
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2011 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2011 mgr
Jerzy Wałaszek
|
Tablica jest złożoną strukturą danych, zbudowaną z ciągu takich samych elementów. Przed pierwszym użyciem tablicy musimy ją zdefiniować:
typ nazwa[liczba_elementów];
typ - określa rodzaj informacji, którą można przechować w każdym
elemencie tablicy
nazwa - określa nazwę zmiennej będącej tablicą. Nazwę tworzymy wg
poznanych zasad.
liczba_elementów - określa, ile elementów zawiera tablica
Przykład:
int a[5]; // zmienna a jest tablicą 5-cio elementową
Elementy tablicy są przechowywane w pamięci komputera w jednym bloku obok siebie. Każdy element posiada numer, zwany indeksem. Indeks pozwala na dostęp do wybranego elementu tablicy. Indeksy w języku C++ rozpoczynają się od 0. W tablicy zdefiniowanej powyżej istnieją następujące elementy (często zwane komórkami tablicy):
a[0] a[1] a[2] a[3] a[4]
Zwróć uwagę, że w tablicy tej nie ma elementu a[5]. Popularnym błędem wśród początkujących programistów w języku C++ jest odwoływanie się do nieistniejących elementów tablicy. Jest to przyczyną trudnych do wykrycia błędów, ponieważ kompilator nie ostrzega nas, jeśli indeks przekroczy dozwoloną wartość. Jeśli program zapisuje dane do takiego nieistniejącego elementu, to faktycznie dane te mogą trafić do innej zmiennej i spowodować nieprawidłowości w pracy programu - zmienna "magicznie" zmienia swoją zawartość, mimo że program tego w niej jawnie nie zapisuje - robi to przy zapisie do nadmiarowych elementów tablicy.
Tablice stosujemy wszędzie tam, gdzie musimy przetworzyć dużą liczbę podobnych danych - np. tysiące wyników pomiarów jakiejś wielkości, ciąg liczbowy, teksty itp. Tablica różni się od zmiennej prostej tym, iż może przechowywać naraz wiele różnych wartości, a zmienna prosta tylko jedną. Dzięki indeksom możemy wyliczać w programie elementy tablicy, które będą przetwarzane.
Poniższy program tworzy tablicę 10-cio elementową (o indeksach od 0 do 9) i wypełnia ją kolejnymi wielokrotnościami liczby 3.
#include <iostream>
using namespace std;
int main()
{
int T[10],i;
// tablicę wypełniamy wielokrotnościami liczby 3
for(i = 0; i < 10; i++) T[i] = 3 * (i + 1);
// wyświetlamy zawartość tablicy
for(i = 0; i < 10; i++) cout << "T[" << i << "] = " << T[i] << endl;
return 0;
}
Zbiór liczb naturalnych bez liczby 1 składa się z dwóch rodzajów liczb:
Pierwszy rodzaj liczby to wielokrotności liczb mniejszych. Jeśli zatem ze zbioru usuniemy wielokrotności kolejnych liczb, to pozostaną w nim tylko liczby pierwsze. Na tej właśnie zasadzie działa sito Eratostenesa - przesiewa liczby wyrzucając ze zbioru ich kolejne wielokrotności.
Przykład:
Mamy zbiór liczb:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Rozpoczynamy od liczby 2. Wyrzucamy wszystkie jej wielokrotności:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Po tej operacji w zbiorze pozostaje liczba 2 oraz liczby nieparzyste. Żadna z pozostałych liczb, oprócz 2, nie dzieli się już przez 2. Teraz to samo wykonujemy z liczbą 3. Wyrzucamy ze zbioru wszystkie jej wielokrotności:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Operację kontynuujemy z pozostałymi liczbami:
2 3 4 5 6 7 8
9 10 11 12 13
14 15
16 17 18 19
20 21
22 23 24
25 26
27 28 29
30 31 32
33 34
35 36 37
38 39
40 41 42 43
44 45
46 47 48 49
50
2 3 4 5 6
7 8
9 10 11
12 13 14
15 16 17
18 19 20
21 22 23
24 25
26 27
28 29 30 31
32 33
34 35
36 37 38
39 40 41
42 43 44
45 46 47
48 49
50
...
I ostatecznie otrzymujemy zbiór, z którego usunięto wszystkie liczby złożone:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Pozostałe w zbiorze liczby są liczbami pierwszymi: 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47.
Realizując ten algorytm na komputerze musimy wybrać odpowiednią reprezentację zbioru liczb, z którego można usuwać w prosty sposób wielokrotności liczb. Użyjemy do tego celu tablicy. Poszczególne elementy tej tablicy będą reprezentowały liczby zbioru. Natomiast zawartość tych elementów będzie informacją, czy dany element pozostaje w zbiorze, czy też został z niego usunięty.
Najlepszym typem danych dla tablicy będzie typ logiczny bool. Jeśli element tablicy będzie miał wartość true, to znaczy, że reprezentowana przez jego indeks liczba znajduje się w zbiorze. Jeśli będzie miał wartość false, to ta liczba została ze zbioru usunięta. Na początku algorytmu umieszczamy true we wszystkich elementach tablicy - odpowiada to pełnemu zbiorowi liczb. Następnie do elementów, których indeksy są wielokrotnościami początkowych liczb, będziemy wpisywać false. Na końcu algorytmu wystarczy przeglądnąć tablicę i wyprowadzić indeksy tych elementów, które zachowały wartość true - nie są one wielokrotnościami żadnych wcześniejszych liczb, a zatem są liczbami pierwszymi.
Wejście:
n - określa górny kraniec przedziału <2,n>,
w którym poszukujemy liczb pierwszych
Wyjście:
Liczby pierwsze z przedziału <2,n>
Dane pomocnicze:
T[ ] - tablica o elementach logicznych, których indeksy obejmują przedział <2,n>
i - kolejne liczby, których wielokrotności
usuwamy
w - wielokrotności liczb i
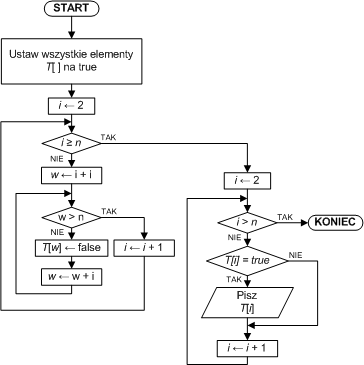
| K01: | Ustaw wszystkie elementy T[ ] na true | |
| K02: | Dla i = 2,3,...,n-1: wykonuj K03...K06 | ; rozpoczynamy od liczby 2 |
| K03: | w ← i + i | ; liczymy pierwszą wielokrotność liczby i |
| K04: | Dopóki w ≤ n: wykonuj K05...K06 | ; sprawdzamy, czy wielokrotność wpada w przedział <2,n> |
| K05: | T[w] ← false | ; jeśli tak, to usuwamy ją ze zbioru liczb |
| K06: | w ← w + i | ; obliczamy następną wielokrotność |
| K07: | Dla i = 2,3,...,n: wykonuj: Jeśli T[i] = true, to pisz i |
; przeglądamy tablicę T[ ], wypisując indeksy,
dla których ; komórki zachowały true |
| K11: | Zakończ |
Na podstawie algorytmu napisz pierwszą wersję programu
Algorytm na ślepo usuwa wszystkie wielokrotności kolejnych liczb w zbiorze. Tymczasem nie jest to konieczne. Np. liczba 2 usunęła ze zbioru wszystkie liczby parzyste za wyjątkiem siebie. Zatem w zbiorze nie ma już liczb 4, 6, 8 itd. Nie ma też wielokrotności żadnej liczby parzystej, która sama jest parzysta. Podobnie liczba 3 usunęła wszystkie wielokrotności podzielne przez 3: 6 9 12 15 itd. Nasuwa się spostrzeżenie, że wielokrotności danej liczby mogą występować w zbiorze, jeśli ta liczba nie została wcześniej usunięta. Jeśli ją usunięto, to również usunięto wszystkie jej wielokrotności. Zatem wykonanie pętli usuwającej wielokrotności powinniśmy uzależnić od tego, czy liczba i jest w zbiorze. Zmiana jest niewielka, a zysk duży:
Zmodyfikuj program, aby uwzględniał to spostrzeżenie.
Kolejne usprawnienie będzie dotyczyło pierwszej usuwanej ze zbioru wielokrotności. Obecnie jest to:
w = i + i
Rozważmy:
i = 3. Wielokrotność 6 jest podzielna przez 2 i została już
usunięta wcześniej ze zbioru. Pierwszą nieusuniętą wielokrotnością jest 9, czyli
32.
i = 5. Wielokrotności już usunięte to: 10, 15, 20. Pierwsza
nieusunięta wielokrotność to 25, czyli 52.
i = 7. Wielokrotności już usunięte to: 14, 21, 28, 35, 42. Pierwsza
nieusunięta wielokrotność to 49, czyli 72.
Z podanych przykładów widzimy jasno, że pierwszą wielokrotnością, od której należy rozpocząć usuwanie jest i2. Powód jest bardzo prosty. Mniejsze wielokrotności rozkładają się na dwa czynniki, z których jednym jest i, a drugim liczba mniejsza od i. Skoro tak, to ta mniejsza liczba już wcześniej usunęła taką wielokrotność.
Zatem w programie zmieniamy:
for(w = i + i; ...
na
for(w = i * i; ...
Skoro pierwszą usuwaną wielokrotnością jest i2, to gdy i przekroczy wartość pierwiastka z n, wielokrotność ta znajdzie się poza przedziałem <2,n>. Zatem wystarczy, aby i przebiegało wartości od 2 do pierwiastka z n.
Zadanie
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe