
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2013 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2013 mgr
Jerzy Wałaszek
|

Taśma filmowa z kodem programu
Gdy liczba instrukcji maszyny cyfrowej rosła, a same instrukcje stawały się coraz bardziej skomplikowane, wymyślono język asemblera (ang. assembler language). Zamiast binarnych kodów instrukcji w języku asemblera stosuje się ich nazwy symboliczne (jak ADD, SUB, JMP w PMC). Dzięki temu łatwiej je zapamiętać, a i sam program staje się dużo prostszy.
| Asembler PMC | Kod binarny PMC | |
START: LDA #"Z
LOOP: STA $INOUT
DEC
JMP #LOOP
END
|
0001010001011010 0010100000000000 1001000000000000 1010010000000010 0000000000000000 |
Procesor rozumie tylko i wyłącznie swój kod binarny. Dlatego tworząc programy w asemblerze musimy je kompilować, czyli zamieniać na postać binarną. Konwersji takiej dokonuje program, który również nazywamy asemblerem. Pierwszy asembler musiał jednak być napisany bezpośrednio w kodzie binarnym.
Asembler daje programiście dostęp do wszystkich składników komputera. Jednakże, jak widzieliśmy przy programowaniu PMC, tworzenie programu jest bardzo żmudne, ponieważ każdą operację należy rozbijać na poszczególne instrukcje procesora. Np. sprawdzenie, czy komórki o etykietach L1 i L2 są sobie równe, wymaga kilku instrukcji procesora:
| Asembler PMC |
LDA $L1 ; załaduj do akumulatora komórkę L1 SUB $L2 ; odejmij od niej komórkę L2 JZR #ROWNE ; jeśli są równe, skocz ... ; jeśli są różne, jesteś tutaj |
Czyż nie byłoby lepiej zapisać:
| ??? |
JEŚLI L1 = L2, TO ... INACZEJ ... |
I tak dochodzimy do koncepcji języków wysokiego poziomu – HLL (ang. High Level Language). Asembler, a tym bardziej kod binarny instrukcji procesora, to języki niskiego poziomu – LLL (ang. Low Level Language), które operują bezpośrednio na zasobach komputera: na procesorze, pamięci, rejestrach wejścia/wyjścia. Aby w nich efektywnie programować, programista musi posiadać dużą wiedzę na temat budowy komputera oraz urządzeń towarzyszących. Również musi dokładnie wiedzieć, w jaki sposób realizować złożone polecenia. Pomyłki w kodzie są trudne do wyłapania. Wszystko to powoduje, że chociaż asembler jest bardzo potężnym narzędziem, to jednak jest również bardzo trudny w opanowaniu i mało efektywny przy dużych projektach. Dzisiaj w asemblerze tworzone są tylko fragmenty programów, które muszą być naprawdę szybkie i efektywne.
Język wysokiego poziomu oddala się od sprzętu komputera i pozwala tworzyć bardziej abstrakcyjne konstrukcje, które zbliżone są do pojęć matematycznych. Dzięki temu programista może dużo szybciej tworzyć złożone programy, niż jest to możliwe w asemblerze. Wszystkie języki wysokiego poziomu muszą być przetwarzane na postać binarną (nie dotyczy to języków interpretowanych, tzw. skryptowych, o których dowiemy się później). Konwersję taką wykonuje program zwany kompilatorem (ang. compiler).
Pierwsze języki wysokiego poziomu zaczęły się pojawiać po II Wojnie Światowej. Wcześniej stosowano kody binarne oraz asemblery. Poniżej podajemy chronologiczną listę najważniejszych języków programowania (niech cię nie przeraża ich liczba):
 Bjarne Stroustrup – twórca C++ |
Język C++ jest językiem programowania stworzonym przez Bjarne Stroustrupa, profesora Texas A&M University. Jest to język wysokiego poziomu i należy do grupy języków kompilowanych. Oznacza to, iż programista w edytorze tworzy tekst programu, który następnie jest przekazywany do kompilatora. Kompilator analizuje otrzymany tekst i na jego podstawie tworzy program wynikowy zawierający binarne instrukcje dla procesora.
|
tworzenie tekstu programu |
→ |
kompilacja tekstu na język maszynowy |
→ |
uruchomienie programu wynikowego |
Języki wysokiego poziomu są bardziej czytelne dla ludzi. Jednakże procesor nie potrafi bezpośrednio wykonywać zawartych w takim programie poleceń - program musi być przetłumaczony do postaci zrozumiałej dla procesora, czyli do binarnych kodów instrukcji maszynowych.
Do programowania w języku C++ będziemy używali zintegrowanego środowiska programowania (ang. IDE - Integrated Developement Environment), które zawiera edytor oraz kompilator. Na lekcjach oprzemy się o darmowe środowisko Code::Blocks 12.11 (oraz później Borland C++ Builder 6.0 Personal Edition), które można pobrać z sieci Internet. Na komputerze domowym ucznia musi być bezwzględnie zainstalowane podane środowisko programowania, aby mógł on wykonywać ćwiczenia w domu.
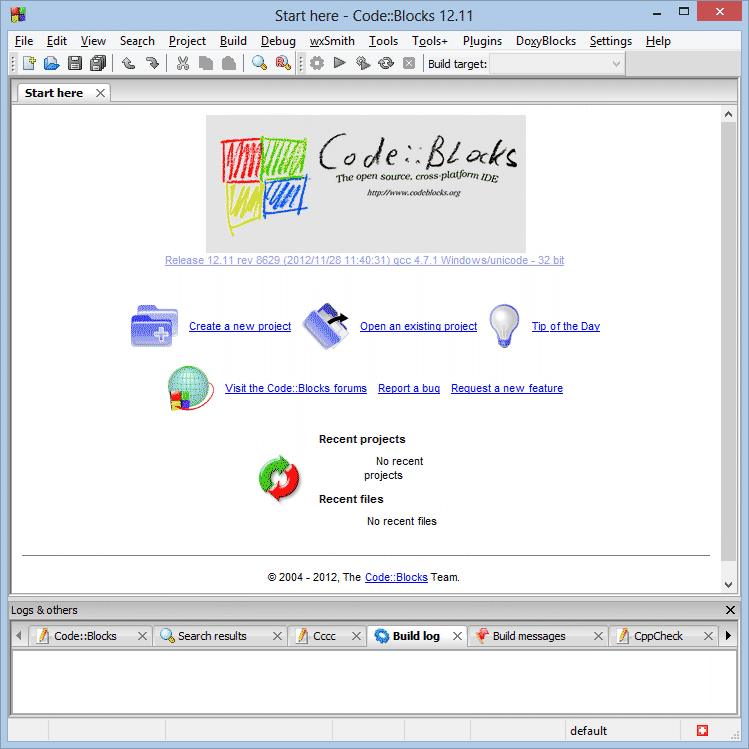
Z dostępnych opcji startowych wybieramy Create a new project (Utwórz nowy projekt). Teraz pojawi się okno dialogowe wyboru typu projektu:
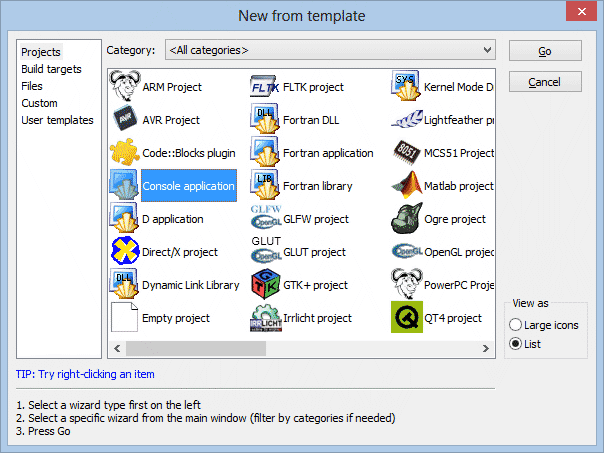
Zaznaczamy tutaj opcję Console application (aplikacja konsoli). Projekt aplikacji konsoli pozwoli nam utworzyć tzw. program konsolowy, czyli program pracujący w środowisku tekstowym. Jest to najprostsze środowisko programowania, ponieważ nie musimy w nim obsługiwać w programie współpracy z systemem Windows. Wszyscy uczący się programowania zwykle zaczynają od konsoli.
Gdy wybierzesz rodzaj tworzonej aplikacji, kliknij myszką przycisk Go. Okienko wyboru rodzaju projektu zostanie zastąpione nowym oknem dialogowym:
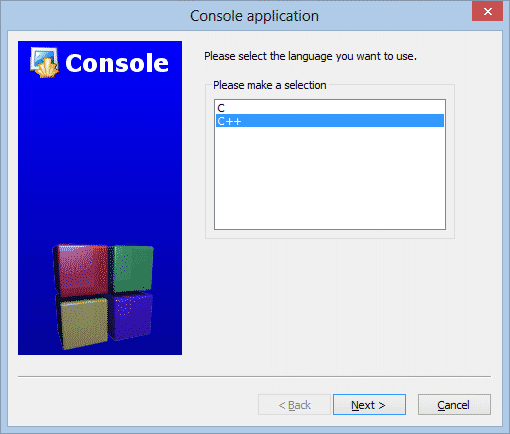
Tutaj upewnij się tylko, czy jest wybrana opcja C++ i kliknij przycisk Next. Kolejne okienko dialogowe jest bardzo ważne, więc omówimy je szczegółowo:
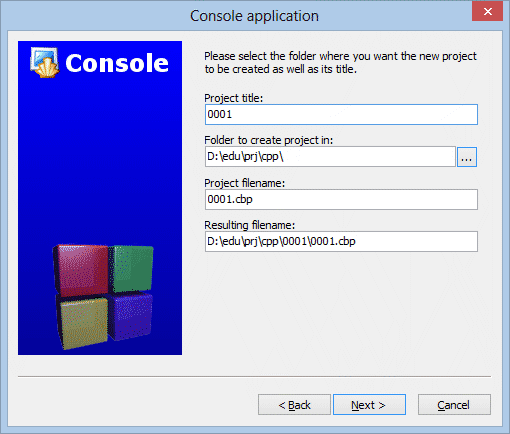
W polu tekstowym Project title (nazwa projektu) wpisz swoją nazwę. Proponuję numerować projekty kolejno 0001, 0002, itd. Nazwa projektu stanie się nazwą katalogu z projektem oraz nazwą programu.
W polu Folder to create project in (Katalog na projekt) określasz miejsce, gdzie ma się znaleźć katalog z projektem. Jeśli nie pamiętasz lub podana ścieżka jest zła, kliknij myszką w przycisk obok pola i wybierz na dysku odpowiednie miejsce. W naszej pracowni będzie to odpowiednio c:\uczniowie\2k1\ lub c:\uczniowie\2k2\.
Pole Project filename (Nazwa pliku projektu) służy do określania nazwy pliku, w którym Code::Blocks będzie przechowywało informacje o twoim projekcie. Jeśli w pierwszym polu określiłeś nazwę projektu, to nie zmieniaj zawartości tego pola.
Ostatnie pole Resulting filename (Wynikowa nazwa pliku) jest polem podsumowującym. Nie zmieniaj jego zawartości.
Gdy określisz nazwę i położenie swojego projektu na dysku, kliknij w przycisk Next. Na ekranie pojawi się ostatnie okno dialogowe:
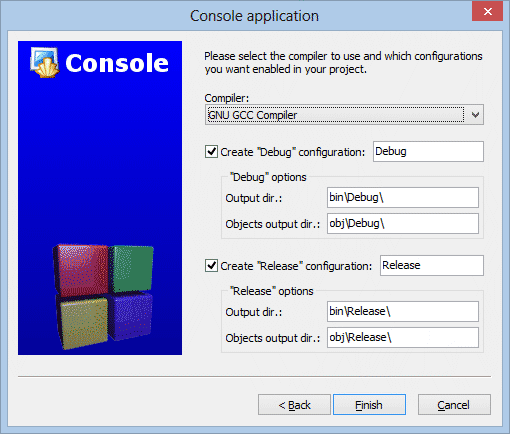
Tutaj nie powinieneś nic zmieniać. Okno to służy do wyboru kompilatora oraz opcji konfiguracyjnych. Kliknij w przycisk Finish. Na ekranie pojawi się okno środowiska Code::Blocks.
Uwagi:
Ponieważ rozpoczynasz naukę języka C++, usuń wszystko z edytora i wprowadź poniższy kod.
int main()
{
}
|
Program w języku C++ zbudowany jest z tzw. funkcji, czyli fragmentów kodu, które można wielokrotnie używać. Najprostszy program posiada tylko jedną funkcję, która nosi nazwę main (główna). Nazwa ta musi być pisana małymi literami, ponieważ język C++ rozróżnia duże i małe litery. Wykonanie programu w języku C++ zawsze rozpoczyna się od kodu w funkcji main, dlatego jest to główna funkcja programu.
Powyższy program zawiera pustą funkcję main, czyli po prostu nic nie robi, lecz można go skompilować i uruchomić, a o to nam w tym momencie chodzi.
Aby skompilować program (czyli utworzyć na dysku plik programu z rozszerzeniem exe), kliknij myszką na ikonę (na pasku narzędziowym u góry okna):

Jeśli nie zrobiłeś błędów, to panelu na spodzie ekranu dostaniesz raport z kompilacji:
mingw32-g++.exe -Wall
-fexceptions -g -c D:\edu\prj\cpp\0001\main.cpp -o obj\Debug\main.o
mingw32-g++.exe -o bin\Debug\0001.exe obj\Debug\main.o
Output size is 27.66 KB
Process terminated with status 0 (0 minutes, 0
seconds)
0 errors, 0 warnings (0 minutes, 0 seconds)
Ważny jest ostatni wiersz, który informuje cię o błędach. Jeśli program zawiera jakieś błędy (ang. errors), to nie będziesz go mógł uruchomić. Błędy zawsze muszą zostać usunięte.
Gdy kompilacja przebiegła poprawnie, to na dysku pojawi się plik programu o nazwie takiej samej jak nazwa projektu. U nas jest to 0001.exe. Aby go uruchomić, nie musisz opuszczać środowisk Code::Blocks. Wystarczy, że klikniesz myszką ikonę:

Na ekranie pojawi się czarne okienko konsoli, a w nim tekst:
Process returned 0 (0x0) execution time : 0.007 s Press any key to continue.
Tekst ten będzie się pojawiał tylko wtedy, gdy program uruchamiasz w środowisku Code::Blocks. Jeśli zrobisz to bezpośrednio z poziomu Windows, to okienko ukaże się na ułamek sekundy, po czym zaraz zniknie. Dzieje się tak dlatego, że nasz program natychmiast po uruchomieniu kończy się, a system Windows automatycznie zamyka okna konsoli programów, które ukończyły swoją pracę. Tyle informacji powinno ci wystarczyć na początek.
Funkcja main() zwraca wartość całkowitą, którą można wykorzystać (i często to się robi) do zwrócenia dodatkowych informacji przez program - np. czy wykonanie go powiodło się, czy też wystąpił jakiś błąd. Do zwracania wartości przez funkcję używamy polecenia return. Jeśli je pominiesz, to funkcja zwróci zero. Zmień program w edytorze na poniższy:
int main()
{
return 155;
}
|
Jeśli teraz skompilujesz i uruchomisz program, w oknie konsoli pojawi się informacja:
Process returned 155 (0x9B) execution time : 0.000 s Press any key to continue.
To właśnie jest argument instrukcji return. Dodatkowo, ponieważ kod zwrócony przez program był różny od 0, w okienku Logs & others pojawi się na czerwonym tle napis:
Process terminated with status 155 (0 minutes, 0 seconds)
Tak będzie zawsze, jeśli funkcja main() zwróci wartość różną od 0 (oznaczającego wykonanie z sukcesem - inna wartość jest zawsze interpretowana jako błąd). Najczęściej funkcję main() będziemy kończyli instrukcją:
int main()
{
return 0;
}
|
Jeśli teraz skompilujesz i uruchomisz program, to w oknie Logs & others nie pojawi napis na czerwonym tle, lecz napis niebieski:
Process terminated with status 0 (0 minutes, 1
seconds)
Proces zakończył się ze statusem 0 ...
Zwykle program w C++ musi odczytywać dane z konsoli i wyprowadzać na nią wyniki swojego działania. Operacje wejścia/wyjścia nie są częścią definicji języka C++, lecz osobną biblioteką. Jeśli chcemy z nich korzystać, to musimy poinformować kompilator o obiektach, które tych operacji dokonują. Definicje tych obiektów zawarte są w tzw. plikach nagłówkowych (ang. header files), które dołączamy do programu dyrektywą #include. Wpisz poniższy program:
#include <iostream>
int main()
{
return 0;
}
|
Pliki nagłówkowe są bardzo wygodnym rozwiązaniem - zamiast w każdym programie wpisywać żmudnie definicje tych samych obiektów, wpisujemy jedynie prostą dyrektywę. Przed rozpoczęciem kompilacji plik źródłowy jest wstępnie obrabiany przez tzw. preprocesor. Wyszukuje on w programie źródłowym swoich poleceń, które nazywamy dyrektywami preprocesora. Np. polecenie #include każe preprocesorowi zastąpić się zawartością odpowiedniego pliku nagłówkowego, który jest wstawiany w miejscu tej dyrektywy. Następnie tak zmieniony plik wędruje do kompilatora, który ma już pod ręką wszystkie potrzebne definicje.
Plik nagłówkowy iostream definiuje tzw. strumienie wejścia/wyjścia konsoli (ang. input output streams). Strumień wyjścia cout (ang. console output) pozwala wyświetlać informację w oknie konsoli. Strumień wejścia cin (ang. console input) z kolei pozwala odczytywać informację wpisaną przez użytkownika z klawiatury. Wpisz poniższy program:
#include <iostream>
int main()
{
std::cout << "Witaj w programie C++" << std::endl;
return 0;
}
|
Po uruchomieniu zobaczymy w oknie konsoli napis:
Tutaj program w C++
Process returned 0 (0x0) execution time : 0.130 s
Press any key to continue.
<< jest operatorem przesłania danych do strumienia.
endl to tzw. manipulator powodujący przejście z wydrukiem do następnego wiersza w oknie konsoli. Dzięki niemu po napisie Tutaj program w C++ mamy jeden pusty wiersz odstępu. Zamiast manipulatora endl można w tekście umieszczać znaki końca wiersza - \n:
#include <iostream>
int main()
{
std::cout << "Witaj w programie C++\n"
"---------------------\n\n";
return 0;
}
|
Zwróć uwagę, że nazwy cout oraz endl są poprzedzone napisem std::. Jeśli go usuniesz, to program nie da się skompilować, ponieważ kompilator nie potrafi odnaleźć cout i endl. Napis std to tzw. przestrzeń nazw, w której żyją obiekty biblioteki STL. Wyobraź sobie ją jako worek z napisem std. Poza tym workiem nazwy zdefiniowanych w nim obiektów są niedostępne, o ile nie poprzedzisz je napisem std:: - wtedy kompilator będzie po prostu wiedział gdzie ich szukać. Możesz jednakże poinformować kompilator, że chcesz standardowo korzystać z danej przestrzeni nazw - do tego celu służy dyrektywa using namespace, za którą wpisujemy nazwę przestrzeni nazw. Gdy taką dyrektywę umieścisz w swoim programie, to nie będziesz musiał poprzedzać nazw cout, cin i innych z STL kwalifikatorem std:: - do duże ułatwienie. Dyrektywa using namespace std mówi po prostu kompilatorowi, że jeśli nie znajdzie danej nazwy w standardowym środowisku, to ma jej poszukać w "worku" o nazwie std. Przestrzenie nazw zmniejszają ryzyko konfliktów nazw różnych obiektów i z tego powodu znalazły się w języku C++. Uwierz nam, to dobry wynalazek.
Wpisz poniższy program:
#include <iostream>
using namespace std;
int main()
{
std::cout << "Witaj w programie C++" << endl
<< "---------------------" << endl << endl;
return 0;
}
|
Na początku programu umieszczamy zwykle krótki komentarz informujący użytkownika o przeznaczeniu danego programu, autorze i dacie utworzenia. Komentarze mamy za darmo - nie są one przenoszone do programu wynikowego i w żaden sposób nie zwiększają jego pojemności ani nie zmniejszają szybkości działania. Komentujmy zatem programy - staną się o wiele czytelniejsze nawet dla samych ich autorów - szczególnie po upływie kilku tygodni od daty utworzenia.
// Przykładowy program w C++
// (C)2010 mgr Jerzy Wałaszek
// I LO w Tarnowie
//---------------------------
#include <iostream>
using namespace std;
int main()
{
std::cout << "Witaj w programie C++" << endl
<< "---------------------" << endl << endl;
return 0;
}
|
Program w języku C++ posiada następującą strukturę:
// Przykładowy program w C++ // (C)2010 mgr Jerzy Wałaszek // I LO w Tarnowie //--------------------------- |
Komentarz | |
#include <iostream> |
Pliki nagłówkowe zawierające definicje używanych w programie struktur danych oraz funkcji bibliotecznych. | |
using namespace std; |
Jeśli wykorzystujemy elementy biblioteki STL, to wstawiamy do programu dyrektywę informującą kompilator o używanej przestrzeni nazw. | |
int main()
{
std::cout << "Witaj w programie C++" << endl
<< "---------------------" << endl << endl;
return 0;
}
|
Każdy program w języku C++ musi posiadać funkcję main(), od której rozpoczyna się wykonywanie programu. Zawartość tej funkcji określa to, co program robi. |
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe