
Autor artykułu: mgr Jerzy Wałaszek
©2014 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2014 mgr
Jerzy Wałaszek
|
|
Poczynając od tego rozdziału przechodzimy do opisu algorytmów szybkich, tzn. takich, które posiadają klasę czasowej złożoności obliczeniowej równą O(n log n) lub nawet lepszą. W informatyce zwykle obowiązuje zasada, iż prosty algorytm posiada dużą złożoność obliczeniową, natomiast algorytm zaawansowany posiada małą złożoność obliczeniową, ponieważ wykorzystuje on pewne własności, dzięki którym szybciej dochodzi do rozwiązania. Wiele dobrych algorytmów sortujących korzysta z rekurencji, która powstaje wtedy, gdy do rozwiązania problemu algorytm wykorzystuje samego siebie ze zmienionym zestawem danych. Przykład: Jako przykład może posłużyć rekurencyjne obliczanie silni. Silnię liczby
n
należącej do zbioru liczb naturalnych definiujemy następująco: n! = 1 × 2 × 3 × ... × (n - 1) × n Na przykład: 5! = 1
×
2
×
3
×
4
×
5 = 120 Specyfikacja algorytmu
Lista kroków
Przykładowy program w języku C++
Dzięki rekurencji funkcja wyliczająca wartość silni staje się niezwykle prosta. Najpierw sprawdzamy warunek zakończenia rekurencji, tzn. sytuację, gdy wynik dla otrzymanego zestawu danych jest oczywisty. W przypadku silni sytuacja taka wystąpi dla n < 2 - silnia ma wartość 1. Jeśli warunek zakończania rekurencji nie wystąpi, to wartość wyznaczamy za pomocą rekurencyjnego wywołania obliczania silni dla argumentu zmniejszonego o 1. Wynik tego wywołania mnożymy przez n i zwracamy jako wartość silni dla n.
Wynaleziony w 1945 roku przez Johna von Neumanna
algorytm
sortowania przez scalanie jest algorytmem
rekurencyjnym. Wykorzystuje zasadę dziel i zwyciężaj,
która polega na podziale zadania głównego na zadania mniejsze dotąd, aż
rozwiązanie stanie się oczywiste. Algorytm sortujący dzieli porządkowany zbiór
na kolejne połowy dopóki taki podział jest możliwy (tzn.
podzbiór zawiera co najmniej dwa elementy). Następnie uzyskane w ten
sposób części zbioru rekurencyjnie sortuje tym samym algorytmem. Posortowane
części łączy ze sobą za pomocą scalania, tak aby wynikowy zbiór był posortowany. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Scalanie zbiorów uporządkowanychPodstawową operacją algorytmu jest scalanie dwóch zbiorów uporządkowanych w jeden zbiór również uporządkowany. Operację scalania realizujemy wykorzystując pomocniczy zbiór, w którym będziemy tymczasowo odkładać scalane elementy dwóch zbiorów. Ogólna zasada jest następująca:
Przykład: Połączmy za pomocą opisanego algorytmu dwa uporządkowane zbiory: { 1 3 6 7 9 } z { 2 3 4 6 8 }
Z podanego przykładu możemy wyciągnąć wniosek, iż operacja scalania dwóch uporządkowanych zbiorów jest dosyć prosta. Diabeł jak zwykle tkwi w szczegółach.
Algorytm scalania dwóch zbiorówPrzed przystąpieniem do wyjaśniania sposobu łączenia dwóch zbiorów uporządkowanych w jeden zbiór również uporządkowany musimy zastanowić się nad sposobem reprezentacji danych. Przyjmijmy, iż elementy zbioru będą przechowywane w jednej tablicy, którą oznaczymy literką d. Każdy element w tej tablicy będzie posiadał swój numer, czyli indeks z zakresu od 0 do n-1. Kolejnym zagadnieniem jest sposób reprezentacji scalanych zbiorów. W przypadku algorytmu sortowania przez scalanie zawsze będą to dwie przyległe połówki zbioru, który został przez ten algorytm podzielony. Co więcej, wynik scalenia ma być umieszczony z powrotem w tym samym zbiorze.
Przykład: Prześledźmy prosty przykład. Mamy posortować zbiór o postaci: { 6 5 4 1 3 7 9 2 }
Ponieważ w opisywanym tutaj algorytmie sortującym scalane podzbiory są przyległymi do siebie częściami innego zbioru, zatem logiczne będzie użycie do ich definicji indeksów wybranych elementów tych podzbiorów:
Przez podzbiór młodszy rozumiemy podzbiór zawierający elementy o indeksach mniejszych niż indeksy elementów w podzbiorze starszym.
Indeks końcowego elementu młodszej połówki zbioru z łatwością wyliczamy - będzie on o 1 mniejszy od indeksu pierwszego elementu starszej połówki.
Przykład:
Specyfikacja algorytmu scalaniaScalaj(ip, is, ik)Dane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków algorytmu scalania
Schemat blokowy algorytmu scalania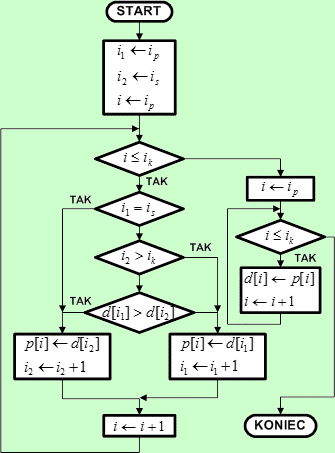
Operacja scalania dwóch podzbiorów wymaga dodatkowej pamięci o rozmiarze równym sumie rozmiarów scalanych podzbiorów. Dla prostoty na potrzeby naszego algorytmu zarezerwujemy tablicę p o rozmiarze równym rozmiarowi zbioru d[ ]. W tablicy p algorytm będzie tworzył zbiór tymczasowy, który po zakończeniu scalania zostanie przepisany do zbioru d[ ] w miejsce dwóch scalanych podzbiorów. Parametrami wejściowymi do algorytmu są indeksy ip, is oraz ik, które jednoznacznie definiują położenie dwóch podzbiorów do scalenia w obrębie tablicy d[ ]. Elementy tych podzbiorów będą indeksowane za pomocą zmiennych i1 (młodszy podzbiór od pozycji ip do is - 1) oraz i2 (starszy podzbiór od pozycji is do ik). Na początku algorytmu przypisujemy tym zmiennym indeksy pierwszych elementów w każdym podzbiorze. Zmienna i będzie zawierała indeksy elementów wstawianych do tablicy p[ ]. Dla ułatwienia indeksy te przebiegają wartości od ip do ik, co odpowiada obszarowi tablicy d[ ] zajętemu przez dwa scalane podzbiory. Na początku do zmiennej i wprowadzamy indeks pierwszego elementu w tym obszarze, czyli ip. Wewnątrz pętli sprawdzamy, czy indeksy i1 i i2 wskazują elementy podzbiorów. Jeśli któryś z nich wyszedł poza dopuszczalny zakres, to dany podzbiór jest wyczerpany - w takim przypadku do tablicy p przepisujemy elementy drugiego podzbioru. Jeśli żaden z podzbiorów nie jest wyczerpany, porównujemy kolejne elementy z tych podzbiorów wg indeksów i1 i i2. Do tablicy p[ ] zapisujemy zawsze mniejszy z porównywanych elementów. Zapewnia to uporządkowanie elementów w tworzonym zbiorze wynikowym. Po zapisie elementu w tablicy p[ ], odpowiedni indeks i1 lub i2 jest zwiększany o 1. Zwiększany jest również indeks i, aby kolejny zapisywany element w tablicy p[ ] trafił na następne wolne miejsce. Pętla jest kontynuowana aż do zapełnienia w tablicy p[ ] obszaru o indeksach od ip do ik. Wtedy przechodzimy do końcowej pętli, która przepisuje ten obszar z tablicy p[ ] do tablicy wynikowej d[ ]. Scalane zbiory zostają zapisane zbiorem wynikowym, który jest posortowany rosnąco. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Algorytm sortowania przez scalanieSortuj_przez_scalanie(ip, ik)Dane wejściowe
Dane wyjściowe
Zmienne pomocnicze
Lista kroków algorytmu sortującego
Schemat blokowy algorytmu sortującego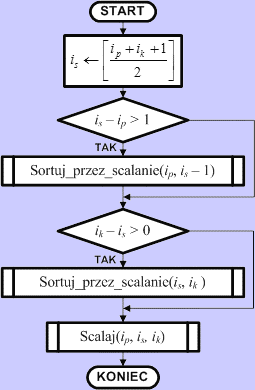 Algorytm sortowania przez scalanie jest algorytmem rekurencyjnym. Wywołuje się go z zadanymi wartościami indeksów ip oraz ik. Przy pierwszym wywołaniu indeksy te powinny objąć cały zbiór d, zatem ip = 0, a ik = n-1. Najpierw algorytm wyznacza indeks is, który wykorzystywany jest do podziału zbioru na dwie połówki: - młodszą o indeksach elementów od ip
do
is - 1 Następnie sprawdzamy, czy dana połówka zbioru zawiera więcej niż jeden element. Jeśli tak, to rekurencyjnie sortujemy ją tym samym algorytmem. Po posortowaniu obu połówek zbioru scalamy je za pomocą opisanej wcześniej procedury scalania podzbiorów uporządkowanych i kończymy algorytm. Zbiór jest posortowany. W przykładowych programach procedurę scalania umieściliśmy bezpośrednio w kodzie algorytmu sortującego, aby zaoszczędzić na wywoływaniu.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe
