
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2013 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2013 mgr
Jerzy Wałaszek
|

Zajęcia na kole informatycznym oprzemy na pakiecie Borland C++ Builder 6.0 Personal Edition. Nie jest to nowe narzędzie, lecz posiada istotną zaletę – jest darmowe, można je legalnie pobrać z sieci oraz zarejestrować w firmie Borland. Do nauki programowania jest idealne. Posiada wbudowaną pomoc kontekstową w języku angielskim.
Przy instalacji środowiska Borland C++ Builder potrzebujesz numeru seryjnego i klucza autoryzacji:
Po instalacji możesz zarejestrować produkt w firmie Borland. W tym celu musisz założyć sobie konto. Nie jest to skomplikowane i można tego dokonać wprost z programu instalacyjnego. Po rejestracji, która jest darmowa, staniesz się legalnym użytkownikiem pakietu. Jeśli nie zarejestrujesz pakietu, to wciąż będziesz mógł korzystać ze wszystkich jego funkcji.
W systemach Windows 7/8 pakiet Borland C++ Builder należy uruchamiać z
uprawnieniami administratora.
W systemie Windows XP program działa poprawnie na koncie z uprawnieniami
administratora.
Po uruchomieniu środowiska Borland C++ Builder problem powinien zniknąć.
Programy normalnie utworzone w środowisku Borland C++ Builder wykorzystują biblioteki DLL, które to środowisko zainstalowało w systemie. Zaletą takiego rozwiązania jest dosyć krótki kod programu - kilkadziesiąt kilobajtów. Niestety, jeśli zechcesz przesłać komuś gotowy program, a ten ktoś nie będzie miał zainstalowanego środowiska Borland C++ Builder, to program po prostu się nie uruchomi, zgłaszając przy starcie brak bibliotek DLL. Na szczęście istnieje proste rozwiązanie tego problemu:
Zapisz i przekompiluj swój projekt. Objętość programu wzrośnie do kilkuset kilobajtów, jednakże teraz program wszystko będzie zawierał w sobie i nie wystąpi już brak bibliotek DLL przy jego uruchomieniu na innym komputerze.
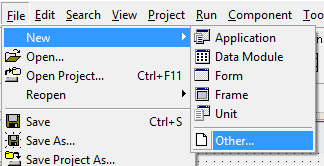
Z menu wybierz opcję File – New – Other...
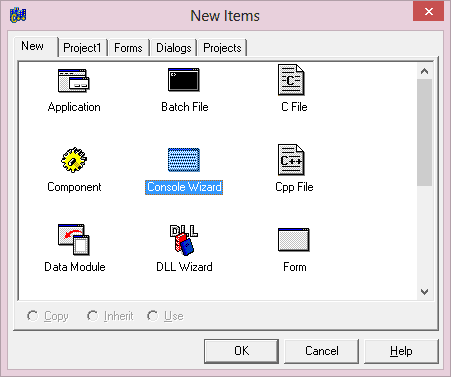
W oknie dialogowym New Items na zakładce New wybierz opcję Console Wizard i kliknij przycisk OK.
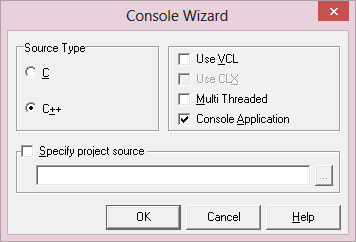
W oknie dialogowym Console Wizard ustaw opcje jak powyżej i kliknij przycisk OK. Po tej operacji otrzymasz okno edytora kodu:
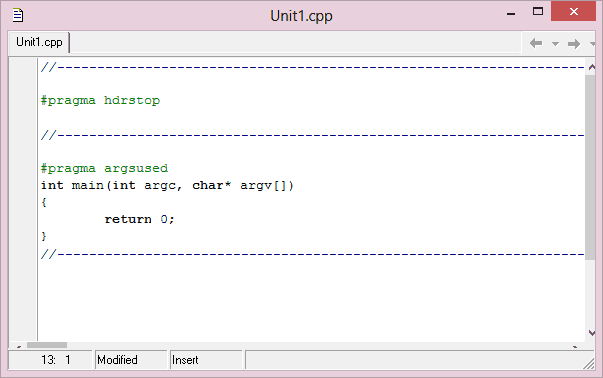
W oknie tym będziesz wpisywał swoje programy. Teraz zapisz swój projekt na dysku: z menu wybierz opcję File – Save All. W oknie dialogowym zapisu możesz wybrać miejsce, gdzie projekt zostanie zapisany – w razie konieczności jest również opcja tworzenia nowego katalogu. Zapisywane są dwa pliki:
Uwaga: program wynikowy będzie miał nazwę projektu i rozszerzenie exe.
Do testów program uruchamiasz zieloną strzałką na pasku narzędziowym. Końcowej kompilacji dokonujesz poprzez opcję menu: Project – Build nazwa_projektu. Środowisko Borland C++ Builder jest bardzo schludne i nie zaśmieca katalogu projektowego dużą liczbą plików.
Pamięć komputerowa (ang. computer memory) jest urządzeniem cyfrowym służącym do przechowywania informacji w postaci bitów. Dzielimy ją na:
Pamięć RAM (ang. Random Access Memory - pamięć o dostępie swobodnym) jest podstawowym składnikiem pamięci operacyjnej komputera. Termin RAM oznacza pamięć, z której informacja może być odczytywana w dowolnej kolejności bez względu na poprzednie odczyty czy zapisy. Termin RAM wprowadzono w celu odróżnienia pamięci o dostępie swobodnym od pamięci o dostępie sekwencyjnym (np. taśmowej, dyskowej itp.), popularnej na początku ery komputerowej.
Informacja przechowywana jest w pamięci RAM w postaci bitów umieszczanych w komórkach (ang memory cell), których mogą być miliardy. Aby komputer mógł uzyskiwać w prosty sposób dostęp do każdej komórki pamięci, zostały one ponumerowane. Numery komórek nazywamy adresami komórek pamięci (ang. memory cell address). Poniżej przedstawiamy fragment logicznej struktury pamięci (czyli tak, jak widzi swoją pamięć komputer):
| Pamięć | |
| Adres | Zawartość komórki |
| 0 | 11000110 |
| 1 | 00001111 |
| 2 | 11000011 |
| 3 | 11111110 |
| 4 | 00000001 |
| 5 | 11100111 |
| ... | ... |
Ze względów ekonomicznych poszczególne komórki pamięci przechowują grupę kilku bitów (najczęściej jest ich 8 - czyli 1 bajt, ale rozmiar bitowy komórki pamięci zależy od architektury systemu komputerowego). Na przykład komórka o adresie 3 przechowuje 8 bitów o zawartości 11111110. Treść tej informacji uzależniona jest od interpretacji stanów bitów.

Komputer steruje pamięcią przy pomocy trzech magistral (ang. bus). Magistrale zbudowane są z linii, którymi transmituje się sygnały. We współczesnych komputerach magistrale są cyfrowe, co oznacza, iż poszczególne linie przesyłają tylko sygnały dwustanowe, czyli bity. Widać z tego wyraźnie, iż komputery są maszynami binarnymi nie tylko ze względu na rodzaj przetwarzanych informacji, lecz również z powodu swojej wewnętrznej budowy - mówimy, iż posiadają architekturę binarną (ang. binary architecture).
Magistrala adresowa (ang. address bus) przekazuje pamięci adres komórki, do której komputer chce uzyskać dostęp - odczytać zawartość lub umieścić nowe dane. Ponieważ adres przekazywany jest magistralą cyfrową, to sam również występuje jako liczba binarna. Ilość linii na magistrali adresowej określa zakres dostępnych adresów, a zatem maksymalny rozmiar pamięci komputera. Do obliczeń stosujemy prosty wzór:
rozmiar pamięci = 2liczba linii na magistrali adresowej
Na przykład w starych komputerach magistrala adresowa mogła zawierać maksymalnie 16 linii. Zatem rozmiar możliwej do zaadresowania pamięci wynosił 216 = 65536 komórek (sławne 64KB - kilo bajty). Jeśli magistrala adresowa składa się z 32 linii, to komputer jest w stanie wykorzystać 232 = 4294967296 = 4GB pamięci (GB - gigabajt). Oczywiście w systemie może być mniej pamięci (np. tylko 1GB = 1073741824 komórek), w takim przypadku część adresów nie jest wykorzystywana, gdyż nie stoją za nimi żadne komórki. Ilość możliwych do zaadresowania komórek nosi nazwę przestrzeni adresowej (ang. address space). Natomiast pamięć fizyczna (ang. physical memory, physical storage) określa ilość pamięci rzeczywiście zainstalowanej w systemie komputerowym.
Magistrala danych (ang. data bus) umożliwia komputerowi przekazywanie danych do pamięci oraz odczyt przechowywanych przez pamięć informacji z komórek. Magistrala danych zbudowana jest z linii sygnałowych, po których przekazywane są bity. Ilość linii na magistrali danych zależy od architektury komputera. Na przykład w systemach 32-bitowych magistrala danych zawiera 32 linie, co pozwala w jednym cyklu dostępu do pamięci przesłać porcję 32 bitów.
|
Jeśli dokładnie czytałeś podane wyżej informacje, to zapewne zauważyłeś, iż pisaliśmy o pamięci zawierającej komórki 8 bitowe. Tutaj z kolei piszemy, że magistrala danych jest 32-bitowa. Jak pogodzić ze sobą te dwa fakty. Prześledźmy krótką historię rozwoju magistral danych.
Popularne w latach 80-tych ubiegłego wieku komputery 8-bitowe
Magistrala danych pierwszych popularnych komputerów domowych była 8 bitowa i odpowiadała dokładnie rozmiarowi komórki pamięci. Dane umieszczane na 8-bitowej magistrali trafiały bezpośrednio do zaadresowanej komórki. Również odczyt danych z dowolnej komórki był realizowany przy pomocy 8 bitowej magistrali. Stąd systemy takie często określa się dzisiaj mianem komputerów 8 bitowych. Magistrale 8 bitowe wciąż są w użyciu w świecie mikrokontrolerów - małych komputerków, które w całości mieszczą się w pojedynczym układzie scalonym i sterują różnymi urządzeniami - monitorami, radiami, telewizorami, aparatami fotograficznymi, pralkami, zegarkami, grami elektronicznymi itp.
Komputery 16-bitowe, rozpowszechnione pod koniec lat 80-tych ubiegłego wieku.
Kolejna generacja komputerów osobistych to maszyny z 16 bitową magistralą danych. Komórki pamięci zostały dalej 8-bitowe. Pamięć podzielono na dwa banki, które współpracowały z jedną połówką magistrali danych.
Na przykład bank 0 podłączony był do linii d7...d0, czyli do młodszych 8 bitów magistrali danych. Poprzez te linie komputer komunikował się z komórkami pamięci zawartymi w banku 0. Z kolei drugi bank, bank 1, podłączony był do pozostałych 8 linii danych - d15...d8.
Z punktu widzenia komputera komórki w banku 0 posiadały adresy parzyste 0, 2, 4, 6, ... Komórki w banku 1 posiadały adresy nieparzyste. Oba banki pamięci połączone były z tą samą magistralą adresową bez linii A0, która służyła do wyboru banku pamięci w przypadku danych 8-bitowych. Dzięki takiemu rozwiązaniu komputer mógł przesłać do lub pobrać z pamięci porcję 16 bitów (naraz dwie komórki), gdyż magistrala adresowa wybierała z obu pamięci komórki leżące w tym samym wierszu. Istnieje też pewna niedogodność. Jeśli dane 16-bitowe zostaną umieszczone pod nieparzystym adresem (tutaj w komórkach 5 i 6), to nie można ich pobrać w jednym cyklu odczytu pamięci, ponieważ znajdują się w dwóch różnych wierszach. Powoduje to spowolnienie działania programu przetwarzającego te dane - komputer musi czytać pamięć dwa razy po 8 bitów, pomimo że jest maszyną 16-bitową!. Dlatego kompilatory języków programowania posiadają wbudowane odpowiednie mechanizmy umieszczania danych wielobajtowych pod właściwymi adresami, nawet jeśli prowadziłoby to do powstania dziur (niewykorzystanych komórek) w obszarze pamięci.
32 bitowe komputery lat 90-tych ubiegłego wieku.
Rozwój komputeryzacji wymusił pojawienie się maszyn 32-bitowych. Pamięć komputera 32-bitowego wciąż zbudowana jest z komórek 8-bitowych. Zastosowano podobne rozwiązanie jak w systemach 16 bitowych - podzielono pamięć na cztery banki 0, 1, 2 i 3. Każdy bank współpracuje z 8 liniami magistrali danych. Banki są podłączone do wspólnej magistrali adresowej z wyjątkiem linii A1 i A0, które sterują wybieraniem odpowiedniego banku (lub pary banków) w przypadku danych 8-bitowych (lub 16 bitowych).
Poniżej przedstawiamy rozłożenie adresów komórek w poszczególnych bankach pamięci z punktu widzenia komputera. Magistrala adresowa wybiera zawsze rząd 4 komórek, leżących pod tym samym adresem w każdym z banków. Dwa najmłodsze bity A1 i A0 adresują odpowiedni bank, a komputer odczytuje lub zapisuje dane wykorzystując linie magistrali danych połączone z wybranym bankiem (lub z wybranymi bankami).
Aby wykorzystać maksymalnie potencjał systemu 32-bitowego dane 16 bitowe należy umieszczać pod adresami parzystymi (np. komórki 6-7 i 8-9), a dane 32 bitowe należy umieszczać pod adresami podzielnymi przez 4 (np. komórki 16-17-18-19). Wtedy komputer będzie miał do nich dostęp w jednym cyklu odczytu lub zapisu pamięci. Zwróć uwagę na sposób przechowywania danych wielobajtowych w komórkach pamięci. Możliwe są dwa rozwiązania - tzw. little-endian i big-endian. Wszystkie procesory Intel i kompatybilne stosują system little-endian, który polega na tym, iż w niższych adresach przechowuje się mniej znaczące bajty danych. Zatem dana 16-bitowa w little-endian zostanie umieszczona w kolejnych dwóch komórkach jako b7...b0 w pierwszej komórce (o niższym adresie) i b15...b8 w drugiej komórce o adresie wyższym. Z danymi 32-bitowymi jest identycznie : najmłodszy bajt trafi do pierwszej komórki, a najstarszy do ostatniej. Porządek ten odzwierciedla nasz schemat rozmieszczenia bloków pamięci. W systemie big-endian (stosowanym w starszych komputerach Amiga, Macintosh oraz w niektórych systemach mainframe) jest na odwrót: pierwszy adres przechowuje starsze bity, następne adresy przechowują coraz młodsze bity danej. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Adresy i rozmiary zmiennych
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
char a;
bool b;
short int c;
int d;
long long e;
float f;
double g;
long double h;
cout << "a" << setw(3) << sizeof(a) << setw(10) << (void *)&a << endl;
cout << "b" << setw(3) << sizeof(b) << setw(10) << &b << endl;
cout << "c" << setw(3) << sizeof(c) << setw(10) << &c << endl;
cout << "d" << setw(3) << sizeof(d) << setw(10) << &d << endl;
cout << "e" << setw(3) << sizeof(e) << setw(10) << &e << endl;
cout << "f" << setw(3) << sizeof(f) << setw(10) << &f << endl;
cout << "g" << setw(3) << sizeof(g) << setw(10) << &g << endl;
cout << "h" << setw(3) << sizeof(h) << setw(10) << &h << endl;
system("pause"); // Oczekiwanie na klawisz przed zamknięciem okna konsoli
return 0;
}
|
Uwagi: strumień cout traktuje adres zmiennej znakowej jako ciąg znaków. Musimy stosować jawne rzutowanie na typ np. void (spróbuj usunąć to rzutowanie i zobacz, co się stanie).
Kolejna ciekawa rzecz, to sposób rozmieszczenia zmiennych w pamięci (otrzymane adresy zależą od komputera i kompilatora, na którym uruchomiono program):
a 1 1638223 b 1 1638222 c 2 1638220 d 4 1638216 e 8 1638208 f 4 1638204 g 8 1638196 h 10 1638184 |
Zmienne umieszczane są kolejno w kierunku końca pamięci – ostatnia zmienna h znajduje się pod najniższym adresem. Zwróć uwagę, że zmienna h faktycznie zajmuje w pamięci 12 bajtów, chociaż jej rozmiar wynosi tylko 10. Dwa bajty nie są zatem wykorzystywane.
Z kolei elementy tablic są upakowane jeden obok drugiego (lecz same tablice wcale nie muszą być po kolei w pamięci):
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Adresy elementów tablic
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
long double a[4];
bool b[4];
int c[4];
for(int i = 0; i < 4; i++)
cout << "a[" << i << "]" << setw(3) << sizeof(a[i]) << setw(10) << &a[i] << endl;
cout << endl;
for(int i = 0; i < 4; i++)
cout << "b[" << i << "]" << setw(3) << sizeof(b[i]) << setw(10) << &b[i] << endl;
cout << endl;
for(int i = 0; i < 4; i++)
cout << "c[" << i << "]" << setw(3) << sizeof(c[i]) << setw(10) << &c[i] << endl;
system("pause");
return 0;
}
|
Wskaźnik (ang. pointer) jest zmienną, która przechowuje adres danych. W języku C++ wskaźniki posiadają typy. Typ wskaźnika określa, co wskazuje przechowywany przez niego adres. Wskaźnik definiujemy następująco:
typ * nazwa_wskaźnika;
Wskaźnikowi można przypisać adres zmiennej. Typ zmiennej musi być zgodny z typem wskazywanych przez wskaźnik danych – tzn. do wskaźnika wskazującego zmienne typu int można wprowadzić tylko adres zmiennej typu int (da się "oszukać" kompilator przez rzutowanie, co czasami może być użyteczne, ale zwykle jest to błąd programu).
wskaźnik = &zmienna;
Gdy wskaźnik zawiera już poprawny adres, to dostęp do wskazywanego elementu otrzymujemy poprzez operator *.
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Wskaźnik do zmiennej
//-----------------------------------
#include <iostream>
using namespace std;
int main()
{
int a, b, *p; // Tworzymy dwie zmienne int oraz wskaźnik do int
p = &a; // W p umieszczamy adres a
* p = 10; // W a umieszczamy 10
p = &b; // W p umieszczamy adres b
* p = 33; // W b umieszczamy 33
cout << "a = " << a << endl
<< "b = " << b << endl;
system("pause");
return 0;
}
|
Wskaźniki mogą również wskazywać elementy tablic. W takim przypadku dodanie 1 do wskaźnika powoduje, że zaczyna on wskazywać kolejny element w tablicy. Odjęcie 1 od wskaźnika powoduje, że wskaże on poprzedni element w tablicy. W rzeczywistości kompilator na podstawie typu wskazywanego obiektu wyznacza jego rozmiar i ten rozmiar jest dodawany lub odejmowany od wskaźnika. Pamiętaj, że elementy tablic leżą w pamięci jeden obok drugiego – dlatego zwiększenie adresu o rozmiar elementu daje adres kolejnego elementu tablicy.
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Wskaźnik do elementów tablicy
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int a[10],*p,i;
for(i = 0; i < 10; i++) a[i] = (i + 1) * 2;
p = a; // Nazwa tablicy jest adresem &a[0]
for(i = 0; i < 10; i++) cout << setw(2) << *p++ << endl;
system("pause");
return 0;
}
|
Dodanie n do wskaźnika powoduje, że wskazuje on element leżący o n elementów dalej w pamięci.
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Wskaźnik do elementów tablicy
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int a[10],*p,i;
for(i = 0; i < 10; i++) a[i] = (i + 1) * 2;
p = a; // Nazwa tablicy jest adresem &a[0]
for(i = 0; i < 10; i++) cout << setw(2) << *(p+i) << endl;
cout << endl;
for(i = 0; i < 10; i++) cout << setw(2) << a[i] << endl;
system("pause");
return 0;
}
|
Zwróć uwagę, że zapisy *(p+i) oraz a[i] w
powyższym programie są sobie równoważne (tzn. dają ten sam
wynik). Ta równoważność idzie dużo dalej:
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Wskaźnik do elementów tablicy
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int a[10],*p,i;
for(i = 0; i < 10; i++) a[i] = (i + 1) * 2;
p = a; // Nazwa tablicy jest adresem &a[0]
for(i = 0; i < 10; i++) cout << setw(2) << p[i] << endl;
cout << endl;
for(i = 0; i < 10; i++) cout << setw(2) << *(a+i) << endl;
system("pause");
return 0;
}
|
Dlaczego tak jest? Otóż a jest również wskaźnikiem, czyli
adresem naszej tablicy. Natomiast a[0], a[1],
a[2] to odwołania do kolejnych elementów. Skoro a
jest wskaźnikiem, to *(a+0) wskazuje element a[0],
*(a+1) wskazuje element a[1], itd. Skoro p
też jest wskaźnikiem do tej samej tablicy, to również musi podlegać tym
samym prawom, zatem *(p+0) wskazuje element p[0],
*(p+1) wskazuje element p[1], itd. W
naszym programie różnica pomiędzy a i p jest taka,
iż a ma wartość stałą (wskazuje zawsze
tablicę a[]), natomiast p jest zmienną i może wskazywać
również inne tablice.
Zapamiętaj: jeśli p wskazuje początek tablicy, to p[i]
jest jej i-tym elementem. Równoważny zapis to *(p+i).
Wskaźniki mogą również wskazywać zmienne złożone. Cechą charakterystyczną takich zmiennych jest to, iż posiadają one pola danych o różnych nazwach i typach.
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Wskaźnik do struktury
//-----------------------------------
#include <iostream>
using namespace std;
struct complex
{
double r,i;
};
int main()
{
complex a,*p;
a.i = 1.7; // Nadajemy wartości polom struktury
a.r = 3.3; // Dostęp do pól za pomocą .
p = &a; // p wskazuje strukturę a
p->r++; // Dostęp do pól za pomocą ->
p->i += 10;
cout << a.r << " " << a.i << endl;
system("pause");
return 0;
}
|
Dostęp do pól zmiennej złożonej odbywa się za pomocą operatora . (kropka). Jeśli wskaźnik wskazuje zmienną złożoną, to dostęp do jej pól uzyskujemy za pomocą operatora -> (strzałka). Najlepiej zapamiętaj to w ten sposób:
Jeśli zmienna x jest wskaźnikiem, to nie zawiera w sobie żadnych pól, lecz adres do struktury. Aby uzyskać dostęp za pomocą x do danego pola tej struktury, używamy operatora ->.
KROPKA – ELEMENT SKŁADOWY
STRZAŁKA – WSKAZANIE ELEMENTU SKŁADOWEGO
wskaźnik = new typ;
Operator new rezerwuje obszar pamięci na pomieszczenie danej o podanym typie i zwraca adres początku tego obszaru. Adres ten trafia do wskaźnika. Takie tworzenie zmiennych nazywamy dynamicznym, ponieważ powstają one dynamicznie w czasie działania programu.
Adres pamiętany przez wskaźnik nie powinien być niszczony lub zmieniany. Za jego pomocą możemy oddać zarezerwowaną pamięć przy pomocy operatora delete. Jeśli zniszczymy ten adres, to nie będziemy mogli "oddać" do systemu przydzielonej pamięci i powstanie tzw. wyciek (ang. memory leak). Gdy taka sytuacja występuje cyklicznie w programie, to program w miarę swojego działania rezerwuje coraz więcej pamięci na swoje potrzeby i jej nie oddaje. W końcu zostanie zarezerwowana cała dostępna pamięć w komputerze i program przestanie działać (oby tylko on jeden!!!).
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Zmienne dynamiczne
//-----------------------------------
#include <iostream>
using namespace std;
int main()
{
double *x,*y; // Dwa wskaźniki do danych double
x = new double; // Przydzielamy pamięć dla x
y = new double; // Przydzielamy pamięć dla y
*x = 1.5; // Na zmiennych dynamicznych wykonujemy działania
*y = *x * 6.5;
cout << "x = " << *x << endl
<< "y = " << *y << endl;
delete x; // Zwalniamy pamięć przydzieloną x
delete y; // Zwalniamy pamięć przydzieloną y
system("pause");
return 0;
}
|
W ten sam sposób możemy tworzyć dynamiczne struktury:
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Struktury dynamiczne
//-----------------------------------
#include <iostream>
using namespace std;
struct point3d
{
double x,y,z;
};
int main()
{
point3d *a, *b; // Dwa wskaźniki do struktury point3d
a = new point3d; // Przydzielamy pamięć dla struktur
b = new point3d;
a->x = 1.73; // Inicjujemy pola struktur
a->y = 2.52;
a->z = 3.98;
b->x = 32.3;
b->y = 18.5;
b->z = 27.3;
cout << "punkt a(" << a->x << " " << a->y << " " << a->z << ")" << endl
<< "punkt b(" << b->x << " " << b->y << " " << b->z << ")" << endl;
delete a; // Zwalniamy zarezerwowaną pamięć
delete b;
system("pause");
return 0;
}
|
wskaźnik = new typ[liczba_elementów]
Do elementów tablicy mamy dostęp poprzez wskaźnik oraz indeks jak do zwykłej tablicy:
wskaźnik[indeks]
Gdy tablica przestanie nam być potrzebna (pamiętamy, że nie wolno zmieniać zawartości wskaźnika!), to zajmowany przez nią obszar pamięci oddajemy do systemu za pomocą polecenia:
delete [] wskaźnik;
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Tablice dynamiczne
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int i,*T;
T = new int[10]; // Tworzymy tablicę T o dziesięciu elementach int
for(i = 0; i < 10; i++) T[i] = 3 * (i+1);
for(i = 0; i < 10; i++)
cout << "T[" << i << "] =" << setw(3) << T[i] << endl;
cout << endl;
for(i = 0; i < 10; i++)
cout << "*(T+" << i << ") =" << setw(3) << *(T+i) << endl;
delete [] T;
system("pause");
return 0;
}
|
W niektórych zastosowaniach (np. w teorii grafów) potrzebne są tablice dwuwymiarowe, które nazywamy macierzami. Macierz składa się z określonej liczby wierszy i kolumn. Każdy element macierzy posiada dwa indeksy: numer wiersza oraz numer kolumny. Macierz deklarujemy następująco:
typ nazwa[liczba_wierszy][liczba_kolumn];
Dostęp do elementów odbywa się za pomocą dwóch indeksów:
nazwa[nr_wiersza][nr_kolumny]
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Macierz
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int A[3][4],i,j,c;
c = 0;
for(i = 0; i < 3; i++)
for(j = 0; j < 4; j++) A[i][j] = c++;
for(i = 0; i < 3; i++)
{
for(j = 0; j < 4; j++)
cout << "A[" << i << "][" << j << "]=" << setw(2) << A[i][j] << " ";
cout << endl;
}
cout << endl;
system("pause");
return 0;
}
|
Podobnie jak tablice, macierze również mogą być tworzone dynamicznie. Zasada jest następująca:
Najpierw tworzymy dynamiczną tablicę o m elementach. Każdy element tej tablicy jest wskaźnikiem.
Dla każdego elementu tablicy wskaźników tworzymy dynamiczną tablicę o n elementach danych i zapamiętujemy adres tej tablicy w odpowiednim wskaźniku tablicy wskaźników.
// Koło Informatyczne I LO w Tarnowie
// (C)2013 mgr Jerzy Wałaszek
// Macierz dynamiczna
//-----------------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int **A; // Wskaźnik do danej typu wskaźnik int
int i,j,c,m,n;
cout << "Liczba wierszy : "; cin >> m;
cout << "Liczba kolumn : "; cin >> n;
A = new int * [m]; // Tablica wskaźników wierszy
for(i = 0; i < m; i++)
A[i] = new int [n]; // Tablica wiersza
c = 0;
for(i = 0; i < m; i++)
for(j = 0; j < n; j++) A[i][j] = c++;
cout << endl;
for(i = 0; i < m; i++)
{
for(j = 0; j < n; j++)
cout << "A[" << i << "][" << j << "]=" << setw(3) << A[i][j] << " ";
cout << endl;
}
cout << endl;
// Najpierw usuwamy wiersze
for(i = 0; i < m; i++) delete [] A[i];
// Następnie usuwamy tablicę wskaźników wierszy
delete [] A;
system("pause");
return 0;
}
|
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe









