|
Serwis Edukacyjny
Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny
Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu |
©2026 mgr Jerzy Wałaszek
|
Podstawowym językiem programowania każdego mikrokontrolera jest kod maszynowy (ang. machine code). Jednakże ma on postać zupełnie nieczytelną dla człowieka, ponieważ składa się z instrukcji kodowanych bitami. Program w kodzie maszynowym może wyglądać następująco:
01111011 11100010 10111110 11010100 ... |
Aby uczynić go bardziej zrozumiałym dla człowieka, wymyślono język symboliczny asemblera (ang. assembly language). Program w języku asemblera bezpośrednio konwertuje się na instrukcje, które rozumie mikroprocesor zawarty wewnątrz mikrokontrolera. Jednakże asembler jest dosyć skomplikowany w użyciu, ponieważ nie przypomina on języka naturalnego. Instrukcje są kodowane za pomocą tzw. mnemoników, czyli nazw kilkuliterowych, które kojarzą się z wykonywaną przez instrukcję operacją. Na przykład (nie odnosi się do żadnego konkretnego mikrokontrolera):
... mov a,r1 ;przenieś zawartość a do rejestru r1 add b,r1 ;do rejestru r1 dodaj zawartość b mov r1,c ;wynik umieść w c ... |
Każdy wiersz zawiera jedną instrukcję, która zostanie przetłumaczona na pojedynczy rozkaz dla mikroprocesora. Sens tych instrukcji nie jest widoczny od razu – program należy przeanalizować. Co więcej, tak napisany program nie będzie przenośny i jest trudny w modyfikacji. Zmiana nawet jednej instrukcji może spowodować nieoczekiwane efekty. O wiele lepiej byłoby zapisać to tak:
... c = a + b; ... |
Od razu wzrosła czytelność. Na tym właśnie polega programowanie w języku wysokiego poziomu (asembler jest językiem niskiego poziomu). Przykładem takiego języka jest język C. Dlaczego język ten stał się tak popularny. Spowodowała to jego niesamowita efektywność. Programy pisane w języku C są prawie tak szybkie, jak programy pisane w asemblerze. Wygoda pisania w C jest o całe niebo większa. Programy są czytelniejsze i łatwiejsze do modyfikowania. Co więcej, jeśli jakiś fragment musi być naprawdę szybki, to zawsze część kodu możemy zapisać w asemblerze.
Język C powstał jako następca języka B w końcu lat 60-tych ubiegłego wieku. Jego twórcą jest Denis Ritchie, informatyk z Bell Telephone Laboratories. O potędze języka C może świadczyć fakt, iż za jego pomocą napisane zostało jądro (czyli procedury wykonawcze) profesjonalnego systemu Unix, na bazie którego powstał popularny dzisiaj system Linux. Również Windows posiada większość kodu napisanego w języku C.
Język C jest językiem kompilowanym. Oznacza to, że tworzenie programu składa się z dwóch faz:
Podany tutaj kurs uczy podstaw programowania w języku C i skupia się na tych aspektach, które są niezbędne przy programowaniu mikrokontrolerów. Język programowania jest jak język obcy. Należy nauczyć się jego reguł (gramatyki) oraz poleceń (słówek), aby się nim posługiwać. Biegłość przychodzi z czasem. Jeśli początkowo coś ci nie będzie wychodziło, nie zniechęcaj się. To normalne. Gdy nabędziesz praktyki, programowanie w C okaże się bardzo proste.
Na bazie języka C powstał nowszy standard, zwany językiem C++. Autorem tego projektu jest duński informatyk Bjarne Stroustrup. Język C++ jest bardzo nowoczesnym językiem programowania, który daje programiście potężne narzędzie wyposażone w obiekty, dziedziczenie, przeciążanie operatorów i funkcji, itp. Niestety, język C++ posiada pewne wymagania sprzętowe i trudno jest go uruchomić na malutkich mikrokontrolerach PIC czy AVR. W pewnym dialekcie języka C++ programowana jest platforma Arduino.
Jeśli celem twoim jest programowanie małych mikrokontrolerów, to raczej nie uruchomisz na nich programu w C++. Jednak nie martw się. Prawie wszystko, co znajdziesz w języku C, występuje również w C++. Więc nauka języka C nie pójdzie na marne, gdy w przyszłości, prawdopodobnie bliskiej, zechcesz się przesiąść na większe mikrokontrolery i rozpocząć przygodę z C++. Na razie opanuj dobrze język C, który jest znacznie prostszy od C++.
Do nauki programowania w języku C będziesz potrzebował aplikacji Code::Blocks. Zainstaluj ją wg instrukcji, którą znajdziesz po kliknięciu w podane hiperłącze. Dlaczego Code::Blocks? Po prostu dlatego, że korzystam z tej aplikacji już kilka lat i uważam, że jest dobra. W sumie może to być dowolne inne środowisko dla języka C. Jednak do nauki programowania Code::Blocks jest wręcz idealny: darmowy, legalny, posiada tę samą wersję dla Linuksa i dla Windows, prosty w obsłudze. Czegóż potrzeba nam więcej na początek.
Tutaj drobna uwaga: w Code::Blocks będziemy tworzyć programy dla komputera PC, nie dla mikrokontrolerów, ponieważ ma być to w założeniu nauka podstaw języka C. Jak ją zakończysz, powinieneś być w stanie zaprogramować w tym języku dowolny mikrokontroler, jeśli tylko opanujesz jego specyfikację techniczną – odpowiednie informacje zawsze znajdziesz w dokumentacji technicznej mikrokontrolera, którą producenci zwykle udostępniają w sieci Internet. Jednakże zrozumienie tej dokumentacji wymaga znajomości techniki cyfrowej, nie pomijaj zatem rozdziałów, które opisują własności różnych elementów elektronicznych.
Przed rozpoczęciem kursu przygotuj na swoim dysku katalog o nazwie cprj i zapisz sobie, gdzie ten katalog się znajduje. W katalogu cprj będą powstawały kolejne projekty programów, które napiszesz w Code::Blocks.
Uruchom Code::Blocks. Okno robocze podzielone jest na kilka obszarów:
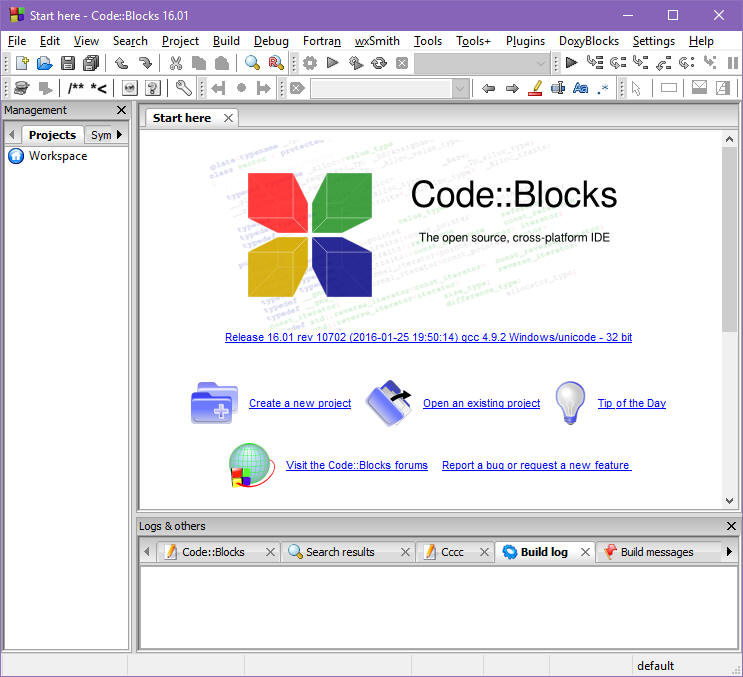
U góry znajdują się paski z ikonami narzędzi, po lewej stronie jest panel zarządzania projektem (włączasz/wyłączasz go klawiszami Shft+F2), na spodzie jest panel wiadomości (włączasz/wyłączasz go klawiszem F2), natomiast centralnie umieszczone jest okno robocze. Po uruchomieniu Code::Blocks pojawi się tutaj okno startowe. Kliknij w opcję Create a new project (Tworzenie nowego projektu). W okienku dialogowym wybierz jako kategorię Console application (aplikacja konsoli):
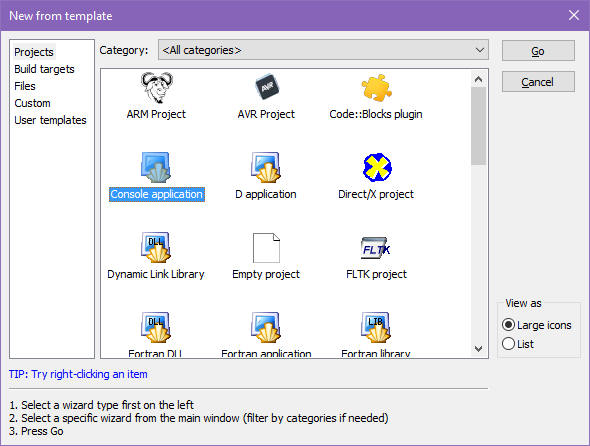
Co to jest aplikacja konsoli? Kiedyś, dawno temu, gdy jeszcze nie powstał system Windows, komputery programowane były w systemie DOS (ang. Disk Operating System – dyskowy system operacyjny) w trybie znakowym. Ekran wyświetlał ustalony zestaw znaków. Tryb ten pojawia się czasem na niektórych starszych komputerach IBM-PC przy starcie systemu, zanim Windows/Linux przejmą kontrolę. Ekran w trybie tekstowym wyglądał tak:

Na dzisiejszych komputerach tryb ten stał się już przestrzały, jednak wciąż możemy go symulować w Windows oraz w Linuxie. Zaletą konsoli jest prostota używania. Nie musisz walczyć z procedurami graficznymi Windows, aby wyświetlić wynik działania swojego programu: po prostu przesyłasz do konsoli tekst, a ten zostanie wyświetlony na ekranie monitora. Gdy będziesz programował mikrokontrolery, to nawet taka prosta konsola często nie będzie dostępna. Ale o tym później.
Gdy wybierzesz aplikację konsoli, to twój program otrzyma możliwość wysyłania tekstu do konsoli oraz odczytywania informacji, którą użytkownik wprowadził z klawiatury. Zatwierdź okienko kategorii projektu, klikając w przycisk Go. Następne okienko służy do wyboru języka programowania dla twojego projektu. Wybierz C, nie C++:
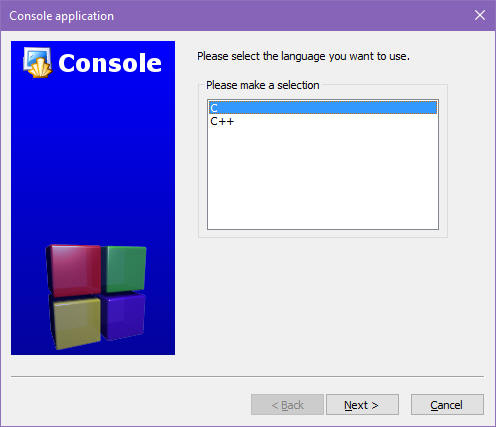
Język C++ jest młodszym bratem języka C, który udostępnia nowe możliwości. On również jest stosowany do programowania mikrokontrolerów, tylko tych większych, 32-bitowych, o mocniejszych parametrach. Zatwierdź okienko, klikając w przycisk Next.
Kolejne okienko jest bardzo ważne i musisz je wypełnić uważnie:
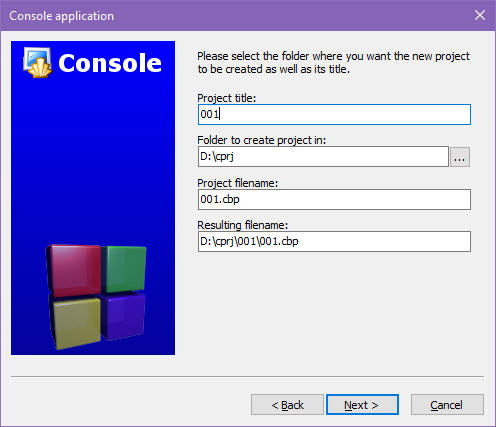
W polu Project title (tytuł/nazwa projektu) wpisujesz nazwę dla swojego projektu. Proponuję nazwy zbudowane z trzech cyfr będących kolejnymi numerami 001, 002... Później projekty możesz nazywać wg swojego uznania.
W polu Folder to create project in (katalog, w którym ma zostać utworzony projekt) wpisz ścieżkę do swojego katalogu cprj, który wcześniej założyłeś sobie na dysku, nie sugeruj się moim wpisem na powyższym obrazku. Pole to jest zapamiętywane i przy następnym projekcie pojawi się już odpowiednio wypełnione.
Pozostałych pól tekstowych nie zmieniaj. Program wypełnia je automatycznie wg dwóch pierwszych pól. Kliknij w Next.
Ostatnie okienko umożliwia wybór kompilatora oraz konfiguracji. Konfiguracje mamy dwie:
Konfiguracje te są istotne przy dużych projektach. W twoim przypadku zaznacz konfigurację Debug i odznacz Release:
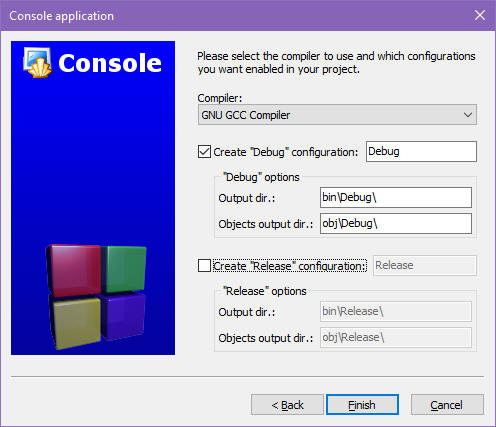
Nie zmieniaj zawartości pozostałych pól tekstowych, ponieważ określają one katalogi w obrębie katalogu projektowego, w których znajdziesz pliki wynikowe, do których wkrótce przejdziemy. Kliknij w przycisk Finish.
Projekt został utworzony. W panelu Management (zarządzanie) powinno pojawić się na zakładce Projects drzewko struktury twojego projektu (jeśli nie widzisz tego panelu, naciśnij Shft+F2).
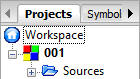
Gałąź Sources (źródła) zawiera pliki z tekstem programu, który tworzysz. Kliknij w znak + obok symbolu katalogu. Powinien pojawić się symbol pliku main.c:
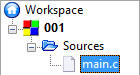
Pliki zawierające tekst programu w języku C mają rozszerzenie nazwy c lub cc. Program może się składać z wielu takich plików. Głównym jest plik o nazwie main.c, który jest automatycznie tworzony w Code::Blocks. Kliknij dwukrotnie myszką w nazwę main.c. Spowoduje to wczytanie pliku z dysku i otwarcie go w wewnętrznym edytorze:
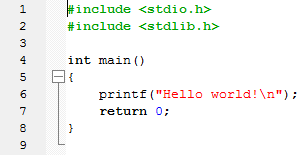
Edytor Code::Blocks zapewnia kolorowanie składni, tzn. wyświetla tekst programu różnymi kolorami w zależności od funkcji elementów.
Program w języku C składa się z wierszy. Wiersze te mogą być w edytorze numerowane, co pozwala szybko odnaleźć szukany wiersz. Omówmy krótko to, co widzisz w edytorze.
Dwa pierwsze wiersze są tzw. dyrektywami preprocesora. Dyrektywy preprocesora rozpoczynają się znakiem #, po którym następuje nazwa dyrektywy oraz jej ewentualne parametry. Preprocesor jest częścią kompilatora. Gdy plik źródłowy jest przetwarzany na program wynikowy w czasie kompilacji, to najpierw zostaje obrobiony przez preprocesor, a wynik z preprocesora trafia do kompilatora. Przetwarzając plik, preprocesor wczytuje kolejne wiersze programu i szuka w nich swoich dyrektyw, po czym dyrektywę usuwa z tekstu i zastępuje ją wynikiem dyrektywy. Dyrektywa #include zostaje zastąpiona treścią tzw. pliku nagłówkowego z rozszerzeniem h (ang. heading – nagłówek). Pliki nagłówkowe są rozprowadzane z kompilatorem lub mogą być tworzone przez użytkownika. Zawierają one definicje często wykorzystywanych w programach elementów. Dzięki plikom nagłówkowym definicji tych nie musisz każdorazowo wpisywać ręcznie.
Wróćmy do naszego programu. Po przetworzeniu przez preprocesor kompilator otrzyma plik, w którym w miejscu dyrektywy #include <stdio.h> znajdzie się zawartość pliku nagłówkowego stdio.h, a w miejscu dyrektywy #include <stdlib.h> zostanie umieszczona zawartość pliku stdlib.h. Mechanizm ten jest dla kompilatora zupełnie przezroczysty. Nawet nie będzie wiedział, że w twoim pliku były jakieś dyrektywy preprocesora. Powstanie jeden plik złożony z trzech plików: stdio.h, stdlib.h i reszty main.c. Ten plik kompilator przetworzy i na jego podstawie zbuduje program wykonywalny.
Dalej mamy tzw. funkcję main( ). Funkcjami zajmiemy się dokładnie później. Teraz wystarczy, abyś wiedział, że funkcja jest to fragment programu, któremu nadaliśmy nazwę. Nazwa twojej własnej funkcji może być dowolna, np. bubu( ) czy yogi( ), lecz nazwa main( ) jest zastrzeżona dla tzw. funkcji głównej. Każdy program w języku C musi posiadać dokładnie jedną funkcję o nazwie main( ), ponieważ od tej funkcji rozpoczyna się wykonanie programu.
Treść funkcji umieszczamy w klamerkach za jej nazwą. W edytorze tekst zawarty w klamerkach można ukryć, klikając w kwadrat z minusem obok klamry otwierającej. Przydaje się to wtedy, gdy w klamrach znajduje się dużo kodu, a chcemy sprawdzić strukturę (czyli budowę) danej instrukcji zawierającej klamry (instrukcje takie, zwane blokowymi, poznasz w dalszej części kursu). W naszej funkcji main( ) mamy tutaj dwa elementy:
Zwróć uwagę, że na końcu każdej instrukcji wewnątrz klamerek umieszczony jest średnik. Średnik pełni tutaj rolę znaku kończącego daną instrukcję. Jeśli go pominiesz, kompilator zgłosi błąd w czasie kompilacji.
Argumentem funkcji printf( ) jest tekst, czyli ciąg znaków. Teksty w języku C umieszczamy w cudzysłowach. Na końcu tekstu jest tzw. znak sterujący \n. Oznacza on nowy wiersz (ang. new line). O co tutaj chodzi? Znak nowego wiersza \n powoduje, że następny tekst pojawi się w oknie konsoli w nowym wierszu. Przećwiczysz to w następnym rozdziale.
Co zatem robi nasz program? Po uruchomieniu przesyła do konsoli znakowej tekst Hello world!, przenosi wydruk do następnego wiersza i kończy działanie, zwracając wartość 0.
Jak uruchomić ten program? Najpierw musisz go skompilować, czyli zamienić w plik binarny zawierający rozkazy dla mikroprocesora. Na pasku narzędziowym u góry okna roboczego kliknij ikonę żółtego koła zębatego (lub naciśnij Ctrl+F9). W panelu dolnym pojawi się komunikat z kompilacji:
| -------------- Build: Debug in 001 (compiler: GNU GCC Compiler)--------------- mingw32-gcc.exe -Wall -g -c D:\cprj\001\main.c -o obj\Debug\main.o mingw32-g++.exe -o bin\Debug\001.exe obj\Debug\main.o Output file is bin\Debug\001.exe with size 28.47 KB Process terminated with status 0 (0 minute(s), 2 second(s)) 0 error(s), 0 warning(s) (0 minute(s), 2 second(s)) |
| -------------- Build: Debug in 001 (compiler: GNU GCC Compiler)--------------- gcc -Wall -g -c /home/geo/cprj/001/main.c -o obj/Debug/main.o g++ -o bin/Debug/001 obj/Debug/main.o Output file is bin/Debug/001 with size 9,45 KB Process terminated with status 0 (0 minute(s), 0 second(s)) 0 error(s), 0 warning(s) (0 minute(s), 0 second(s)) |
Ważny jest ostatni wiersz. Jeśli pojawi się w nim napis: 0 error(s), 0 warning(0) (0 błędów, 0 ostrzeżeń), to kompilacja przebiegła bezproblemowo i program jest gotowy do uruchomienia. Program znajduje się w katalogu ...cprj/bin/Debug. Możesz go uruchomić albo z poziomu IDE, albo z okna konsoli/terminala. Z poziomu IDE uruchomienie skompilowanego programu jest bardzo proste: kliknij myszką zieloną strzałkę na pasku narzędziowym u góry okna lub naciśnij klawisze Ctrl+F10. Zostanie otworzone okienko konsoli i pojawi się w nim napis Hello world! Jeśli jesteś pewny, że program nie zawiera błędu, to możesz jednocześnie go skompilować i uruchomić, klikając ikonę kółka zębatego i strzałki lub naciskając klawisz F9.
Z poziomu okienka konsoli lub terminala też możesz uruchomić swój program.
Windows:
Wciśnij klawisze Windows+R i wpisz w polu tekstowym cmd. Otworzy się okno konsoli Windows. Wpisz w nim:
cd ścieżka do katalogu cprj\001\bin\debug |
Następnie wpisz:
001 |
Linux:
Wciśnij Ctrl+Alt+T. W terminalu wpisz:
cd ścieżka do katalogu cprj/001/bin/Debug |
Następnie wpisz:
./001 |
Gotowe. Właśnie utworzyłeś i uruchomiłeś pierwszy program w języku C. Nie usuwaj tego programu, gdyż w następnej sekcji pobawimy się nieco wyświetlaniem tekstu w oknie konsoli.
Zakładam, że uruchomiłeś program z poprzedniej sekcji. Jeśli nie, to wróć i uruchom go wg podanych tam wskazówek.
Programując mikrokontrolery, z tekstem spotkasz się wtedy, gdy będziesz musiał przesłać do jakiegoś urządzenia informację w postaci literek, np. wyniku przetwarzania informacji odczytanej z czujników.

Zwykle nie będzie wtedy dostępna funkcja printf( ) (ang. print formatted text – wypisz tekst sformatowany), lecz coś do niej podobnego. Funkcja printf( ) została zaprojektowana do pracy z konsolą znakową/terminalem na dużym komputerze, który jest wyposażony w monitor ekranowy. Niemniej jednak musisz opanować sposób posługiwania się funkcją printf( ), aby ukończyć ten kurs.
Język C w swojej definicji nie zawiera żadnych instrukcji wejścia/wyjścia. Komunikacja z urządzeniami zewnętrznymi w całości opiera się na bibliotekach funkcji. Aby w programie uzyskać dostęp do tych funkcji, musisz dołączyć do niego odpowiedni plik nagłówkowy z ich definicjami. W naszym przypadku plik ten nazywa się stdio.h (ang. standard input/output functions – standardowe funkcje wejścia/wyjścia). Zwróć uwagę, że dołączony on został na samym początku programu za pomocą dyrektywy preprocesora #include <stdio.h>. To właśnie w tym pliku jest zdefiniowana funkcja printf( ).
Tekst składa się z ciągu liter, który umieszcza się wewnątrz cudzysłowów. Na przykład tak: "ABC", "Nazwisko", "Kuba"... Aby wyświetlić tekst, umieść go wewnątrz nawiasów funkcji printf( ). Zmień program w edytorze na poniższy:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("Witaj w języku C");
printf("----------------");
return 0;
}
|
Program w założeniu ma wyświetlić dwa wiersze. Drugi wiersz jest podkreśleniem pierwszego.
Po uruchomieniu dostaniesz w oknie konsoli/terminala coś takiego:
| Witaj w jŕzyku C---------------- Process returned 0 (0x0) execution time : 0.009 s Press any key to continue. |
| Witaj w języku C---------------- Process returned 0 (0x0) execution time : 0.003 s Press ENTER to continue. |
Dwa ostatnie wiersze pochodzą od środowiska Code::Blocks i nie pojawią się, jeśli uruchomisz swój program z poziomu konsoli/terminala.
Pierwszym problemem jest to, iż podkreślenie wcale nie zostało wyświetlone pod tekstem, lecz obok niego. Przy wyświetlaniu tekstu w konsoli komputer wykorzystuje tzw. pozycję druku. Okno konsoli podzielone jest na określoną liczbę wierszy i kolumn, w których mogą pojawiać się znaki (podobnie będzie przy wyświetlaczach znakowych stosowanych w układach mikrokontrolerowych). Pozycja druku, którą komputer pamięta, określa wiersz i kolumnę w wierszu, gdzie pojawi się kolejny znak tekstu. Pierwsza funkcja printf( ) wyświetliła tekst Witaj w języku C i pozostawiła pozycję wydruku za literą C (oznaczoną tutaj kolorem czerwonym):
W |
i |
t |
a |
j |
|
w |
|
j |
ę |
z |
y |
k |
u |
|
C |
|
|
Druga funkcja printf( ) rozpocznie wyświetlanie tekstu od tej właśnie pozycji, dlatego ciąg minusów pojawi się zaraz za literką C. Zwróć uwagę, że nie ma tutaj nic do rzeczy sposób zapisu tego tekstu w programie. Aby podkreślenie trafiło pod tekst, musisz w poprzedzającym je tekście umieścić znak specjalny, który przeniesie pozycję wydruku na początek następnego miejsca. Taki znak nazywamy znakiem sterującym (ang. control character), ponieważ nie jest on wyświetlany, lecz powoduje jakieś inne działanie w oknie konsoli. Potrzebnym znakiem jest znak nowego wiersza (ang. new line), który oznaczamy w tekście za pomocą dwóch znaków: \n. Pierwszy znak, backslash, ukośnik, informuje funkcję printf( ), że następny znak należy potraktować specjalnie. W tym przypadku znak \n powoduje przeniesienie pozycji wydruku na początek następnego wiersza. Zmień program w edytorze:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("Witaj w języku C\n");
printf("----------------\n\n");
return 0;
}
|
Teraz otrzymasz:
| Witaj w jŕzyku C ---------------- Process returned 0 (0x0) execution time : 0.009 s Press any key to continue. |
| Witaj w języku C ---------------- Process returned 0 (0x0) execution time : 0.003 s Press ENTER to continue. |
Problem rozwiązany. Tekst w edytorze możesz dzielić na dowolną liczbę wierszy tekstu. Wpisz program:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("Witaj w języku C\n"
"----------------\n\n");
return 0;
}
|
Co tutaj się zmieniło: podzieliliśmy tekst na dwa teksty, które kompilator i tak połączy w jeden ciąg znaków. Jednak taki sposób podziału tekstu na wiersze jest bardziej czytelny od takiego, który również jest zupełnie poprawny:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("Witaj w języku C\n----------------\n\n");
return 0;
}
|
Jednak przy podziale tekstu nie możesz zapomnieć o cudzysłowach. Poniższy program nie skompiluje się, ponieważ nie można jednego tekstu umieszczać w kilku wierszach bez podziału na fragmenty za pomocą cudzysłowów:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("Witaj w języku C\n
----------------\n\n");
return 0;
}
|
Gdy spróbujesz skompilować ten program, w wierszu 6 pojawi się czerwony kwadrat. Oznacza on miejsce wykrycia błędu przez kompilator:
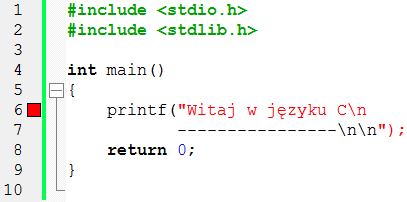
Jaki to jest błąd, przeczytasz w panelu wiadomości na spodzie okna Code::Blocks (jeśli nie masz tego panelu, naciśnij klawisz F2). Błędów może być kilka, lecz pierwszy jest opisany jako:
D:\cprj\001\main.c|6|warning: missing terminating " character| |
Wiadomość ta mówi, że brakuje kończącego znaku cudzysłowu, czyli w wierszu jest nie zamknięty cudzysłowem tekst. Błąd jest również w wierszu nr 7. Tutaj z kolei brak cudzysłowu otwierającego. Kolor czarny tekstu jest wskazówką, że ten fragment nie został rozpoznany jako tekst – standardowo tekst jest wyświetlany w kolorze czerwonym przez edytor Code::Blocks.
Drugi problem występuje w kochanym systemie Windows. Komputer źle wyświetla w konsoli znakowej polskie znaki. W Linuksie tego błędu nie ma. Spowodowane to jest radosną twórczością firmy Microsoft, która sprawiła, że polskie litery w konsoli i w Windows są wyświetlane inaczej. Aby to zrozumieć, musisz wiedzieć, że każdy znak posiada tzw. kod, czyli ma przypisany numer. Np. literka A posiada numer 65, literka B posiada numer 66, itd. Niestety, polskie litery mogą być kodowane w różny sposób, czyli mogą posiadać różne kody w różnych standardach. Problem ten rozwiązuje definitywnie dopiero system Unicode. W Linuksie powszechnie stosuje się standardowe kodowanie w całym systemie, dlatego polskie literki w programie i w terminalu wyglądają tak samo. W Windows polskie znaki mają inne kody niż w konsoli. Jeśli prześlemy do konsoli znakowej tekst "język", to literka ę będzie przesłana z kodem Windows. Jednak w konsoli kod ten nie reprezentuje literki ę, lecz literkę ŕ. Z innymi znakami polskimi jest podobnie. Przy programowaniu wyświetlaczy sterowanych przez mikrokontrolery również możesz napotkać na ten sam problem. Są cztery rozwiązania:
W tekście możemy umieścić znak o dowolnym kodzie za pomocą ukośnika oraz notacji ósemkowej (patrz: następny rozdział). Kod znaku zapisujemy tutaj za pomocą 3 cyfr ósemkowych wg poniższej tabelki:
| Ą | Ć | Ę | Ł | Ń | Ó | Ś | Ź | Ż | ą | ć | ę | ł | ń | ó | ś | ź | ż | |
| ósemkowo | \244 | \217 | \250 | \235 | \343 | \340 | \227 | \215 | \275 | \245 | \206 | \251 | \210 | \344 | \242 | \230 | \253 | \276 |
Teraz program przyjmie w Windows postać:
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("Witaj w j\251zyku C\n"
"----------------\n\n");
return 0;
}
|
Nie wygląda to może ładnie, ale działa.
W języku C możemy również zastosować funkcję setlocale( ), która zdefiniowana jest w pliku nagłówkowym locale.h. Funkcja ta ustawia odpowiednie kodowanie znaków w konsoli wg ustawień systemowych. Korzystasz z niej następująco:
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
setlocale(LC_ALL,"");
printf("O książę, zażółć gęślą jaźń\n"
"---------------------------\n\n");
return 0;
}
|
Efekt będzie następujący:
| O książę, zażółć gęślą jaźń --------------------------- Process returned 0 (0x0) execution time : 0.085 s Press any key to continue. |
Z tego rozwiązania będziemy korzystać w dalszej części kursu, musisz jednakże pamiętać, iż funkcja setlocale( ) może nie być dostępna lub nie działać na mikrokontrolerach.
Funkcję setlocale( ) możesz również używać w Linuksie, jednak tam konsola ma już ustawione odpowiednie kodowanie, zatem nic to nie zmieni. Jednak pozwoli ci to bez modyfikacji uruchamiać nasze programy.
Ostatnią rzeczą, którą wprowadzimy na tej lekcji, będą komentarze. Komentarz jest dodatkową informacją umieszczaną w programie. Służy ona najczęściej do opisania sposobu działania lub przeznaczenia określonych fragmentów kodu. Komentarze są ignorowane przez kompilator, zatem program wynikowy nie jest przez nie większy, czy wolniejszy. Masz je za darmo. Stosuj je często, a sam się zdziwisz, jak potrafią być użyteczne.
We współczesnym języku C dostępne są dwa rodzaje komentarzy.
Komentarz tradycyjny rozpoczyna się od dwóch znaków /* (pomiędzy tymi znakami nie może wystąpić spacja) i kończy się znakami */. Pomiędzy początkiem i końcem komentarza może znaleźć się dowolny tekst (nie zawierający sekwencji */, gdyż kończy ona komentarz) w dowolnej liczbie wierszy (wewnątrz komentarza możesz bez problemu stosować polskie litery bez względu na użyte rozwiązanie do ich wyświetlania). Wszystko pomiędzy /* i */ jest ignorowane przez kompilator. Tego typu komentarz, zwany komentarzem blokowym, stosuje się najczęściej do celów dokumentacji. Oto przykład:
/*
Pierwszy program w języku C
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 22.09.2019
Program wyświetla dwa wiersze tekstu
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
setlocale(LC_ALL,"");
printf("Witaj w języku C\n"
"----------------\n\n");
return 0;
}
|
Drugi komentarz nazywa się komentarzem wierszowym. Rozpoczynamy go dwoma znakami //. Wszystko, co się znajdzie za tymi znakami aż do końca wiersza, zostanie potraktowane jako komentarz i nie będzie tłumaczone na kod wynikowy. Komentarze wierszowe stosuje się najczęściej do opisu poleceń lub danych:
/*
Pierwszy program w języku C
(C)2016 mgr Jerzy Wałaszek
Data utworzenia: 22.09.2019
Program wyświetla dwa wiersze tekstu
*/
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
// Główna funkcja programu
//------------------------
int main()
{
// Wypisujemy tekst powitalny
setlocale(LC_ALL,"");
printf("Witaj w języku C\n"
"----------------\n\n");
return 0;
}
|
To wszystko w tym rozdziale. Zapraszamy do następnego.
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
