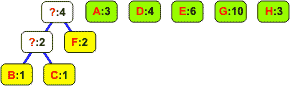Wymagane jest zapoznanie się z następującymi podrozdziałami:
OL013 - Lista.
OL014 - Algorytm wyszukiwania dwóch
najmniejszych elementów na liście.
OL015 - Drzewo binarne, algorytm
inorder.
Kompresja danych polega na takim kodowaniu informacji, aby w wyniku otrzymać jak najkrótszy ciąg bitów. Algorytm Huffmana realizuje zadanie kompresji tworząc bezprzystankowe kody binarne, gdzie symbole występujące najczęściej w kodowanej informacji otrzymują kody najkrótsze, a symbole występujące rzadziej otrzymują kody dłuższe.
Dla zobrazowania zasady działania algorytmu Huffmana załóżmy, iż mamy skompresować tekst zawierający 8 symboli A, B, C, D, E, F, G i H:
EAEACDGDGEGGFGDFGHGAGGBEEEDGHH
Jeśli zastosujemy normalne kodowanie binarne, to każdemu z 8 symboli musimy przypisać kod 3 bitowy, np:
A - 000, B - 001, C - 010, D - 011, E - 100, F - 101, G - 110, H - 111
Wtedy powyższy napis można przedstawić w postaci strumienia bitów:
100000100000010011110011110100110110101110011101110111110000110110001100100100011110111111
Jak łatwo policzyć, strumień ten zawiera 30 znaków x 3 bity na znak = 90 bitów.
Policzmy teraz ilość wystąpień każdego znaku w tekście. Otrzymamy następujące wartości:
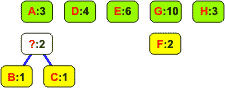
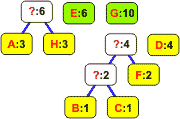
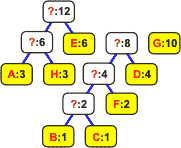
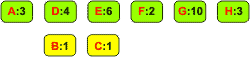
Znak A B C D E F G H Częstość 3 1 1 4 6 2 10 3
Ze znaku i jego częstości tworzymy węzeł-liść drzewa binarnego. Węzły nie są jeszcze połączone w drzewo. Umieszczamy je na liście dwukierunkowej:
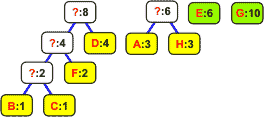
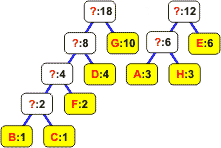
Z listy wybieramy dwa węzły o najmniejszych częstościach występowania:
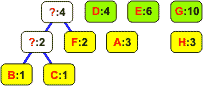
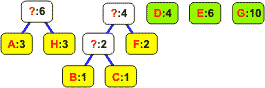
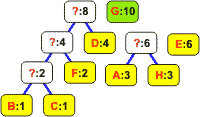
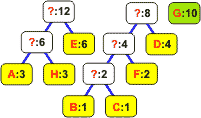
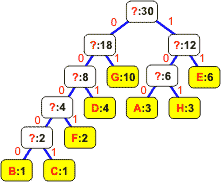
Wyjęte z listy węzły łączymy w drzewo binarne. Korzeń staje się nowym elementem, którego częstość jest równa sumie częstości obu liści. Korzeń wstawiamy z powrotem na listę: