
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2010 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2010 mgr
Jerzy Wałaszek
|
Pomoce:
Instalacja Code Blocks i
tworzenie projektu aplikacji konsoli.
System uzupełnień do podstawy - U2
Wprowadzenie do języka C++, strumienie i zmienne
Komputer podejmuje decyzje
Pętle warunkowe
Pętla iteracyjna
Wprowadzenie do algorytmów, algorytm Euklidesa
Generacja liczb pierwszych przez sprawdzanie podzielności
Zbiór liczb naturalnych bez liczby 1 składa się z dwóch rodzajów liczb:
Liczb złożonych, które są podzielne przez liczby mniejsze z tego zbioru.
Liczb pierwszych, które nie są podzielne przez liczby mniejsze z tego zbioru.
Pierwszy rodzaj liczby to wielokrotności liczb mniejszych. Jeśli zatem ze zbioru usuniemy wielokrotności kolejnych liczb, to pozostaną w nim tylko liczby pierwsze. Na tej właśnie zasadzie działa sito Eratostenesa - przesiewa liczby wyrzucając ze zbioru ich kolejne wielokrotności.
Przykład:
Mamy zbiór liczb:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Rozpoczynamy od liczby 2. Wyrzucamy wszystkie jej wielokrotności:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Po tej operacji w zbiorze pozostaje liczba 2 oraz liczby nieparzyste. Żadna z pozostałych liczb, oprócz 2, nie dzieli się już przez 2. Teraz to samo wykonujemy z liczbą 3. Wyrzucamy ze zbioru wszystkie jej wielokrotności:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Operację kontynuujemy z pozostałymi liczbami:
2 3 4 5 6 7 8
9 10 11 12 13
14 15
16 17 18 19
20 21
22 23 24
25 26
27 28 29
30 31 32
33 34
35 36 37
38 39
40 41 42 43
44 45
46 47 48 49
50
2 3 4 5 6
7 8
9 10 11
12 13 14
15 16 17
18 19 20
21 22 23
24 25
26 27
28 29 30 31
32 33
34 35
36 37 38
39 40 41
42 43 44
45 46 47
48 49
50
...
I ostatecznie otrzymujemy zbiór, z którego usunięto wszystkie liczby złożone:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Pozostałe w zbiorze liczby są liczbami pierwszymi: 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47.
Realizując ten algorytm na komputerze musimy wybrać odpowiednią reprezentację zbioru liczb, z którego można usuwać w prosty sposób wielokrotności liczb. Użyjemy do tego celu tablicy. Poszczególne elementy tej tablicy będą reprezentowały liczby zbioru. Natomiast zawartość tych elementów będzie informacją, czy dany element pozostaje w zbiorze, czy też został z niego usunięty.
Najlepszym typem danych dla tablicy będzie typ logiczny bool. Jeśli element tablicy będzie miał wartość true, to znaczy, że reprezentowana przez jego indeks liczba znajduje się w zbiorze. Jeśli będzie miał wartość false, to ta liczba została ze zbioru usunięta. Na początku algorytmu umieszczamy true we wszystkich elementach tablicy - odpowiada to pełnemu zbiorowi liczb. Następnie do elementów, których indeksy są wielokrotnościami początkowych liczb, będziemy wpisywać false. Na końcu algorytmu wystarczy przeglądnąć tablicę i wyprowadzić indeksy tych elementów, które zachowały wartość true - nie są one wielokrotnościami żadnych wcześniejszych liczb, a zatem są liczbami pierwszymi.
Wejście:
n - określa górny kraniec
przedziału <2,n>, w którym poszukujemy liczb pierwszych
Wyjście:
Liczby pierwsze z przedziału <2,n>
Dane pomocnicze:
T[ ] - tablica o elementach logicznych, których indeksy obejmują przedział <2,n>
i - kolejne liczby, których
wielokrotności usuwamy
w - wielokrotności liczb i
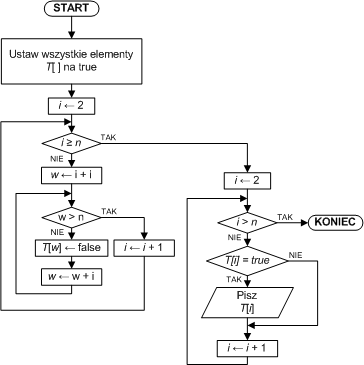
| Krok 1: | Ustaw wszystkie elementy T[ ] na true | |
| Krok 2: | i ← 2 | ; rozpoczynamy od liczby 2 |
| Krok 3: | Jeśli i ≥ n, to idź do kroku 11 | ; sprawdzamy, czy liczby osiągnęły koniec przedziału <2,n> |
| Krok 4: | w ← i + i | ; liczymy pierwszą wielokrotność liczby i |
| Krok 5: | Jeśli w > n, to idź do kroku 9 | ; sprawdzamy, czy wielokrotność wpada w przedział <2,n> |
| Krok 6: | T[w] ← false | ; jeśli tak, to usuwamy ją ze zbioru liczb |
| Krok 7: | w ← w + i | ; obliczamy następną wielokrotność |
| Krok 8: | Idź do kroku 5 | ; i kontynuujemy usuwanie wielokrotności |
| Krok 9: | i ← i + 1 | ; wyznaczamy następną liczbę |
| Krok 10: | Idź do kroku 3 | ; i kontynuujemy |
| Krok 11: | i ← 2 | ; przeglądamy tablicę T[ ] |
| Krok 12: | Jeśli i > n. to zakończ | |
| Krok 13: | Jeśli T[i] = true, to pisz i | ; wyprowadzamy liczby, które pozostały w T[ ] |
| Krok 14: | i ← i + 1 | |
| Krok 15: | Idź do kroku 12 |
// Sito Eratostenesa - wersja 1
// (C)2010 I LO w Tarnowie
//------------------------
#include <iostream>
using namespace std;
const unsigned N = 1000; // definiuje koniec przedziału <2,N>
int main()
{
bool T[N+1]; // tablica musi obejmować indeksy od 2 do N
unsigned i,w;
// ustawiamy wszystkie elementy T[] na true
for(i = 2; i <= N; i++) T[i] = true;
// eliminujemy w T[] wielokrotności
for(i = 2; i < N; i++)
for(w = i + i; w <= N; w += i) T[w] = false;
// wyświetlamy indeksy elementów pozostawionych w T[]
for(i = 2; i <= N; i++)
if(T[i]) cout << i << " ";
cout << endl << "--- KONIEC ---\n\n";
return 0;
}
|
Teraz, gdy podstawowa wersja algorytmu działa, zastanowimy się, jak go ulepszyć. Program na ślepo usuwa wszystkie wielokrotności kolejnych liczb w zbiorze. Tymczasem nie jest to konieczne. Np. liczba 2 usunęła ze zbioru wszystkie liczby parzyste za wyjątkiem siebie. Zatem w zbiorze nie ma już liczb 4, 6, 8 itd. Nie ma też wielokrotności żadnej liczby parzystej, która sama jest parzysta. Podobnie liczba 3 usunęła wszystkie wielokrotności podzielne przez 3: 6 9 12 15 itd. Nasuwa się spostrzeżenie, że wielokrotności danej liczby mogą występować w zbiorze, jeśli ta liczba nie została wcześniej usunięta. Jeśli ją usunięto, to również usunięto wszystkie jej wielokrotności. Zatem wykonanie pętli usuwającej wielokrotności powinniśmy uzależnić od tego, czy liczba i jest w zbiorze. Zmiana jest niewielka, a zysk duży:
// Sito Eratostenesa - wersja 2
// (C)2010 I LO w Tarnowie
//------------------------
#include <iostream>
using namespace std;
const unsigned N = 1000; // definiuje koniec przedziału <2,N>
int main()
{
bool T[N+1]; // tablica musi obejmować indeksy od 2 do N
unsigned i,w;
// ustawiamy wszystkie elementy T[] na true
for(i = 2; i <= N; i++) T[i] = true;
// eliminujemy w T[] wielokrotności
for(i = 2; i < N; i++)
if(T[i]) for(w = i + i; w <= N; w += i) T[w] = false;
// wyświetlamy indeksy elementów pozostawionych w T[]
for(i = 2; i <= N; i++)
if(T[i]) cout << i << " ";
cout << endl << "--- KONIEC ---\n\n";
return 0;
}
|
Kolejne usprawnienie będzie dotyczyło pierwszej usuwanej ze zbioru wielokrotności. Obecnie jest to:
w = i + i
Rozważmy:
i = 3. Wielokrotność 6 jest podzielna przez 2 i
została już usunięta wcześniej ze zbioru. Pierwszą nieusuniętą wielokrotnością
jest 9, czyli 32.
i = 5. Wielokrotności już usunięte to: 10, 15, 20. Pierwsza
nieusunięta wielokrotność to 25, czyli 52.
i = 7. Wielokrotności już usunięte to: 14, 21, 28, 35, 42. Pierwsza
nieusunięta wielokrotność to 49, czyli 72.
Z podanych przykładów widzimy jasno, że pierwszą wielokrotnością, od której należy rozpocząć usuwanie jest i2. Powód jest bardzo prosty. Mniejsze wielokrotności rozkładają się na dwa czynniki, z których jednym jest i, a drugim liczba mniejsza od i. Skoro tak, to ta mniejsza liczba już wcześniej usunęła taką wielokrotność.
Zatem w programie zmieniamy:
for(w = i + i; ...
na
for(w = i * i; ...
// Sito Eratostenesa - wersja 3
// (C)2010 I LO w Tarnowie
//------------------------
#include <iostream>
using namespace std;
const unsigned N = 1000; // definiuje koniec przedziału <2,N>
int main()
{
bool T[N+1]; // tablica musi obejmować indeksy od 2 do N
unsigned i,w;
// ustawiamy wszystkie elementy T[] na true
for(i = 2; i <= N; i++) T[i] = true;
// eliminujemy w T[] wielokrotności
for(i = 2; i < N; i++)
if(T[i]) for(w = i * i; w <= N; w += i) T[w] = false;
// wyświetlamy indeksy elementów pozostawionych w T[]
for(i = 2; i <= N; i++)
if(T[i]) cout << i << " ";
cout << endl << "--- KONIEC ---\n\n";
return 0;
}
|
Skoro pierwszą usuwaną wielokrotnością jest i2, to gdy i przekroczy wartość pierwiastka z n, wielokrotność ta znajdzie się poza przedziałem <2,n>. Zatem wystarczy, aby i przebiegało wartości od 2 do pierwiastka z n.
// Sito Eratostenesa - wersja 4
// (C)2010 I LO w Tarnowie
//------------------------
#include <iostream>
#include <cmath>
using namespace std;
const unsigned N = 1000; // definiuje koniec przedziału <2,N>
int main()
{
bool T[N+1]; // tablica musi obejmować indeksy od 2 do N
unsigned i,w,g;
// ustawiamy wszystkie elementy T[] na true
for(i = 2; i <= N; i++) T[i] = true;
// eliminujemy w T[] wielokrotności
g = sqrt(N);
for(i = 2; i <= g; i++)
if(T[i]) for(w = i * i; w <= N; w += i) T[w] = false;
// wyświetlamy indeksy elementów pozostawionych w T[]
for(i = 2; i <= N; i++)
if(T[i]) cout << i << " ";
cout << endl << "--- KONIEC ---\n\n";
return 0;
}
|
Sito Eratostenesa można dalej optymalizować, ale zadanie to pozostawiam do wykonania dla zdolniejszych uczniów informatyki. W każdym razie jest to bardzo szybki algorytm, który w danym zbiorze kolejnych liczb naturalnych wyznacza nam wszystkie liczby pierwsze. Szybkość jest tutaj okupiona zajętą pamięcią - algorytm wyznaczania liczb pierwszych przez sprawdzanie podzielności miał bardzo małe wymagania pamięciowe, lecz działał wolno. Sito Eratostenesa działa bardzo szybko, lecz ma duże wymagania pamięciowe. Coś za coś.
UWAGA: Klasa I mat-inf pisze test z poznanych dotąd algorytmów na najbliższej lekcji.
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe