
Autor artykułu: mgr Jerzy Wałaszek
©2014 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2014 mgr
Jerzy Wałaszek
|
Poznaliśmy dotychczas dwa typy danych liczbowych w języku C++:
int – liczby 32 bitowe ze znakiem o zakresie około ± 2 mld.
unsigned – liczby 32 bitowe bez znaku o zakresie od 0 do około 4 mld.
Oba powyższe typy pozwalają stosować jedynie liczby całkowite. Tymczasem w obliczeniach naukowych musimy operować wartościami niecałkowitymi. Dlatego język C++ został wyposażony w nowy typ danych – liczby rzeczywiste. Zanim do nich przejdziemy, zapoznajmy się ze sposobami zapisu liczb rzeczywistych w komputerze. Odpowiedzmy sobie na proste pytanie – czy wykorzystując tylko liczby całkowite, można zapisywać również liczby ułamkowe? Na fizyce zapewne spotkałeś się wielokrotnie z zapisem bardzo dużych lub bardzo małych wartości. Robiono to na przykład tak:
2,5 × 1036
lub tak:
3,3 × 10-31
Ogólnie możemy to zapisać następująco:
W = m × pc
gdzie:
W – wartość liczby
m – mantysa
p – podstawa
c – cecha
Podstawa p jest zwykle stała, w systemie dziesiętnym wynosi 10. Zatem nie musimy jej zapamiętywać – po prostu wiemy, że wynosi 10. Pozostają do zapamiętania dwie pozostałe liczby: m – mantysa i c – cecha. Znając je możemy obliczyć wartość liczby W. Zwróć uwagę, że daną wartość W otrzymasz dla wielu zestawów m i c.
Przykłady:
c = 1
m = 3
W = 3 × 101 = 3 × 10 = 30
c = 0
m = 30
W = 30 × 100 = 30 × 1 = 30
c = 2
m = 0,3
W = 0,3 × 102 = 0,3 × 100 = 30
Jeśli naszą liczbę zapiszemy w postaci pary liczb (c,m), to następujące pary odpowiadają tej samej wartości W: (3,1) (30,0) (0,3 2). Cecha jest zawsze liczbą całkowitą, a te już znamy. Mantysa jest liczbą ułamkową. Aby standaryzować zapis, możemy się umówić, że mantysa jest ZAWSZE ułamkiem właściwym o mianowniku np. 1000. Skoro tak, to licznik tego ułamka jest liczbą całkowitą od -999 do 999. Skoro mianownik jest ustalony, to nie musimy go zapamiętywać – wystarczy nam licznik, aby odtworzyć wartość mantysy.
Przykład:
Niech m oznacza u nas licznik mantysy, mianownik mantysy ma stałą wartość 1000 (bo tak się umawiamy).
c = 2
m = 3
W = 3/1000 × 102 = 3/1000
× 100 = 3/10 = 0,3 – liczba ułamkowa dla pary
(2,3).
Pomimo iż pamiętamy jedynie liczby całkowite, wartość reprezentowanej przez nie liczby jest ułamkowa. Zatem liczby rzeczywiste możemy zapamiętywać w postaci pary dwóch liczb całkowitych – cechy oraz licznika mantysy. Tak właśnie komputer zapamiętuje liczby rzeczywiste – w postaci dwóch liczb całkowitych, które wspólnie razem tworzą tzw. kod zmiennoprzecinkowy (ang floating point code). Komputer pracuje w systemie dwójkowym, zatem mantysa jest ułamkiem binarnym – mianownik jest zawsze potęgą liczby 2 (w systemie praktycznym jest to dosyć duża potęga, np. 253). Komputer w kodzie zmiennoprzecinkowym zapamiętuje jedynie licznik tego ułamka. Podstawa p wynosi 2. Znając mianownik ułamka mantysy 2x oraz jego licznik m i cechę c możemy wyliczyć wartość dowolnej liczby zmiennoprzecinkowej:
W = m / 2x × 2c
m – licznik mantysy, liczba całkowita
2x – mianownik mantysy, stała wartość, nie pamiętana w
kodzie zmiennoprzecinkowym
c – cecha
Przykład:
Niech mianownik ułamka mantysy wynosi 16 (24). Zatem licznik może przybierać wartości od -16 do 15. Obliczmy wartości kilku binarnych liczb zmiennoprzecinkowych:
c = 2
m = 1
W = 1 / 24 × 22 = 1 / 22 =
1/4
= 0,25
c = -3
m = 5
W = 5 / 24 × 2-3 = 5 / 24 × 1 / 23
= 5 / 27 = 5/128
c = 1
m = 12
W = 12 / 24 × 21 = 12 / 23 =
12/8
= 1 4/8 = 1 1/2 = 1,5
Widzimy, że obliczenia nie są skomplikowane. Wyznaczenie licznika mantysy m i cechy c jest równie proste. Wykorzystujemy tu proste przekształcenia matematyczne w celu sprowadzenia mantysy do ułamka właściwego. Obliczmy przykładowo m i c dla liczby 2,5.
Najpierw zapisujemy liczbę 2,5 w postaci ułamka o mianowniku 16:
2,5 = 5/2 = 40/16
Teraz zapisujemy mantysę i cechę wstępną równą 0:
3,5 = 40/16 × 20
Mantysę musimy sprowadzić do ułamka właściwego. Zatem licznik dzielimy przez 2, a do cechy dodajemy 1. Operację tę kontynuujemy do momentu, aż mantysa stanie się ułamkiem właściwym:
40/16 × 20 = 20/16 × 21 = 10/16 × 22.
Dostaliśmy:
c = 2 i m = 10.
Pewnych liczb nie da się dokładnie przedstawić w tym systemie. Spróbujmy zapisać liczbę 17 przy założeniu, że mantysa jest ułamkiem właściwym o mianowniku 16.
17 = 272/16 × 20 = 136/16 × 21 = 68/16 × 22 = 34/16 × 23 = 17/16 × 24 = 8/16 × 25
W ostatnim działaniu przyjęliśmy 8 jako wynik dzielenia 17 przez 2, ponieważ licznik ułamka musi być liczbą całkowitą. To zaokrąglenie spowodowało, że pierwotna liczba 17 zostaje sprowadzona do liczby:
c = 5
m = 8
W = 8/24 × 25 = 8 × 21 = 8 × 2 =
16!
Wniosek – jeśli mantysa jest ułamkiem o mianowniku 16, to liczby 17 nie da się przedstawić dokładnie. Gdyby mantysa była ułamkiem o mianowniku większym, np. 32, problem ten nie wystąpiłby dla liczby 17, ale pojawiłby się z kolei dla liczby 33. Zatem jest to stała cecha tego zapisu.
W rzeczywistym systemie mantysa jest ułamkiem o mianowniku bardzo dużym, np. 256. Pozwala to zapisywać liczby z dużą dokładnością. Ale błędy zaokrągleń dają czasami znać o sobie, co zobaczymy w dalszych przykładach. Więcej informacji na ten temat znajdziesz w artykule o binarnym kodowaniu liczb.
W języku C++ stosowane są trzy typy danych zmiennoprzecinkowych. Różnią się one tzw. precyzją, czyli dokładnością zapisu liczb. Wiąże się to z ilością bitów, które w kodzie zmiennoprzecinkowym są przeznaczone na zapis licznika mantysy. Im więcej bitów, tym ułamek mantysy może dokładniej reprezentować w zapisie zmiennoprzecinkowym daną wartość. Typy zmiennoprzecinkowe są następujące:
float – dane zmiennoprzecinkowe 32 bitowe, pojedynczej precyzji. Dokładność 7-8 cyfr znaczących.
double – dane zmiennoprzecinkowe 64 bitowe podwójnej precyzji. Dokładność 15 cyfr znaczących.
long double – dane zmiennoprzecinkowe 80 bitowe o rozszerzonej precyzji. Dokładność 20 cyfr znaczących.
Typ float jest najmniej dokładnym typem danych rzeczywistych. Jedyną jego zaletą jest mały rozmiar – 32 bity. Ogólnie dzisiaj nie zaleca się jego stosowania.
Typ double jest standardowym typem rzeczywistym. Jeśli nie będą istniały specjalne powody, to będziemy stosować w programach tylko typ double.
Typ long double jest typem danych, które wewnętrznie wykorzystuje koprocesor arytmetyczny – jest to część procesora Pentium, która wykonuje operacje zmiennoprzecinkowe. Typ ten pozwala zminimalizować błędy zaokrągleń i zachować dużą precyzję obliczeń. Jednakże nie będziemy z niego korzystać, ponieważ może nie być dostępny na innych platformach sprzętowych – koprocesory mają różne standardy w różnych systemach.
// Obliczanie pola i obwodu prostokąta
// (C)2014 I LO w Tarnowie
//------------------------
#include <iostream>
using namespace std;
int main()
{
double a,b,pole,obwod;
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
pole = a * b;
obwod = 2 * (a + b);
cout << endl
<< "Obwód = " << obwod << endl
<< "Pole = " << pole << endl;
return 0;
}
|
Powyższy program, chociaż działa doskonale posiada kilka wad z punktu widzenia użytkownika. Uruchom go i wprowadź poniższe dane:
| a = 2.3 b = 4.12 Obwod = 12.84 Pole = 9.476 |
Zwróć uwagę, że wynik nie jest odpowiednio wyrównany. Kropki dziesiętne znajdują się w różnych kolumnach. Liczba miejsc po przecinku jest różna. A teraz wpisz takie dane:
| a = 33212356 b = 98777878 Obwod = 2.6398e+008 Pole = 3.28065e+015 |
Ponieważ wynik jest dużą liczbą, to komputer przedstawia go w postaci naukowej
| Obwód | = 2,6398 × 108 |
| Pole | = 3.28065× 1015 |
Aby mieć pełną kontrolę nad sposobem prezentacji liczb zmiennoprzecinkowych przez konsolę, musimy użyć tzw. manipulatorów strumienia. W tym celu należy do programu dołączyć plik nagłówkowy iomanip, który zawiera definicję tych manipulatorów. Manipulatory przesyłamy do strumienia jak zwykłe dane. W poniższej tabelce zebraliśmy podstawowe manipulatory strumienia cout.
| Manipulator | Opis |
|---|---|
endl |
Przenosi wydruk na początek nowego wiersza. |
setw(n) |
Ustawia szerokość wydruku liczby. Jeśli liczba posiada mniej cyfr niż
wynosi n, to reszta pola jest wypełniana spacjami. Manipulator setw(n)
działa jedynie na następną liczbę przesłaną do strumienia. Kolejne dane
nie będą nim już objęte. Cyfry liczby standardowo dosuwane są do prawej
krawędzi pola wydruku.cout << setw(6) << a << endl; |
left |
Umieszcza cyfry liczby po lewej stronie pola wydruku. Stosuje się
tylko po manipulatorze setw(n).
|
right |
Umieszcza cyfry liczby po prawej stronie pola wydruku. Manipulator jest ustawiony standardowo, zatem jego użycie ma sens tylko do anulowania manipulatora left. Stosuje się tylko po manipulatorze setw(n). |
setfill(ch) |
Manipulator używany tylko po setw(n). Ustawia on znak,
którym zostanie wypełnione puste miejsce w polu wydruku liczby – jeśli
liczba posiada mniej cyfr niż wynosi szerokość pola, to puste miejsca są
zwykle wypełniane spacjami. Manipulator setfill() pozwala zmienić spacje
na inny znak. Poniższy przykład formatuje wydruk liczb całkowitych na 6
cyfr z wiodącymi zerami, np. zamiast 173 otrzymamy 000173:cout << setw(6) << setfill('0') << a << endl;
|
setprecision(n) |
Manipulator ustawia liczbę cyfr po przecinku przy wydruku liczb zmiennoprzecinkowych. Stosuje się do wszystkich liczb zmiennoprzecinkowych, które po manipulatorze trafią do strumienia wyjściowego. |
fixed |
Manipulator powoduje, iż kolejne liczby zmiennoprzecinkowe będą
wyświetlane ze stałą liczbą cyfr po przecinku. Liczbę cyfr ustala
manipulator setprecision(). Jeśli nie był wcześniej zastosowany, to
standardowo otrzymamy 6 cyfr po przecinku:
|
scientific |
Po zastosowaniu tego manipulatora liczby zmiennoprzecinkowe będą
wyświetlane w postaci naukowej:
1.56E-2 odpowiada liczbie 1.56 × 10-2 = 1,56 × 0,01 = 0,0156 |
Nasz program po zastosowaniu manipulatorów wygląda następująco:
// Obliczanie pola i obwodu prostokąta
// (C)2014 I LO w Tarnowie
//------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
double a,b,pole,obwod;
// ustawiamy stałoprzecinkowe wyświetlanie liczb rzeczywistych
// z czterema cyframi po przecinku
cout << fixed << setprecision(4);
cout << "a = "; cin >> a;
cout << "b = "; cin >> b;
pole = a * b;
obwod = 2 * (a + b);
cout << endl
<< "Obwód = " << setw(12) << obwod << endl
<< "Pole = " << setw(12) << pole << endl;
return 0;
}
|
Liczby zmiennoprzecinkowe są liczbami przybliżonymi. Typ double pozwala reprezentować dokładnie tylko 15 cyfr znaczących. Jeśli liczba ma ich więcej, to tylko 15 pierwszych cyfr będzie dokładne. Pozostałe już nie.
// Precyzja liczby zmiennoprzecinkowej
// (C)2014 I LO w Tarnowie
//------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
double x;
cout << fixed;
x = 12345678901234567890.0; // x ma dwadzieścia cyfr
cout << x << endl;
return 0;
}
|
// Precyzja liczby zmiennoprzecinkowej
// (C)2014 I LO w Tarnowie
//------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
double x;
cout << fixed << setprecision(20);
x = 0.1234567890123456789; // x ma dwadzieścia cyfr
cout << x << endl;
return 0;
}
|
Niektóre liczby nie będą nigdy reprezentowane dokładnie, chociaż posiadają mniej niż 15 cyfr znaczących. Typowym przykładem jest ułamek 0,1. Ponieważ mantysa liczby zmiennoprzecinkowej jest ułamkiem dwójkowym (mianownik tego ułamka jest potęgą liczby 2), to wartości 0,1 nie da się nigdy przedstawić dokładnie, zawsze będzie istniał pewien błąd.
Poniższe ułamki dwójkowe są prawie równe 0,1. Ale "prawie" nie oznacza wcale, że są równe:
1/8, 1/16, 3/32, 6/64, 12/128, 25/256, 102/1024, 6553/65535 ...
Ułamek dziesiętny 0,1 posiada w systemie dwójkowym nieskończone rozwinięcie. W naszym systemie dziesiętnym podobną własność mają ułamki 1/3, 1/6, 1/7, 1/9 – ułamków tych nie da się przedstawić dokładnie za pomocą skończonej ilości cyfr w systemie dziesiętnym. Tak samo w systemie dwójkowym, ułamka 1/10 nie da się przedstawić dokładnie za pomocą mantysy o skończonej liczbie bitów. Konsekwencje tego faktu prezentuje poniższy prosty program:
// Niedokładny ułamek 1/10
// (C)2014 I LO w Tarnowie
//------------------------
#include <iostream>
using namespace std;
int main()
{
double x;
x = 0.1;
x += 0.1; // 0,2
x += 0.1; // 0,3
x += 0.1; // 0,4
x += 0.1; // 0,5
x += 0.1; // 0,6
x += 0.1; // 0,7
x += 0.1; // 0,8
x += 0.1; // 0,9
x += 0.1; // 1
cout << "x = " << x << endl;
if(x == 1) cout << "Dobrze!";
else cout << "Źle!!!";
cout << endl;
return 0;
}
|
Program dodaje do zmiennej x ułamek 0,1. Po wykonaniu 9 takich dodawań x powinno osiągnąć wartość 1 i na ekranie powinien pojawić się tekst Dobrze!. Tymczasem po uruchomieniu programu pojawia się ten drugi tekst, pomimo że program wyświetla wartość x jako 1. Powodem jest to, iż po wykonaniu 9 dodawań 0,1 w zmiennej x nie była dokładnie wartość 1, tylko wartość bardzo zbliżona do 1. Niestety, operator == traktuje ją jako różną od 1.
Z programu powyższego wynika BARDZO WAŻNY wniosek – liczb zmiennoprzecinkowych NIE WOLNO przyrównywać do wartości dokładnych. Zamiast sprawdzania, czy dwie liczby zmiennoprzecinkowe a i b są równe:
a == b
powinniśmy zbadać ich różnicę. Jeśli ta różnica jest dostatecznie mała, to przyjmiemy, że liczby a i b są równe. Różnica może być dodatnia lub ujemna. Aby nie rozważać zatem dwóch różnych przypadków, będziemy badać wartość bezwzględną różnicy:
| a - b | < wartość graniczna
Wartość bezwzględna liczby zmiennoprzecinkowej oblicza funkcja fabs(x). Dostęp do tej funkcji uzyskamy po dołączeniu do programu pliku nagłówkowego cmath. Za wartość graniczną przyjmiemy 0.0000001. W tym celu w programie zdefiniujemy stałą EPS o takiej właśnie wartości. W pętli while mamy warunek x różne od 1. Otrzymamy go następująco:
fabs(x - 1) > EPS
A oto zmodyfikowany program, który teraz działa wg oczekiwań:
// Niedokładny ułamek 1/10
// (C)2014 I LO w Tarnowie
//------------------------
#include <iostream>
#include <cmath>
using namespace std;
const double EPS = 0.0000001;
int main()
{
double x;
x = 0.1;
x += 0.1; // 0,2
x += 0.1; // 0,3
x += 0.1; // 0,4
x += 0.1; // 0,5
x += 0.1; // 0,6
x += 0.1; // 0,7
x += 0.1; // 0,8
x += 0.1; // 0,9
x += 0.1; // 1
cout << "x = " << x << endl;
if(fabs(x - 1) < EPS) cout << "Dobrze!";
else cout << "Źle!!!";
cout << endl;
return 0;
}
|
Na liczby zmiennoprzecinkowe trzeba bardzo uważać w programowaniu. Musimy pamiętać, że są to wartości przybliżone. Błąd w stosunku do wartości dokładnej jest zwykle bardzo mały, ale może powodować błędne działanie programu, jeśli nie weźmiemy tego faktu pod uwagę. Następny program znajduje pierwiastki równania kwadratowego:
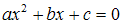
Algorytm znajdowania pierwiastków jest następujący:
Obliczamy wyróżnik równania:
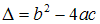
W zależności od wartości wyróżnika mamy trzy przypadki:

Istnieje pierwiastek podwójny, który obliczamy ze wzoru:


Istnieją dwa różne pierwiastki, które obliczamy ze wzorów:
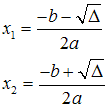
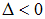
Nie ma pierwiastków rzeczywistych.
Algorytm wymaga obliczania pierwiastka kwadratowego, który udostępni nam funkcja sqrt(x), dostępna po dołączeniu pliku nagłówkowego cmath.
// Równanie kwadratowe
// (C)2013 I LO w Tarnowie
//------------------------
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
const double EPS = 0.0000001;
int main()
{
double a,b,c,delta,x1,x2;
cout << fixed << setprecision(4);
cout << "Rozwiązywanie równania kwadratowego\n"
"-----------------------------------\n\n"
" 2\n"
" ax + bx + c = 0\n\n";
cout << " a = "; cin >> a;
cout << " b = "; cin >> b;
cout << " c = "; cin >> c;
cout << endl;
delta = b*b - 4*a*c;
if(fabs(delta) < EPS)
{
cout << " Jeden pierwiastek podwójny:\n\n";
x1 = -b / 2 / a;
cout << " x = " << x1 << endl;
}
else if(delta > 0)
{
cout << " Dwa różne pierwiastki:\n\n";
x1 = (-b - sqrt(delta)) / 2 / a;
x2 = (-b + sqrt(delta)) / 2 / a;
cout << " x1 = " << setw(14) << x1 << endl
<< " x2 = " << setw(14) << x2 << endl << endl;
}
else cout << " Brak pierwiastków rzeczywistych\n\n";
return 0;
}
|
Program sprawdź dla trzech poniższych równań kwadratowych:
x2 - 2x + 1 = 0,
pierwiastek podwójny x1 = x2 = 1
x2 - 3x + 2 = 0, dwa pierwiastki
różne:
x1 = 1, x2 = 2
x2 + x + 1 = 0, brak
pierwiastków.
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe