|
Serwis Edukacyjny Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny Nauczycieli w I-LO w Tarnowie |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
| SPIS TREŚCI |
| Podrozdziały |
Komunikacja procesora z resztą systemu komputerowego odbywa się za pomocą tzw. magistral. Magistrala jest zbiorem linii, po których równolegle przebiegają sygnały. Jeśli sygnały mogą biegnąć tylko w jednym kierunku, to magistrala jest jednokierunkowa, jeśli w obu kierunkach, to magistrala jest dwukierunkowa. W naszym przypadku będą to sygnały binarne. Wyróżniamy trzy rodzaje magistral:
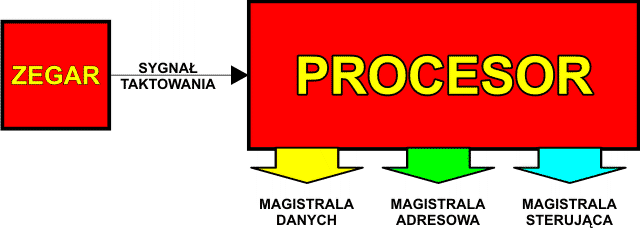
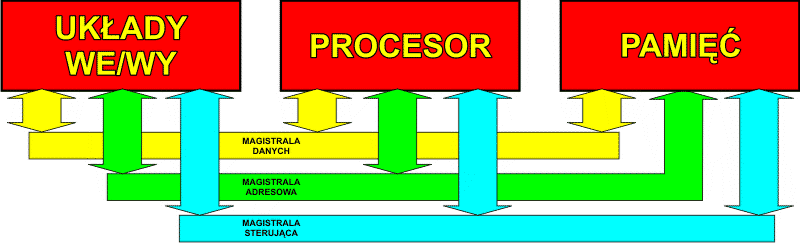
Sposób współpracy poszczególnych elementów składowych komputera jest następujący:
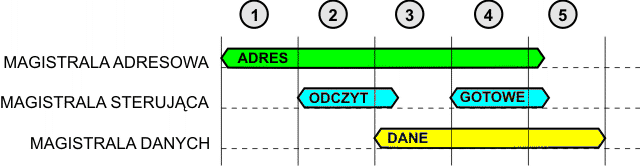
Gdy procesor chce odczytać dane z pamięci lub z urządzenia wejścia, to postępuje następująco:
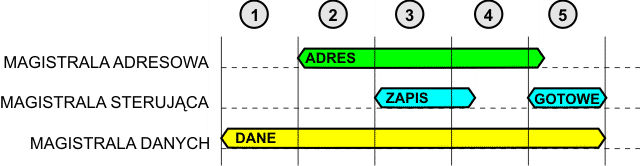
Podobnie wygląda zapis do pamięci lub do urządzenia wyjścia:
Wewnętrznie procesor składa się z wielu bloków funkcjonalnych. Poniższy schemat prezentuje bardzo uproszczoną budowę wewnętrzną procesora (rzeczywiste rozwiązania są wyposażane w wiele dodatkowych elementów, których omówienie wykracza poza ramy tego artykułu):
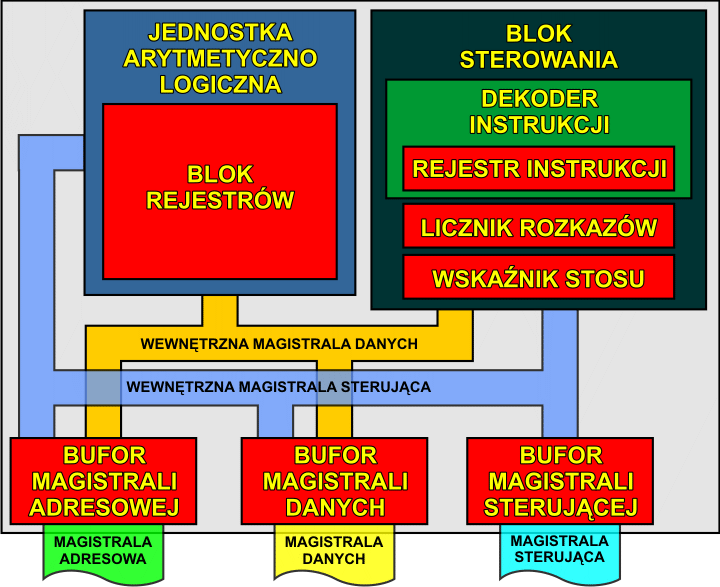
Działanie tych bloków omówimy na prostych przykładach.
Instrukcja dla procesora jest kodem binarnym, który określa rodzaj operacji do wykonania. Ciąg instrukcji tworzy program dla procesora. Instrukcje są umieszczane w komórkach pamięci. Do adresowania instrukcji w programie procesor używa specjalnego rejestru zwanego licznikiem rozkazów lub licznikiem programu (ang. PC - program counter). Rejestr ten przechowuje adres instrukcji do wykonania. Aby pobrać daną instrukcję, procesor przesyła zawartość rejestru PC na magistralę adresową i odczytuje dane umieszczone pod tym adresem w pamięci do rejestru instrukcji (ang. IR - instruction register). Po pobraniu kodu instrukcji rejestr licznika programu PC jest odpowiednio zwiększany i wskazuje kolejną instrukcję w pamięci programu (w ten sposób pobierane są kolejne instrukcje w programie).
Po umieszczeniu instrukcji w rejestrze IR do pracy przystępuje dekoder instrukcji. Jest to bardzo skomplikowana sieć logiczna, która analizuje odczytany rozkaz i na tej podstawie określa sekwencję mikrorozkazów, które należy wewnętrznie wykonać, aby zrealizować pobraną instrukcję. Mikrorozkazy wykonuje blok sterowania (ang. CU - control Unit), wysyłając odpowiednie sygnały sterujące do pozostałych bloków procesora.
Po zakończeniu wykonywania instrukcji cały cykl pobrania kolejnego rozkazu powtarza się.
Współczesne procesory pobierają rozkazy z pamięci zewnętrznej do tzw. kolejki rozkazowej (ang. instruction queue). Proces ten jest zwykle niezależny od działania pozostałych elementów procesora i odbywa się równolegle z wykonywaniem innych rozkazów. Takie rozwiązanie przyspiesza pracę procesora, ponieważ po zakończeniu danego rozkazu ma on gotowy kod następnego w kolejce.
Operacje arytmetyczne i logiczne są wykonywane przez tzw. jednostkę arytmetyczno logiczną (ang. ALU - arithmetic logic unit). Jest to skomplikowana sieć logiczna, która potrafi wykonywać na dostarczonych danych operacje arytmetyczne (dodawanie, odejmowanie, mnożenie, dzielenie, porównanie) oraz logiczne (alternatywa, koniunkcja, suma symetryczna, operacje przesuwu bitów). Dane dla operacji mogą być pobierane z bloku rejestrów wewnętrznych lub z pamięci zewnętrznej albo z urządzeń wejścia/wyjścia. Również wyniki tych operacji mogą trafić do rejestrów wewnętrznych lub pamięci/urządzeń we/wy. Pozwala to realizować praktycznie dowolne algorytmy przetwarzania danych.
Blok rejestrów jest pamięcią wewnętrzną procesora. Powodów stosowania rejestrów wewnętrznych jest kilka. Przede wszystkim są one wewnątrz procesora, zatem dostęp do przechowywanych w nich danych jest bardzo szybki. Drugim powodem jest to, iż rejestrów jest zwykle niewiele i adresowanie nie wymaga wielu bitów, jak w przypadku pamięci zewnętrznej. Zatem kody instrukcji działających na rejestrach mogą być krótkie (np. 1-bajtowe). Ponieważ w rejestrach można również przechowywać adresy, rozwiązanie to jest bardzo wygodne.
Zwykle jeden z rejestrów posiada więcej funkcji niż pozostałe (nie jest to regułą) i nosi on nazwę akumulatora (ang. accumulator register). Akumulator często jest jednym z argumentów operacji arytmetyczno-logicznych oraz miejscem umieszczania wyniku tej operacji. Stąd właśnie pochodzi nazwa tego rejestru - akumuluje on jakby wyniki przetwarzania.
Współczesne procesory zawierają również jednostkę arytmetyki zmiennoprzecinkowej (ang. FPU - floating point unit). Potrafi ona wykonywać sprzętowo (tzn. bardzo szybko) operacje na liczbach rzeczywistych oraz wyliczać wiele funkcji matematycznych (pierwiastek, sinus, cosinus, tangens, logarytm, itp.).
Procesor często musi zmieniać kolejność wykonywanych instrukcji. Osiąga się to za pomocą tzw. rozkazów skoków. Rozkaz skoku za kodem instrukcji zawiera adres, od którego procesor powinien kontynuować pobieranie kolejnych instrukcji. Adres ten jest po prostu wpisywany do rejestru licznika programu. Po wykonaniu tej operacji kolejną instrukcję procesor pobierze spod wskazanego adresu.
| Kod instrukcji skoku | Adres, pod który należy wykonać skok |
W podobny sposób wykonywany jest skok do podprogramu. Jedyna różnica polega na tym, iż procesor zapamiętuje, skąd ten skok nastąpił (tzn. adres zaraz za instrukcją skoku do podprogramu). W podprogramie może być zawarta instrukcja powrotu, która powoduje, iż ten zapamiętany wcześniej adres zostaje z powrotem umieszczony w rejestrze licznika rozkazów i program kontynuuje się od następnej instrukcji za instrukcją skoku do podprogramu. Pozwala to wielokrotnie wykorzystywać często używane fragmenty kodu w różnych miejscach programu - piszemy tzw. podprogram, czyli ciąg instrukcji zakończony instrukcją powrotu z podprogramu, a następnie skaczemy do niego z różnych miejsc w programie za pomocą instrukcji skoku do podprogramu. Stosowanie podprogramów często skraca długość programu i upraszcza go.
Adres powrotu zapamiętywany jest na tzw. stosie maszynowym (ang. machine stack). Jest to obszar pamięci adresowany przez rejestr wskaźnika stosu (ang. SP - stack pointer). Stos zwykle rośnie w dół pamięci. Zapis na stos jest wykonywany następująco (jedna z możliwych wersji - w różnych procesorach szczegóły mogą wyglądać inaczej):
Odczyt ze stosu wykonywany jest następująco:
Stos jest bardzo wygodną strukturą danych i jej wykorzystanie nie ogranicza się tylko do podprogramów i ich adresów powrotnych. Zwykle każdy procesor posiada wiele rozkazów, które pozwalają mu umieszczać na stosie zwartości rejestrów, innych komórek pamięci, itp. Dzięki stosowi można realizować wiele algorytmów rekurencyjnych.
Program zwierający instrukcje dla procesora nosi nazwę kodu maszynowego (ang. machine code). Jest to kod binarny, dla człowieka zwykle nieczytelny. Aby umożliwić programowanie procesorów opracowana w latach 50-tych XX wieku język symboliczny, zwany językiem asemblera (ang. assembler lub assembly language). W języku tym każda instrukcja maszynowa jest reprezentowana za pomocą tzw. mnemonika, czyli kilkuliterowego napisu, który kojarzy się z wykonywaną operacją. Dodatkowo określone są reguły dla argumentów operacji.
Przykład (mikroprocesor 6502)
LDA - LoaD Accumulator - ładuj daną do akumulatora LDA #liczba - ładuj do akumulatora liczbę LDA adres - ładuj do akumulatora zawartość komórki spod wskazanego adresu STA - STore Accumulator 0 prześlij zawartość akumulatora do pamięci STA adres - umieść zawartość akumulatora we wskazanej komórce pamięci ADC - ADd with Carry - dodaj z przeniesieniem ADC #liczba - dodaj liczbę do akumulatora ADC adres - dodaj do akumulatora zawartość komórki pamięci spod wskazanego adresu
...
Program napisany w języku asemblera jest zwykłym tekstem - składa się z liter. Procesor w takiej postaci nie jest w stanie go zrozumieć. Dlatego należy zawsze dokonać kompilacji, czyli zamiany tekstu programu na odpowiadające mu instrukcje binarne dla procesora. Operacji tej dokonuje program zwany asemblerem.
Programowanie w języku asemblera daje 100% kontrolę nad całym komputerem. Jednakże jest bardzo trudne, ponieważ programista musi dokładnie znać budowę całego komputera, specyfikę wykonywania w nim różnych działań, itp. Poza tym każdą operację należy rozbić na elementarne instrukcje dla procesora. Programy w języku maszynowym są mało czytelne dla człowieka, a częste błędy trudno zdiagnozować i wymagają one dużej koncentracji przy ich wyszukiwaniu. W początkach swojej działalności informatycznej często programowałem w asemblerze komputery ZX81, ZX-Spectrum, Atari 800XL/130XE, Commodore 64, Amiga i IBM. Nad niektórymi błędami w programach straciłem całe tygodnie (nie narzekam, bo miałem z tego mnóstwo satysfakcji i niezłą zabawę intelektualną). Dlatego, o ile nie istnieją jakieś ważne powody, lepiej jest programować komputery w językach wysokiego poziomu, jak chociażby C++. Zaoszczędzimy wiele czasu i niepotrzebnej frustracji - chociaż i tam błędy potrafią być złośliwe. Dodatkowo, programy w języku maszynowym są nieprzenośne na inne platformy sprzętowe, gdzie procesor ma inny zestaw rozkazów, inaczej są zorganizowane układy wejścia/wyjścia. Wad tych nie posiadają języki wysokiego poziomu, które nie działają na warstwie sprzętowej komputera, lecz na warstwie rozwiązywanego przez program problemu.
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
