
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2011 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2011 mgr
Jerzy Wałaszek
|
Stos (ang. stack) jest sekwencyjną strukturą danych. Najprościej możemy go sobie wyobrazić jako stos książek na biurku. Nowe książki układamy na szczycie stosu (ang. stack top), wtedy stos rośnie w górę.
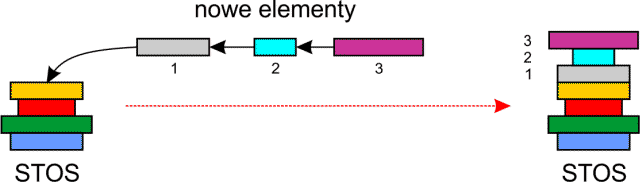
Ze stosu pobieramy książki znajdujące się na samej górze, wtedy stos maleje. Zwróć uwagę, że książki zawsze zdejmujesz ze stosu w kolejności odwrotnej do ich umieszczania – jako pierwszą zdejmiesz ostatnią książkę na stosie.
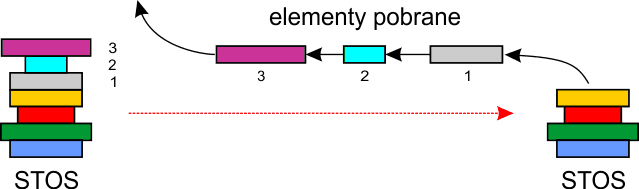
Wracając do świata komputerów, stos jest taką strukturą danych, z której odczytujemy elementy w kolejności odwrotnej do ich wstawiania. Struktura ta nosi nazwę LIFO (ang. Last In – First Out – wszedł ostatni, a wyszedł pierwszy).
Rozróżniamy następujące operacje dla stosu:
Stosy możemy realizować za pomocą tablic lub list jednokierunkowych. Realizacja tablicowa jest bardzo prosta i szybka. Stosujemy ją wtedy, gdy dokładnie wiemy, ile maksymalnie elementów będzie przechowywał stos – jest to potrzebne do przygotowania odpowiednio pojemnej tablicy na elementy stosu. Realizacja z pomocą listy jednokierunkowej jest przydatna wtedy, gdy nie znamy dokładnego rozmiaru stosu – listy dostosowują się dobrze do obszarów wolnej pamięci.
Do utworzenia stosu w tablicy potrzebujemy dwóch zmiennych. Pierwszą z nich będzie tablica, która przechowuje umieszczone na stosie elementy. Druga zmienna sptr służy do zapamiętywania pozycji szczytu stosu i nosi nazwę wskaźnika stosu (ang. stack pointer). Umawiamy się, że wskaźnik stosu zawsze wskazuje pustą komórkę tablicy, która znajduje się tuż ponad szczytem stosu:
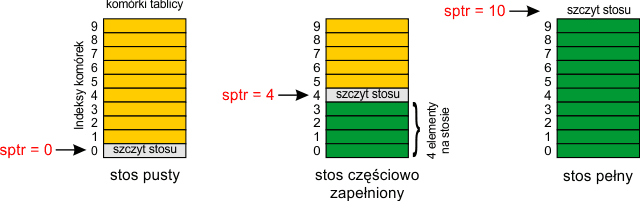
Po utworzeniu tablicy zmienna sptr musi zawsze być zerowana. Stos jest pusty, gdy sptr wskazuje początek tablicy, czyli komórkę o indeksie zero. Ta własność jest wykorzystywana w operacji empty. Stos jest pełny, gdy sptr ma wartość równą liczbie komórek tablicy. W takim przypadku na stosie nie można już umieszczać żadnych dalszych danych. gdyż trafiłyby poza obszar zarezerwowany na tablicę.
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
True, jeśli na stosie nie ma żadnego elementu, inaczej false
| K01 | Jeśli sptr = 0, to zakończ zwracając true |
| K02: | Zakończ zwracając false |
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
| n | – | rozmiar tablicy |
| S | – | tablica przechowująca stos |
Zawartość szczytu stosu lub wartość specjalna, jeśli stos jest pusty.
| K01 | Jeśli sptr = 0, to zakończ zwracając wartość specjalną | |
| K02: | Zakończ zwracając S[sptr - 1] |
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
| n | – | rozmiar tablicy |
| S | – | tablica przechowująca stos |
| v | – | zapisywana wartość |
Na stosie zostaje zapisana wartość v, jeśli jest na to miejsce. W przeciwnym razie v nie będzie zapisane.
| K01 | Jeśli sptr = n, to zakończ | ; stos jest pełny i nie ma miejsca na nową wartość |
| K02: | S[sptr] ← v | ; umieszczamy v ponad szczytem stosu |
| K03: | sptr ← sptr + 1 | ; zwiększamy wskaźnik stosu |
| K04: | Zakończ |
| sptr | – | zmienna przechowująca wskaźnik stosu tablicy |
| S | – | tablica przechowująca stos |
Ze szczytu stosu zostaje usunięty element.
| K01 | Jeśli sptr > 0, to sptr ← sptr - 1 | ; jeśli stos coś zawiera, to usuwamy element na szczycie stosu |
| K02: | Zakończ |
Każdy element listy jest następującą strukturą danych:
struct slistEl
{
slistEl * next;
typ_danych data;
}; |
... slistEl * stack; ... |
Przed pierwszym użyciem wskaźnik stack musi być odpowiednio wyzerowany:
... stack = NULL; ... |
| p | – | wskaźnik szczytu stosu |
True, jeśli na stosie nie ma żadnego elementu, inaczej false
| K01 | Jeśli p = nil, to zakończ zwracając true |
| K02: | Zakończ zwracając false |
| p | – | wskaźnik szczytu stosu |
Zwraca wskazanie elementu, który jest bieżącym szczytem stosu lub nil, jeśli stos jest pusty
| K01: | Zakończ zwracając p |
| p | – | wskaźnik szczytu stosu |
| v | – | zapisywana wartość |
Na stosie zostaje zapisana wartość v, jeśli jest na to miejsce. Inaczej nic nie zostaje zapisane.
| e | – | wskaźnik elementu listy |
| K01 | Utwórz element listy i umieść jego adres w e | |
| K02: | e→data ← v | ; dane umieszczamy w polu data |
| K03: | e→next ← p | ; następnikiem będzie bieżący szczyt stosu |
| K04: | p ← e | ; szczytem stosu staje się dodany element |
| K05: | Zakończ |
| p | – | wskaźnik szczytu stosu |
Ze szczytu stosu zostaje usunięty element.
| e | – | wskaźnik elementu listy |
| K01 | Jeśli p = nil, to zakończ | ; stos jest pusty |
| K02: | e ← p | ; zapamiętujemy szczyt stosu |
| K03 | p ← p→next | ; usuwamy ze stosu bieżący szczyt |
| K04: | Usuń z pamięci element wskazany przez e | |
| K05: | Zakończ |
Odwrotną notację polską ONP (ang. RPN – Reverse Polish Notation), zwana często również notacją Postfix, wymyślono w celu zapisywania dowolnych wyrażeń arytmetycznych bez nawiasów. W normalnym zapisie arytmetycznym operatory znajdują się pomiędzy argumentami:
2 + 2 6 - 4 3 * 5 12 / 3
Operatory posiadają priorytety, czyli "ważność". Jeśli w wyrażeniu wystąpią operatory o różnych priorytetach, to najpierw zostaną wykonane te ważniejsze:
3 + 5 * 2 = 3 + 10 = 13
Jeśli chcemy zmienić kolejność wykonywania działań, musimy używać nawiasów:
(3 + 5) * 2 = 8 * 2 = 16
W ONP problem ten nie występuje. Operator zawsze występuje po swoich argumentach:
2 2 + 6 4 - 3 5 * 12 3 /
Dzięki tej prostej zasadzie nawiasy stają się zbędne:
3 + 5 * 2 → 3 5 2 * + = 3 10 + = 13
(3 + 5) * 2 → 3 5 + 2 * = 8 2 * = 16
Do obliczenia wartości wyrażenia zapisanego w ONP potrzebujemy stosu. Zasada jest następująca:
Wyrażenie ONP przeglądamy od strony lewej do prawej. Jeśli napotkamy liczbę, to umieszczamy ją na stosie. Jeśli napotkamy operator, to ze stosu pobieramy dwie ostatnie liczby, wykonujemy na nich działanie zgodne z napotkanym operatorem i wynik umieszczamy z powrotem na stosie. Gdy wyrażenie zostanie przeglądnięte do końca, na szczycie stosu będzie znajdował się jego wynik.
Przykład:
| Wyrażenie ONP | Element | Operacja | Stos |
| 3 5 2 * + | --- | ||
| 3 5 2 * + | 3 | na stos |
3 |
| 3 5 2 * + | 5 | na stos |
5 |
| 3 5 2 * + | 2 | na stos |
2 |
| 3 5 2 * + | * |
pobierz 2 i 5 |
10 |
| 3 5 2 * + | + |
pobierz 10 i 3 |
13 |
Notacja ONP jest szeroko wykorzystywana w kompilatorach języków wysokiego poziomu. Istnieją również języki, które do obliczeń stosują jedynie ONP – np. Forth.
Przed przystąpieniem do zaprojektowania algorytmu ONP musimy poczynić pewne ustalenia. Dla prostoty umawiamy się, że używać będziemy tylko czterech operatorów arytmetycznych:
Wyrażenie musi być poprawne – algorytm nie sprawdza jego poprawności.
Każdy element będzie wprowadzany w osobnym wierszu – w ten sposób pozbędziemy się problemu analizowania tekstu pod kątem zawartości w nim liczb i operatorów. W rzeczywistości wyrażenie zawarte w wierszu zostałoby najpierw rozbite na elementy składowe – liczby i operatory – a następnie elementy te zostałyby użyte do obliczenia wartości wyrażenia wg naszego algorytmu.
Liczby muszą mieć postać akceptowaną przez dany język programowania.
Ostatnim elementem wyrażenia jest znak "=". Powoduje on zakończenie obliczeń i wyprowadzenie wyniku ze stosu.
W algorytmie będziemy musieli rozpoznawać, czy wprowadzony element jest liczbą, czy też operatorem lub znakiem "=".
Tutaj wykorzystuje się najczęściej strumienie. Wykorzystujemy własność strumienia, który przy złej konwersji daje wartość 0. Wypróbuj poniższy program dla strumienia cin:
#include <iostream>
using namespace std;
int main()
{
double x;
cout << (cin >> x) << endl;
return 0;
}
Program odczytuje ze strumienia cin ciąg znaków i stara się je zamienić na liczbę zmiennoprzecinkową dla zmiennej x. Jeśli konwersja się powiedzie, to operacja (cin >> x) zwróci jakąś wartość różną od zera. Jeśli ciągu znaków nie da się zamienić na liczbę, to operacja zwróci wartość 0 (w programie wpisz wartość poprawną, np. 12.54, a następnie niepoprawną, np. ABC – za pierwszym razem otrzymasz coś różnego od zera, a za drugim zero). Jeśli operacje takie wykonujemy w pętli, to należy wyzerować stan znaczników błędów strumienia za pomocą funkcji cin.clear() – inaczej dostaniemy poprzednią wartość błędu.
Na tym prostym fakcie oprzemy rozpoznawanie, czy wprowadzony łańcuch tekstu reprezentuje liczbę, czy nie. Jako strumień wykorzystamy strumień łańcuchowy. Będzie nam potrzebny plik nagłówkowy sstream, który definiuje klasy strumieni łańcuchowych.
#include <iostream>
#include <sstream>
#include <string>
using namespace std;
int main()
{
double x;
stringstream ss; // strumień łańcuchowy
string s; // łańcuch;
cin >> s; // czytamy łańcuch znaków
ss << s; // odczytany łańcuch umieszczamy w strumieniu
if(ss >> x) // konwertujemy na liczbę i sprawdzamy, czy konwersja była poprawna
cout << "LICZBA\n";
else
cout << "NIE LICZBA\n";
return 0;
}
| S | – | stos liczb zmiennoprzecinkowych |
Kolejne elementy wyrażenia odczytujemy ze standardowego wejścia
Wartość wyrażenia ONP na szczycie stosu S
| e | – | przechowuje odczytaną informację z wejścia jako łańcuch tekstowy |
| v1, v2 | – | przechowują argumenty operacji |
| K01: | Czytaj e | ; odczytujemy kolejne elementy wyrażenia ONP |
| K02: | Jeśli e = "=", to zakończ | ; znak = kończy wyrażenie ONP |
| K03: | Jeśli e jest liczbą, to idź do K09 | ; liczby umieszczamy na stosie |
| K04: | v2 ← S.top() S.pop() |
; pobieramy ze stosu argumenty operacji |
| K05: | v1 ← S.top() S.pop() |
|
| K06: | Wykonaj operację na v1 i v2
zgodnie z zawartością e. Wynik umieść w v1 |
; wykonujemy obliczenia zgodnie ze znakiem operatora |
| K07: | S.push(v1) | ; wynik trafia na stos |
| K08: | Idź do K01 | ; kontynuujemy przetwarzanie wyrażenia |
| K09: | Przekształć e na liczbę w v1 | |
| K10: | Idź do K07 | ; liczbę umieszczamy na stosie |
Kolejnym problemem jest przekształcanie wyrażeń symbolicznych ze
zwykłej notacji na ONP.
W wyrażeniu symbolicznym zamiast wartości liczbowych występują symbole: (a + b) * c
Gdy obliczaliśmy wartość wyrażenia ONP, stos był używany do przechowywania wyników częściowych obliczeń – czyli był to stos liczbowy. Przy konwersji wyrażenia arytmetycznego na postać ONP również wykorzystujemy stos, jednakże tutaj będzie on przechowywał nie liczby, a operatory. Zasada jest następująca:
Jeśli dojdziemy do końca wyrażenia, to ze stosu
operatorów pobieramy operatory i przenosimy je kolejno na wyjście aż do
wyczyszczenia stosu. Algorytm kończymy.
Jeśli odczytanym elementem jest symbol zmiennej, to przenosimy go na
wyjście.
Jeśli odczytanym elementem jest nawias otwierający, to umieszczamy go na
stosie.
Jeśli odczytanym elementem jest nawias zamykający, to ze stosu przesyłamy na
wyjście wszystkie operatory, aż do napotkania nawiasu otwierającego, który
usuwamy ze stosu.
Jeśli odczytanym elementem jest operator, to ze stosu na wyjście przesyłamy
wszystkie operatory o priorytecie wyższym od priorytetu odczytanego
operatora. Po tej operacji operator umieszczamy na stosie.
Kontynuujemy od początku z następnym elementem.
Przykład:
| Wyrażenie | Element | Operacja | Stos | Wyjście |
| ( a + b * c - d ) / ( e + f ) = | start | --- | ||
| ( a + b * c - d ) / ( e + f ) = | ( |
na stos |
( |
|
| ( a + b * c - d ) / ( e + f ) = | a |
na wyjście |
( |
a |
| ( a + b * c - d ) / ( e + f ) = | + |
na stos |
+ |
a |
| ( a + b * c - d ) / ( e + f ) = | b |
na wyjście |
+ |
a b |
| ( a + b * c - d ) / ( e + f ) = | * |
na stos |
* |
a b |
| ( a + b * c - d ) / ( e + f ) = | c |
na wyjście |
* |
a b c |
| ( a + b * c - d ) / ( e + f ) = | - |
ze
stosu na wyjście |
- |
a b c * |
| ( a + b * c - d ) / ( e + f ) = | d |
na wyjście |
- |
a b c * d |
| ( a + b * c - d ) / ( e + f ) = | ) |
ze
stosu na wyjście |
--- |
a b c * d - + |
| ( a + b * c - d ) / ( e + f ) = | / |
na stos |
/ |
a b c * d - + |
| ( a + b * c - d ) / ( e + f ) = | ( |
na stos |
( |
a b c * d - + |
| ( a + b * c - d ) / ( e + f ) = | e |
na wyjście |
( |
a b c * d - + e |
| ( a + b * c - d ) / ( e + f ) = | + |
na stos |
+ |
a b c * d - + e |
| ( a + b * c - d ) / ( e + f ) = | f |
na wyjście |
+ |
a b c * d - + e f |
| ( a + b * c - d ) / ( e + f ) = | ) |
ze
stosu na wyjście |
/ |
a b c * d - + e f + |
| ( a + b * c - d ) / ( e + f ) = | koniec |
ze stosu na wyjście |
--- |
a b c * d - + e f + / |
Przed zaprojektowaniem algorytmu ustalamy co następuje:
Symbole są zbudowane z pojedynczych liter. Chodzi tutaj o
uproszczenie analizy wyrażenia. Gdy napotkamy literę, to traktujemy ją jako
symbol.
W wyrażeniu dozwolone są tylko operacje +, -, *, / i ^
(potęgowanie).
Wyrażenie wejściowe musi być poprawne – algorytm nie sprawdza tego.
Operacje posiadają priorytety zgodne z zasadami arytmetyki – najwyższy priorytet
ma potęgowanie, później mnożenie i dzielenie, a na końcu dodawanie i
odejmowanie.
Wyrażenie kończy się znakiem "=".
symboliczne wyrażenie arytmetyczne
wyrażenie ONP
| S | – | stos operatorów |
| c | – | znak odczytany z wejścia |
| p(c) | – | funkcja zwracająca priorytet: ( = 0 + - = 1 * / = 2 ^ = 3 |
| K01: | Utwórz pusty stos S | |
| K02: | Czytaj c | ; odczytujemy znak z wejścia |
| K03: | Jeśli c ≠ '=', to idź do K08 | ; sprawdzamy, czy koniec wyrażenia |
| K04: | Dopóki S.empty() = false, wykonuj K05...K06 | |
| K05: | Pisz S.top() | ; na wyjście przesyłamy operatory ze stosu |
| K06: | S.pop() | ; przesłany operator usuwamy ze stosu |
| K07: | Zakończ | |
| K08: | Jeśli c ≠ '(', to idź do K11 | ; sprawdzamy, czy mamy nawias otwierający |
| K09: | S.push('(') | ; nawias otwierający umieszczamy na stosie |
| K10: | Idź do K02 | ; i kontynuujemy przetwarzanie wyrażenia |
| K11: | Jeśli c ≠ ')', to idź do K17 | ; sprawdzamy, czy mamy nawias zamykający |
| K12: | Dopóki S.top() ≠ '(', wykonuj K13...K14 | |
| K13: | Pisz S.top() | ; ze stosu przesyłamy na wyjście operatory |
| K14: | S.pop() | ; aż do napotkania nawiasu otwierającego |
| K15: | S.pop() | ; usuwamy ze stosu nawias otwierający |
| K16: | Idź do K02 | ; i kontynuujemy przetwarzanie wyrażenia |
| K17: | Jeśli c ≠ operator, to idź do K23 | ; sprawdzamy, czy mamy operator |
| K18: | Dopóki S.empty() = false
|
|
| K19: | Pisz S.top() | ; na wyjście przesyłamy ze stosu operatory |
| K20: | S.pop() | ; o wyższych priorytetach |
| K21: | S.push(c) | ; operator umieszczamy na stosie |
| K22: | Idź do K02 | ; i kontynuujemy przetwarzanie wyrażenia |
| K23: | Pisz c | ; z przesyłamy na wyjście |
| K24: | Idź do K02 | ; i kontynuujemy przetwarzanie wyrażenia |
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe