów zawierających tysiące wierszy kodu. W małych programach użycie zmiennych globalnych może prowadzić do znacznego uproszczenia kodu, jednak jeśli nie musisz, nie stosuj zmiennych globalnych.
Następny przykład wykorzystuje zmienną globalną do wyznaczenia kolejnego wyniku – zmienne globalne przechowują informację pomiędzy kolejnymi wywołaniami funkcji.
Liczby bliźniacze, to dwie liczby pierwsze, które różnią się o 2. Np. liczbami bliźniaczymi są: 3 i 5, 5 i 7, 11 i 13, 17 i 19... Nasz program będzie wyszukiwał takie pary.
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 14.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <locale.h>
// Zmienne globalne
//-----------------
unsigned p1, p2 = 3;
// Funkcja wyszukuje parę liczb bliźniaczych
//------------------------------------------
void tp( )
{
unsigned i,g;
char test;
do
{
p1 = p2; // druga liczba będzie pierwszą
p2 = p1 + 2; // kolejny kandydat na liczbę pierwszą
do // sprawdzamy, czy p2 jest pierwsze
{
test = 1;
g = sqrt(p2);
for(i = 3; i <= g; i += 2)
if(!(p2 % i))
{
test = 0; break;
}
if(!test) p2 += 2; // jeśli nie, to następne p2
}
while(!test); // kontynuujemy, aż p2 będzie pierwsze
if(p2 - p1 == 2) printf("%u i %u\n",p1,p2);
}
while(p2 - p1 != 2); // kontynuujemy, aż p1 i p2 będą bliźniacze
}
int main()
{
int n;
setlocale(LC_ALL,"");
printf("Ile par liczb bliźniaczych? n = ");
scanf("%d",&n);
while(n--) tp( );
return 0;
}
|
Jak działa funkcja tp( )? Otóż wykorzystuje ona fakt, iż zmienne p1 i p2 zachowują swoje wartości pomiędzy jej wywołaniami. Zadaniem funkcji tp( ) jest znalezienie dwóch liczb pierwszych p1 i p2, których różnica wynosi 2. Znalezione liczby są wyświetlane jako para liczb bliźniaczych. Przed pierwszym wywołaniem funkcji tp( ) zmienna p2 otrzymuje wartość początkową 3.
Funkcja tp( ) zakłada, że w zmiennych p1 i p2 znajduje się para liczb pierwszych, które zostały znalezione poprzednio. W pętli głównej przepisuje p2 do p1 i rozpoczyna szukanie kolejnej liczby pierwszej w p2 (wykorzystujemy tutaj podany wcześniej algorytm testowania podzielności). Gdy znaleziona zostanie kolejna liczba pierwsza w p2, funkcja sprawdza, czy różnica p2 - p1 wynosi 2. Jeśli tak, to wypisuje obie liczby i kończy działanie. Jeśli nie, to pętla główna wykonuje następny obieg, aż taka para zostanie znaleziona.
W funkcji głównej wywołujemy funkcję tp( ) n razy, gdzie n podaje użytkownik. W efekcie otrzymujemy n początkowych par liczb bliźniaczych.
Parametry umożliwiają przekazanie do funkcji różnych danych, które mogą być jej potrzebne do obliczeń. Parametry umieszczamy w nawiasach za nazwą funkcji. Parametry określamy w definicji funkcji. Istnieją dwa sposoby przekazywania danych w parametrach.
Funkcja otrzymuje tylko wartość w argumencie, z którą może sobie wszystko zrobić. W takim przypadku parametr jest zdefiniowany jako zwykła zmienna – funkcja może sobie ten parametr dowolnie zmieniać, ponieważ jest on dla niej prywatny, lokalny. W wywołaniu parametrem może być dowolne wyrażenie arytmetyczne – komputer oblicza wartość wyrażenia i wynik przekazuje funkcji w parametrze.
Przykładowa funkcja wyświetla liczbę, którą dostaje jako swój argument. Nie korzysta z funkcji printf( ) (pamiętamy, że w środowisku małych mikrokontrolerów taka funkcja może nie być dostępna). Powstaje zatem problem: jak wyświetlić liczbę otrzymaną jako wartość? Zanim podam pełny algorytm, zróbmy małe spostrzeżenie:
Mamy liczbę 7429. Dzielimy ją całkowitoliczbowo przez 10, czyli przez podstawę naszego systemu. Otrzymujemy:
7429 : 10 = 742 i reszta 9
Reszta z dzielenia jest ostatnią cyfrą. Wynik dzielenia z kolei możemy potraktować jako przesunięcie cyfr o jedną pozycję w prawo z usunięciem najmłodszej cyfry:
7429 742 i 9 usuwamy. |
Jeśli powtórzymy tę sama operację dla wyniku, to otrzymamy:
742 : 10 = 74 i reszta 2
Otrzymaliśmy kolejną cyfrę od końca. Kontynuując otrzymamy kolejne cyfry 4 i 7. Operację przerywamy, gdy wynik dzielenia osiągnie 0.
Jeśli ułożymy cyfry w kolejności otrzymywania, dostaniemy: 9 4 7. Jest to zapis naszej liczby wspak. Aby wypisać liczbę normalnie, musimy przechować liczby w tablicy, w której utworzymy tzw. stos.
Stos (ang. stack) jest sekwencyjną strukturą danych. Najprościej możemy go sobie wyobrazić jako stos książek na biurku. Nowe książki układamy na szczycie stosu (ang. stack top), wtedy stos rośnie w górę.
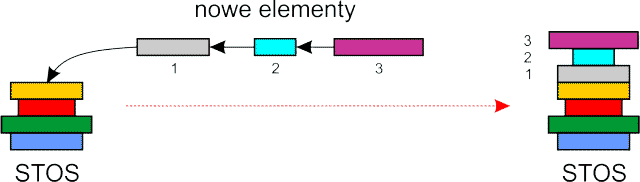
Ze stosu pobieramy książki znajdujące się na samej górze, wtedy stos maleje. Zwróć uwagę, że książki zawsze zdejmujesz ze stosu w kolejności odwrotnej do ich umieszczania – jako pierwszą zdejmiesz ostatnią książkę na stosie.
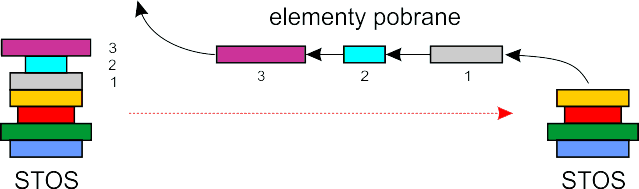
Wracając do świata komputerów, stos jest taką strukturą danych, z której odczytujemy elementy w kolejności odwrotnej do ich wstawiania. Struktura ta nosi nazwę LIFO (ang. Last In – First Out – wszedł ostatni, a wyszedł pierwszy). Zaletą stosu jest prostota jego implementacji. Do utworzenia stosu w tablicy potrzebujemy dwóch zmiennych. Pierwszą z nich będzie tablica, która przechowuje umieszczone na stosie elementy. Druga zmienna sptr służy do zapamiętywania pozycji szczytu stosu i nosi nazwę wskaźnika stosu (ang. stack pointer). Umawiamy się, że wskaźnik stosu zawsze wskazuje pustą komórkę tablicy, która znajduje się tuż ponad szczytem stosu:
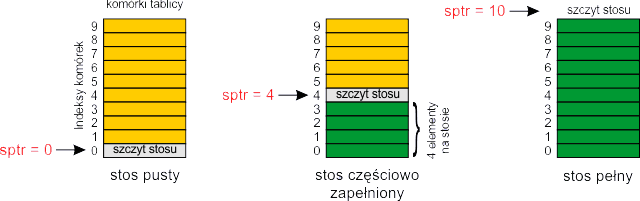
Tablica powinna mieć wystarczająco duży rozmiar, aby pomieścić wszystkie zapisywane dane. Jeśli będziemy wyświetlać liczby typu unsigned, to w IBM PC maja one zakres od 0 do 4 miliardów, czyli zapis liczby może przyjąć maksymalnie 10 cyfr.
Algorytm wyświetlania liczby pozycyjnej o podstawie p jest następujący:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 14.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <locale.h>
// Funkcja wyświetla podaną w parametrze liczbę
//---------------------------------------------
void print(unsigned x)
{
char s[10]; // stos
int sptr = 0; // wskaźnik stosu
char c; // cyfra
do
{
c = '0' + (x % 10);
s[sptr++] = c; // cyfra na stos
x = x / 10;
}
while(x);
while(sptr) putchar(s[--sptr]);
}
int main()
{
unsigned n;
setlocale(LC_ALL,"");
printf("Liczba = "); scanf("%u",&n);
printf("Liczba = "); print(n);
printf("\n\n");
return 0;
}
|
W programie pojawiła się nowa funkcja putchar( ). Przesyła ona do okna konsoli jeden znak, który przekazujemy w parametrze jako kod ASCII. Tego typu funkcję łatwo zaprogramować i ma ona krótki kod, co jest zaletą w przypadku małych mikrokontrolerów, którym zawsze brakuje pamięci.
Zmieniając nieco ten program, można wyświetlać liczby w systemie ósemkowym:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 14.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <locale.h>
// Funkcja wyświetla podaną w parametrze liczbę
//---------------------------------------------
void print(unsigned x)
{
char s[11]; // stos
int sptr = 0; // wskaźnik stosu
char c; // cyfra
do
{
c = '0' + (x % 8);
s[sptr++] = c; // cyfra na stos
x = x / 8;
}
while(x);
while(sptr) putchar(s[--sptr]);
}
int main()
{
unsigned n;
setlocale(LC_ALL,"");
printf("DEC = "); scanf("%u",&n);
printf("OCT = "); print(n);
printf("\n\n");
return 0;
}
|
W systemie dwójkowym (istnieje prostszy sposób wyświetlania liczby dwójkowej, podamy go w rozdziale o bitach):
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 14.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <locale.h>
// Funkcja wyświetla podaną w parametrze liczbę
//---------------------------------------------
void print(unsigned x)
{
char s[32]; // stos
int sptr = 0; // wskaźnik stosu
char c; // cyfra
do
{
c = '0' + (x % 2);
s[sptr++] = c; // cyfra na stos
x = x / 2;
}
while(x);
while(sptr) putchar(s[--sptr]);
}
int main()
{
unsigned n;
setlocale(LC_ALL,"");
printf("DEC = "); scanf("%u",&n);
printf("BIN = "); print(n);
printf("\n\n");
return 0;
}
|
I szesnastkowym:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 14.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <locale.h>
// Funkcja wyświetla podaną w parametrze liczbę
//---------------------------------------------
void print(unsigned x)
{
char s[8]; // stos
int sptr = 0; // wskaźnik stosu
char c; // cyfra
do
{
c = '0' + (x % 16);
if(c > '9') c += 7;
s[sptr++] = c; // cyfra na stos
x = x / 16;
}
while(x);
while(sptr) putchar(s[--sptr]);
}
int main()
{
unsigned n;
setlocale(LC_ALL,"");
printf("DEC = "); scanf("%u",&n);
printf("HEX = "); print(n);
printf("\n\n");
return 0;
}
|
Czasami chcemy, aby funkcja miała dostęp do zmiennych lokalnych innej funkcji, która wywołuje tę pierwszą. Najczęściej chodzi o to, aby wywołana funkcja zmieniła zawartość wskazanych zmiennych. Jeśli chodzi o zmienienie tylko jednej zmiennej, to można wykorzystać wynik zwracany przez funkcję. Dla kilku zmiennych to nie zadziała, ponieważ funkcja zwraca tylko jeden wynik. Musi zatem posiadać dostęp do zewnętrznych zmiennych lokalnych innej funkcji. Uzyskamy to definiując parametr funkcji jako wskaźnik. Poprzez ten wskaźnik funkcja może zmieniać wskazywany obiekt, czyli ma do niego dostęp. Wskaźnik zwany jest często referencją (czyli odwołaniem). Dlatego ten sposób przekazywania danych w parametrach nosi nazwę przekazywania przez referencję.
Poniższy przykład wylicza pole i obwód trójkąta zadanego współrzędnymi trzech punktów wierzchołkowych. Przypomnijmy sobie nieco geometrii:
Mamy dwa punkty P1 i P2 na płaszczyźnie kartezjańskiej:
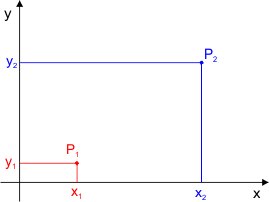
Punkty te posiadają odpowiednio współrzędne: P1 → (x1,y1), P2 → (x2,y2)
Odległość pomiędzy tymi punktami obliczymy przy pomocy Twierdzenia Pitagorasa, ponieważ otrzymujemy tutaj trójkąt prostokątny:
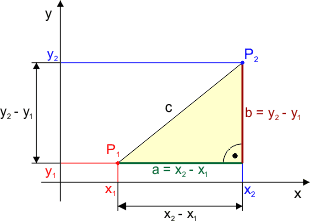
Piszemy:
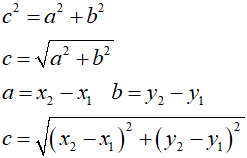
Otrzymaliśmy wzór, który umożliwia obliczenie odległości na płaszczyźnie dwóch dowolnych punktów o znanych współrzędnych. Teraz przejdziemy do trójkąta. Mamy dane trzy dowolne punkty płaszczyzny o znanych współrzędnych, które wyznaczają trójkąt:
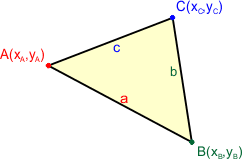
Długości boków obliczymy ze wzorów:
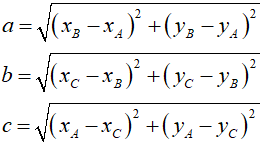
Gdy mamy długości boków obliczamy obwód trójkąta:
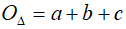
Pole trójkąta obliczymy za pomocą wzoru Herona:
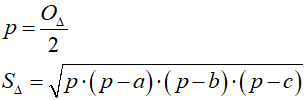
Mamy wszystkie potrzebne wzory, przystępujemy do tworzenia programu:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 15.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <locale.h>
// Funkcja odczytuje współrzędne punktu
//-------------------------------------
void r(char p, float * x, float * y)
{
printf("Punkt %c:\n",p);
printf("x = "); scanf("%f",x);
printf("y = "); scanf("%f",y);
printf("\n");
}
// Funkcja oblicza długość boku
//-----------------------------
float l(float x1, float y1, float x2, float y2)
{
float x = x2 - x1;
float y = y2 - y1;
return sqrt(x * x + y * y);
}
int main()
{
float xa,ya,xb,yb,xc,yc,a,b,c,p,o,s;
setlocale(LC_ALL,"");
printf("Obliczanie obwodu i pola trójkąta\n"
"---------------------------------\n\n");
r('A',&xa,&ya); // czytamy współrzędne punktu A
r('B',&xb,&yb); // czytamy współrzędne punktu B
r('C',&xc,&yc); // czytamy współrzędne punktu C
a = l(xa,ya,xb,yb); // długość boku a
b = l(xb,yb,xc,yc); // długość boku b
c = l(xc,yc,xa,ya); // długość boku c
o = a + b + c; // obwód
p = o / 2; // połowa obwodu potrzebna we wzorze Herona
s = sqrt(p * (p - a) * (p - b) * (p - c)); // pole
printf("Obwód = %9.3f\n"
"Pole = %9.3f\n\n", o, s);
return 0;
}
|
Wypróbuj go dla danych: A(-1,-1), B(1,-1), C(1,1). Obwód powinien wynieś 6,228, a pole 2,000.
Funkcja r( ) uzyskuje poprzez referencję dostęp do dwóch zmiennych lokalnych funkcji main( ). Jest to jej potrzebne do umieszczenia w tych zmiennych współrzędnych x i y punktu, które wprowadza użytkownik. Zwróć uwagę, że w funkcji scanf( ) parametry te podawane są bez operatora adresu &, ponieważ to już są adresy (wskaźniki) zmiennych.
Prototyp funkcji (ang. function prototype) jest jakby częściową definicją, która ma poinformować kompilator o podstawowych cechach tej funkcji: typie zwracanego wyniku, nazwie, typach parametrów. Po co to jest potrzebne? Jeśli twój program składa się tylko z jednego pliku źródłowego, to zwykle prototypów nie potrzebujesz. Jednak musisz wiedzieć, że funkcja jest "znana" w programie dopiero od miejsca, w którym umieścisz jej definicję. Jeśli spróbujesz wywołać ją wcześniej, np. w innej funkcji, to dostaniesz komunikat o błędzie, ponieważ w języku C obowiązuje zasada: obiekt można użyć po zdefiniowaniu, nigdy wcześniej. Prototyp rozwiązuje ten problem. Umieszczamy go na samym początku programu. Od tego momentu w dół funkcja może być używana tak, jakby została już zdefiniowana. Oczywiście prototyp nie zwalnia cię z obowiązku zdefiniowania tej funkcji gdzieś w programie.
Prototyp funkcji wygląda następująco:
typ nazwa(lista_parametrów); |
W prototypie nie umieszczamy kodu wykonawczego funkcji, a lista parametrów nie musi zawierać ich nazw, jedynie typy (chociaż dla porządku lepiej takie nazwy umieścić).
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 15.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
// Prototyp funkcji
//-----------------
float sum2(float,float);
int main()
{
float x = 0.1;
int i;
setlocale(LC_ALL,"");
for(i = 1; i <= 26; i++) x = sum2(x,x);
return 0;
}
// Definicja funkcji
//------------------
float sum2(float a, float b)
{
float c = a + b;
printf("%9.1f + %9.1f = %9.1f\n",a,b,c);
return c;
}
|
Dzięki prototypowi funkcję sum2( ) można dopisać na końcu programu. Sprawdź, co się stanie, gdy usuniesz prototyp z tego programu i spróbujesz go ponownie skompilować.
Prototypy funkcji są bardzo przydatne, gdy tworzysz program składający się z wielu plików źródłowych. W takim przypadku pozwalają one odwoływać się do funkcji zdefiniowanych w innym pliku. Prototypy zewnętrznych funkcji umieszcza się w pliku nagłówkowym i dołącza do programu dyrektywą #include "nazwa_pliku.h" (w ten sposób możesz stworzyć bibliotekę funkcji i używać jej w swoich programach). Tą opcją nie będę się tutaj zajmował.
Mikroprocesor jest maszyną stosową. O stosie pisaliśmy już wcześniej: jest to struktura danych, w której składuje się informację, a pobiera ją w kolejności odwrotnej do zapisu. Stos tworzony jest w pamięci RAM (czyli tej, w której trzymane są dane). Wyjątkiem są najprostsze mikrokontrolery, które posiadają osobną, niewielką pamięć stosu. Stos używany przez mikroprocesor nazywa się stosem maszynowym (ang. machine stack). Gdy w programie jest wywoływana funkcja, mikroprocesor umieszcza na tym stosie maszynowym adres powrotny, czyli np. adres następnej instrukcji za funkcją. Adres ten jest wykorzystywany później do powrotu w miejsce wywołania, gdy funkcja zakończy swoje działanie. Również parametry mogą być przesyłane poprzez stos: zanim komputer wywoła funkcję, oblicza wartości parametrów i umieszcza je kolejno na stosie. Po argumentach dodaje adres powrotny i wykonuje skok do kodu funkcji.
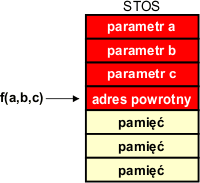
Kod funkcji pobiera, uzyskuje dostęp do parametrów, poprzez stos. Jeśli funkcja tworzy zmienne lokalne, to są one również umieszczane na stosie:
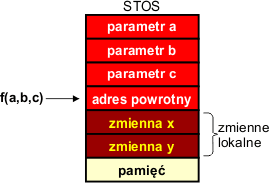
Jeśli stos jest odpowiednio duży, to w ten sposób funkcje mogą wywoływać ze swojego kodu dalsze funkcje i nie będą nawzajem ze sobą kolidować. jednak musisz pamiętać, że każde wywołanie funkcji rezerwuje na stosie pewną liczbę komórek pamięci na argumenty, adres powrotny oraz zmienne lokalne. Również wartość zwracana przez funkcję może być umieszczana na stosie maszynowym.
Słowo rekurencja pochodzi z języka łacińskiego i oznacza bieg wstecz. Funkcja jest funkcją rekurencyjną (ang. recursive function), jeśli wywołuje samą siebie do rozwiązania pewnego problemu. Oczywiście nie wygląda to w ten sposób:
void f( )
{
f( );
}
|
Powód jest prosty: każde wywołanie powoduje wzrost stosu. W pewnym momencie stos przestaje się mieścić w pamięci. Wywołanie rekurencyjne ma sens tylko wtedy, gdy najpierw sprawdzamy warunek wyjścia z rekurencji, a jeśli nie jest on spełniony, to rekurencję kontynuujemy. Istnieje wiele problemów, które rekurencyjnie rozwiązuje się bardzo prosto, natomiast inne podejścia są skomplikowane (np. tak często jest w teorii grafów, którą tutaj nie będziemy się zajmować). Istnieją rekurencyjne struktury danych. Nie szukając daleko: system plików na twoim dysku twardym: dysk twardy zawiera pliki i katalogi, a katalogi mogą dalej zawierać następne pliki i katalogi itd.
W świecie mikrokontrolerów zastosowanie rekurencji ogranicza mała pojemność pamięci. Niemniej warto coś na jej temat wiedzieć.
Na początek szkolny przykład: liczenie silni. Silnię obliczamy jako:
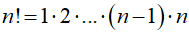
Czyli jest to iloczyn kolejnych liczb naturalnych od 1 do n. Silnię możemy zdefiniować rekurencyjnie:
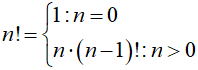
Odczytujemy to tak: silnia 0! = 1, a silnia innych liczb jest otrzymywana z silni poprzedniej: n·(n-1)!, Jak to działa? Policzmy tym sposobem silnię liczby 5:
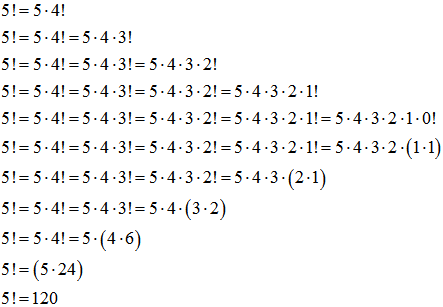
Silnię rozwijamy rekurencyjne aż do momentu, gdy będzie znana jej wartość, czyli 0! = 1. Teraz biegniemy wstecz i kolejno wyliczamy silnie:
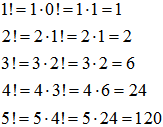
Uruchom program:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 16.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
unsigned silnia(unsigned n)
{
if(n) return n * silnia(n - 1);
else return 1;
}
int main()
{
unsigned i;
setlocale(LC_ALL,"");
for(i = 0; i <= 13; i++)
printf("%2u! = %10u\n", i, silnia(i));
return 0;
}
|
Zwróć uwagę, że każde wywołanie rekurencyjne funkcji silnia( ) odbywa się z innym parametrem. Jest to podstawowa cecha wywołań rekurencyjnych. Inaczej doprowadzilibyśmy do przepełnienia stosu, ponieważ funkcja wywoływałby się w nieskończoność (no, prawie w nieskończoność, aż do zapełnienia całej dostępnej pamięci). Drugą istotną cechą jest to, że najpierw sprawdzamy warunek kontynuacji rekurencji, i dopiero gdy jest spełniony, wywołujemy funkcję rekurencyjnie. Inaczej otrzymalibyśmy przepełnienie stosu, bo nic by rekurencji nie powstrzymywało.
Rekurencja wcale nie jest zagadnieniem prostym i często mają z nią kłopoty nawet doświadczeni programiści. Podobno Departament Obrony USA zakazał stosowania rekurencji w programach dla wojska. Nie wiem, czy to jest prawda, niemniej jednak rekurencja może czasem sprawić kłopoty. Dla przykładu przeanalizujmy ten program:
/*
Funkcje
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 16.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
unsigned fib(unsigned n)
{
if(n < 2) return n;
else return fib(n-2) + fib(n-1);
}
int main()
{
unsigned i;
setlocale(LC_ALL,"");
for(i = 0; i <= 46; i++)
printf("fib[%2u] = %10u\n", i, fib(i));
return 0;
}
|
Wygląda normalnie. Program oblicza rekurencyjnie kolejne liczby ciągu Fibonacciego, który jest zdefiniowany następująco:
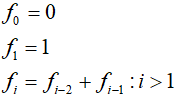
Kilka początkowych liczb ciągu Fibonacciego:
0 1 1 2 3 5 8 13 21 34 55 89 144 ... |
Gdy uruchomisz program, początkowe wyrazy ciągu Fibonacciego zostaną znalezione bardzo szybko, lecz dalsze są wyliczane coraz wolniej, aż w końcu tempo staje się żółwie i musimy długo czekać na kolejną liczbę. Dlaczego tak się dzieje? Wszystkiemu winne są wywołania rekurencyjne. Program wielokrotnie liczy te same wartości, co w efekcie wydłuża obliczenia. W pewnym momencie ilość wywołań jest tak duża, że może nastąpić przepełnienie stosu.
Dla przykładu rozwińmy fib(6):
fib(6) = fib(4) + fib(5) fib(6) = (fib(2)+fib(3)) + (fib(3)+fib(4)) fib(6) = ((fib(0)+fib(1)) + (fib(1)+fib(2))) + ((fib(1)+fib(2))+(fib(2)+fib(3))) fib(6) = ((fib(0)+fib(1)) + (fib(1)+(fib(0)+fib(1)))) + ((fib(1)+(fib(0)+fib(1))) + ((fib(0)+fib(1))+(fib(1)+fib(2)))) fib(6) = ((fib(0)+fib(1)) + (fib(1)+(fib(0)+fib(1)))) + ((fib(1)+(fib(0)+fib(1))) + ((fib(0)+fib(1))+(fib(1)+(fib(0)+fib(1))))) |
Widać wyraźnie, że program wielokrotnie wylicza te same wartości fib(0) i fib(1). Ilość tych wywołań rośnie lawinowo wraz ze wzrostem numeru liczby w ciągu. Dlatego starsze liczby są wyznaczane coraz wolniej.
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
