w I-LO w Tarnowie
Materiały dla uczniów liceum
Wyjście Spis treści Wstecz Dalej

Autor artykułu: mgr Jerzy Wałaszek
©2026 mgr Jerzy Wałaszek
![]()
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
SPIS TREŚCI |
We współczesnych językach programowania znaki są podstawowym typem danych. W pamięci komputera znak jest przechowywany w postaci liczby, którą nazywamy kodem znaku (ang. character code). Każdy znak posiada swój własny kod. Aby różne urządzenia systemu komputerowego mogły w ten sam sposób interpretować kody znaków, opracowano kilka standardów kodowania liter. Bardzo rozpowszechniony jest standard ASCII:
Znaki są zapamiętywane w postaci 8 bitowych kodów (pierwotnie było to 7 bitów, lecz później standard ASCII został poszerzony na 8 bitów, w których znalazły się różne znaki narodowe). Taki sposób reprezentacji znaków jest dzisiaj bardzo wygodny, ponieważ podstawowa komórka pamięci komputera IBM przechowuje właśnie 8 bitów. Dzięki temu znaki dobrze mieszczą się w pamięci.
Typ ten jest w C++ reprezentowany przez char lub unsigned char. W pierwszym typie kody znaków spoza standardowego zestawu ASCII są ujemne i przyjmują wartości od -128 do -1. W drugim typie kody znaków spoza standardowego zestawu ASCII mają wartości od 128 do 255.
Przyjrzyjmy się dokładniej kodom ASCII w postaci binarnej:
Podstawowy standard ASCII definiuje kody w zakresie od 0 do 127. Bitowo jest to 7 najmłodszych bitów kodu. Pozostałe kody od 128 do 255 to rozszerzony zestaw ASCII:
| 0 | x | x | x | x | x | x | x | 1 | x | x | x | x | x | x | x | |
| podstawowy kod ASCII |
rozszerzony kod ASCII |
|||||||||||||||
| 0 | 0 | 0 | x | x | x | x | x |
| znaki sterujące | |||||||
Np. kod 13 oznacza przejście do następnej linii, kod 7 to dźwięk dzwonka.
// Kody ASCII
//-----------
#include <iostream>
using namespace std;
int main()
{
cout << char(7) << endl;
return 0;
}
|
Większość z tych kodów (za wyjątkiem 0,7,8,9,10 i 13) produkuje w konsoli znakowej użyteczne znaki, kody niedrukowalne zamieniliśmy na opis symboliczny:
// Kody ASCII
//-----------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
for(int i = 0; i < 32; i++)
{
cout << "znak(" << setw(2) << i << ") = ";
switch(i)
{
case 0: cout << "NUL"; break;
case 7: cout << "BEL"; break;
case 8: cout << "BS"; break;
case 9: cout << "HT"; break;
case 10: cout << "LF"; break;
case 13: cout << "CR"; break;
default: cout << char(i);
}
cout << endl;
}
return 0;
}
|
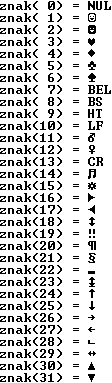 |
W programie występuje nowa instrukcja switch. Nazywamy ją instrukcją wyboru i jej składnia jest następująca:
switch(wyrażenie)
{
case wartość_1: ciąg instrukcji;
case wartość_2: ciąg instrukcji;
....
case wartość_n: ciąg instrukcji;
default: ciąg instrukcji;
}
| wyrażenie | – | wyrażenie, którego wartość zostaje obliczona |
| case wartość_x: | – | miejsce w instrukcji switch, do którego komputer wykona skok, jeśli wyrażenie ma wartość_x. |
| ciąg instrukcji | – | dowolny ciąg instrukcji języka c++. Instrukcje te są kolejno wykonywane i jeśli na ich końcu nie umieścimy instrukcji break, to komputer przejdzie do wykonywania instrukcji w następnym bloku case. Instrukcja break przerywa instrukcję switch i komputer przechodzi do następnej instrukcji w programie za switch. |
| default: | – | miejsce w instrukcji switch, do którego komputer wykona skok, jeśli wartość wyrażenie nie odpowiada żadnej z wartości_x case. |
// Instrukcja switch
//------------------
#include <iostream>
using namespace std;
int main()
{
int i;
for(i = 1; i < 10; i++)
switch(i)
{
case 1: cout << "raz...";
break;
case 2: cout << "dwa...";
break;
default: cout << " i " << i << "...";
}
cout << endl << endl;
return 0;
}
|
// Kody ASCII
//-----------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
for(int i = 0; i < 32; i++)
{
for(int j = 1; j <= 3; j++)
cout << "znak(" << setw(3) << i + 32 * j << ") = "
<< char(i + 32*j) << " ";
cout << endl;
}
return 0;
}
|
 |
Cyfry mają kody od 48 (0) do 57 (9).
| 0 | 0 | 1 | 1 | x | x | x | x |
| cyfry | |||||||
W powyższym kodzie xxxx jest wartością binarną cyfry: 0000 = 0, 0001 = 1, 0010 = 2, ..., 1001 = 9.
// Kody ASCII
//-----------
#include <iostream>
using namespace std;
int main()
{
for(int i = 48; i < 58; i++)
cout << "znak(" << i << ") = " << char(i) << endl;
return 0;
}
|
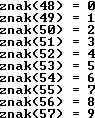 |
Litery duże mają kody od 65 (A) do 89 (Z). Litery małe mają kody od 97 (a) do 122 (z).
| 0 | 1 | 0 | x | x | x | x | x | 0 | 1 | 1 | x | x | x | x | x | |
| litery duże | litery małe | |||||||||||||||
W powyższych kodach xxxxx oznacza binarny numer litery od 00001 = 1 do 11010 = 26. Zwróć uwagę, że litery małe różnią się od dużych bitem b5. Oznacza to, że np. kod litery 'a' jest większy o 32 od kodu litery 'A'. Aby z kodu dużej litery otrzymać kod małej, wystarczy ustawić na 1 bit b5. Podobnie, aby z kodu małej litery otrzymać kod duże, wystarczy wyzerować bit b5.
// Kody ASCII
//-----------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
for(int i = 1; i < 27; i++)
{
for(int j = 0; j < 2; j++)
cout << "znak(" << setw(3) << i + 64 + 32 * j << ") = "
<< char(i + 64 + 32 * j) << " ";
cout << endl;
}
return 0;
}
|
 |
// Kody ASCII
//-----------
#include <iostream>
using namespace std;
int main()
{
for(int i = 0; i < 32; i++)
{
for(int j = 0; j < 4; j++)
cout << "znak("
<< 128+i+j*32
<< ") = "
<< char(128+i+j*32)
<< " ";
cout << endl;
}
return 0;
} |
 |
W polskich systemach Windows w konsoli znakowej jest zwykle wykorzystywana strona kodowa CP852. Niestety, sam system Windows wykorzystuje standard Windows 1250, w którym polskie literki posiadają inne kody niż ich odpowiedniki w konsoli znakowej.
| Ą | Ć | Ę | Ł | Ń | Ó | Ś | Ź | Ż | ą | ć | ę | ł | ń | ó | ś | ź | ż | |
| Windows 1250 | 165 | 198 | 202 | 163 | 209 | 211 | 140 | 143 | 175 | 185 | 230 | 234 | 179 | 241 | 243 | 156 | 159 | 191 |
| CP852 | 164 | 143 | 168 | 157 | 227 | 224 | 151 | 141 | 189 | 165 | 134 | 169 | 136 | 228 | 162 | 152 | 171 | 190 |
Konsekwencją tego faktu jest to, że program napisany w edytorze pracującym w Windows nie będzie poprawnie wyświetlał polskich znaków (tablica znakowa s zawiera kody polskich znaków Windows 1250):
// Kody ASCII
//-----------
#include <iostream>
using namespace std;
int main()
{
unsigned char s[] = "ĄĆĘŁŃÓŚŹŻąćęłńóśźż*";
cout << "Windows 1250" << endl << endl;
for(int i = 0; s[i] != '*'; i++)
cout << s[i] << " : " << (int) s[i] << endl;
return 0;
} |
 |
Należy dokonać odpowiedniej konwersji (tablica znakowa t zawiera poprawne kody polskich znaków dla konsoli CP852):
// Kody ASCII
//-----------
#include <iostream>
using namespace std;
int main()
{
unsigned char s[] = "ĄĆĘŁŃÓŚŹŻąćęłńóśźż*";
unsigned char t[] = {164,143,168,157,227,224,151,141,189,
165,134,169,136,228,162,152,171,190};
cout << "Windows 1250" << endl << endl;
for(int i = 0; s[i] != '*'; i++)
cout << t[i] << " : " << (int) s[i] << endl;
return 0;
} |
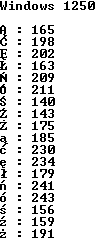 |
Problemy te znikają, jeśli zrezygnujemy z polskich znaków w trybie konsoli lub wywołamy na początku programu funkcję:
setlocale(LC_ALL,"");
Ustawia ona w konsoli ten sam sposób kodowania liter co w Windows. Należy wspomnieć, że w systemie Linux nie występuje ten problem, ponieważ kodowanie polskich znaków jest jednolite w całym systemie (ale z kolei jest to jeszcze inna strona kodowa – ISO-8859-2, która jest standardem ogólnoświatowym).
Tekst jest ciągiem znaków. Jeśli chcemy w naszym programie przetwarzać teksty, to musimy na nie przygotować miejsce w pamięci. W języku C++ można to zrobić na wiele sposobów. My poznamy najprostszy – tablicę znakową. Jest to tablica, której elementy są znakami. Znaki z kolei są reprezentowane przez typ char (znaki ASCII). Dlatego tablicę znakową tworzymy następująco:
char nazwa_tablicy[liczba_znaków];
Kolejną ważną rzeczą jest znajomość sposobu umieszczania tekstu w tablicy. Kolejne znaki są umieszczane w kolejnych kolejnych komórkach. Za ostatnim znakiem komputer umieszcza kod NUL, czyli znak o kodzie zero. Znak ten nie wchodzi w skład tekstu, lecz informuje, że tekst się zakończył. Dlatego w tym przypadku nosi on nazwę znacznika końca tekstu (ang. End Of Text flag, EOT). Załóżmy, że pewna tablica znakowa t przechowuje tekst "JANEK". Poniższy program umieszcza w tablicy słowo "JANEK", po czym wyświetla z tej tablicy kolejne znaki, aż do napotkania kodu NUL:
// Przechowywanie tekstu
//----------------------
#include <iostream>
using namespace std;
int main()
{
char t[100] = "JANEK";
int i;
i = 0;
do
{
cout << t[i] << " : " << int(t[i]) << endl;
i++;
} while(t[i - 1] > 0);
return 0;
}
|
Na wyjściu otrzymamy:
J : 74 A : 65 N : 78 E : 69 K : 75 : 0
Za ostatnim znakiem "K" zostaje umieszczony znacznik końca tekstu "NUL". Skoro znacznik ten jest zawsze umieszczany za tekstem, to musimy zarezerwować dla niego miejsce w tablicy znakowej. Wynika stąd, iż rozmiar tej tablicy musi być o jeden większy od maksymalnej liczby znaków tekstu, który chcemy w tablicy przechowywać.
Powyższy program pokazuje kilka rzeczy:
char tablica[rozmiar] = "dowolny tekst"; |
– | Tablicę znakową możemy zainicjować tekstem (tekst nie może zawierać więcej znaków niż rozmiar tablicy minus jeden) |
t[i] |
– | Dostęp do poszczególnych znaków w tablicy uzyskujemy poprzez nazwę tablicy i indeks komórki, która zawiera znak. |
cin << t[i] |
– | Gdy przesyłamy do strumienia wyjściowego cin znak z tablicy znakowej, to zostaje on potraktowany jako litera. |
cin << int(t[i]) |
– | Jeśli chcemy wyświetlić kod znaku, to używamy rzutowania na typ int. |
t[i - 1] > 0 |
– | W wyrażeniach znaki są traktowane jak liczby, będące ich kodami. |
Teraz zobaczmy, w jaki sposób program odczytuje tekst z okna konsoli. Kolejny program w pętli nieskończonej odczytuje tekst wprowadzony przez użytkownika i umieszcza go w tablicy t. Następnie zawartość tej tablicy zostaje wyświetlona w nawiasach okrągłych, po czym program wykonuje następny obieg pętli i operacje te są wykonywane ponownie.
// Odczyt i zapis tekstu
//----------------------
#include <iostream>
using namespace std;
int main()
{
char t[100];
while(true) // pętla nieskończona
{
cin >> t;
cout << "( " << t << " )" << endl;
}
return 0;
}
|
Uruchom program i wpisz tekst:
Ala ma kotka
Otrzymasz:
Ala ma kotka ( Ala ) ( ma ) ( kotka )
Zwróć uwagę, iż w nawiasach okrągłych pojawiły się kolejne wyrazy, a nie cały wpisany tekst. Dzieje się tak dlatego, iż strumień traktuje jako osobne elementy wyrazy rozdzielone znakami białymi (znak biały to taki, który na wydruku nie używa tuszu, np. spacja, tabulacja, koniec wiersza, itp.). W naszym przykładzie spacje znajdują się pomiędzy "Ala" a "ma" i "ma" a " kotka". Dlatego odczyt cin >> t umieścił w tablicy t pierwszy wyraz w pierwszym obiegu, drugi wyraz w drugim obiegu i trzeci wyraz w trzecim obiegu, W czwartym obiegu strumień cin był już pusty, zatem komputer czekał na wprowadzenie nowych danych.
Wpisz teraz to samo zdanie, lecz zamiast spacji użyj kropki (lub dowolnego innego znaku). Otrzymasz:
Ala.ma.kotka ( Ala.ma.kotka )
Teraz ze strumienia cin został odczytany cały tekst, ponieważ nie ma w nim znaków białych.
W programie zwróć uwagę na:
while(true)
{
...
}
|
– | Pętla nieskończona, powstaje wtedy, gdy warunek
kontynuacji jest zawsze prawdziwy. Wykonuje w kółko swoje obiegi aż do ręcznego zamknięcia programu. |
cin >> t; |
– | Odczyt ze strumienia wyrazu (kolejne litery tekstu aż do napotkania znaku białego). |
cout << t; |
– | Zapis do strumienia zawartości tablicy t aż do napotkania znaku NUL (o kodzie 0). Znak NUL nie jest zapisywany w strumieniu. |
Jeśli chcemy ze strumienia odczytać cały wiersz, a nie poszczególne wyrazy, to musimy użyć funkcji składowej strumienia cin. Strumień wejścia konsoli (ang. console input, cin) jest obiektem, który zawiera wiele funkcji składowych (ang. member functions) operujących na tym strumieniu. W tym przypadku skorzystamy z funkcji cin.getline(). Jej składnia jest następująca:
cin.getline(t,n);
t – tablica znakowa, w której zostaną umieszczone znaki
odczytane ze strumienia
n – maksymalna liczba znaków do zapisu w tablicy n razem z kończącym
znakiem NUL.
Kolejny program w pętli nieskończonej odczytuje ze strumienia cin cały wiersz znaków, umieszcza go w tablicy t, po czym wyświetla zawartość tablicy t.
// Odczyt i zapis tekstu
//----------------------
#include <iostream>
using namespace std;
int main()
{
char t[256];
while(true) // pętla nieskończona
{
cin.getline(t,256);
cout << "( " << t << " )" << endl;
}
return 0;
}
|
Napiszemy teraz program, który odczyta w pętli nieskończonej będzie odczytywał wiersz znaków do tablicy t, po czym wyświetli odczytany wiersz wspak.
Zasada działania jest następująca:
Po odczytaniu wiersza program znajdzie pozycję znaku NUL, który jest umieszczony za ostatnim znakiem wiersza. Następnie przejdzie do ostatniego znaku i zacznie wyświetlać znaki z tablicy t od tej pozycji cofając się do początku tablicy. W ten sposób wiersz będzie wyświetlony wspak.
// Przetwarzanie tekstu
//----------------------
#include <iostream>
using namespace std;
int main()
{
char t[256];
while(true) // Pętla nieskończona
{
cin.getline(t,256); // Czytamy wiersz do t
int i = 0; // Zaczynamy szukać pozycji znaku NUL
while(t[i] != 0) i++;
// Indeks i wskazuje pozycję NUL w tablicy t
i--; // Ustawiamy indeks na ostatni znak wiersza w tablicy t
while(i >= 0) // Wyświetlamy znaki od ostatniego do pierwszego
{
cout << t[i];
i--;
}
cout << endl;
}
return 0;
}
|
12 :(całk.) 7 = 1
3 :(całk.) 4 = 0
22 :(całk.) 6 = 3
Operatorem dzielenia całkowitoliczbowego w języku C++ jest znak "/". Ten sam znak używany jest również do zwykłego dzielenia, zatem aby nie pomylić się, zapamiętaj prostą regułę:
Jeśli oba argumenty operatora dzielenia są całkowite, to wynik też jest liczbą całkowitą. Mamy dzielenie całkowitoliczbowe:
4 / 3 daje wynik 1
15 / 4 daje wynik 3
29 / 5 daje wynik 5
Jeśli dowolny z argumentów jest liczbą rzeczywistą (ułamkową), to wynik też jest liczbą rzeczywistą. Mamy normalne dzielenie rzeczywiste:
Liczba 4.0 jest liczbą rzeczywistą, która ma wartość równą liczbie całkowitej 4, ale język C++ traktuje ją jak liczbę rzeczywistą. Liczby rzeczywiste są inaczej zapisywane w pamięci komputera niż liczby całkowite. W naszym serwisie jest duży artykuł o kodowaniu liczb w komputerze pt. "Binarne kodowanie liczb". Jednakże polecam go jedynie najzdolniejszym uczniom.
Dzielenie całkowitoliczbowe możemy zdefiniować przez odejmowanie. Np. 5 :(całk.) 2 = 2, ponieważ liczbę 2 możemy odjąć od 5 dwa razy. To, co pozostaje po takim odejmowaniu, nazywamy resztą z dzielenia:
Zwróć uwagę, iż reszta z dzielenia jest zawsze mniejsza od dzielnika. Wyjaśnienie jest proste. Gdyby reszta była równa lub większa od dzielnika, to moglibyśmy dalej kontynuować odejmowanie.
Zatem dzieląc liczbę a przez liczbę b odejmujemy od a kolejno b dotąd, aż nie będzie to możliwe. To, co pozostanie z a, nazywamy resztą z dzielenia całkowitego a przez b:
Operacja wyznaczania reszty z dzielenia całkowitego nosi nazwę operacji modulo i w języku C++ posiada swój operator "%":
W operacji modulo dzielnik nosi nazwę modułu:
Jeśli dzielimy liczby nieujemne (naturalne i zero), to wynik operacji modulo jest również liczbą nieujemną. Sprawdźmy, jakie wartości daje operacja modulo dla modułu 6 i różnych liczb. Uruchom poniższy program:
// Przetwarzanie tekstu
//----------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int i;
for(i = 0; i < 15; i++)
cout << setw(2) << i << " % " << 6 << " = " << i % 6 << endl;
return 0;
}
|
Zauważ iż wynikiem operacji modulo są liczby:
Wyniki te powtarzają się, gdy A ≥ B. To bardzo ważna cecha operacji modulo. Wyniki tworzą pierścień, np. dla operacji modulo 6 mamy:

Operację modulo można połączyć z dodawaniem, które zdefiniujemy następująco:
Jeśli A jest liczbą w pierścieniu modulo B, to dodanie do A liczby C modulo B da liczbę z pierścienia leżącą na pozycji o C obrotów w prawo od pozycji liczby A. Weźmy na przykład liczbę 3, jako wartość startową:
 |
(3 + 0) % 6 = 3 % 6 = 3 | |
 |
(3 + 1) % 6 = 4 % 6 = 4 | |
 |
(3 + 2) % 6 = 5 % 6 = 5 | |
 |
(3 + 3) % 6 = 6 % 6 = 0 | |
 |
(3 + 4) % 6 = 7 % 6 = 1 | |
 |
(3 + 5) % 6 = 8 % 6 = 2 | |
 |
(3 + 6) % 6 = 9 % 6 = 3 | |
 |
(3 + 7) % 6 = 10 % 6 = 4 itd. |
Zwróć uwagę na istotną własność dodawania modulo: dodanie modułu B do A daje wynik A:
A +(modulo B) B = (A + B) % B = A
O takiej liczbie mówimy, że jest zerem dodawania modulo. Jeśli w pierścieniu modulo obrócimy się o B pozycji, to zawsze wrócimy na to samo miejsce.
Zdefiniujmy teraz odejmowanie modulo A - C jako liczbę leżącą na pozycji o C obrotów w lewo od pozycji A, czyli odwrotnie niż dla dodawania modulo. Aby wyniki odejmowania zawsze były nieujemne, dodamy do liczby A moduł B przed wykonaniem odejmowania (zakładamy, iż C należy do pierścienia modulo, jest zatem zawsze mniejsze od B):
A -(modulo B) C = (A + B - C) % B
 |
(3 + 6 - 0) % 6 = 9 % 6 = 3 | |
 |
(3 + 6 - 1) % 6 = 8 % 6 = 2 | |
 |
(3 + 6 - 2) % 6 = 7 % 6 = 1 | |
 |
(3 + 6 - 3) % 6 = 6 % 6 = 0 | |
 |
(3 + 6 - 4) % 6 = 5 % 6 = 5 | |
 |
(3 + 6 - 5) % 6 = 4 % 6 = 4 |
Reszta z dzielenia jest zawsze mniejsza od modułu.
Ilość możliwych reszt z dzielenia liczb nieujemnych jest zawsze równa modułowi.
Dodawanie modulo wykonujemy wg wzoru (a + b) % m.
Odejmowanie modulo wykonujemy wg wzoru (a + m - b) % m.
Szyfr Cezara został nazwany na cześć rzymskiego imperatora Juliusza Cezara, który stosował ten sposób szyfrowania do przekazywania informacji o znaczeniu wojskowym. Szyfr polega na zastępowaniu liter alfabetu A...Z literami leżącymi o trzy pozycje dalej w alfabecie:
| Tekst jawny | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Szyfr Cezara | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | A | B | C |
Ostatnie trzy znaki X, Y i Z nie posiadają następników w alfabecie przesuniętych o trzy pozycje. Dlatego umawiamy się, iż alfabet "zawija się" i za literką Z następuje znów litera A. Teraz bez problemu znajdziemy następniki X → A, Y → B i Z → C.
Przykład:
Zaszyfrować zdanie: NIEPRZYJACIEL JEST BARDZO BLISKO.
Poszczególne literki tekstu jawnego zastępujemy literkami szyfru Cezara zgodnie z powyższą tabelką kodu. Spacje oraz inne znaki nie będące literami pozostawiamy bez zmian:
NIEPRZYJACIEL JEST BARDZO BLISKO |
Deszyfrowanie tekstu zaszyfrowanego kodem Cezara polega na wykonywaniu operacji odwrotnych. Każdą literę kodu zamieniamy na literę leżącą o trzy pozycje wcześniej w alfabecie.
| Szyfr Cezara | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tekst jawny | X | Y | Z | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W |
Podobnie jak poprzednio trzy pierwsze znaki szyfru Cezara nie posiadają bezpośrednich odpowiedników liter leżących o trzy pozycje wcześniej, ponieważ alfabet rozpoczyna się dopiera od pozycji literki D. Rozwiązaniem jest ponowne "zawinięcie" alfabetu, tak aby przed literą A znalazły się trzy ostatnie literki X, Y i Z.
Do wyznaczania kodu literek przy szyfrowaniu i deszyfrowaniu posłużymy się operacjami modulo. Moduł będzie równy liczbie liter alfabetu, czyli 26. Aby można było stosować operacje modulo, liczby muszą należeć do pierścienia, czyli być z zakresu od 0 do 25 (moduł minus jeden). Tymczasem kody ASCII literek A...Z mają wartości od 65 (litera A) do 90 (litera Z). Zatem najpierw od kodu literek odejmiemy 65, aby otrzymać liczby od 0 do 25.
Szyfrowanie polega na wzięciu kodu literki leżącego o trzy pozycje, co wyznaczymy następująco:
Mamy literkę o kodzie ASCII równym c.
| c - 65 | Odejmujemy od jej kodu 65, aby otrzymać liczbę z pierścienia modulo: 0...25 | |
| (c - 65 + 3) % 26 | Dodajemy 3 modulo 26, aby przesunąć się w pierścieniu o trzy pozycje do przodu. | |
| ((c - 65 + 3) % 26) + 65 | Do wyniku dodajemy 65, aby powrócić do kodu ASCII |
Litra szyfru cezara dla litery c ma kod ASCII równy:
k = ((c - 65 + 3) % 26) + 65
a po uproszczeniu ostatecznie
k = ((c - 62) % 26) + 65
Sprawdźmy dla wybranych liter alfabetu:
Litera M ma kod ASCII równy 77. Podstawiamy do wzoru:
k = ((77 - 62) % 26) + 65
k = (15 % 26) + 65
k = 15 + 65
k = 80
Kod ASCII 80 oznacza literę P, czyli literę leżącą w alfabecie o trzy pozycje dalej.
Teraz sprawdźmy literę z końca alfabetu, gdzie następuje zawinięcie i przejście na początek (za Z jest A):
Litera Y ma kod ASCII równy 89. Podstawiamy go do wzoru:
k = ((89 - 62) % 26) + 65
k = (27 % 26) + 65
k = 2 + 65
k = 66
Jest to kod litery B.
Deszyfrowanie jest operacją odwrotną: cofamy się w alfabecie o trzy pozycje, co zrealizujemy za pomocą odejmowania modulo.
Mamy literę ASCII szyfru Cezara k.
| k - 65 | Odejmujemy od jej kodu 65, aby otrzymać liczbę z pierścienia modulo: 0...25 | |
| (c - 65 + 26 - 3) % 26 | Odejmujemy 3 modulo 26, aby przesunąć się w pierścieniu o trzy pozycje do tyłu. | |
| ((c - 65 + 26 -3) % 26) + 65 | Do wyniku dodajemy 65, aby powrócić do kodu ASCII |
Kod ASCII rozszyfrowanej litery ma wartość:
c = ((c - 65 + 26 -3) % 26) + 65
A po uproszczeniu:
c = ((c - 42) % 26) + 65
Sprawdzamy:
Litera M ma kod ASCII równy 77. Podstawiamy do wzoru:
k = ((77 - 42) % 26) + 65
k = (35 % 26) + 65
k = 9 + 65
k = 74
Kod ASCII 74 odpowiada literze J, leżącej o trzy pozycje do tyłu od litery M.
Litera C ma kod ASCII 67. Podstawiamy do wzoru:
k = ((67 - 42) % 26) + 65
k = (25 % 26) + 65
k = 25 + 65
k = 90
Jest to kod litery Z leżącej o trzy pozycje przed literą C.
Jeśli c jest kodem ASCII dużej litery alfabetu ( rozważamy tylko teksty zbudowane z dużych liter ), to szyfrowanie kodem Cezara polega na wykonaniu następującej operacji arytmetycznej:
c = 65 + ( c - 62 ) % 26
Deszyfrowanie polega na zamianie kodu wg wzoru:
c = 65 + ( c - 42 ) % 26
Napiszemy program, który będzie szyfrował szyfrem cezara lub rozszyfrowywał tekst zaszyfrowany tym szyfrem. Tryb działania programu będzie wybierała pierwsza litera we wprowadzonym wierszu tekstu. Jeśli będzie to "S", program zaszyfruje resztę znaków w wierszu. Jeśli będzie to "R", program rozszyfruje resztę znaków. Następnie, zaszyfrowany/rozszyfrowany wiersz zostanie wyświetlony.
Program będzie utworzony na lekcji.
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.