|
Serwis Edukacyjny
Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny
Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu |
©2026 mgr Jerzy Wałaszek
|
Tablica (ang. array) jest złożoną strukturą danych, która w języku C składa się z ciągu elementów tego samego typu. Z tablicami spotkasz się często w świecie mikrokontrolerów, ponieważ są bardzo użyteczne. W zmiennej prostej możesz umieścić tylko pojedynczą informację, np. liczbę lub literę. W tablicy takich informacji będziesz mógł umieścić więcej. Jednak musisz poznać oraz zrozumieć sposób dostępu do danych umieszczonych w tablicy. Tablice są bliskimi przyjaciółmi pętli.
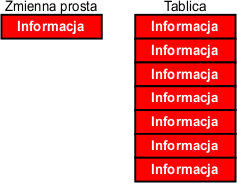
Tablica zbudowana jest z komórek, które możesz traktować jak zmienne proste (chociaż, jak zobaczysz dalej, komórka tablicy może być nową tablicą). Komórki te są ponumerowane kolejnymi liczbami, które nazywamy indeksami. Numeracja indeksów w języku C rozpoczyna się od wartości 0, a indeks jest liczbą całkowitą nieujemną. Indeksy umieszczamy w klamrach kwadratowych obok nazwy tablicy. Wszystkie komórki są tego samego typu.

Dzięki tym indeksom możesz się odwoływać do wybranej komórki tablicy. Jeśli zmienna a jest tablicą i zawiera 10 komórek, to nazwy tych komórek są następujące:
a[0] a[1] a[2] a[3] a[4] a[5] a[6] a[7] a[8] a[9] |
Do czego stosuje się tablice? Najczęściej do serii, ciągu danych. Wyobraź sobie, że tworzysz program dla mikrokontrolera, który powinien wczytać serię danych z czujników, np. co 1/100 sekundy przez 1 sekundę, czyli 100 odczytów, a następnie te dane w jakiś tam sposób przeanalizować lub przetworzyć. Zachodzi pytanie, gdzie umieścić ten ciąg odczytów? Odpowiedź jest prosta: w tablicy 100 elementowej. Bez tablic program byłby beznadziejnie nudny i długi:
a0 = odczyt_czujnikow; a1 = odczyt_czujnikow; a2 = odczyt_czujnikow; // i tak dalej do a99 ... a99 = odczyt_czujnikow; |
A później równie bezsensowne przetwarzanie danych:
Przetwarzaj a0; Przetwarzaj a1; Przetwarzaj a2; // i tak dalej do a99 ... Przetwarzaj a99; |
Dzięki tablicom sprawę załatwia kilka linijek kodu, ponieważ indeksy komórek mogą być dowolnymi wyrażeniami arytmetycznymi (o sensownych wartościach):
for(i = 0; i < 100; i++) a[i] = odczyt_czujnikow; for(i = 0; i < 100; i++) Przetwarzaj a[i]; |
Tablica jest zmienną, zatem zanim będziesz się mógł cieszyć nią w programie, tablicę musisz odpowiednio zdefiniować. Na szczęście tablicę definiujesz prawie tak samo jak zmienną prostą. Składnia jest następująca:
typ nazwa[rozmiar]; |
| typ | – | określa typ komórek tablicy, czyli
rodzaj przechowywanych informacji. Możesz stosować
wszystkie poznane tutaj typy: int, unsigned, float i char |
| nazwa | – | określa nazwę tablicy w programie. Reguły tworzenia nazw tablic są identyczne jak dla zmiennych prostych. |
| rozmiar | – | liczba całkowita dodatnia, która określa liczbę komórek tablicy. |
Przykład:
int b[6]; |
Zostanie utworzona tablica o nazwie b, która będzie zawierała 6 komórek o indeksach: b[0], b[1], b[2], b[3], b[4], b[5]. W każdej komórce tablicy będzie można umieścić liczbę całkowitą ze znakiem.
Zwracam uwagę na ważny fakt, który wielu uczniów myli. Rozmiar w definicji tablicy jest liczbą jej komórek, a nie indeksem ostatniej komórki:
float x[100]; |
Ostatnią komórką tej tablicy jest x[99], a nie x[100]. Problem jest poważny, ponieważ kompilator nie sprawdza indeksów tablic. Jeśli zatem utworzysz taką tablicę i spróbujesz coś umieścić w nieistniejącej w niej komórce o indeksie 100, to przejdzie to niezauważenie w trakcie kompilacji. Jednak po uruchomieniu takiego programu może dochodzić do trudno wykrywalnych błędów. Każda zmienna zajmuje w pamięci komputera pewien obszar komórek. Zwykle te obszary leżą tuż obok siebie (bo tak jest sensownie i oszczędnie). Jeśli odwołasz się do komórki poza obszarem tablicy, to w rzeczywistości będziesz się odwoływał do jakiejś zmiennej, która akurat znajduje się w tym miejscu w pamięci. Umieszczenie danych w takiej komórce spowoduje nadpisanie i uszkodzenie danych przechowywanej w innej zmiennej. A wtedy o kłopoty nietrudno.
Tablicę można również utworzyć przez podanie zawartości komórek. Wygląda to następująco:
typ nazwa[] = {wartość_1, wartość_2, ..., wartość_n};
|
W wyniku powstanie tablica zawierająca tyle komórek, ile podałeś wartości w klamerkach. Nie musisz określać rozmiaru. Zwróć uwagę, że tutaj za klamerką zamykającą musi wystąpić średnik kończący definicję tablicy.
Przykład:
int a[] = {1,6,3,2,8};
|
Powstanie tablica o nazwie a, która zawiera 5 komórek. W komórkach tej tablicy zostaną umieszczone podane liczby:
a[0] ← 1 a[1] ← 6 a[2] ← 3 a[3] ← 2 a[4] ← 8 |
Bardzo użyteczne są tablice typu char. Komórki tych tablic zawierają znaki tekstu. Tekst w języku C jest tworzony ze znaków o kodach ASCII, które tworzą ciąg liter. Przyjęto konwencję, że za ostatnim znakiem tekstu umieszczany jest kod o wartości 0. Nosi on nazwę EOT (ang. End Of Text – Koniec Tekstu). Poniższa definicja:
char t[] = "Jasiek"; |
tworzy tablicę tekstową o nazwie t, która w poszczególnych komórkach zawiera kolejne literki tekstu:
| komórki | t[0] | t[1] | t[2] | t[3] | t[4] | t[5] | t[6] |
| zawartość | J | a | s | i | e | k |
|
Zwróć uwagę, że tablica zdefiniowana za pomocą tekstu zawsze ma rozmiar i 1 większy od liczby znaków w tekście, aby pomieścić EOT.
Najprościej wyświetlić zawartość tablicy znakowej, jeśli zawarty w niej tekst kończy się znakiem EOT. Uruchom poniższy program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 2.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
char t[]="Jasiek";
setlocale(LC_ALL,"");
printf(t);
return 0;
}
|
W programie tworzymy tablicę znakową t i umieszczamy w jej komórkach tekst, który następnie wyświetlamy za pomocą funkcji printf( ). Bardziej zrozumiałe stanie się to, gdy omówimy w następnym rozdziale adresy elementów. Na chwilę obecną przyjmij, że tablica znakowa jest równoważna tekstowi – oznacza to, że wszędzie tam, gdzie umieszczasz w programie tekst w cudzysłowach, możesz również umieścić tablicę znakową pod warunkiem, że zawarty w niej tekst kończy się znakiem EOF. Przykładem jest tutaj drugi program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 2.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
char t[]="Jasiek";
setlocale(LC_ALL,"");
printf("Tablica t zawiera tekst [%s]\n",t);
return 0;
}
|
W tym programie również powstaje identyczna tablica jak w poprzednim. Teraz jednak przekazujemy ją jako argument z tekstem formatującym. Format "%s" oznacza ciąg znaków (ang. string).
Możemy też wyświetlać pojedyncze komórki tablicy:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 2.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
char t[]="Jasiek";
int i;
setlocale(LC_ALL,"");
for(i = 0; t[i]; i++)
printf("t[%d] = '%c', kod %3u\n",i,t[i],t[i]);
return 0;
}
|
Jak widzisz, do dostępu do kolejnych komórek tablicy wykorzystaliśmy pętlę, dlatego napisałem, że pętle są przyjaciółkami tablic – komórki tablic przetwarza się w pętlach. Jak działa nasza pętla?:
for(i = 0; t[i]; i++) |
Na początku do zmiennej i trafia 0, będzie to indeks pierwszej komórki tablicy. Przed każdym obiegiem pobierana jest komórka t[i] i, jeśli jej zawartość jest różna od zera (czyli zawiera znak tekstu), to zostaje wypisany indeks komórki, jej zawartość jako znak oraz jej zawartość jako kod ASCII. Jeśli natomiast komórka t[i] zawiera zero, to jest to znak EOT, który nie zostanie wypisany. Pętla zakończy się, a wraz z nią zakończy działanie program.
Z tablicami liczbowymi postępujemy podobnie: jedynie nie można przekazać tablicy jako parametru dla printf( ). Musimy tablicę przetwarzać komórka po komórce.
Uruchom program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 2.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int a[] = {6,7,2,8,1,4,3,0,9,5}; // 10 liczb, komórki od a[0]...[9]
int i;
setlocale(LC_ALL,"");
printf("NORMALNIE: ");
for(i=0; i < 10; i++) printf("%3d",a[i]);
printf("\n\nWSPAK : ");
for(i=9; i >= 0; i--) printf("%3d",a[i]);
printf("\n\n");
return 0;
}
|
Tutaj tworzymy tablicę liczbową a i umieszczamy w niej dziesięć liczb całkowitych. Następnie w pierwszej pętli wyświetlamy te liczby od pierwszej do ostatniej, a w drugiej pętli od ostatniej do pierwszej.
Każda komórka tablicy jest normalną zmienną. Inicjujemy ją zatem tak samo jak zmienną za pomocą instrukcji przypisania. Jedyną różnicą jest to, że dodatkowo należy użyć indeksu, aby wybrać odpowiednią komórkę:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 4.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int a[] = {1,2,3,4,5}; // 5 liczb, komórki od a[0]...[4]
int i;
setlocale(LC_ALL,"");
printf("PRZED:\n");
for(i = 0; i < 5; i++) printf("a[%d] = %d\n",i,a[i]);
a[0] = 25;
a[1] = 59;
a[4] = 119;
printf("\nPO:\n");
for(i = 0; i < 5; i++) printf("a[%d] = %d\n",i,a[i]);
return 0;
}
|
W programie tworzymy tablicę i wypełniamy ją kolejnymi liczbami od 1 do 5. Wyświetlamy zawartość tej tablicy. Następnie do komórek o indeksach 0, 1 i 4 wpisujemy kolejno liczby 25, 59 i 119, po czym wyświetlamy ponownie zawartość komórek tablicy.
Największe korzyści mamy przypisując komórkom wartości w pętli. Poniższy program wypełnia tablicę kolejnymi 32 liczbami Fibonacciego:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 4.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int fibo[32];
int i;
setlocale(LC_ALL,"");
fibo[0] = 0; // pierwsze dwie liczby wpisujemy
fibo[1] = 1; // bezpośrednio do komórek tablicy
for(i = 2; i < 32; i++) fibo[i] = fibo[i-2] + fibo[i-1];
printf("Liczby Fibonacciego:\n");
for(i = 0; i < 32; i++) printf("f[%2d] = %7d\n",i,fibo[i]);
return 0;
}
|
W pętli możemy dowolnie wyliczać zawartości kolejnych komórek. Poniższy program wypełnia tablicę 1000 elementową kolejnymi liczbami pierwszymi. Liczby pierwsze są wyznaczane w dosyć ciekawy sposób:
W komórce o indeksie 0 zostaje umieszczona liczba 2, która jest jedyną liczbą parzystą i pierwszą. Następnie za kandydatów na liczby pierwsze będziemy brali kolejne liczby nieparzyste począwszy od 3. W osobnej zmiennej będzie pamiętana ilość liczb pierwszych w tablicy. Do wyszukiwania liczb pierwszych zastosujemy ich własność niepodzielności przez wcześniejsze liczby pierwsze, które będą pobierane z tablicy. Jeśli żadna z liczb w tablicy nie będzie dzieliła kandydata, to kandydat jest liczbą pierwszą i dopiszemy go do tablicy, zwiększając o 1 licznik znalezionych liczb pierwszych, gdy licznik osiągnie 1000, wyznaczanie się zakończy i program wypisze zawartość tablicy./*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 4.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
unsigned tlp[1000]; // tablica liczb pierwszych
unsigned p,i,j; // zmienne robocze
char test; // do testowania podzielności
setlocale(LC_ALL,"");
tlp[0] = 2; // pierwsza liczba pierwsza
p = 3; // pierwszy kandydat na liczbę pierwszą
for(i = 1; i < 1000; i++) // wyznacza kolejne liczby pierwsze
{
do
{
test = 1; // zakładamy, że p jest pierwsze
for(j = 1; j < i; j++) // sprawdzamy podzielność
if(!(p % tlp[j])) // jeśli p jest podzielne
{
test = 0; // to p nie jest pierwsze, wychodzimy
break;
}
if(!test) p += 2; // jeśli p nie jest pierwsze, to następne
} while(!test); // jeśli p jest pierwsze,
tlp[i] = p; // to dopisujemy je do tablicy
p += 2; // następne p
}
printf("1000 liczb pierwszych:\n\n");
for(i = 0; i < 1000; i++) printf("%5u",tlp[i]);
printf("\n\n");
return 0;
}
|
Program na pierwszy rzut oka może wydawać się skomplikowanym. Jeśli jednak go dokładnie przeanalizujesz i zrozumiesz, to okaże się w miarę prosty.
Na początku tworzymy tablicę tlp o 1000 komórkach, w której będą umieszczane kolejne znalezione liczby pierwsze. Tablicę inicjujemy liczbą 2, czyli początkową liczbą pierwszą.
Zmienna p służy do tworzenia liczby, której pierwszość będzie sprawdzana. Ustawiamy w niej liczbę 3, która jest nieparzysta – wszystkie liczby pierwsze oprócz 2 są liczbami nieparzystymi.
Rozpoczynamy pętlę główną. W każdym obiegu tej pętli będzie wyznaczana jedna liczba pierwsza, która zostanie wstawiona na końcu do tablicy tlp na pozycji i-tej. Liczbę tę wyznaczamy w pętli wewnętrznej, która wykonuje się dotąd, aż p stanie się liczbą pierwszą. Jak działa ta pętla? Na początku każdego jej obiegu ustawiamy zmienną pomocniczą test na 1. Zmienna ta będzie pamiętać fakt, iż p nie dzieliło się przez żadną z liczb w tablicy tlp. Sprawdzanie podzielności rozpoczynamy w pętli od liczby w komórce tlp[1]. Tutaj jest mały haczyk. Na początku w komórce tlp[1] nic sensownego nie ma. Zwróć jednak uwagę na warunek kontynuacji tej pętli:
j < i |
Warunek ten nie będzie prawdziwy dla j = 1, ponieważ 1 nie jest mniejsze od 1. W efekcie dla i = 1 pętla nie wykona się ani raz i zmienna test zachowa wartość 1, co spowoduje wyjście z pętli do...while. I bardzo dobrze, ponieważ w tej sytuacji mamy p równe 3, a jest to kolejna po 2 liczba pierwsza. Pętla główna umieści tę liczbę w komórce tlp[1], po czym zwiększy ją na 5 i cały proces się powtórzy. Przy drugim obiegu program sprawdzi podzielność 5 przez 3. Ponieważ liczby te się nie dzielą, nastąpi wyjście z pętli do...while i wstawienie 5 do komórki tlp[2]. Zmienna p znów zostanie zwiększona do 7 i proces się powtórzy. Teraz 7 będzie testowane na podzielność przez 3 i 5. Ponieważ liczba ta się nie dzieli przez 3 i 5, to znów nastąpi wyjście z wewnętrznej pętli do...while i umieszczenie 7 w komórce tlp[3]. Jak dotąd, tablica tlp zawiera liczby: 2 3 5 i 7. Zmienna p zostanie zwiększona na 9 i proces sprawdzania podzielności się powtórzy. Jednak teraz komputer stwierdzi, że 9 dzieli się przez 3. W takim przypadku zmienna test przyjmie wartość 0 i dalsze sprawdzanie podzielności zostanie przerwane, ponieważ już wiadomo, że 9 nie jest pierwsze. Ponieważ test ma wartość 0, to zadziała instrukcja if umieszczona za pętlą wewnętrzną for. Instrukcja zwiększy p o 2, czyli do p trafi liczba 11. Warunek kontynuacji w pętli do...while jest prawdziwy, zatem pętla ta wykona kolejny obieg testujący podzielność liczby 11. Ponieważ żadna z liczb w tablicy nie dzieli 11, otrzymamy kolejną liczbę pierwszą. Pętla do...while zostanie zakończona i komputer umieści p w kolejnej komórce tablicy tlp. Według tego samego schematu zostaną znalezione kolejne liczby pierwsze.
Z podanego przykładu wynika bardzo istotny wniosek: nauka programowania nie polega jedynie na opanowaniu jakiś tam instrukcji języka programowania. Podstawą zawsze jest Algorytmika. Jeśli chcesz dobrze programować, musisz koniecznie zapoznać się z Algorytmika, ponieważ w niej znajdziesz odpowiedzi, jak rozwiązuje się typowe problemy za pomocą komputera. Bez porządnych podstaw algorytmicznych twoje programy zawsze będą amatorskie.
W naszym serwisie jest bardzo obszerny artykuł o algorytmach. Proponuję ci się z nim zapoznać. Dobrze byłoby również przeczytać książkę Thomasa Cormena "Wprowadzenie do algorytmów", którą bez trudu znajdziesz w Internecie. Oczywiście do programowania prostych rzeczy na małych mikrokontrolerach nie potrzebujesz bardzo rozbudowanej wiedzy na temat algorytmów. Niemniej jest ona pomocna, ponieważ Algorytmika uczy właściwego podejścia do rozwiązywania problemów na komputerze. Musisz zacząć widzieć świat "oczami" komputera. Nie jest to proste, więc nie zniechęcaj się tylko ćwicz i ćwicz, a doczekasz się efektów.
Tutaj pokażemy kilka typowych algorytmów przetwarzania informacji w tablicach. Więcej na ten temat znajdziesz w podanym wcześniej artykule o algorytmach.
Zadaniem jest zsumowanie liczb, które przechowuje tablica. Zadanie wykonujemy bardzo prosto, przeglądając kolejne elementy tablicy:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 6.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int t[] = {6,-5,3,12,2-5,8,-22,9,0}; // tablica do sumowania
int suma = 0;
int i;
setlocale(LC_ALL,"");
for(i = 0; t[i]; i++) suma += t[i];
printf("Suma wynosi: %d\n\n",suma);
return 0;
} |
Program sumuje kolejne elementy w tablicy, aż do napotkania elementu o wartości 0. Element ten jest traktowany jako koniec danych. Dzięki takiemu podejściu nie musimy wiedzieć, ile elementów zawiera tablica.
Średnia arytmetyczna jest sumą elementów podzieloną przez ich liczbę. Wykorzystamy poprzedni program.
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 6.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int t[] = {6,-4,3,11,2-5,8,-20,9,0}; // tablica do sumowania
float suma = 0;
float srednia;
int i;
setlocale(LC_ALL,"");
for(i = 0; t[i]; i++) suma += t[i];
if(i)
{
srednia = suma / i;
printf("Srednia wynosi: %f\n\n",srednia);
}
else printf("Tablica jest pusta!\n\n");
return 0;
} |
Po wyliczeniu sumy (zwróć uwagę, że zmieniliśmy jej typ na float: dlaczego?) program sprawdza, czy liczba elementów w tablicy jest większa od 0. Jeśli tak, to liczy średnią i wypisuje ją. Jeśli nie, to wypisuje odpowiedni komunikat zamiast średniej. Ilość zsumowanych elementów zawiera zmienna i.
Zadaniem jest znalezienie w tablicy wszystkich elementów, które spełniają określony warunek, np. są równe jakiejś wartości. Zadanie rozwiązujemy przeglądając kolejne elementy tablicy i sprawdzając, czy bieżący element spełnia zadane kryterium. W programie rozmiar tablicy trzymamy w zmiennej n, co umożliwia umieszczanie w tablicy liczby 0.
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 6.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów
int t[] = {6,-4,3,11,2,-5,8,-20,9,1}; // tablica do przeszukania
int i;
setlocale(LC_ALL,"");
printf("Liczby dodatnie : ");
for(i = 0; i < n; i++) if(t[i] > 0) printf("%4d",t[i]);
printf("\nLiczby ujemne : ");
for(i = 0; i < n; i++) if(t[i] < 0) printf("%4d",t[i]);
printf("\nLiczby parzyste : ");
for(i = 0; i < n; i++) if(!(t[i] % 2)) printf("%4d",t[i]);
printf("\nLiczby podzielne przez 3 : ");
for(i = 0; i < n; i++) if(!(t[i] % 3)) printf("%4d",t[i]);
printf("\n\n");
return 0;
}
|
Czasami chcemy sprawdzić, czy dana wartość występuje w tablicy, a jeśli tak, to w której komórce. Zadanie rozwiązujemy przechodząc przez kolejne komórki tablicy aż do momentu, gdy znajdziemy dany element lub przejrzymy wszystkie komórki.
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 6.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów
int t[] = {6,-4,3,11,2,-5,8,-20,9,1}; // tablica do przeszukania
int v = -20; // poszukiwana wartość
int i;
setlocale(LC_ALL,"");
for(i = 0; i < n; i++) if(t[i] == v) break;
if(i < n) printf("Element %d na pozycji %d\n\n",v,i);
else printf("Elementu %d nie ma w tablicy\n\n",v);
return 0;
}
|
Zadanie znalezienia największego/najmniejszego elementu występuje często przy analizie pomiarów, które zebrano z czujników w pewnej tablicy. Wykonujemy je prosto przeglądając kolejne elementy tablicy i porównując je z zapamiętaną chwilową wartością maksymalną lub minimalną.
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 6.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów w tablicy
int t[] = {6,-4,3,11,2,-5,8,-20,9,1}; // tablica do przeszukania
int i,elmax,elmin;
setlocale(LC_ALL,"");
elmax = elmin = t[0];
for(i = 1; i < n; i++)
if (t[i] > elmax) elmax = t[i];
else if(t[i] < elmin) elmin = t[i];
printf("Element maksymalny: %3d\n",elmax);
printf("Element minimalny : %3d\n",elmin);
return 0;
}
|
Zadanie polega na znalezieniu w tablicy wartości, która powtarza się najczęściej. Tego typu operacje mogą być przydatne przy analizie pomiarów, które zarejestrował mikrokontroler z jakiegoś czujnika.
Najprostszy sposób rozwiązania tego problemu polega na przeglądaniu tablicy i zliczaniu wystąpień kolejnych elementów. W osobnych zmiennych pamiętamy najczęściej powtarzający się element oraz liczbę jego wystąpień. Jeśli bieżąco zliczony element ma większą liczbę wystąpień, to zapamiętujemy go w tych zmiennych.
Uruchom program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 6.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 100; // liczba elementów
int t[] = { 3, 6,13, 6, 5, 7, 2, 3, 1, 7,4, 3, 1, 7,12,15,11, 4, 8, 1,
5, 4, 9, 4, 8, 2, 6, 5, 4,11,3, 8,13, 4, 8, 6, 3, 7, 3, 8,
9, 5, 7, 8, 7, 9, 3,11, 7, 5,1,12, 6, 2, 1, 2, 6, 3,12,10,
11, 8, 1, 2, 9, 4, 8,15, 9, 2,0, 5, 3,17, 3, 3, 9,12, 5, 3,
2, 4, 0,10, 3, 2, 1, 4, 3,16,7, 2, 2, 1, 5, 4, 8, 1, 9, 2};
int lmax = 0; // licznik najczęstszej wartości
int vmax; // najczęstsza wartość
int ln; // licznik pomocniczy
int vn; // zliczana wartość
int i,j;
setlocale(LC_ALL,"");
for(i = 0; i < n; i++) // przeglądamy kolejne elementy
{
vn = t[i]; // zapamiętujemy bieżący element
ln = 1; // ustawiamy licznik jego wystąpień
for(j = i + 1; j < n; j++) // przeglądamy resztę tablicy
if(t[j] == vn) ln++; // i zliczamy bieżący element
if(ln > lmax) // jeśli bieżący powtarza się częściej od zapamiętanego,
{
lmax = ln; // to zapamiętujemy bieżący
vmax = vn;
}
}
printf("v = %d, n = %d\n\n",vmax,lmax);
return 0;
}
|
Zwróć uwagę, że wystąpienia elementu zliczamy od miejsca jego wystąpienia w tablicy w kierunku jej końca. Ma to sens, ponieważ jeśli ten element pojawił się w tablicy wcześniej, to został już zliczony. Takie podejście zmniejsza nieco czas działania programu przy dużych tablicach. Program można nieco ulepszyć, np. przerywając zliczanie, gdy liczba pozostałych elementów do zliczenia jest mniejsza od lmax (dlaczego?). Zadanie to pozostawiam ci jako ćwiczenie.
Sortowanie ma na celu uporządkowanie elementów tablicy w określonej kolejności, np. elementy są ułożone tak, że każdy następny jest większy lub równy swojemu poprzednikowi. Istnieje bardzo wiele algorytmów sortujących. W naszym serwisie jest na ten temat napisany obszerny artykuł, z którym proponuję ci się zapoznać.
Bardzo prostym algorytmem sortującym jest tzw. sortowanie bąbelkowe (ang. bubble sort). Polega ono na porównywaniu ze sobą dwóch elementów kolejnych par w tablicy. Jeśli porównywane elementy nie zachowują przyjętego porządku, to zamieniamy je miejscami. Operację tę prowadzimy dotąd, aż cała tablica zostanie uporządkowana.
Aby lepiej zrozumieć zasadę sortowania bąbelkowego, prześledźmy je na prostym przykładzie. Załóżmy, że mamy tablicę 5-cio elementową o początkowej zawartości:
{ 7 5 2 6 1 }
Tablicę chcemy posortować rosnąco.
{ 7?5 2 6 1 }
|
Sprawdzamy pierwszą parę liczb.
Liczby 7 i 5 są w złej kolejności. |
{ 5 7 2 6 1 }
|
Zamieniamy je miejscami. |
{ 5 7?2 6 1 }
|
Sprawdzamy drugą parę liczb. Znów kolejność jest zła. |
{ 5 2 7 6 1 }
|
Zamieniamy je miejscami. Zwróć uwagę, że liczba większa jest "ciągnięta" w kierunku końca tablicy. Natomiast liczby mniejsze przesuwają się w kierunku początku tablicy. |
{ 5 2 7?6 1 }
|
Sprawdzamy kolejną parę. |
{ 5 2 6 7 1 }
|
Zła kolejność. Liczby w parze zamieniamy miejscami. |
{ 5 2 6 7?1 }
|
Sprawdzamy ostatnią parę. |
{ 5 2 6 1 7 }
|
Zła kolejność. Liczby zamieniamy miejscami. Wykonaliśmy jeden przebieg sortujący. Zwróć uwagę, że największa liczba, 7, trafiła na koniec zbioru, czyli na swoje miejsce w tablicy posortowanej. W drugim obiegu sortującym nie musimy już tej liczby brać pod uwagę. |
{ 5?2 6 1 7 }
|
Drugi obieg sortujący. Testujemy pierwszą parę. |
{ 2 5 6 1 7 }
|
Kolejność jest zła, zamieniamy liczby miejscami. |
{ 2 5?6 1 7 }
|
Testujemy kolejną parę. Kolejność jest dobra, liczb nie zamieniamy miejscami. |
{ 2 5 6?1 7 }
|
Testujemy ostatnią parę liczb (ponieważ 7 jest już na swoim właściwym miejscu). |
{ 2 5 1 6 7 }
|
Kolejność jest zła. Liczby zamieniamy miejscami. Zakończyliśmy drugi obieg sortujący. Liczba 6 znalazła się na swoim miejscu. Pozostały do posortowania jeszcze trzy liczby. |
{ 2?5 1 6 7 }
|
Trzeci obieg sortujący. Testujemy pierwszą parę liczb. Są w dobrej kolejności. |
{ 2 5?1 6 7 }
|
Testujemy drugą parę liczb. |
{ 2 1 5 6 7 }
|
Kolejność jest zła, zatem liczby w parze zamieniamy miejscami. Liczba 5 trafia na swoje miejsce. Do posortowania zostały nam już dwie liczby. |
{ 2?1 5 6 7 }
|
Czwarty obieg sortujący. Testujemy pierwszą parę liczb. |
{ 1 2 5 6 7 }
|
Liczby są w złej kolejności.
zamieniamy je miejscami |
{ 1 2 5 6 7 }
|
Koniec sortowania. |
Wyciągamy następujące wnioski:
Z rozważań tych wyłania się następujący program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 7.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów
int t[] = {6,-4,3,11,2,-5,8,-20,9,1}; // tablica do przeszukania
int i,j,x;
setlocale(LC_ALL,"");
printf("Przed sortowaniem:");
for(i = 0; i < n; i++) printf("%4d",t[i]);
// sortowanie bąbelkowe
for(i = 1; i < n; i++) // wykonuje się n - 1 razy
for(j = 0; j < n - i; j++)
if(t[j] > t[j + 1]) // sprawdzamy kolejność
{
x = t[j]; // jeśli zła, elementy zamieniamy
t[j] = t[j + 1];
t[j + 1] = x;
}
printf("\n\nPo sortowaniu :");
for(i = 0; i < n; i++) printf("%4d",t[i]);
printf("\n\n");
return 0;
}
|
Algorytm sortowania bąbelkowego nie należy do specjalnie szybkich algorytmów sortujących. Jego zaletą jest prostota. Stosujemy go zwykle do małych tablic, jeśli nie zależy nam na szybkości działania.
Jako ćwiczenie zmodyfikuj ten program, tak aby tablica była porządkowana malejąco: od liczb największych do najmniejszych.
Dla większych tablic (do mniej więcej 5 tys. elementów) zalecany jest algorytm sortowania przez wstawianie (ang. insertion sort).
W algorytmie występuje pojęcie listy posortowanej (ang. sorted list). Jest to ciąg elementów, które są już posortowane. Taką listę możemy sobie tworzyć na początku lub na końcu tablicy. Załóżmy, że będzie ona powstawała na końcu tablicy. Początkowo lista posortowana zawiera ostatni element – zapamiętaj: jednoelementowa lista jest zawsze posortowana.
W obiegu sortującym wybieramy z tablicy element leżący tuż przed listą uporządkowaną, a następnie staramy się go umieścić wśród elementów tej listy, tak aby powstała nowa lista uporządkowana zawierająca o jeden element więcej. Operację tę kontynuujemy dotąd, aż lista uporządkowana obejmie całą tablicę.
Prześledźmy operacje dla tablicy o zawartości: { 7 5 2 6 1 }, którą posortujemy rosnąco.
{ 7 5 2 6 1 }
|
Na końcu tablicy mamy listę posortowaną, która początkowo zawiera tylko jeden element: 1 |
6 { 7 5 2 ▲ 1 } |
Z tablicy wybieramy element, który leży tuż przed listą posortowaną i zapamiętujemy go sobie. Miejsce zajmowane przez ten element możemy potraktować jako puste (tzn. z nieistotną zawartością). |
?6 { 7 5 2 ◄ 1 } |
Wybrany element będziemy porównywać z kolejnymi elementami listy. Porównujemy 6 z 1. 6 jest większe, zatem 1 przesuwamy na puste miejsce |
6 { 7 5 2 1 ▼ } |
Ponieważ lista się skończyła, 6 wstawiamy na puste miejsce. |
{ 7 5 2 1 6 }
|
Lista staje się dwuelementowa. |
2 { 7 5 ▲ 1 6 } |
Wybieramy przed listą kolejny element: 2. |
?2 { 7 5 ◄ 1 6 } |
Porównujemy go z pierwszym elementem listy, czyli z 1. 2 jest większe, 1 przesuwamy na wolne miejsce |
?2 { 7 5 1 ▼ 6 } |
2 porównujemy z 6. Ponieważ 6 jest większe, to 2 wstawiamy na puste miejsce za 1. |
{ 7 5 1 2 6 }
|
Lista znów się powiększa i obejmuje już trzy elementy. |
5 { 7 ▲ 1 2 6 } |
Wybieramy kolejny element przed listą posortowaną, 5. |
?5 { 7 ◄ 1 2 6 } |
5 porównujemy z 1. 1 przesuwamy na wolne miejsce, ponieważ jest mniejsze |
?5 { 7 1 ◄ 2 6 } |
5 porównujemy z 2. 2 przesuwamy na puste miejsce. |
?5 { 7 1 2 ▼ 6 } |
5 porównujemy z 6. 6 jest większe, więc 5 wstawiamy na wolne miejsce. |
{ 7 1 2 5 6 }
|
Lista posortowana się rozrasta i obejmuje 4 elementy. |
7 { ▲ 1 2 5 6 } |
I ostatni obieg. Wybieramy 7. |
?7 { ◄ 1 2 5 6 } |
7 porównujemy z 1. 1 przesuwamy na wolne miejsce. |
?7 { 1 ◄ 2 5 6 } |
7 porównujemy z 2. 2 przesuwamy na wolne miejsce. |
?7 { 1 2 ◄ 5 6 } |
7 porównujemy z 5. 5 przesuwamy na wolne miejsce. |
?7 { 1 2 5 ◄ 6 } |
7 porównujemy z 6. 6 przesuwamy na wolne miejsce. |
7 { 1 2 5 6 ▼ } |
6 przesuwamy. Lista się skończyła, 7 wstawiamy na puste miejsce. |
{ 1 2 5 6 7 }
|
Koniec, lista posortowana obejmuje wszystkie elementy. |
Na postawie tych rozważań otrzymujemy następujący program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 7.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów
int t[] = {6,-4,3,11,2,-5,8,-20,9,1}; // tablica do przeszukania
int i,j,x;
setlocale(LC_ALL,"");
printf("Przed sortowaniem:");
for(i = 0; i < n; i++) printf("%4d",t[i]);
// sortowanie przez wstawianie
for(i = n - 2; i >= 0; i--) // pozycja wybieranego elementu
{
x = t[i]; // zapamiętujemy wybrany element
for(j = i+1; j < n; j++) // pozycja elementów listy
if(x <= t[j]) break;
else t[j - 1] = t[j]; // przesuwamy element listy
t[j - 1] = x; // wybrany element umieszczamy na liście
}
printf("\n\nPo sortowaniu :");
for(i = 0; i < n; i++) printf("%4d",t[i]);
printf("\n\n");
return 0;
}
|
W ramach ćwiczeń zmodyfikuj ten program, tak aby tablica była porządkowana malejąco: od liczb największych do najmniejszych.
Tutaj opiszemy kilka przydatnych operacji na elementach tablic.
Operacja wygląda następująco:
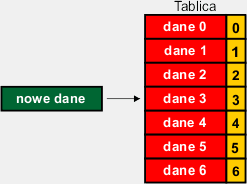 |
Mamy tablicę z pewną zawartością. W wybranej komórce chcemy umieścić nowe dane w ten sposób, iż znajdą się one pomiędzy danymi, które już się znajdują w tablicy – inaczej problem by nie istniał, wystarczyłoby po prostu wpisać dane do wybranej komórki. |
|
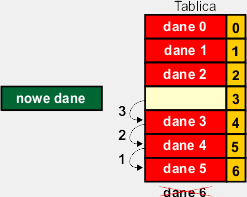 |
Najpierw musimy zrobić w tablicy miejsce na nowe dane przez przesunięcie komórek w dół tablicy (w kierunku większych indeksów). Operację tę nie można zrobić byle jak. Należy zacząć od przedostatniej komórki tablicy, której zawartość przemieszczamy do ostatniej – na rysunku operacja ta ma numer 1. Następnie przesuwamy w ten sam sposób zawartości kolejnych komórek aż dojdziemy do komórki, w której mają się znaleźć nowe dane. Spowoduje to przemieszczenie zawartości komórek w dół tablicy i uzyskanie wolnego miejsca w komórce, w której będziemy wstawiać dane. Zawartość ostatniej komórki tablicy jest tracona, ponieważ zostanie nadpisana zawartością komórki przedostatniej. |
|
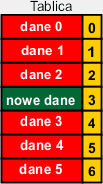 |
Na koniec dane umieszczamy w zwolnionej komórce. |
Uruchom program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 8.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów
int t[] = {6,-4,3,11,2,-5,8,-20,9,1}; // tablica do przeszukania
int i;
int p = 5; // pozycja wstawiania
int v = 999; // wstawiana wartość
setlocale(LC_ALL,"");
printf("Przed:\n");
for(i = 0; i < n; i++) printf("t[%d] =%4d\n",i,t[i]);
// wstawiamy element
for(i = n - 2; i >= p; i--) t[i+1] = t[i];
t[p] = v;
printf("\nPo:\n");
for(i = 0; i < n; i++) printf("t[%d] =%4d\n",i,t[i]);
printf("\n\n");
return 0;
}
|
Przebieg operacji jest następujący:
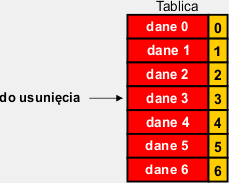 |
Chcemy usunąć dane z wybranej komórki tablicy, tak aby nie zostało po nich puste miejsce. |
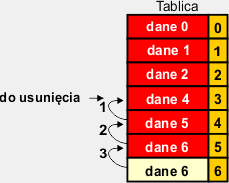 |
Odwrotnie niż w poprzedniej metodzie przesuwamy zawartość komórek leżących pod wybraną w górę, zaczynając od komórki następnej (operacja nr 1) i idąc kolejno do komórki ostatniej. W rezultacie usuwana komórka zostanie nadpisana przez zawartość następnej. Zwróć uwagę, że na końcu tablicy powstanie zdublowana zawartość ostatniej danej. |
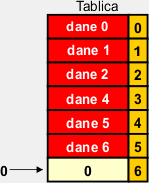 |
W ostatniej komórce umieszczamy wartość 0. |
Uruchom program:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 8.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int n = 10; // liczba elementów
int t[] = {6,-4,3,11,2,999,8,-20,9,1}; // tablica do przeszukania
int i;
int p = 5; // pozycja do usunięcia
setlocale(LC_ALL,"");
printf("Przed:\n");
for(i = 0; i < n; i++) printf("t[%d] =%4d\n",i,t[i]);
// usuwamy element
for(i = p + 1; i < n; i++) t[i-1] = t[i];
t[n-1] = 0;
printf("\nPo:\n");
for(i = 0; i < n; i++) printf("t[%d] =%4d\n",i,t[i]);
printf("\n\n");
return 0;
}
|
Tablica dwuwymiarowa jest tablicą posiadającą m komórek, z których każda jest tablicą o rozmiarze n. Mówimy, że taka tablica ma rozmiar m × n komórek. Tablicę dwuwymiarową możemy sobie wyobrazić jako posiadającą m wierszy i n kolumn:
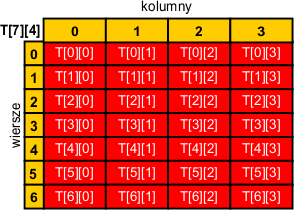
Tablicę dwuwymiarową tworzymy podobnie do tablicy jednowymiarowej. Różnica polega na dodaniu dodatkowego wymiaru:
typ nazwa_tablicy[liczba_wierszy][liczba_kolumn];
Na przykład:
int a[3][4]; |
Tutaj powstaje tablica dwuwymiarowa a posiadająca trzy wiersze oraz 4 kolumny. Dostęp do komórek tej tablicy odbywa się za pomocą dwóch indeksów: wierszowego i kolumnowego.
Na przykład instrukcja:
a[1][2] = 15; |
Umieści liczbę 15 w komórce tablicy a leżącej w wierszu nr 1 i w kolumnie nr 2:

Uruchom poniższy program. Pokazuje on sposób inicjalizacji tablicy dwuwymiarowej:
/*
Tablice
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 8.10.2016
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
int a[3][4] = {
{1,7,2,5},
{8,3,3,9},
{6,2,4,5}
};
int i,j;
setlocale(LC_ALL,"");
for(i = 0; i < 3; i++)
{
for(j = 0; j < 4; j++) printf("%2d",a[i][j]);
printf("\n");
}
return 0;
} |
Inicjalizacja tablicy dwuwymiarowej nie różni się od inicjalizacji tablicy jednowymiarowej. Musisz jedynie pamiętać, że język C traktuje tablicę dwuwymiarową jak tablicę jednowymiarową, której komórki są również tablicami. Dlatego odwołanie do komórki tablicy dwuwymiarowej jest dwuetapowe:
nazwa_tablicy[indeks_wierszowy]
To jest odwołanie to komórki tablicy głównej. Następnie odwołujemy się do komórki tablicy, która znajduje się wewnątrz komórki tablicy głównej:
nazwa_tablicy[indeks_wierszowy][indeks_kolumnowy]
Tak samo działa przypisanie. Przypisujemy dane kolejnym komórkom tablicy głównej:
{
dane dla komórki o indeksie 0,
dane dla komórki o indeksie 2,
...
dane dla komórki o indeksie m-1
} |
Ponieważ każda komórka tablicy głównej sama jest tablicą, to dane dla niej muszą przyjąć postać listy w klamerkach:
{
{dana, dana, ..., dana},
{dana, dana, ..., dana},
...
{dana, dana, ..., dana}
} |
W efekcie powstaje coś takiego:
int a[3][4] = {
{1,7,2,5},
{8,3,3,9},
{6,2,4,5}
}; |
Zapisałem tę inicjalizację, tak aby była czytelna. Ty też staraj się robić podobnie, bo taka inicjalizacja, chociaż zupełnie poprawna, nie jest specjalnie czytelna:
int a[3][4] = {{1,7,2,5},{8,3,3,9},{6,2,4,5}};
|
Liczba wymiarów tablicy może być większa niż 2, jednak pamiętaj, że zapotrzebowanie na pamięć rośnie bardzo szybko. Na przykład poniższa tablica:
char t[8][8][10][10]; |
zajmie w pamięci:
8 × 8 × 10 × 10 = 6400 komórek
Jak to policzyliśmy? Tablica czterowymiarowa jest przez język C traktowana jako jednowymiarowa tablica, której komórki są tablicami trójwymiarowymi. Z kolei tablice trójwymiarowe są traktowane jako jednowymiarowe o komórkach będących tablicami dwuwymiarowymi, itd. Jeśli zrozumiesz tę regułę, to stanie się to dla ciebie zupełnie proste.
Zatem tablica t posiada 8 komórek-tablic trójwymiarowych. Każda ich komórka jest tablicą zawierającą 8 komórek-tablic dwuwymiarowych. Otrzymujemy 8 × 8 komórek-tablic dwuwymiarowych. Tablice dwuwymiarowe posiadają po 10 komórek-tablic jednowymiarowych, otrzymujemy 8 × 8 × 10 tablic jednowymiarowych. Każda tablica jednowymiarowa ma 10 komórek, czyli ostatecznie liczba wszystkich komórek w tablicach jednowymiarowych wynosi 8 × 8 × 10 × 10 = 6400. Każda komórka przechowuje daną typu char o rozmiarze 1 bajtu, zatem całość zajmuje 6400 bajtów w pamięci. Jak na mikrokontroler to całkiem sporo. Na szczęście rzadko potrzebujemy tablic więcej niż dwuwymiarowych przy programowaniu mikrokontrolerów.
Zapraszamy do następnego rozdziału.
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
