Autor artykułu: mgr Jerzy Wałaszek
©2015 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2015 mgr
Jerzy Wałaszek
|
|
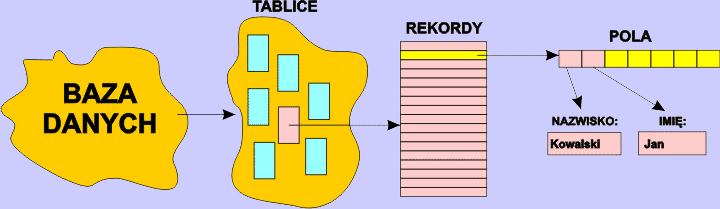
Baza danych (ang. data base) jest aplikacją, która służy do gromadzenia i przetwarzania informacji. W bazie danych informację przechowujemy w tabelach. Tabele zbudowane są z rekordów, które obejmują grupę powiązanych ze sobą informacji (np. dane osobowe, parametry produktu, itp.). Każdy rekord składa się z pól, w których umieszczamy pojedyncze informacje (np. imię, nazwisko, adres, wiek, telefon, itp.).
Tabele te łączy się ze sobą za pomocą relacji, czyli związków logicznych. Chodzi tutaj głównie o unikanie wielokrotnego umieszczania tych samych danych. Jeśli informacja musi się powtarzać, to istnieje ryzyko popełnienia błędów (np. literówek) przy jej wielokrotnym wprowadzaniu. Później są duże kłopoty przy wyszukiwaniu danych, ponieważ rekordy zawierające błędy mogą być pomijane. Jeśli dane są umieszczane tylko raz, zajmują mniej cennej pamięci. Jak to działa? Załóżmy, że tworzymy bazę danych klientów pewnej firmy. W bazie danych musimy przechowywać:
Imię i nazwisko klienta, numer telefonu, miasto, wykonywany zawód.
Załóżmy, że umieścimy te dane w jednej tabeli:
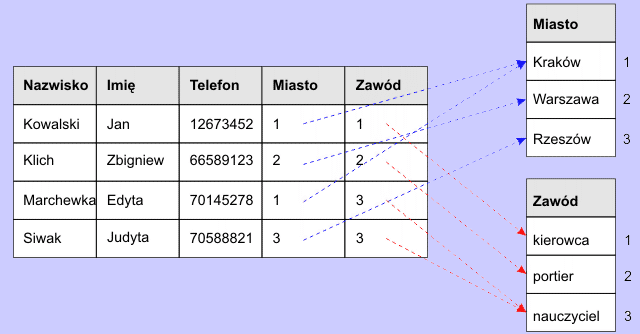
Zwróć uwagę, że pola Miasto oraz Zawód mogą się powtarzać (imiona też). Umieszczenie tych danych w jednej tabeli powoduje wzrost objętości bazy danych oraz zwiększa możliwość popełnienia pomyłki przy ich wprowadzaniu (Kraków → Krakow → kraków → krakow itp.). Dane powtarzające się umieśćmy w osobnych tabelach i połączmy je relacjami:
W pierwszej tabeli pole Miasto kojarzymy z tabelą miasto, a pole Zawód z tabelą Zawód. W polach tych przechowujemy numery rekordów z odpowiednich tabel. Np. w polu Miasto liczba 1 odnosi się do pierwszego rekordu tabeli Miasto, w którym jest zapisana informacja: Kraków. Wiele rekordów z pierwszej tabeli może się odwoływać do jednego rekordu z tabel Miasto i Zawód - informacja nie jest powtarzana. Rozmiar bazy danych zmniejszył się. Ponieważ informację wprowadzamy tylko raz, to zmniejszamy możliwość popełnienia pomyłek. Co więcej, rozbudowując bazę danych, tabele te możemy skojarzyć z innymi tabelami, tworząc całą sieć relacji.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ĆwiczeniePod kierunkiem
nauczyciela utwórz bazę danych, która będzie zawierała dane różnych krajów
świata. Dla każdego kraju w bazie danych powinna się znaleźć informacja:
Zastanów się, które z tych danych są wspólne dla wielu krajów. Wspólne dane umieszczamy w osobnych tabelach i tworzymy odpowiednie relacje.
Przykładowe dane do ćwiczenia:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Zadanie maturalneNoworodkiPliki noworodki.txt oraz mamy.txt zawierają dane o dzieciach i ich matkach. W pliku noworodki.txt każdy wiersz zawiera następujące informacje o jednym dziecku, rozdzielone znakami odstępu: identyfikator, płeć (c – córka, s – syn), imię, data urodzenia, waga [g], wzrost [cm] oraz identyfikator matki. Przykład:
1 c Agnieszka 20-lis-1999 2450 48 33
W pliku mamy.txt każdy wiersz zawiera informacje o jednej kobiecie, rozdzielone znakami odstępu: identyfikator matki, imię, wiek. Przykład:
1 Agata 25
Identyfikator matki z pliku noworodki.txt odpowiada identyfikatorowi w pliku mamy.txt. Wykorzystując dane zawarte w plikach mamy.txt i noworodki.txt oraz dostępne narzędzia informatyczne, wykonaj poniższe polecenia.
|
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe