Autor artykułu: mgr Jerzy Wałaszek
©2017 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2017 mgr
Jerzy Wałaszek
|
|
Poczynając od tego rozdziału przechodzimy do opisu algorytmów
szybkich, tzn. takich, które posiadają klasę czasowej
złożoności obliczeniowej równą
O(n
log
n)
lub nawet lepszą.
W informatyce zwykle obowiązuje zasada, iż prosty algorytm posiada dużą złożoność obliczeniową, natomiast algorytm zaawansowany posiada małą złożoność obliczeniową, ponieważ wykorzystuje on pewne własności, dzięki którym szybciej dochodzi do rozwiązania. Wiele dobrych algorytmów sortujących korzysta z rekurencji, która powstaje wtedy, gdy do rozwiązania problemu algorytm wykorzystuje samego siebie ze zmienionym zestawem danych. Przykład: Jako przykład może posłużyć rekurencyjne obliczanie silni. Silnię liczby
n
należącej do zbioru liczb naturalnych definiujemy następująco: n! = 1 × 2 × 3 × ... × (n - 1) × n Na przykład: 5! = 1
×
2
×
3
×
4
×
5 = 120 Specyfikacja algorytmu
Lista kroków
Przykładowy program w języku C++
Dzięki rekurencji funkcja wyliczająca wartość silni staje się niezwykle prosta. Najpierw sprawdzamy warunek zakończenia rekurencji, tzn. sytuację, gdy wynik dla otrzymanego zestawu danych jest oczywisty. W przypadku silni sytuacja taka wystąpi dla n < 2 - silnia ma wartość 1. Jeśli warunek zakończania rekurencji nie wystąpi, to wartość wyznaczamy za pomocą rekurencyjnego wywołania obliczania silni dla argumentu zmniejszonego o 1. Wynik tego wywołania mnożymy przez n i zwracamy jako wartość silni dla n.
Wynaleziony w 1945 roku przez Johna von Neumanna
algorytm
sortowania przez scalanie jest algorytmem
rekurencyjnym. Wykorzystuje zasadę dziel i zwyciężaj,
która polega na podziale zadania głównego na zadania mniejsze dotąd, aż
rozwiązanie stanie się oczywiste. Algorytm sortujący dzieli porządkowany zbiór
na kolejne połowy dopóki taki podział jest możliwy (tzn.
podzbiór zawiera co najmniej dwa elementy). Następnie uzyskane w ten
sposób części zbioru rekurencyjnie sortuje tym samym algorytmem. Posortowane
części łączy ze sobą za pomocą scalania, tak aby wynikowy zbiór był posortowany. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Scalanie zbiorów uporządkowanychPodstawową operacją algorytmu jest scalanie dwóch zbiorów uporządkowanych w jeden zbiór również uporządkowany. Operację scalania realizujemy wykorzystując pomocniczy zbiór, w którym będziemy tymczasowo odkładać scalane elementy dwóch zbiorów. Ogólna zasada jest następująca:
Przykład: Połączmy za pomocą opisanego algorytmu dwa uporządkowane zbiory: { 1 3 6 7 9 } z { 2 3 4 6 8 }
Z podanego przykładu możemy wyciągnąć wniosek, iż operacja scalania dwóch uporządkowanych zbiorów jest dosyć prosta. Diabeł jak zwykle tkwi w szczegółach.
Algorytm scalania dwóch zbiorówPrzed przystąpieniem do wyjaśniania sposobu łączenia dwóch zbiorów uporządkowanych w jeden zbiór również uporządkowany musimy zastanowić się nad sposobem reprezentacji danych. Przyjmijmy, iż elementy zbioru będą przechowywane w jednej tablicy, którą oznaczymy literką d. Każdy element w tej tablicy będzie posiadał swój numer, czyli indeks z zakresu od 0 do n-1. Kolejnym zagadnieniem jest sposób reprezentacji scalanych zbiorów. W przypadku algorytmu sortowania przez scalanie zawsze będą to dwie przyległe połówki zbioru, który został przez ten algorytm podzielony. Co więcej, wynik scalenia ma być umieszczony z powrotem w tym samym zbiorze.
Przykład: Prześledźmy prosty przykład. Mamy posortować zbiór o postaci: { 6 5 4 1 3 7 9 2 }
Ponieważ w opisywanym tutaj algorytmie sortującym scalane podzbiory są przyległymi do siebie częściami innego zbioru, zatem logiczne będzie użycie do ich definicji indeksów wybranych elementów tych podzbiorów:
Przez podzbiór młodszy rozumiemy podzbiór zawierający elementy o indeksach mniejszych niż indeksy elementów w podzbiorze starszym.
Indeks końcowego elementu młodszej połówki zbioru z łatwością wyliczamy - będzie on o 1 mniejszy od indeksu pierwszego elementu starszej połówki.
Przykład:
Specyfikacja algorytmu scalaniaScalaj(ip, is, ik)Dane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków algorytmu scalania
Schemat blokowy algorytmu scalania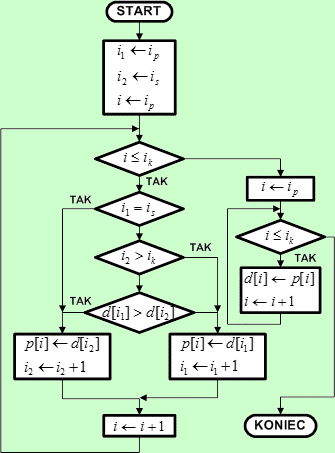
Operacja scalania dwóch podzbiorów wymaga dodatkowej pamięci o rozmiarze równym sumie rozmiarów scalanych podzbiorów. Dla prostoty na potrzeby naszego algorytmu zarezerwujemy tablicę p o rozmiarze równym rozmiarowi zbioru d[ ]. W tablicy p algorytm będzie tworzył zbiór tymczasowy, który po zakończeniu scalania zostanie przepisany do zbioru d[ ] w miejsce dwóch scalanych podzbiorów. Parametrami wejściowymi do algorytmu są indeksy ip, is oraz ik, które jednoznacznie definiują położenie dwóch podzbiorów do scalenia w obrębie tablicy d[ ]. Elementy tych podzbiorów będą indeksowane za pomocą zmiennych i1 (młodszy podzbiór od pozycji ip do is - 1) oraz i2 (starszy podzbiór od pozycji is do ik). Na początku algorytmu przypisujemy tym zmiennym indeksy pierwszych elementów w każdym podzbiorze. Zmienna i będzie zawierała indeksy elementów wstawianych do tablicy p[ ]. Dla ułatwienia indeksy te przebiegają wartości od ip do ik, co odpowiada obszarowi tablicy d[ ] zajętemu przez dwa scalane podzbiory. Na początku do zmiennej i wprowadzamy indeks pierwszego elementu w tym obszarze, czyli ip. Wewnątrz pętli sprawdzamy, czy indeksy i1 i i2 wskazują elementy podzbiorów. Jeśli któryś z nich wyszedł poza dopuszczalny zakres, to dany podzbiór jest wyczerpany - w takim przypadku do tablicy p przepisujemy elementy drugiego podzbioru. Jeśli żaden z podzbiorów nie jest wyczerpany, porównujemy kolejne elementy z tych podzbiorów wg indeksów i1 i i2. Do tablicy p[ ] zapisujemy zawsze mniejszy z porównywanych elementów. Zapewnia to uporządkowanie elementów w tworzonym zbiorze wynikowym. Po zapisie elementu w tablicy p[ ], odpowiedni indeks i1 lub i2 jest zwiększany o 1. Zwiększany jest również indeks i, aby kolejny zapisywany element w tablicy p[ ] trafił na następne wolne miejsce. Pętla jest kontynuowana aż do zapełnienia w tablicy p[ ] obszaru o indeksach od ip do ik. Wtedy przechodzimy do końcowej pętli, która przepisuje ten obszar z tablicy p[ ] do tablicy wynikowej d[ ]. Scalane zbiory zostają zapisane zbiorem wynikowym, który jest posortowany rosnąco. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Algorytm sortowania przez scalanieSortuj_przez_scalanie(ip, ik)Dane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków algorytmu sortującego
Schemat blokowy algorytmu sortującego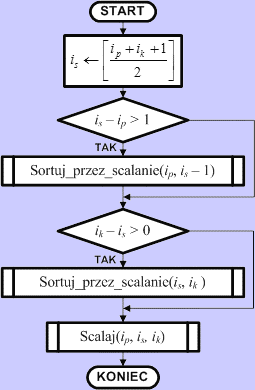 Algorytm sortowania przez scalanie jest algorytmem rekurencyjnym. Wywołuje się go z zadanymi wartościami indeksów ip oraz ik. Przy pierwszym wywołaniu indeksy te powinny objąć cały zbiór d, zatem ip = 0, a ik = n-1. Najpierw algorytm wyznacza indeks is, który wykorzystywany jest do podziału zbioru na dwie połówki: - młodszą o indeksach elementów od ip
do
is - 1 Następnie sprawdzamy, czy dana połówka zbioru zawiera więcej niż jeden element. Jeśli tak, to rekurencyjnie sortujemy ją tym samym algorytmem. Po posortowaniu obu połówek zbioru scalamy je za pomocą opisanej wcześniej procedury scalania podzbiorów uporządkowanych i kończymy algorytm. Zbiór jest posortowany. W przykładowych programach procedurę scalania umieściliśmy bezpośrednio w kodzie algorytmu sortującego, aby zaoszczędzić na wywoływaniu.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
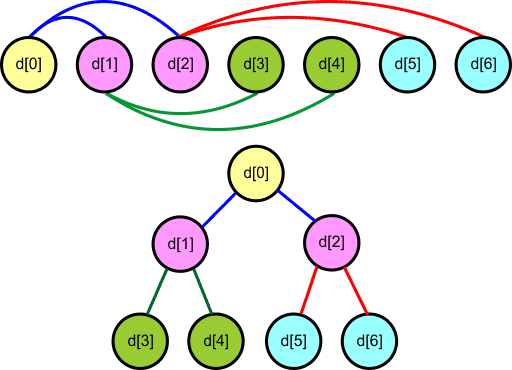
Drzewo binarneDotychczas operowaliśmy na prostych strukturach danych,
takich jak
tablice. W tablicy elementy ułożone są
zgodnie z ich numeracją, czyli indeksami.
Jeśli za punkt odniesienia weźmiemy element
d[i]
(i
=
2,3,..,n-1;
n
-
liczba elementów w tablicy), to elementem
poprzedzającym go będzie element o mniejszym o
1
indeksie, czyli d[i
- 1].
Elementem następnym będzie element o indeksie o
1
większym, czyli d[i
+ 1]. Jest to
tzw.
hierarchia liniowa - elementy następują jeden
za drugim. Graficznie możemy przedstawić to tak:
Pierwszy element d[0] nie posiada poprzednika (ang. predecessor - elementu poprzedzającego w ciągu). Ostatni element d[n-1] nie posiada następnika (ang. successor - elementu następnego w ciągu). Wszystkie pozostałe elementy posiadają poprzedniki i następniki. Drzewo binarne jest hierarchiczną strukturą danych, którego elementy będziemy nazywali węzłami (ang. node) lub wierzchołkami. W hierarchii liniowej każdy element może posiadać co najwyżej jeden następnik. W drzewie binarnym każdy węzeł może posiadać dwa następniki (stąd pochodzi nazwa drzewa - binarny = dwójkowy, zawierający dwa elementy), które nazwiemy potomkami. dziećmi lub węzłami potomnymi danego węzła (ang. child node). 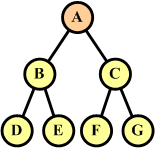 Węzły są połączone krawędziami symbolizującymi następstwo kolejnych elementów w strukturze drzewa binarnego. Według rysunku po prawej stronie węzeł A posiada dwa węzły potomne: B i C. Węzeł B nosi nazwę lewego potomka (ang. left child node), a węzeł C nosi nazwę prawego potomka (ang. right child node). Z kolei węzeł B posiada węzły potomne D i E, a węzeł C ma węzły potomne F i G. Jeśli dany węzeł nie posiada dalszych węzłów potomnych, to jest w strukturze drzewa binarnego węzłem terminalnym. Taki węzeł nosi nazwę liścia (ang. leaf node). Na naszym rysunku liśćmi są węzły terminalne D, E, F i G. Rodzicem, przodkiem (ang. parent node) lub węzłem nadrzędnym będziemy nazywać węzeł leżący na wyższym poziomie hierarchii drzewa binarnego. Dla węzłów B I C węzłem nadrzędnym jest węzeł A. Podobnie dla węzłów D i E węzłem nadrzędnym będzie węzeł B, a dla F i G będzie to węzeł C. Węzeł nie posiadający rodzica nazywamy korzeniem drzewa binarnego (ang. root node). W naszym przykładzie korzeniem jest węzeł A. Każde drzewo binarne, które zawiera węzły posiada dokładnie jeden korzeń.
Odwzorowanie drzewa binarnegoJeśli chcemy przetwarzać za pomocą komputera struktury
drzew binarnych, to musimy zastanowić się nad sposobem reprezentacji
takich struktur w pamięci. Najprostszym rozwiązaniem jest
zastosowanie zwykłej tablicy n elementowej.
Każdy element tej tablicy będzie reprezentował jeden węzeł drzewa
binarnego. Pozostaje nam jedynie określenie związku pomiędzy
indeksami elementów w tablicy a położeniem tych elementów w
strukturze drzewa binarnego.
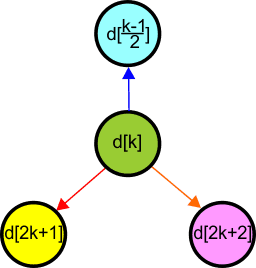
Zastosujmy następujące odwzorowanie:
Otrzymamy w ten sposób następujące odwzorowanie elementów tablicy w drzewo binarne:
Dla węzła k-tego wyprowadzamy następujące wzory:
Sprawdź, iż podane wzory są również spełnione w drzewach binarnych o większych rozmiarach niż prezentuje nasz przykład (pomocna może być kartka papieru).
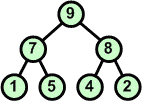
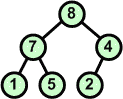
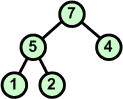
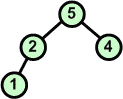
Przykład: Skonstruować drzewo binarne z elementów zbioru {7 5 9 2 4 6 1}
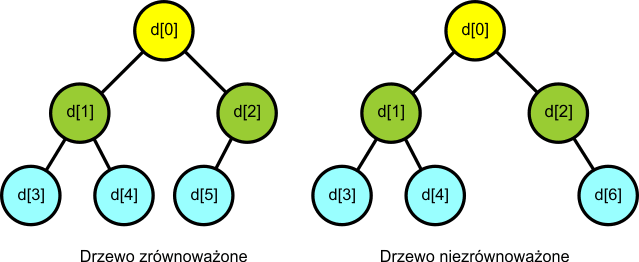
Zrównoważone drzewa binarneUmówmy się na potrzeby tego artykułu, iż binarne drzewo
jest
zrównoważone i uporządkowane, jeśli na
wszystkich poziomach za wyjątkiem ostatniego posiada maksymalną
liczbę węzłów, a na poziomie ostatnim węzły są ułożone kolejno od
lewej strony. Innymi słowy, jeśli ostatni węzeł drzewa binarnego
posiada numer i-ty, to drzewo zawiera
wszystkie węzły od numeru
1
do i.
Warunek ten gwarantuje nam, iż każdy element tablicy będzie reprezentował pewien węzeł w drzewie binarnym - czyli w tej strukturze nie wystąpią dziury.
Drzewo po lewej stronie nie posiada węzła d[6]. Ale posiada wszystkie węzły od d[0] do d[5], jest zatem zrównoważone i uporządkowane. Można je bez problemu przedstawić za pomocą tablicy elementów od d[0] do d[5]. Drzewo po prawej stronie nie posiada węzła d[5]. Takiego drzewa nie przedstawimy poprawnie za pomocą tablicy elementów od d[0] do d[6], ponieważ nie mamy możliwości zaznaczenia (bez dodatkowych zabiegów), iż element d[5] nie należy do struktury drzewa. Zatem nie będzie to uporządkowane i zrównoważone drzewo binarne. W uporządkowanych i zrównoważonych drzewach binarnych bardzo prosto można sprawdzić, czy k-ty węzeł jest liściem. Będzie tak, jeśli węzeł ten nie posiada węzłów potomnych. Zatem, jeśli drzewo binarne składa się z n węzłów, to wystarczy sprawdzić, czy 2k+1 > n-1. Jeśli tak, węzeł jest liściem. Jeśli nie, węzeł posiada potomka o indeksie 2k+1, zatem nie może być liściem.
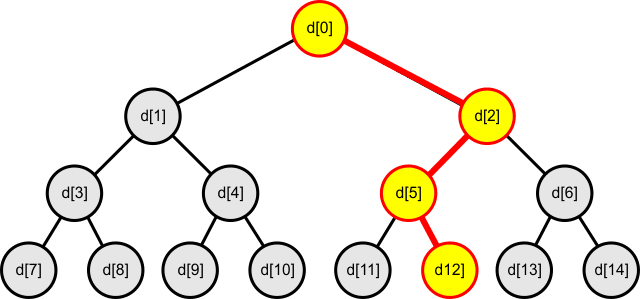
Ścieżki na drzewach binarnychŚcieżką nazwiemy ciąg węzłów
drzewa binarnego spełniających warunek, iż każdy węzeł poprzedni
jest rodzicem węzła następnego. Jeśli ścieżka składa się z
k węzłów, to długością ścieżki jest liczba
k - 1.
Na powyższym rysunku zaznaczona została ścieżka biegnąca poprzez węzły {d[0], d[2], d[5], d[12]}. Ścieżka ta zawiera cztery węzły, ma zatem długość równą 3. Wysokością drzewa binarnego nazwiemy długość najdłuższej ścieżki od korzenia do liścia. W powyższym przykładzie najdłuższa taka ścieżka ma długość 3, zatem zaprezentowane drzewo binarne ma wysokość równą 3. Dla n węzłów zrównoważone drzewo binarne ma wysokość równą:
h = [log2n]
Podsumowanie nowej terminologii
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
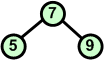
KopiecKopiec jest drzewem binarnym, w
którym wszystkie węzły spełniają następujący warunek
(zwany warunkiem kopca):
Węzeł nadrzędny jest większy lub równy węzłom potomnym (w porządku malejącym relacja jest odwrotna - mniejszy lub równy).
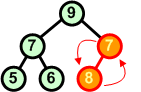
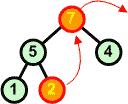
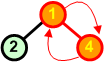
Konstrukcja kopca jest nieco bardziej skomplikowana od konstrukcji drzewa binarnego, ponieważ musimy dodatkowo troszczyć się o zachowanie warunku kopca. Zatem po każdym dołączeniu do kopca nowego węzła, sprawdzamy odpowiednie warunki i ewentualnie dokonujemy wymian węzłów na ścieżce wiodącej od dodanego węzła do korzenia.
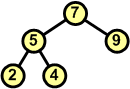
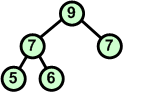
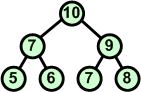
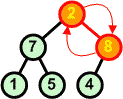
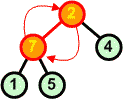
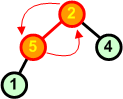
Przykład: Skonstruować kopiec z elementów zbioru {7 5 9 6 7 8 10}
Charakterystyczną cechą kopca jest to, iż korzeń zawsze jest największym (w porządku malejącym najmniejszym) elementem z całego drzewa binarnego.
AlgorytmPoniżej przedstawiamy algorytm konstrukcji kopca z elementów zbioru.
Specyfikacja problemuDane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków
Uwaga: przy porządku malejącym należy zmienić drugi warunek w kroku K04 z d[k] < x na d[k] > x. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
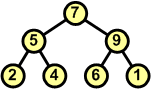
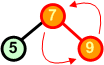
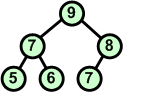
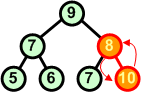
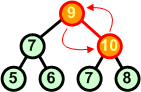
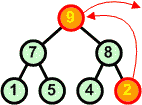
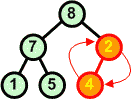
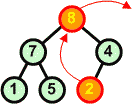
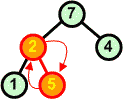
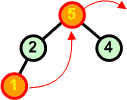
Rozbiór kopcaAlgorytmW tym rozdziale nauczymy się rozbierać kopiec. Zasada jest następująca:
Przykład: Dokonaj rozbioru następującego kopca:
Operację rozbioru kopca można przeprowadzić w miejscu. Jeśli mamy zbiór d[ ] ze strukturą kopca, to idąc od końca zbioru (ostatnie liście drzewa) w kierunku początku zamieniamy elementy z pierwszym elementem zbioru (korzeń drzewa), a następnie poruszając się od korzenia w dół przywracamy warunek kopca w kolejno napotykanych węzłach.
Specyfikacja problemuDane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sortowanie przez kopcowanieAlgorytmJeśli przeczytałeś uważnie poprzednie dwa rozdziały, to zasadę sortowania przez kopcowanie zrozumiesz od razu - w zbiorze tworzymy kopiec, a następnie dokonujemy jego rozbioru. W wyniku wykonania tych dwóch operacji zbiór zostanie posortowany.
Specyfikacja problemuDane wejściowe
Dane wyjściowe
Zmienne pomocnicze i funkcje
Lista kroków
Ponieważ sortowanie przez kopcowanie składa się z dwóch
następujących bezpośrednio po sobie operacji o klasie czasowej
złożoności obliczeniowej
O(n
log
n),
to dla całego algorytmu klasa złożoności również będzie wynosić
O(n
log
n).
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
AlgorytmAlgorytm sortowania szybkiego opiera się na strategii "dziel i zwyciężaj" (ang. divide and conquer), którą możemy krótko scharakteryzować w trzech punktach:
Idea sortowania szybkiego jest następująca:
Sortowanie szybkie zostało wynalezione przez angielskiego informatyka, profesora Tony'ego Hoare'a w latach 60-tych ubiegłego wieku. W przypadku typowym algorytm ten jest najszybszym algorytmem sortującym z klasy złożoności obliczeniowej O(n log n) - stąd pochodzi jego popularność w zastosowaniach. Musimy jednak pamiętać, iż w pewnych sytuacjach (zależnych od sposobu wyboru piwotu oraz niekorzystnego ułożenia danych wejściowych) klasa złożoności obliczeniowej tego algorytmu może się degradować do O(n2), co więcej, poziom wywołań rekurencyjnych może spowodować przepełnienie stosu i zablokowanie komputera. Z tych powodów algorytmu sortowania szybkiego nie można stosować bezmyślnie w każdej sytuacji tylko dlatego, iż jest uważany za jeden z najszybszych algorytmów sortujących - zawsze należy przeprowadzić analizę możliwych danych wejściowych właśnie pod kątem przypadku niekorzystnego - czasem lepszym rozwiązaniem może być zastosowanie wcześniej opisanego algorytmu sortowania przez kopcowanie, który nigdy nie degraduje się do klasy O(n2).
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tworzenie partycjiDo utworzenia partycji musimy ze zbioru wybrać jeden z
elementów, który nazwiemy piwotem. W lewej
partycji znajdą się wszystkie elementy niewiększe od piwotu, a w
prawej partycji umieścimy wszystkie elementy niemniejsze od piwotu.
Położenie elementów równych nie wpływa na proces sortowania, zatem
mogą one występować w obu partycjach. Również porządek elementów w
każdej z partycji nie jest ustalony. Jako piwot można wybierać element pierwszy, środkowy, ostatni, medianę lub losowy. Dla naszych potrzeb wybierzemy element środkowy:
Dzielenie na partycje polega na umieszczeniu dwóch wskaźników na początku zbioru - i oraz j. Wskaźnik i przebiega przez zbiór poszukując wartości mniejszych od piwotu. Po znalezieniu takiej wartości jest ona wymieniana z elementem na pozycji j. Po tej operacji wskaźnik j jest przesuwany na następną pozycję. Wskaźnik j zapamiętuje pozycję, na którą trafi następny element oraz na końcu wskazuje miejsce, gdzie znajdzie się piwot. W trakcie podziału piwot jest bezpiecznie przechowywany na ostatniej pozycji w zbiorze.
Przykład: Dla przykładu podzielimy na partycje zbiór: { 7 2 4 7 3 1 4 6 5 8 3 9 2 6 7 6 3 }
Po zakończeniu podziału na partycje wskaźnik j wyznacza pozycję piwotu. Lewa partycja zawiera elementy mniejsze od piwotu i rozciąga się od początku zbioru do pozycji j - 1. Prawa partycja zawiera elementy większe lub równe piwotowi i rozciąga się od pozycji j + 1 do końca zbioru. Operacja podziału na partycje ma liniową klasę złożoności obliczeniowej - O(n). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
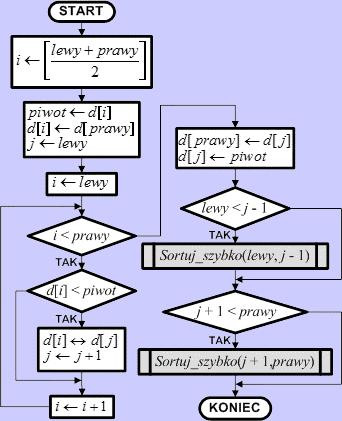
Specyfikacja problemuSortuj_szybko(lewy, prawy)Dane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków
Algorytm sortowania szybkiego wywołujemy podając za lewy indeks pierwszego elementu zbioru, a za prawy indeks elementu ostatniego (czyli Sortuj_szybko(0,n-1)). Zakres indeksów jest dowolny - dzięki temu ten sam algorytm może również sortować fragment zbioru, co wykorzystujemy przy sortowaniu wyliczonych partycji.
Schemat blokowy
Na element podziałowy wybieramy element leżący w środku dzielonej partycji. Wyliczamy jego pozycję i zapamiętujemy ją tymczasowo w zmiennej i. Robimy to po to, aby dwukrotnie nie wykonywać tych samych rachunków. Element d[i] zapamiętujemy w zmiennej piwot, a do d[i] zapisujemy ostatni element partycji. Dzięki tej operacji piwot został usunięty ze zbioru. Ustawiamy zmienną j na początek partycji. Zmienna ta zapamiętuje pozycję podziału partycji. W pętli sterowanej zmienną i przeglądamy kolejne elementy od pierwszego do przedostatniego (ostatni został umieszczony na pozycji piwotu, a piwot zapamiętany). Jeśli i-ty element jest mniejszy od piwotu, to trafia on na początek partycji - wymieniamy ze sobą elementy na pozycjach i-tej i j-tej. Po tej operacji przesuwamy punkt podziałowy partycji j. Po zakończeniu pętli element z pozycji j-tej przenosimy na koniec partycji, aby zwolnić miejsce dla piwotu, po czym wstawiamy tam piwot. Zmienna j wskazuje zatem wynikową pozycję piwotu. Pierwotna partycja została podzielona na dwie partycje:
Sprawdzamy, czy partycje te obejmują więcej niż jeden
element. Jeśli tak, to wywołujemy rekurencyjnie algorytm sortowania
szybkiego przekazując mu granice wyznaczonych partycji. Po powrocie
z wywołań rekurencyjnych partycja wyjściowa jest posortowana
rosnąco. Kończymy algorytm.
|
|
Opisany w tym rozdziale algorytm sortowania kubełkowego
pozwala sortować zbiory liczb całkowitych - najlepiej o dużej ilości
elementów, lecz o małym zakresie wartości. Zasada działania jest
następująca:
Przykład: Dla przykładu posortujemy opisaną wyżej metodą zbiór { 2 6 4 3 8 7 2 5 7 9 3 5 2 6 }. Najpierw określamy zakres wartości elementów (w tym celu możemy na przykład wyszukać w zbiorze element najmniejszy i największy). U nas zakres wynosi:
wmin = 2, wmax = 9
Potrzebujemy zatem:
wmax - wmin + 1 = 9 - 2 + 1 = 8 liczników.
Liczniki ponumerujemy zgodnie z wartościami, które będą zliczały:
[2] [3] [4] [5] [6] [7] [8] [9]
Na początku sortowania wszystkie liczniki mają stan zero:
[2:0] [3:0] [4:0] [5:0] [6:0] [7:0] [8:0] [9:0]
Teraz przeglądamy kolejne elementy zbioru zliczając ich wystąpienia w odpowiednich licznikach:
{ 2 6 4 3 8 7 2 5 7 9 3 5 2 6 } [2:3] [3:2] [4:1] [5:2] [6:2] [7:2] [8:1] [9:1]
Zapis [2:3] oznacza, iż licznik numer 2 zawiera liczbę 3, a to z kolei oznacza, iż liczba 2 pojawiła się w zbiorze 3 razy. Przeglądamy kolejne liczniki począwszy od licznika o najmniejszym numerze (w przypadku sortowania malejącego przeglądanie rozpoczynamy od licznika o największym numerze) i zapisujemy do zbioru wynikowego tyle razy numer licznika, ile wynosi jego zawartość:
[2:3] [3:2] [4:1] [5:2] [6:2] [7:2] [8:1] [9:1] { 2 2 2 3 3 4 5 5 6 6 7 7 8 9 }
Specyfikacja problemuDane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków
Algorytm ma klasę czasowej złożoności obliczeniowej O(m + n), gdzie m oznacza ilość możliwych wartości, które mogą przyjmować elementy zbioru, a n to ilość sortowanych elementów. Jeśli m jest małe w porównaniu z n (sortujemy dużo elementów o małym zakresie wartości), to na czas sortowania będzie miała wpływ głównie ilość elementów n i klasa złożoności uprości się do postaci O(n). Dzieje się tak dlatego, iż przy równomiernym rozkładzie dużej ilości elementów o małym zakresie wartości liczniki będą równomiernie zapełnione (stan każdego licznika będzie dążył do [n/m]). Zatem algorytm wykona:
W sytuacji odwrotnej, gdy sortujemy mało elementów o dużym zakresie wartości klasa złożoności zredukuje się z kolei do O(m) - spróbuj uzasadnić ten wynik samemu na podstawie analizy działania poszczególnych fragmentów algorytmu.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sortowanie przez zliczanie
|
| Wartość: | 0 | 0 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 3 | 4 | 4 | 4 | 5 | 5 | 5 | 6 | 6 | 6 | 6 | 7 | 7 | 7 | 8 | 8 | 8 | 8 | 9 | 9 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pozycja: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 |
Przeglądamy jeszcze raz zbiór wejściowy idąc od ostatniego elementu do pierwszego (aby zachować stabilność sortowania). Każdy element umieszczamy w zbiorze wynikowym na pozycji równej zawartości licznika dla tego elementu. Po wykonaniu tej operacji licznik zmniejszamy o 1. Dzięki temu następna taka wartość trafi na wcześniejszą pozycję.
W naszym przykładzie rozpoczynamy od ostatniej liczby 3. Jej licznik ma zawartość [3:14]. Zatem liczbę 3 umieszczamy w zbiorze wynikowym na pozycji 14 - 1 = 13 i zmniejszamy o 1 stan licznika otrzymując [3:13]. Kolejna liczba 3 trafi teraz na pozycję 12, itd.
Dla liczby 5 stan licznika wynosi [5:20]. Umieszczamy ją zatem na 20 - 1 = 19 pozycji i licznik zmniejszamy o 1 otrzymując [5:19].
Postępujemy w ten sam sposób z pozostałymi elementami zbioru. W efekcie zbiór wynikowy będzie posortowany rosnąco:
{ 0 0 1 1 1 2 2 2 2 3 3 3 3 3 4 4 4 5 5 5 6 6 6 6 7 7 7 8 8 8 8 9 9 9 }
Przyjrzawszy się dokładnie algorytmowi sortowania przez zliczanie możesz zastanawiać się, dlaczego postępujemy w tak dziwny sposób? Przecież mając zliczone wystąpienia każdej wartości w licznikach, możemy je od razu przepisać do zbioru wyjściowego, jak zrobiliśmy w algorytmie sortowania kubełkowego. Miałbyś rację, gdyby chodziło jedynie o posortowanie liczb. Jest jednak inaczej.
Celem nie jest posortowanie jedynie samych wartości elementów. Sortowane wartości są zwykle tzw. kluczami, czyli wartościami skojarzonymi z elementami, które wyliczono na podstawie pewnego kryterium Sortując klucze chcemy posortować zawierające je elementy. Dlatego do zbioru wynikowego musimy przepisać całe elementy ze zbioru wejściowego, gdyż w praktyce klucze stanowią jedynie część (raczej małą) danych zawartych w elementach. Zatem algorytm sortowania przez zliczanie wyznacza docelowe pozycje elementów na podstawie reprezentujących je kluczy, które mogą się wielokrotnie powtarzać. Następnie elementy są umieszczane na właściwym miejscu w zbiorze wyjściowym. Prześledź dokładnie podany poniżej algorytm oraz przykładowe programy, a wszystko powinno się wyjaśnić.
| d[ ] | - | zbiór elementów do posortowania. Każdy element posiada pole klucz, wg którego dokonuje się sortowania. Pole klucz jest liczbą całkowitą. Indeksy elementów rozpoczynają się od 0. |
| n | - | ilość elementów w zbiorze d[ ]. n
|
| kmin | - | minimalna wartość klucza, kmin
|
| kmax | - | maksymalna wartość klucza, kmax
|
| b[ ] | - zbiór z posortowanymi elementami ze zbioru d[ ]. Indeksy elementów rozpoczynają się od 0. |
| i | - | zmienna dla pętli iteracyjnych, i
|
| L[ ] | - | tablica liczników wartości kluczy. Elementy są liczbami całkowitymi. Indeksy przebiegają kolejne wartości od 0 do kmax - kmin . |
| K01: | Dla i = 0,1,...,kmax - kmin: wykonuj L[i] ← 0 |
| K02: | Dla i = 0,2,...,n - 1: wykonuj L[d[i].klucz - kmin] ← L[d[i].klucz - kmin] + 1 |
| K03: | Dla i = 1, 2,...,kmax - kmin: wykonuj L[i] ← L[i] + L[i - 1] |
| K04: | Dla i = n - 1, n - 2,...,0: wykonuj K05...K06 |
| K05: | b[ L[ d[i].klucz - kmin ] - 1] ← d[i] |
| K06: | L[ d[i].klucz - kmin ] ← L[ d[i].klucz - kmin ] - 1 |
| K07: | Zakończ |
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe