
Autor artykułu: mgr Jerzy Wałaszek
©2015 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2015 mgr
Jerzy Wałaszek
|
Pamięć komputera
Pamięć komputerowa (ang. computer memory)
jest urządzeniem cyfrowym służącym do przechowywania informacji w postaci
bitów. Dzielimy ją na:
Pamięć RAM (ang. Random Access Memory – pamięć o dostępie swobodnym) jest podstawowym składnikiem pamięci operacyjnej komputera. Termin RAM oznacza pamięć, z której informacja może być odczytywana w dowolnej kolejności bez względu na poprzednie odczyty czy zapisy. Termin RAM wprowadzono w celu odróżnienia pamięci o dostępie swobodnym od pamięci o dostępie sekwencyjnym (np. taśmowej, dyskowej itp.), popularnej na początku ery komputerowej. Informacja przechowywana jest w pamięci RAM w postaci bitów umieszczanych w komórkach (ang memory cell), których mogą być miliardy. Aby komputer mógł uzyskiwać w prosty sposób dostęp do każdej komórki pamięci, zostały one ponumerowane. Numery komórek nazywamy adresami komórek pamięci (ang. memory cell address). Poniżej przedstawiamy fragment logicznej struktury pamięci (czyli tak, jak widzi swoją pamięć komputer):
Ze względów ekonomicznych poszczególne komórki pamięci przechowują grupę kilku bitów (najczęściej jest ich 8 – czyli 1 bajt, ale rozmiar bitowy komórki pamięci zależy od architektury systemu komputerowego). Na przykład komórka o adresie 3 przechowuje 8 bitów o zawartości 11111110. Treść tej informacji uzależniona jest od interpretacji stanów bitów.
Komputer steruje pamięcią przy pomocy trzech magistral (ang. bus). Magistrale zbudowane są z linii, którymi transmituje się sygnały. We współczesnych komputerach magistrale są cyfrowe, co oznacza, iż poszczególne linie przesyłają tylko sygnały dwustanowe, czyli bity. Widać z tego wyraźnie, iż komputery są maszynami binarnymi nie tylko ze względu na rodzaj przetwarzanych informacji, lecz również z powodu swojej wewnętrznej budowy – mówimy, iż posiadają architekturę binarną (ang. binary architecture). Magistrala adresowa (ang. address bus) przekazuje pamięci adres komórki, do której komputer chce uzyskać dostęp – odczytać zawartość lub umieścić nowe dane. Ponieważ adres przekazywany jest magistralą cyfrową, to sam również występuje jako liczba binarna. Ilość linii na magistrali adresowej określa zakres dostępnych adresów, a zatem maksymalny rozmiar pamięci komputera. Do obliczeń stosujemy prosty wzór:
rozmiar pamięci = 2liczba linii na magistrali adresowej
Na przykład w starych komputerach magistrala adresowa mogła zawierać maksymalnie 16 linii. Zatem rozmiar możliwej do zaadresowania pamięci wynosił 216 = 65536 komórek (sławne 64KB – kilo bajty). Jeśli magistrala adresowa składa się z 32 linii, to komputer jest w stanie wykorzystać 232 = 4294967296 = 4GB pamięci (GB – gigabajt). Oczywiście w systemie może być mniej pamięci (np. tylko 1GB = 1073741824 komórek), w takim przypadku część adresów nie jest wykorzystywana, gdyż nie stoją za nimi żadne komórki. Ilość możliwych do zaadresowania komórek nosi nazwę przestrzeni adresowej (ang. address space). Natomiast pamięć fizyczna (ang. physical memory, physical storage) określa ilość pamięci rzeczywiście zainstalowanej w systemie komputerowym. Magistrala danych (ang. data bus) umożliwia komputerowi przekazywanie danych do pamięci oraz odczyt przechowywanych przez pamięć informacji z komórek. Magistrala danych zbudowana jest z linii sygnałowych, po których przekazywane są bity. Ilość linii na magistrali danych zależy od architektury komputera. Na przykład w systemach 32-bitowych magistrala danych zawiera 32 linie, co pozwala w jednym cyklu dostępu do pamięci przesłać porcję 32 bitów.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Zmienne w pamięciZmienne są obiektami przechowywanymi w pamięci komputera.
Posiadają zatem adresy. Adres zmiennej uzyskujemy za pomocą operatora adresu
&. Dodatkowo zmienne zajmują określoną liczbę komórek pamięci.
Rozmiar zmiennej podaje nam operator sizeof. Przekopiuj lub przepisz
poniższy program do edytora kodu w pakiecie Code::Blocks
(druga opcja jest bardziej wskazana, gdyż, pisząc, więcej zapamiętasz).
Uwagi: strumień cout traktuje adres zmiennej znakowej jako ciąg znaków. Musimy stosować jawne rzutowanie na typ np. void (spróbuj usunąć to rzutowanie i zobacz, co się stanie). Kolejna ciekawa rzecz, to sposób rozmieszczenia zmiennych w pamięci (otrzymane adresy zależą od komputera i kompilatora, na którym uruchomiono program):
Zmienne umieszczane są kolejno w kierunku końca pamięci – ostatnia zmienna h znajduje się pod najwyższym adresem. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
StrukturyStruktura definiuje złożony typ danych, który może w
sobie zawierać inne typy. Strukturę w języku C++ definiujemy
przed pierwszym użyciem w programie w sposób następujący:
struct nazwa
Nazwa struktury budowana jest wg tych samych zasad co nazwy zmiennych. Wewnątrz struktury definiujemy tzw. pola, które określają rodzaj danych przechowywanych przez strukturę. Nazwy pól również tworzymy wg zasad podanych dla nazw zmiennych. Po zdefiniowaniu struktury jej nazwa staje się nowym typem danych, który służy do tworzenia zmiennych o typie struktury. Na przykład, poniższa definicja tworzy nowy typ danych point_xy:
struct point_xy
{
double x,y;
};
Struktura typu point_xy zawiera dwa pola o nazwach x i y. W każdym z tych pól można przechowywać daną typu double, czyli np. współrzędną punktu. Na podstawie typu point_xy (który jest jakby planem budowy zmiennej) tworzymy nowe zmienne:
point_xy a,b;
W każdej z nich znajdują się dwa pola x i y. Dostęp do zawartości tych pól uzyskujemy za pomocą operatora kropki:
a.x = 1; // Do pola x zmiennej a trafi 1 a.y = 3.7; // Do pola y zmiennej a trafi 3,7 b.x = a.x + 2.2; // Do pola x zmiennej b trafi 3,2 b.y = b.x - a.y; // Do pola y zmiennej b trafi -0,5
Poniższy program oblicza odległość dwóch punktów na płaszczyźnie. Korzystamy ze wzoru:
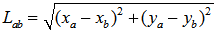
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Deklarowanie tablicTablica (ang. array) lub wektor (ang. vector) jest złożoną strukturą danych (ang. compound data structure) zbudowaną z ciągu elementów tego samego typu. W pamięci komputera elementy tablicy są ułożone kolejno jeden obok drugiego. Dostęp do elementu odbywa się poprzez numer zwany indeksem. Na podstawie indeksu, rozmiaru elementu oraz adresu początku tablicy komputer oblicza adres elementu i w ten sposób uzyskujemy do niego dostęp. We współczesnych językach programowania tablice są stosowane powszechnie do przechowywania danych podobnego rodzaju. Przy ich pomocy można zapisywać ciągi liczbowe, wyniki pomiarów różnych wielkości oraz tworzyć złożone bazy danych. Liczba zastosowań tablic jest w zasadzie ograniczona naszą wyobraźnią. Podstawową zaletą tablic jest prostota przetwarzania ich elementów. Dzięki dostępowi poprzez indeksy, elementy tablic daje się łatwo przetwarzać w pętlach iteracyjnych. Przed pierwszym użyciem każda tablica musi być zadeklarowana tak jak wszystkie zmienne używane w programie – tablica jest zmienną złożoną. Poniżej podajemy sposoby deklaracji tablicy w wybranych przez nas językach programowania:
Deklarację tablicy umieszczamy w języku C++ na liście deklaracji zmiennych. Składnia jest następująca:
typ_danych nazwa_tablicy[liczba_elementów];
Poniżej podajemy kilka przykładów deklaracji tablic w C++: ... int a[3]; // tablica zawierająca 3 elementy typu int double x[10]; // tablica przechowująca 10 liczb typu double char c[6]; // tablica przechowująca 6 wartości znakowych ... W języku C++ indeksy tablic rozpoczynają się od 0. Ma to sens, ponieważ nazwa tablicy jest traktowana zawsze jak adres początku obszaru pamięci, w którym tablica przechowuje swoje elementy. Naturalne zatem jest, iż pierwszy element leży właśnie pod adresem tablicy. Stąd jego indeks wynosi 0, czyli nic nie musimy dodawać do adresu początku tablicy, aby uzyskać dostęp do jej pierwszego elementu. W powyższym przykładzie zadeklarowano trzy tablice a, x oraz c. Posiadają one elementy o następujących indeksach:
Tablica a : a[0] a[1] a[2]
– 3 elementy typu integer
Tablica x : x[0] x[1] x[2] x[3] x[4] x[5] x[6] x[7] x[8] x[9] – 10 elementów typu double Tablica c : c[0] c[1] c[2] c[3] c[4] c[5] – 6 elementów typu char
Zwróć uwagę, iż tablica nie posiada elementu o indeksie równym ilości elementów. Zatem jeśli zadeklarujemy np. tablicę:
double Tlk[168];
to jej ostatnim elementem jest Tlk[167], a nie Tlk[168]. Odwołanie się w programie do Tlk[168] jest błędem, którego kompilator zwykle nie zgłosi, zakładając, iż programista wie co robi. Niestety, język C++ nie był tworzony z myślą o początkujących.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Inicjalizacja tablicCzęsto zdarza się, iż chcemy utworzyć tablicę z zadaną z góry zawartością (np. tablica zawierająca początkowe liczby pierwsze). Postępujemy wtedy w sposób następujący:
typ_elementów nazwa_tablicy[ ] = {lista_wartości_dla_kolejnych_elementów};
Zwróć uwagę, iż nie musimy podawać liczby elementów. Kompilator utworzy tyle elementów, ile podamy dla nich wartości na liście inicjalizacyjnej. Poniższy przykład tworzy tablicę 10 liczb całkowitych i wypełnia ją kolejnymi liczbami Fibonacciego.
... int fib[ ] = (0,1,1,2,3,5,8,13,21,34); ... |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
PrzykładElementami tablicy nie muszą być typy proste.
Poniższy przykład tworzy tablicę struktur i wypełnia ją
przykładowymi wartościami.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tablice dynamiczneZdarza się, iż w trakcie pisania programu nie wiemy, ile dokładnie elementów będzie zawierała używana w tym programie tablica. W takim przypadku problem tworzenia tablicy możemy rozwiązać na dwa sposoby:
W celu utworzenia w języku C++ tablicy dynamicznej, tworzymy zmienną wskaźnikową na typ danych, które mają być przechowywane w tablicy:
typ_elementów * nazwa_tablicy_dynamicznej;
Zmienna wskaźnikowa (ang. pointer variable) nie przechowuje danych tylko adres obszaru pamięci komputera, w którym te dane się znajdują. Deklarację zmiennej wskaźnikowej zawsze poprzedzamy znakiem gwiazdki. W poniższym przykładzie tworzymy trzy wskaźniki a, b i c do danych typu double (czyli do obszaru pamięci, w którym będą przechowywane liczby zmiennoprzecinkowe o podwójnej precyzji):
...
double * a, * b, * c; ... Pamięć rezerwujemy operatorem new i adres zarezerwowanego obszaru umieszczamy w zmiennej wskaźnikowej:
nazwa_tablicy_dynamicznej = new
typ_elementów[liczba_elementów];
Poniższy przykład tworzy trzy tablice dynamiczne, w których będzie można przechowywać odpowiednio 10, 100 i 1000 elementów typu double:
... a = new double[10]; // elementy od a[0] do a[9] b = new double[100]; // elementy od b[0] do b[99] c = new double[1000]; // elementy od c[0] do c[999] ... Po tej operacji do elementów tablic a, b i c odwołujemy się w zwykły sposób za pomocą indeksów. Istnieje również alternatywna metoda, wykorzystująca fakt, iż zmienne a, b i c są wskaźnikami. W języku C++ dodanie do wskaźnika liczby całkowitej powoduje obliczenie adresu elementu o indeksie równym dodawanej liczbie. Zatem wynik takiej operacji jest również wskaźnikiem:
W rzeczywistości zapis a[i] kompilator i tak przekształca sobie na zapis * (a + i). Forma tablicowa jest tylko uproszczeniem zapisu wskaźnikowego. Tablice dynamiczne nie są automatycznie usuwane z pamięci, jeśli utworzono je w funkcji. Dlatego po zakończeniu korzystania z tablicy program powinien zwolnić zajmowaną przez tablicę pamięć. Dokonujemy tego poleceniem delete w sposób następujący:
delete [ ] nazwa_tablicy_dynamicznej;
W poniższym przykładzie zwalniamy pamięć zarezerwowaną wcześniej na elementy tablic b i c.
... delete [ ] b; // usuwamy obszar wskazywany przez b delete [ ] c; // usuwamy obszar wskazywany przez c ... Należy również wspomnieć, iż Code::Blocks dopuszcza konstrukcję:
typ_elementów nazwa_tablicy[zmienna];
co pozwala na tworzenie statycznych tablic o liczbie elementów podanej w zmiennej. Na przykład poniższa konstrukcja programowa tworzy statyczną tablicę a o liczbie elementów odczytanej ze strumienia wejściowego konsoli znakowej:
... int n; cin >> n; double a[n]; ... Jednakże nie jest to zbyt standardowe rozwiązanie i może nie być przenośne na inne kompilatory C++, dlatego odradzam używania go – lepiej zastosować tablicę dynamiczną.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wprowadzanie/wyprowadzanie danychDane dla programu zwykle muszą być odczytywane ze zewnętrznego źródła – konsoli lub pliku. W takim przypadku nie wiemy z góry (tzn. w trakcie pisania programu) ile ich będzie. Narzucającym się rozwiązaniem jest zastosowanie tablic dynamicznych. Ze źródła danych odczytujemy rozmiar tablicy, tworzymy tablicę dynamiczną o odpowiednim rozmiarze, a następnie wczytujemy do jej komórek poszczególne dane. Poniżej podajemy sposoby odczytu zawartości tablicy z konsoli. Sposób ten jest bardzo ogólny. Wykorzystanie standardowego wejścia jako źródła danych daje nam kilka możliwości wprowadzania danych:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ProgramProgram z pierwszego wiersza odczytuje liczbę n
określającą ilość danych. Z następnych n wierszy
odczytywane są dane i umieszczane w tablicy dynamicznej. Odczytane dane
zostają następnie wyświetlone jedna obok drugiej. Wypróbuj z tym
programem podane powyżej trzy opcje dostarczania danych i wyprowadzania
wyników.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wypełnianie tablicyZdarza się, że algorytm musi wstępnie wypełnić tablicę określoną zawartością. Operację taką przeprowadza się w pętli iteracyjnej, której zmienna licznikowa przebiega przez wszystkie kolejne indeksy elementów. Następnie wykorzystuje się zmienną licznikową jako indeks elementu tablicy, w którym umieszczamy określoną zawartość. W poniższych przykładach zakładamy, iż w programie zadeklarowano tablicę T o 100 elementach typu integer. Indeksy elementów tablicy T są w zakresie od 0 do 99. Wypełnianie stałą zawartością x
Wypełnianie liczbami parzystymi począwszy od 2
Wypełnianie liczbami nieparzystymi począwszy od 1
Wypełnianie liczbami pseudolosowymi z przedziału <a,b>
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe










