
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2011 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2011 mgr
Jerzy Wałaszek
|
Zadanie domowe - metoda DFS dla macierzy sąsiedztwa i
macierzy incydencji
Znajdowanie drogi w labiryncie metodą DFS - demonstracja
wizualna z wykorzystaniem biblioteki newconio
Rozwiązanie zadań 12 ... 16 - DFS
Znajdowanie najkrótszej drogi w labiryncie metodą BFS -
demonstracja wizualna z wykorzystaniem biblioteki newconio
Rozwiązanie zadań 17...20 - BFS
Procedura przejścia grafu (ang. graph traversal) polega na odwiedzeniu w systematyczny sposób wszystkich wierzchołków w grafie, do których można dojść wzdłuż dostępnych krawędzi. Procedura taka potrzebna jest w wielu problemach grafowych, na przykład:
Znajdowania ścieżek wiodących od jednego wierzchołka do
innego w grafie - ścieżka (ang. path) jest
ciągiem krawędzi, które łączą się kolejno ze sobą.
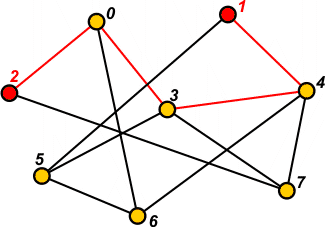
Znajdowania cykli - cykl (ang. cycle)
jest ścieżką w grafie, która zaczyna się w danym wierzchołku i kończy się w
nim.
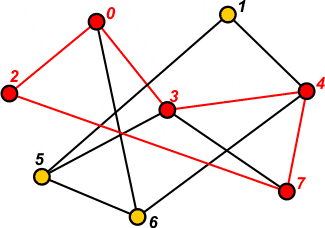
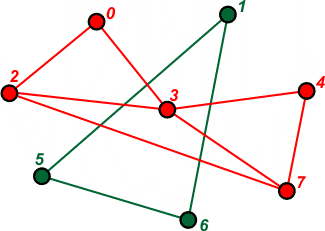
Znajdowania spójnych składowych - spójna składowa
(ang. connected component) jest maksymalną częścią
grafu o takiej własności, iż z każdego jej wierzchołka prowadzą ścieżki do
wszystkich pozostałych wierzchołków w tej części. Mówimy, że graf jest
spójny (ang. connected graph), jeśli posiada
jedną spójną składową obejmującą wszystkie jego wierzchołki. Poniższy graf
nie jest spójny, ponieważ posiada dwie spójne składowe.
Do przechodzenia grafu musimy zabrać się w sposób uporządkowany, aby nie pominąć żadnego wierzchołka i żadnej krawędzi. Z wierzchołkami grafu kojarzymy dodatkową strukturę danych (tablicę), w której przechowujemy informację, czy dany wierzchołek jest:
Nie odwiedzony - procedura przechodzenia grafu jeszcze nie dotarła do danego wierzchołka.
Przetwarzany - procedura przechodzenia grafu dotarła do danego wierzchołka i właśnie go przetwarza (np. przeszukuje wszystkie krawędzie, które prowadzą do jego sąsiadów).
Przetworzony - procedura przechodzenia grafu odwiedziła już ten wierzchołek i całkowicie przetworzyła związane z nim dane.
W niektórych przypadkach możemy się ograniczać do oznaczania wierzchołków tylko jako odwiedzone lub jeszcze nie odwiedzone.
Procedura DFS (ang. Depth First Search - przeszukiwanie najpierw w głąb) rozpoczyna działanie w wybranym wierzchołku grafu, który oznacza jako odwiedzony. Następnie przechodzi wzdłuż dostępnej krawędzi do sąsiada tego wierzchołka, który nie został jeszcze odwiedzony. Przechodzenie jest kontynuowane dalej (w głąb grafu), aż zostanie osiągnięty wierzchołek, który nie posiada nie odwiedzonych sąsiadów. Wtedy procedura wraca do poprzednio odwiedzonego wierzchołka i kontynuuje wzdłuż kolejnej dostępnej krawędzi.
Procedurę DFS realizujemy za pomocą rekurencji lub stosu. Rekurencja polega na wywoływaniu procedury przez samą siebie. Stos jest strukturą danych, w której składujemy kolejne elementy, lecz odczyt zawsze odbywa się w kierunku odwrotnym - od ostatnio umieszczonego na stosie elementu. DFS może pracować z każdą z poznanych reprezentacji grafu, lecz najbardziej efektywne będą listy sąsiedztwa, które umożliwiają bezpośredni dostęp do sąsiadów danego wierzchołka. Działanie DFS jest następujące:
Przeglądanie grafu rozpoczynamy od wierzchołka v.
Tworzymy pusty stos S.
Wierzchołek v umieszczamy na stosie S.
Rozpoczynamy pętlę, która sprawdza na początku, czy stos S zawiera dane. Jeśli tak, wykonujemy poniższe operacje. Jeśli nie, kończymy.
Pobieramy wierzchołek v.
Sprawdzamy, czy jest odwiedzony. Jeśli tak, to wykonujemy od początku następny obieg pętli.
Wierzchołek v zaznaczamy jako odwiedzony.
Przeglądamy wszystkich sąsiadów wierzchołka v. Jeśli dany sąsiad nie jest odwiedzony, to umieszczamy go na stosie.
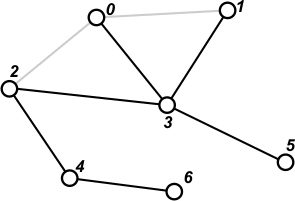
Prześledźmy teraz sposób działania DFS na poniższym grafie, który zadany jest listami sąsiedztwa:
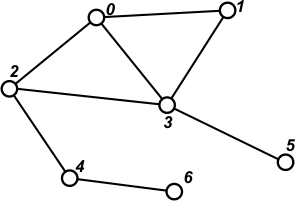 |
|
| Sytuacja | Stos | Opis |
 |
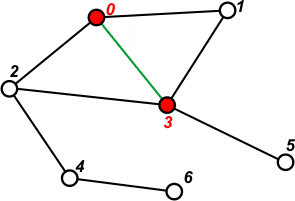
[ ] | Wybieramy wierzchołek startowy - tutaj niech będzie to wierzchołek 0. Wybrany wierzchołek zaznaczamy jako odwiedzony - tutaj będzie to kolor czerwony. |
 |
[1 2 3] | Przeglądamy listę sąsiedztwa wierzchołka 0. Na stosie umieszczamy wierzchołki z tej listy, które nie zostały jeszcze odwiedzone. |
 |
[1 2] | Ze stosu pobieramy ostatni element - 3. Przechodzimy do tego wierzchołka. Ponieważ nie jest on jeszcze odwiedzony, zaznaczamy go jako odwiedzonego i przetwarzamy - gdyby wierzchołek okazał się odwiedzony, zrezygnowalibyśmy z jego przetworzenia, ponieważ algorytm DFS już zrobił to wcześniej. |
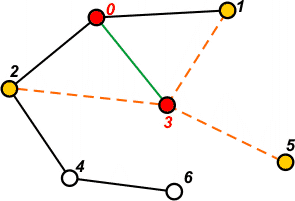 |
[1 2 1 2 5] | Przetworzenie wierzchołka 3 polega na przeglądnięciu jego listy sąsiedztwa i umieszczeniu na stosie wierzchołków, które nie są odwiedzone - w tym przypadku 1, 2 i 5. |
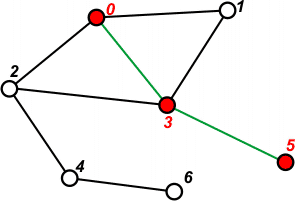 |
[1 2 1 2] | Pobieramy ze stosu ostatni element i przechodzimy do wierzchołka 5. Ponieważ jest nie odwiedzony, zaznaczamy go jako odwiedzonego. Na stosie nie umieszczamy nic, ponieważ jedynym sąsiadem jest wierzchołek 3, a ten został już wcześniej przetworzony przez DFS. |
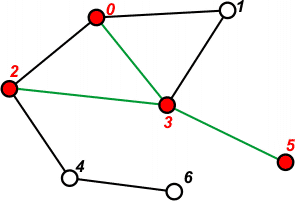 |
[1 2 1] | Pobieramy ze stosu ostatni element - 2. Przechodzimy do wierzchołka 2. Ponieważ nie jest jeszcze odwiedzony, zaznaczamy go jako odwiedzonego. |
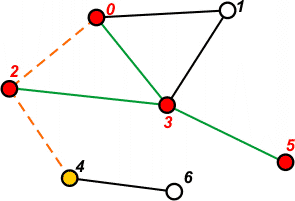 |
[1 2 1 4] | Przetwarzamy wierzchołek 2. Na stosie umieszczamy tylko wierzchołek 4, ponieważ pozostałe są już wcześniej przetworzone. |
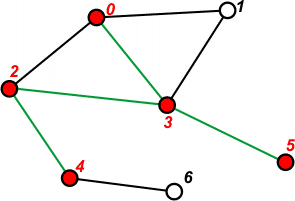 |
[1 2 1] | Pobieramy ze stosu ostatni element - 4 i przechodzimy do tego wierzchołka. Zaznaczamy go jako przetworzony. |
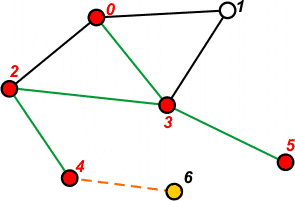 |
[1 2 1 6] | Przeglądamy listę sąsiedztwa wierzchołka 4. Na stos trafi tylko wierzchołek 6, ponieważ wierzchołek 2 jest już przetworzony. |
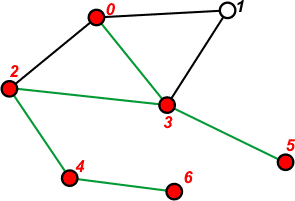 |
[1 2 1] | Pobieramy ze stosu ostatni element - 6. Przechodzimy do wierzchołka 6 i oznaczamy go jako przetworzony. Na stosie nic nie umieszczamy, ponieważ wierzchołek 4 został już przetworzony. |
 |
[1 2] | Pobieramy ze stosu ostatni element - 1. Przechodzimy do wierzchołka 1 i oznaczamy go jako odwiedzony. Na stosie nic nie umieszczamy, ponieważ wierzchołki 0 i 3 są już przetworzone. |
 |
[ ] | Pobieramy ze stosu element 2. Wierzchołek 2 jest już
przetworzony - nic dalej z nim nie robimy. Pobieramy ze stosu element 1. Wierzchołek 1 również jest przetworzony - nic z nim nie robimy. Stos staje się pusty. Procedura DFS zakończyła zadanie. Jeśli graf był spójny, to DFS przeszła przez wszystkie jego wierzchołki - powstało tzw. drzewo rozpinające grafu (ang. spanning tree). Drzewo rozpinające jest podgrafem, w którym nie ma cykli - ścieżek rozpoczynających się i kończących w tym samym wierzchołku. Startując DFS z różnych wierzchołków grafu możemy otrzymywać różne drzewa rozpinające, ponieważ DFS może przechodzić po innych ścieżkach. |
Poniższy program wczytuje graf i przechodzi go za pomocą procedury DFS, wypisując mijane po drodze wierzchołki. Graf jest grafem nieskierowanym. W programie reprezentujemy go za pomocą list sąsiedztwa. Dane wejściowe do programu składają się z definicji grafu oraz numeru wierzchołka, od którego rozpocznie procedura DFS:
|
|
7 8 0 1 0 2 0 3 1 3 2 3 2 4 3 5 4 6 0 |
| Code::Blocks |
// Przechodzenie grafu w głąb - DFS, stos
// Graf nieskierowany
// (C)2011 mgr Jerzy Wałaszek
//-----------------------------
#include <iostream>
#include <list>
#include <stack>
using namespace std;
int main()
{
int n,m,i,v1,v2;
// Odczytujemy n i m
cin >> n >> m;
// Tworzymy tablicę n pustych list
list<int> * A;
A = new list<int> [n];
// Wczytujemy poszczególne krawędzie i umieszczamy informację o nich na listach
for(i = 0; i < m; i++)
{
cin >> v1 >> v2;
// Do listy A[v1] dodajemy wierzchołek v2
A[v1].push_back(v2);
// Do listy A[v2] dodajemy wierzchołek v1, aby krawędź była obukierunkowa
if(v1 != v2) A[v2].push_back(v1);
}
// Tworzymy dynamicznie tablicę odwiedzin
bool * visited = new bool[n];
// Utworzoną tablicę inicjujemy
for(i = 0; i < n; i++) visited[i] = false;
// Tworzymy stos
stack<int> S;
// Pobieramy wierzchołek startowy i umieszczamy go na stosie
cin >> v1; S.push(v1);
// W pętli przechodzimy graf w głąb
cout << endl;
while(!S.empty())
{
// Odczytujemy wierzchołek ze stosu. Usuwamy go ze stosu
v1 = S.top(); S.pop();
// Jeśli wierzchołek jest nieodwiedzony, to odwiedzamy go i
// na stosie umieszczamy jego nieodwiedzonych sąsiadów
if(!visited[v1])
{
visited[v1] = true;
for(list<int>::iterator it = A[v1].begin(); it != A[v1].end(); it++)
if(!visited[*it]) S.push(*it);
// Odwiedzony wierzchołek wypisujemy
cout << v1 << " ";
}
}
cout << endl << endl;
// Usuwamy tablice dynamiczne z pamięci komputera
delete [] visited;
delete [] A;
return 0;
}
|
|
7 8 0 1 0 2 0 3 1 3 2 3 2 4 3 5 4 6 0 0 3 5 2 4 6 1 |
Przekształć podany program, tak aby współpracował z grafem zdefiniowanym za pomocą macierzy sąsiedztwa lub macierzy incydencji. Porównaj efektywność tych reprezentacji dla procedury DFS.
W przypadku procedury rekurencyjnej postępujemy wg poniższego pseudokodu:
void DFS(int wierzchołek)
{
odwiedzony[wierzchołek] = true;
for(i = początek_listy; i != koniec_listy; i++)
if(!odwiedzony[lista[i]]) DFS(lista[i]);
}
Tablice lista oraz odwiedzony muszą być globalne.
| Code::Blocks |
// Przechodzenie grafu w głąb - DFS, rekurencja
// Graf nieskierowany
// (C)2011 mgr Jerzy Wałaszek
//-----------------------------
#include <iostream>
#include <list>
#include <stack>
using namespace std;
// Tablice globalne
list<int> * A;
bool * visited;
// Rekurencyjna funkcja DFS
void DFS(int v)
{
visited[v] = true;
cout << v << " ";
for(list<int>::iterator it = A[v].begin(); it != A[v].end(); it++)
if(!visited[*it]) DFS(*it);
}
int main()
{
int n,m,i,v1,v2;
// Odczytujemy n i m
cin >> n >> m;
// Tworzymy tablicę n pustych list
A = new list<int> [n];
// Wczytujemy poszczególne krawędzie i umieszczamy informację o nich na listach
for(i = 0; i < m; i++)
{
cin >> v1 >> v2;
// Do listy A[v1] dodajemy wierzchołek v2
A[v1].push_back(v2);
// Do listy A[v2] dodajemy wierzchołek v1, aby krawędź była obukierunkowa
if(v1 != v2) A[v2].push_back(v1);
}
// Tworzymy dynamicznie tablicę odwiedzin
visited = new bool[n];
// Utworzoną tablicę inicjujemy
for(i = 0; i < n; i++) visited[i] = false;
// Pobieramy wierzchołek startowy i uruchamiamy DFS
cin >> v1;
cout << endl;
DFS(v1);
cout << endl << endl;
// Usuwamy tablice dynamiczne z pamięci komputera
delete [] visited;
delete [] A;
return 0;
}
|
|
7 8 0 1 0 2 0 3 1 3 2 3 2 4 3 5 4 6 0 0 3 5 2 4 6 1 |
Zwróć uwagę, iż wyniki rekurencyjnej metody DFS są inne od stosowej metody DFS. Spowodowane jest to tym, iż w metodzie rekurencyjnej DFS rozpoczyna wchodzenie w głąb grafu od pierwszego sąsiada na liście. W metodzie ze stosem był to ostatni sąsiad (elementy listy są kolejno umieszczane na stosie od pierwszego do ostatniego, lecz kierunek ich pobierania ze stosu jest odwrotny). Aby uzyskać ten sam efekt, możemy zastosować do przeglądania listy tzw. odwrotny iterator (ang. reverse iterator). Działa on identycznie jak zwykły iterator, tyle że operacja ++ przesuwa go na poprzedni element listy, a operacja -- na następny, czyli na odwrót w stosunku do zwykłego iteratora. Również będziemy musieli skorzystać z funkcji:
rbegin() - zwraca iterator do ostatniego elementu na liście
rend() - zwraca iterator przed pierwszym elementem listy
| Code::Blocks |
// Rekurencyjna funkcja DFS z odwrotnym iteratorem
void DFS(int node)
{
visited[node] = true;
cout << node << " ";
for(list<int>::reverse_iterator it = A[node].rbegin(); it != A[node].rend(); it++)
if(!visited[*it]) DFS(*it);
}
|
|
7 8 0 1 0 2 0 3 1 3 2 3 2 4 3 5 4 6 0 0 3 5 2 4 6 1 |
Przekształć podany program, tak aby współpracował z grafem zdefiniowanym za pomocą macierzy sąsiedztwa lub macierzy incydencji. Porównaj efektywność tych reprezentacji dla DFS.
Metoda BFS (ang. Breadth First Search - przeszukiwanie najpierw w szerz) wykorzystuje strukturę danych zwaną kolejką (ang. queue). Jest to struktura sekwencyjna. Dane dopisujemy na jej końcu, podobnie jak na stosie. Odczyt danych odbywa się kolejno z początku kolejki.
Zapis danych do kolejki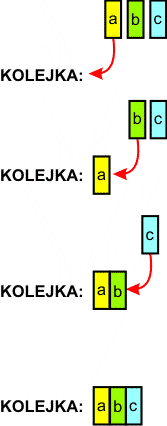 |
Odczyt danych z kolejki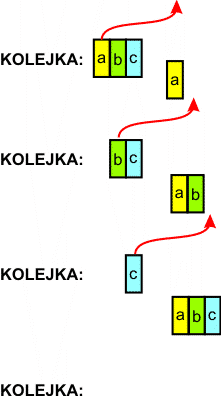 |
Dane odczytujemy z kolejki w takiej samej kolejności, w jakiej zostały zapisane w niej. Kolejkę możemy potraktować jako tzw. bufor, który przechowuje dane. Im więcej danych w kolejce, tym dłużej dany element jest przez nią przechowywany.
Działanie algorytmu BFS jest następujące:
Przeglądanie grafu rozpoczynamy od wybranego wierzchołka v.
Tworzymy pustą kolejkę Q.
W kolejce umieszczamy wierzchołek v.
Wierzchołek v oznaczamy jako odwiedzony
Dopóki kolejka Q nie jest pusta, wykonujemy poniższe operacje, inaczej kończymy.
Pobieramy z kolejki wierzchołek v.
Przeglądamy wszystkich sąsiadów v. Jeśli dany sąsiad nie jest odwiedzony, to umieszczamy go w kolejce i oznaczamy jako odwiedzony.
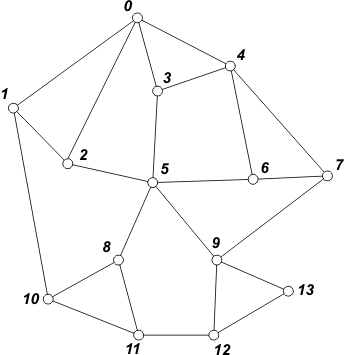
Prześledźmy BFS na prostym przykładzie. Przeglądany graf nieskierowany będzie zadany za pomocą list sąsiedztwa, które są najefektywniejszą reprezentacją grafu dla BFS.
 |
|
| Sytuacja | Kolejka | Opis |
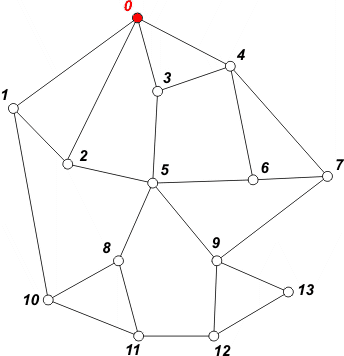 |
[ 0 ] | Rozpoczynamy od wierzchołka 0. Wierzchołek umieszczamy w kolejce i oznaczamy jako odwiedzony. |
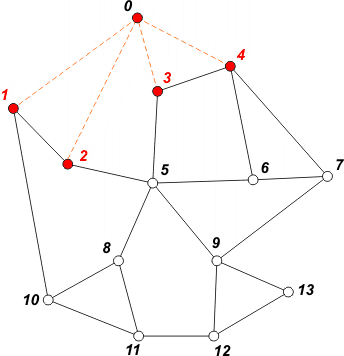 |
[ 1 2 3 4 ] | Pobieramy z kolejki wierzchołek 0. Przeglądamy jego sąsiadów. Do kolejki zapisujemy nieodwiedzonych sąsiadów 1, 2, 3 i 4. Wierzchołki te oznaczamy jako odwiedzone - zapobiega to ponownemu umieszczaniu danego wierzchołka w kolejce. |
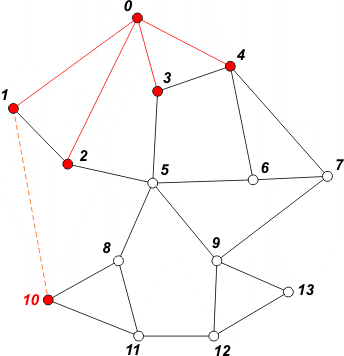 |
[ 2 3 4 10 ] | Pobieramy z kolejki wierzchołek 1. Jedynym nieodwiedzonym sąsiadem jest wierzchołek 10. Umieszczamy go w kolejce i oznaczamy jako odwiedzony. |
 |
[ 3 4 10 5 ] | Pobieramy z kolejki wierzchołek 2. W kolejce umieszczamy wierzchołek 5 i oznaczamy go jako odwiedzony. |
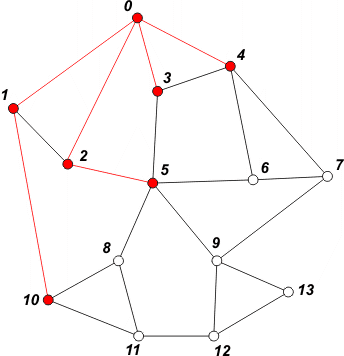 |
[ 4 10 5 ] | Pobieramy z kolejki wierzchołek 3. Nic nie dopisujemy do kolejki, ponieważ w tej chwili wierzchołek 3 nie posiada nieodwiedzonych sąsiadów. |
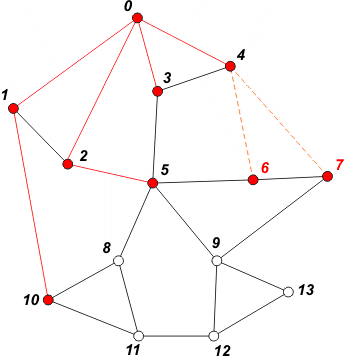 |
[ 10 5 6 7 ] | Pobieramy z kolejki wierzchołek 4. Do kolejki dopisujemy jego dwóch nieodwiedzonych sąsiadów: 6 i 7. Wierzchołki te oznaczamy jako odwiedzone. |
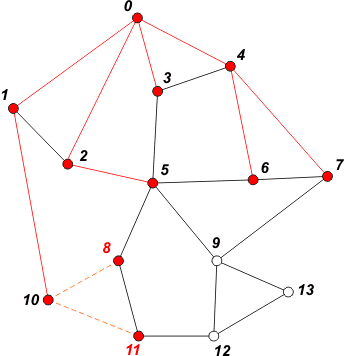 |
[ 5 6 7 8 11] | Pobieramy z kolejki wierzchołek 10. W kolejce umieszczamy sąsiadów 8 i 11. Oznaczamy je jako odwiedzone. |
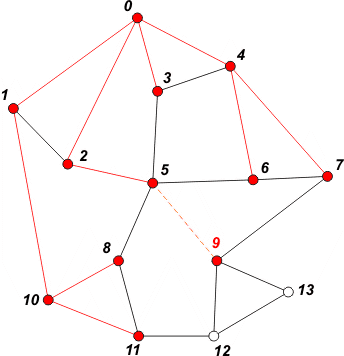 |
[ 6 7 8 11 9 ] | Pobieramy z kolejki wierzchołek 5. W kolejce umieszczamy sąsiada 9. Oznaczamy go jako odwiedzonego. |
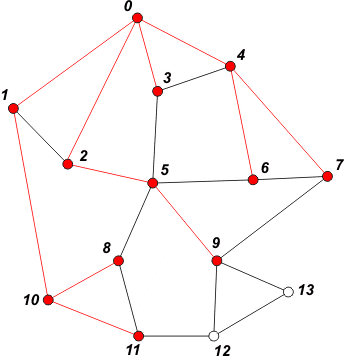 |
[ 11 9 ] | Pobieramy z kolejki wierzchołki 6, 7 i 8. Nic nie dopisujemy - brak nieodwiedzonych sąsiadów. |
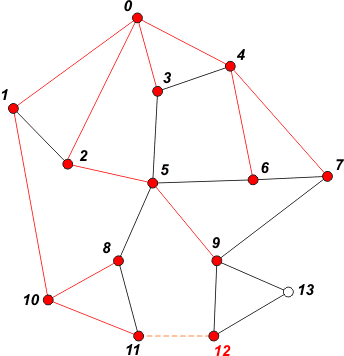 |
[ 9 12 ] | Pobieramy z kolejki wierzchołek 11. Dopisujemy do kolejki sąsiada 12 i oznaczamy go jako odwiedzonego. |
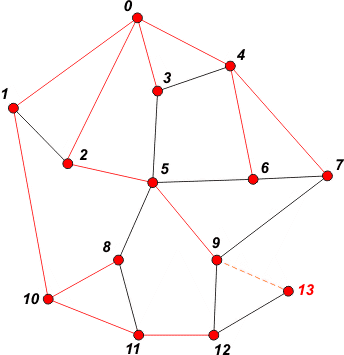 |
[ 12 13 ] | Pobieramy z kolejki wierzchołek 9. Dopisujemy do kolejki sąsiada
13 i oznaczamy go jako odwiedzonego. Przejście grafu jest zakończone, ponieważ od tego momentu nie ma w grafie nieodwiedzonych wierzchołków i BFS jedynie odczyta z kolejki wierzchołki 12 i 13. Po tej operacji kolejka staje się pusta, zatem algorytm zakończy działanie. |
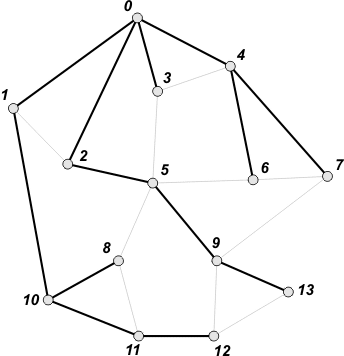 |
Przejście BFS tworzy drzewo rozpinające. Zwróć uwagę, że posiada ono bardzo ciekawą cechę. Wszystkie wierzchołki tego drzewa są połączone z wierzchołkiem startowym najkrótszymi ścieżkami (o najmniejszej liczbie krawędzi). Dzięki tej własności BFS jest często wykorzystywane do wyszukiwania najkrótszych ścieżek w grafie. |
Procedura BFS najpierw odwiedza wszystkie wierzchołki odległe o jedną krawędź od wierzchołka startowego. Gdy wszystkie te wierzchołki zostaną odwiedzone, BFS odwiedza kolejno wszystkie wierzchołki odległe o dwie krawędzie od wierzchołka startowego, potem o 3, 4, itd. To właśnie dzięki temu znajdowane są najkrótsze ścieżki w grafie.
Poniższy program wczytuje graf i przechodzi go za pomocą procedury BFS, wypisując mijane po drodze wierzchołki. Graf jest grafem nieskierowanym. W programie reprezentujemy go za pomocą list sąsiedztwa. Dane wejściowe do programu składają się z definicji grafu oraz numeru wierzchołka, od którego rozpocznie procedura BFS:
|
|
14 22 0 1 0 2 0 3 0 4 1 2 1 10 2 5 3 4 3 5 4 6 4 7 5 6 5 8 5 9 6 7 7 9 8 10 8 11 9 12 9 13 11 12 12 13 0 |
| Code::Blocks |
// Przejście BFS
// Graf nieskierowany
// (C)2011 mgr Jerzy Wałaszek
//-----------------------------
#include <iostream>
#include <queue>
#include <list>
using namespace std;
int main()
{
list<int> * A; // Tablica list sąsiedztwa grafu
int n,m,i,v1,v2;
queue<int>Q; // Kolejka dla dla BFS
// Odczytujemy n i m
cin >> n >> m;
// Tworzymy tablicę n pustych list sąsiedztwa
A = new list<int> [n];
// Wczytujemy poszczególne krawędzie i umieszczamy informację o nich na listach
for(i = 0; i < m; i++)
{
cin >> v1 >> v2; // Odczytujemy krawędź od v1 do v2
A[v1].push_back(v2); // Do listy A[v1] dodajemy wierzchołek v2
A[v2].push_back(v1); // Do listy A[v2] dodajemy wierzchołek v1
}
// Tworzymy dynamicznie tablicę odwiedzonych wierzchołków
bool * visited = new bool [n];
// Zerujemy tablicę visited
for(i = 0; i < n; i++) visited[i] = false;
// Odczytujemy wierzchołek startowy
cin >> v1;
// Odwiedzamy go i umieszczamy w kolejce
visited[v1] = true;
Q.push(v1);
// Pętla BFS
cout << endl;
while(!Q.empty()) // Dopóki w kolejce jest jakiś wierzchołek:
{
v1 = Q.front(); // Pobieramy wierzchołek z kolejki
Q.pop(); // Usuwamy z kolejki pobrany wierzchołek
cout << v1 << " "; // Wyświetlamy go
// Przeglądamy listę sąsiadów wierzchołka, umieszczając w kolejce
// wszystkie nieodwiedzone wierzchołki
for(list<int>::iterator it = A[v1].begin(); it != A[v1].end(); it++)
if(!visited[*it])
{
visited[*it] = true; // Zaznaczamy sąsiedni wierzchołek jako odwiedzony
Q.push(*it); // i umieszczamy go w kolejce
}
}
cout << endl << endl;
// Usuwamy tablice dynamiczne z pamięci komputera
delete [] visited;
delete [] A;
return 0;
}
|
|
14 22 0 1 0 2 0 3 0 4 1 2 1 10 2 5 3 4 3 5 4 6 4 7 5 6 5 8 5 9 6 7 7 9 8 10 8 11 9 12 9 13 11 12 12 13 0 0 1 2 3 4 10 5 6 7 8 9 11 12 13 |
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe