
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2013 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2013 mgr
Jerzy Wałaszek
|
Stos (ang. stack) jest sekwencyjną strukturą danych. Najprościej możemy go sobie wyobrazić jako stos książek na biurku. Nowe książki układamy na szczycie stosu (ang. stack top), wtedy stos rośnie w górę.
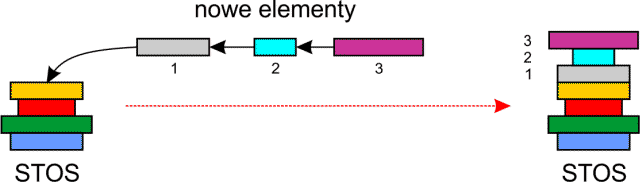
Ze stosu pobieramy książki znajdujące się na samej górze, wtedy stos maleje. Zwróć uwagę, że książki zawsze zdejmujesz ze stosu w kolejności odwrotnej do ich umieszczania – jako pierwszą zdejmiesz ostatnią książkę na stosie.
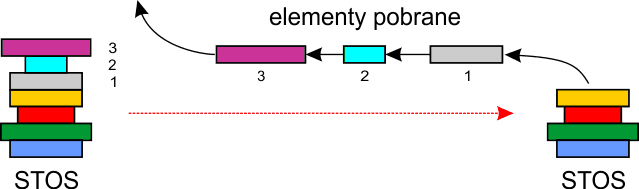
Wracając do świata komputerów, stos jest taką strukturą danych, z której odczytujemy elementy w kolejności odwrotnej do ich wstawiania. Struktura ta nosi nazwę LIFO (ang. Last In – First Out – wszedł ostatni, a wyszedł pierwszy).
Rozróżniamy następujące operacje dla stosu:
Stosy możemy realizować za pomocą tablic lub list jednokierunkowych. Realizacja tablicowa jest bardzo prosta i szybka. Stosujemy ją wtedy, gdy dokładnie wiemy, ile maksymalnie elementów będzie przechowywał stos – jest to potrzebne do przygotowania odpowiednio pojemnej tablicy na elementy stosu. Realizacja za pomocą listy jednokierunkowej jest przydatna wtedy, gdy nie znamy dokładnego rozmiaru stosu – listy dostosowują się dobrze do obszarów wolnej pamięci.
Do utworzenia stosu w tablicy potrzebujemy dwóch zmiennych. Pierwszą z nich będzie tablica, która przechowuje umieszczone na stosie elementy. Druga zmienna sptr służy do zapamiętywania pozycji szczytu stosu i nosi nazwę wskaźnika stosu (ang. stack pointer). Umawiamy się, że wskaźnik stosu zawsze wskazuje pustą komórkę tablicy, która znajduje się tuż ponad szczytem stosu:
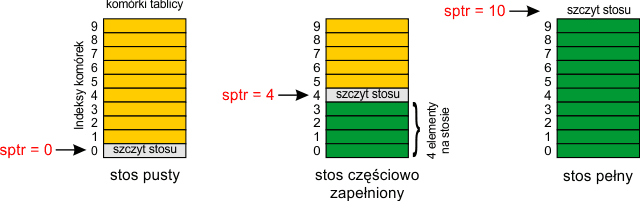
Po utworzeniu tablicy zmienna sptr musi zawsze być zerowana. Stos jest pusty, gdy sptr wskazuje początek tablicy, czyli komórkę o indeksie zero. Ta własność jest wykorzystywana w operacji empty. Stos jest pełny, gdy sptr ma wartość równą liczbie komórek tablicy. W takim przypadku na stosie nie można już umieszczać żadnych dalszych danych. gdyż trafiłyby poza obszar zarezerwowany na tablicę.
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
True, jeśli na stosie nie ma żadnego elementu, inaczej false
| K01 | Jeśli sptr = 0, to zakończ z wynikiem true |
| K02: | Zakończ z wynikiem false |
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
| n | – | rozmiar tablicy |
| S | – | tablica przechowująca stos |
Zawartość szczytu stosu lub wartość specjalna, jeśli stos jest pusty.
| K01 | Jeśli sptr = 0, to zakończ z wynikiem wartość specjalną | |
| K02: | Zakończ z wynikiem S[sptr - 1] |
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
| n | – | rozmiar tablicy |
| S | – | tablica przechowująca stos |
| v | – | zapisywana wartość |
Na stosie zostaje zapisana wartość v, jeśli jest na to miejsce. W przeciwnym razie v nie będzie zapisane.
| K01 | Jeśli sptr = n, to zakończ | ; stos jest pełny i nie ma miejsca na nową wartość |
| K02: | S[sptr] ← v | ; umieszczamy v ponad szczytem stosu |
| K03: | sptr ← sptr + 1 | ; zwiększamy wskaźnik stosu |
| K04: | Zakończ |
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
| S | – | tablica przechowująca stos |
Ze szczytu stosu zostaje usunięty element.
| K01 | Jeśli sptr > 0, to sptr ← sptr - 1 | ; jeśli stos coś zawiera, to usuwamy element na szczycie stosu |
| K02: | Zakończ |
Każdy element listy jest następującą strukturą danych:
struct slistEl
{
slistEl * next;
typ_danych data;
}; |
... slistEl * stack; ... |
Przed pierwszym użyciem wskaźnik stack musi być odpowiednio wyzerowany:
... stack = NULL; ... |
| p | – | wskaźnik szczytu stosu |
True, jeśli na stosie nie ma żadnego elementu, inaczej false
| K01 | Jeśli p = nil, to zakończ z wynikiem true |
| K02: | Zakończ z wynikiem false |
| p | – | wskaźnik szczytu stosu |
Zwraca wskazanie elementu, który jest bieżącym szczytem stosu lub nil, jeśli stos jest pusty
| K01: | Zakończ z wynikiem p |
| p | – | wskaźnik szczytu stosu |
| v | – | zapisywana wartość |
Na stosie zostaje zapisana wartość v, jeśli jest na to miejsce. Inaczej nic nie zostaje zapisane.
| e | – | wskaźnik elementu listy |
| K01 | Utwórz element listy i umieść jego adres w e | |
| K02: | e→data ← v | ; dane umieszczamy w polu data |
| K03: | e→next ← p | ; następnikiem będzie bieżący szczyt stosu |
| K04: | p ← e | ; szczytem stosu staje się dodany element |
| K05: | Zakończ |
| p | – | wskaźnik szczytu stosu |
Ze szczytu stosu zostaje usunięty element.
| e | – | wskaźnik elementu listy |
| K01 | Jeśli p = nil, to zakończ | ; stos jest pusty |
| K02: | e ← p | ; zapamiętujemy szczyt stosu |
| K03 | p ← p→next | ; usuwamy ze stosu bieżący szczyt |
| K04: | Usuń z pamięci element wskazany przez e | |
| K05: | Zakończ |
Systemy pozycyjne służą do zapisu dowolnych liczb za pomocą skończonej liczby znaków, zwanych cyframi. Cyfry są umieszczane na kolejnych pozycjach w zapisie liczby. Pozycje te numerujemy od strony prawej do lewej (dla części całkowitej):
| cyfra: | C | C | C | ... | C | C | C | |
| numer pozycji: | n-1 | n-2 | n-3 | ... | 2 | 1 | 0 |
W powyższym zapisie cyfry oznaczyliśmy symbolicznie literą C. Cyfra zielona C znajduje się w zapisie liczby na pozycji o numerze 1, a cyfra czerwona C na pozycji o numerze n-2. Cały zapis składa się z n cyfr. Pozycje posiadają tzw. wagi, które określają wartości cyfr umieszczonych na tych pozycjach. Wagi pozycji obliczamy wg ich numeru. Do tego celu potrzebujemy bardzo ważnej wartości, która nosi nazwę podstawy systemu. Będziemy ją oznaczali małą literą p. Gdy znamy podstawę p i numer pozycji i-tej, to wagę pozycji obliczamy zawsze wg wzoru:

gdzie: w jest wagą, i numerem pozycji, p podstawą systemu.
Mając te informacje, możemy w prosty sposób wyliczyć wagi wszystkich pozycji w zapisie liczby:
| waga pozycji: | pn-1 | pn-2 | pn-3 | ... | p2 | p1 | p0 | |
| cyfra: | C | C | C | ... | C | C | C | |
| numer pozycji: | n-1 | n-2 | n-3 | ... | 2 | 1 | 0 |
Teraz wartość tak zapisanej liczby obliczamy jako sumę iloczynów cyfr przez wagi ich pozycji. Na przykład, dla powyższego zapisu będzie to:

gdzie: L – wartość liczby, Ci – cyfra na i-tej pozycji, p – podstawa
Cyfr jest zawsze tyle, ile wynosi podstawa systemu. Najmniejszą cyfrą jest 0. Największa cyfra ma wartość p-1. W zapisie liczby cyfry określają, ile razy waga danej pozycji jest użyta w wartości liczby. Dla przykładu policzmy wartość liczby trójkowej: 22101213 (aby nie mylić liczb zapisanych w innych systemach pozycyjnych z liczbami dziesiętnymi, za liczbą w indeksie dolnym podajemy podstawę):
22101213 = 2·36
+ 2·35 +
1·34 + 0·33
+ 1·32 +
2·31 + 1·30
22101213 = 2·729
+ 2·243 + 1·81
+ 0·27 + 1·9
+ 2·3 + 1·1
22101213 = 1458 +
486 + 81 + 0
+ 9 + 6 + 1
22101213 = 2041
A teraz liczba szóstkowa 5320146:
5320146 = 5·65
+ 3·64 +
2·63 + 0·62
+ 1·61 +
4·60
5320146 = 5·7776
+ 3·1296 + 2·216
+ 0·36 + 1·6
+ 4·1
5320146 = 38880 +
3888 + 432 + 0
+ 6 + 4
5320146 = 43210
Nasz problem polega na przeliczeniu liczby zapisanej dziesiętnie na tę sama liczbę zapisaną w systemie o podstawie p. Wykorzystujemy tutaj prostą własność dzielenia z resztą. Otóż, jeśli podzielimy liczbę przez podstawę p, to resztą z dzielenia będzie wartość ostatniej cyfry zapisu. Dla przykładu weźmy kilka liczb w różnych systemach pozycyjnych:
| 1012
= 5 5 / 2 = 2 i reszta 1 |
3156
= 119 119 / 6 = 19 i reszta 5 |
7289
= 593 593 / 9 = 65 i reszta 8 |
Dlaczego tak się dzieje? Odpowiedź jest bardzo prosta. Jeśli przyjrzymy się wzorowi na wartość liczby pozycyjnej, to dojdziemy do wniosku, że:
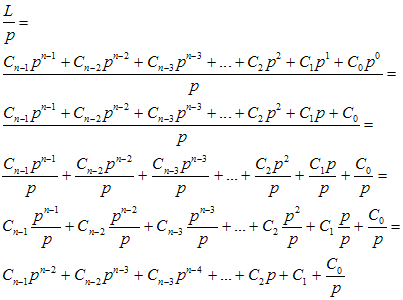
Jako wynik dzielenia całkowitego otrzymujemy wartość, która w docelowym zapisie pozycyjnym nie posiada ostatniej cyfry liczby wyjściowej – zobacz na wartości wag, które stoją przy kolejnych cyfrach – innymi słowy cyfry w wyniku dzielenia są cyframi wyjściowej liczby przesuniętymi o jedną pozycję w prawo bez ostatniej cyfry. Ostatni człon jest ułamkiem, zatem będzie resztą z dzielenia C0 przez p. Ponieważ każda cyfra jest mniejsza od p, to reszta będzie równa C0, czyli ostatniej cyfrze.
| 1012
= 5 102 = 2 → 5 / 2 = 2 i reszta 1 |
3156
= 119 316 = 19 → 119 / 6 = 19 i reszta 5 |
7289
= 593 729 = 65 → 593 / 9 = 65 i reszta 8 |
Liczbę dzielimy przez podstawę p.
Reszta z dzielenia jest równa wartości ostatniej cyfry liczby
zapisanej w systemie o podstawie p.
Część całkowita z dzielenia jest równa wartości, która w systemie o podstawie p
posiada wszystkie cyfry liczby z wyjątkiem ostatniej.
Zatem, aby otrzymać wszystkie cyfry liczby w zapisie o podstawie p dzielimy liczbę cyklicznie przez p, aż otrzymamy wynik zero. Kolejne reszty dadzą nam kolejne od końca cyfry.
Dla przykładu znajdziemy zapis liczby 99999 w systemie o podstawie p=5:
| 99999 / 5 = | 19999 | i reszta 4 |
| 19999 / 5 = | 3999 | i reszta 4 |
| 3999 / 5 = | 799 | i reszta 4 |
| 799 / 5 = | 159 | i reszta 4 |
| 159 / 5 = | 31 | i reszta 4 |
| 31 / 5 = | 6 | i reszta 1 |
| 6 / 5 = | 1 | i reszta 1 |
| 1 / 5 = | 0 | i reszta 1 |
Zatem:
99999 = 111444445
Zwróć uwagę, że cyfry w tym algorytmie otrzymujemy w odwrotnej kolejności – od końca. W tym miejscu wykorzystujemy własności stosu – dane wprowadzone na stos są odczytywane w kolejności odwrotnej do ich wprowadzenia. Zatem wyznaczamy kolejne cyfry, umieszczamy je na stosie, a gdy wartość liczby osiągnie 0, to przenosimy wszystkie cyfry ze stosu na wyjście – otrzymamy poprawny zapis liczby w systemie o podstawie p.
| L | – | wartość liczby, L
|
| p | – | podstawa systemu docelowego, p
|
Kolejne cyfry zapisu liczby w systemie o podstawie p
| S | – | stos cyfr |
| K01: | Utwórz pusty stos S | |
| K02: | S.push(L mod p) | ; obliczamy wartość ostatniej cyfry i umieszczamy ją na stosie |
| K03: | L ← L div p | ; obliczamy nową wartość L |
| K04: | Jeśli L > 0, to idź do K02 | ; wyznaczamy pozostałe cyfry |
| K05: | Dopóki S.empty() = false, wykonuj K06...K07 | |
| K06: | Pisz S.top() | ; wypisujemy cyfrę ze stosu |
| K07: | S.pop() | ; cyfrę usuwamy ze stosu |
| K08: | Zakończ |
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe