|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2024 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2024 mgr Jerzy Wałaszek
|
ProblemW łańcuchu s należy wyznaczyć wszystkie wystąpienia
Tutaj znajdziesz
oryginalny tekst R.S.Boyera oraz |
Uproszczony algorytm Boyera-Moore'a
reaguje tylko na niezgodność znaku wykorzystując wyliczoną wcześniej tablicę
Last do znalezienia przesunięcia okna wzorca
p w obrębie
przeszukiwanego
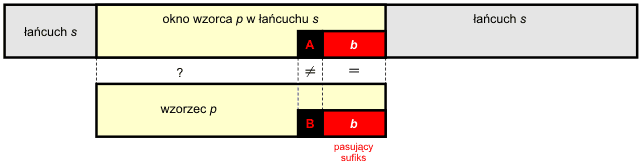
Pełna wersja algorytmu nie wyrzuca do kosza tej informacji. Rozważmy możliwe dwa przypadki:
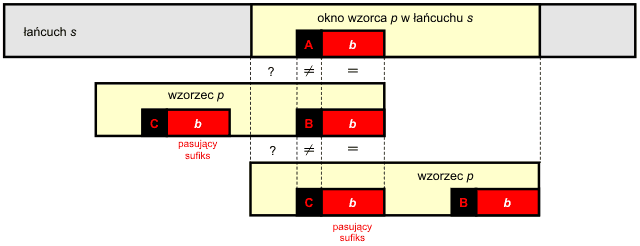
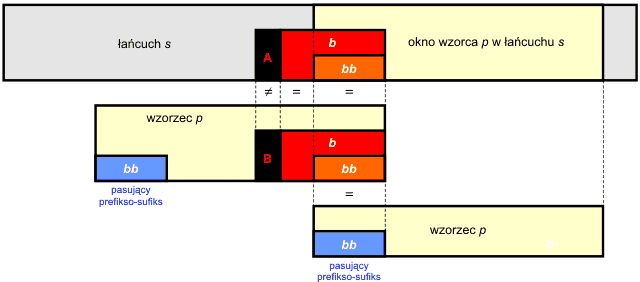
Jeśli prefikso-sufiks jest pusty, to okno wzorca można przesunąć o całą długość wzorca beż żadnej straty dla wyników poszukiwań. W efekcie uzyskujemy bardzo ciekawą własność algorytmu Boyera-Moore'a – im wzorzec p jest dłuższy, tym szybciej przebiega wyszukiwanie, ponieważ algorytm przeskakuje większe partie tekstu.
Opisana w tych dwóch punktach strategia postępowania nosi nazwę heurystyki pasującego sufiksu (ang. good suffix heuristics). W wyniku jej zastosowania otrzymujemy przesunięcie okna wzorca bez pomijania możliwych wystąpień w przeszukiwanym tekście.
Pełny algorytm Boyera-Moore'a wykorzystuje obie heurystyki – nie pasującego znaku (opisana w poprzednim rozdziale) oraz pasującego sufiksu, a wynikowe przesunięcie okna wzorca jest większym z tych dwóch wyliczonych przesunięć.
Do wyznaczenia przesunięcia w przypadku heurystyki pasującego sufiksu będzie nam potrzebna tablica BMNext zawierająca wartości przesunięć dla poszczególnych sufiksów wzorca (tablica ta jest niejako odwróceniem tablicy KMPNext obecnej w algorytmie KMP). Wyznaczamy ją w dwóch etapach.
Ten etap jest bardzo podobny do przetwarzania wzorca w algorytmie KMP. Pasujący sufiks bb jest prefikso-sufiksem pewnego sufiksu b wzorca p:
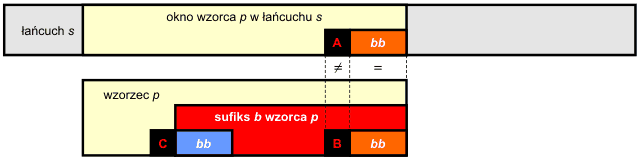
Musimy ustalić prefikso-sufiksy sufiksów wzorca, jednakże w porównaniu z algorytmem KMP będzie obowiązywało odwrotne odwzorowanie pomiędzy prefikso-sufiksem a najkrótszym sufiksem zawierającym ten prefikso-sufiks. Jednocześnie musimy zagwarantować, iż dany prefikso-sufiks nie może być rozszerzalny w lewo (patrz znaki B i C we wzorcu) przez znak B, który spowodował niezgodność z przeszukiwanym tekstem. W przeciwnym razie po przesunięciu okna wzorca otrzymalibyśmy natychmiastową niezgodność, ponieważ w tym samym miejscu znów znalazłby się niezgodny znak B.
W etapie 1 obliczana jest pomocnicza tablica П o elementach indeksowanych od 0 do m (m = |p|). Element П[i] zawiera początkową pozycję maksymalnego prefikso-sufiksu sufiksu wzorca rozpoczynającego się na pozycji i-tej.
Przykład:
Dla wzorca ABBABBBA tablicę П wyznaczymy następująco:
| Tworzenie tablicy П | Opis |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . . . . 9 |
Na pozycji m = 8 jest sufiks
pusty, Ponieważ nie posiada on |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . . . 8 9 |
Na pozycji 7 jest sufiks
A. Posiada on |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . . 8 8 9 |
Sufiks BA
również posiada p |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . 8 8 8 9 |
Sufiks BBA
posiada p |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . 8 8 8 8 9 |
Sufiks BBBA
posiada p |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . 7 8 8 8 8 9 |
Sufiks ABBBA
posiada |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . 6 7 8 8 8 8 9 |
Sufiks BABBBA
rozszerza p |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . 5 6 7 8 8 8 8 9 |
Sufiks BBABBBA
znów rozszerza |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: 7 5 6 7 8 8 8 8 9 |
Sufiks ABBABBBA
redukuje |
Tablica П służy do wstępnej generacji właściwej
BMNext[pozycja prefikso-sufiksu]o ile nie zawiera on już jakiejś wartości
BMNext[pozycja prefikso-sufiksu] = pozycja prefikso-sufiksu – pozycja sufiksu
W efekcie otrzymujemy wartość przesunięcie okna wzorca p w
| Tworzenie tablic П i BMNext | Opis |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . . . . 9 BMNext: 0 0 0 0 0 0 0 0 0 |
Inicjujemy
|
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . . . 8 9 BMNext: 0 0 0 0 0 0 0 0 1 |
Na pozycji 7 jest
sufiks A. Posiada on prefikso-sufiks pusty
rozpoczynający się na pozycji 8. Prefikso-sufiks tego sufiksu nie
daje się rozszerzyć w lewo. |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . . 8 8 9 BMNext: 0 0 0 0 0 0 0 0 1 |
Sufiks
BA
również posiada |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . . 8 8 8 9 BMNext: 0 0 0 0 0 0 0 0 1 |
Sufiks
BBA posiada Tablicy BMNext nie modyfikujemy. |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . . 8 8 8 8 9 BMNext: 0 0 0 0 0 0 0 0 1 |
Sufiks
BBBA
posiada Tablicy BMNext nie modyfikujemy. |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . . 7 8 8 8 8 9 BMNext: 0 0 0 0 0 0 0 0 1 |
Sufiks
ABBBA
posiada Tablicy BMNext nie modyfikujemy. |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . . 6 7 8 8 8 8 9 BMNext: 0 0 0 0 0 0 0 0 1 |
Sufiks
BABBBA
posiada Tablicy BMNext nie modyfikujemy. |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: . 5 6 7 8 8 8 8 9 BMNext: 0 0 0 0 0 4 0 0 1 |
Sufiks
BBABBBA
posiada |
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: 7 5 6 7 8 8 8 8 9 BMNext: 0 0 0 0 0 4 0 0 1 |
Sufiks
ABBABBBA
redukuje |
K01: m ← |p| ; wyznaczamy długość wzorca K02: Dla i = 0,1,…,m: ; zerujemy elementy tablicy BMNext wykonuj BMNext[i] ← 0 K03: i ← m ; ustawiamy indeks elementów dla tablicy П K04: b ← m + 1 ; wstępne położenie prefikso-sufiksu poza pustym sufiksem K05: П[i] ← b ; inicjujemy ostatni element tablicy K06: Dopóki i > 0: ; pętla wypełniająca komórki tablicy П wykonuj kroki K07…K12 K07: Dopóki (b ≤ m)(p[i-1] ≠ p[b-1]): ; pętla obsługuje sytuację, wykonuj kroki K08…K09 ; gdy bieżący prefikso-sufiks istnieje i nie ; daje się rozszerzyć w lewo. K08: Jeśli BMNext[b] = 0, ; odnotowujemy taki prefikso-sufiks w tablicy to BMNext[b] ← b - i ; BMNext o ile nie został już odnotowany przez ; wcześniejszy sufiks. K09: b ← П[b] ; w b umieszczamy położenie prefikso-sufiksu wewnętrznego ; i kontynuujemy pętlę K07 K10: b ← b - 1 ; prefikso-sufiks jest rozszerzalny lub nie istnieje K11: i ← i - 1 ; przesuwamy się na kolejną pozycję w lewo. K12: П[i] ← b ; położenie prefikso-sufiksu zapamiętujemy w tablicy П K13: Zakończ
Po zakończeniu etapu 1 otrzymujemy wypełnioną
Dlatego wyznaczymy teraz dla każdego sufiksu najdłuższy
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: 7 5 6 7 8 8 8 8 9 BMNext: 0 0 0 0 0 4 0 0 1 |
Wartość ta zostaje umieszczona w kolejnych, wolnych elementach
tablicy BMNext. Jednakże gdy sufiks wzorca stanie się krótszy od
i: 0 1 2 3 4 5 6 7 8 p: A B B A B B B A П: 7 5 6 7 8 8 8 8 9 BMNext: 7 7 7 7 7 4 7 7 1 |
BMNext : kompletna
t
K01: b ← П[0] ; najdłuższy prefikso-sufiks K02: Dla i = 0,1,…,m: ; indeksujemy kolejne komórki tablicy BMNext wykonuj kroki K03…K04 K03: Jeśli BMNext[i] = 0, ; w wolnych elementach umieszczamy to BMNext[i] ← b ; położenie prefikso-sufiksu K04: Jeśli i = b, ; jeśli sufiks nie mieści prefikso-sufiksu, to b ← П[b] ; to bierzemy kolejny prefikso-sufiks K05: Zakończ
Algorytm BM składa się z etapu przetwarzania wzorca, w którym wyznacza się dwie tablice:
Po wyznaczeniu tych tablic następuje właściwy etap wyszukiwania.
K01: Wyznacz tablicę Last ; wyznaczamy ostatnie położenia znaków alfabetu we wzorcu ; dla p, zp i zk K02: Wyznacz tablicę BMNext ; wyznaczamy przesunięcia okna wzorca dla pasujących ; sufiksów dla p K03: pp ← -1 ; ustawiamy pozycję wzorca na "nie znaleziono" K04: i ← 0 ; okno wzorca umieszczamy na początku łańcucha s K05: Dopóki i ≤ n - m, ; dopóki okno wzorca mieści się wewnątrz łańcucha wykonuj kroki K06…K13 K06: j ← m - 1 ; porównywanie znaków wzorca z łańcuchem rozpoczynamy od końca K07: Dopóki (j > -1)
|
Uwaga: Zanim uruchomisz program, przeczytaj wstęp do tego artykułu, w którym wyjaśniamy funkcje tych programów oraz sposób korzystania z nich. |
| Program generuje 79 znakowy łańcuch zbudowany z pseudolosowych kombinacji liter A i B oraz 5 znakowy wzorzec wg tego samego schematu. Następnie program wyznacza tablicę długości maksymalnych prefikso-sufiksów kolejnych prefiksów wzorca i wykorzystuje ją do znalezienia wszystkich wystąpień wzorca w łańcuchu. |
Pascal// Wyszukiwanie wzorca pełnym algorytmem BM
// Data: 10.06.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------------------
program prg;
uses Math;
const
N = 79; // długość łańcucha s
M = 5; // długość wzorca p
zp = 65; // kod pierwszego znaku alfabetu
zk = 66; // kod ostatniego znaku alfabetu
var
s, p : ansistring;
Last : array [0..zk-zp] of integer;
BMNext, Pi : array [0..M] of integer;
b, i, j, pp : integer;
begin
randomize;
// generujemy łańcuch s
s := '';
for i := 1 to N do
s := s + chr(zp+random(zk-zp+1));
// generujemy wzorzec p
p := '';
for i := 1 to M do
p := p+chr(zp+random(zk-zp+1));
// wypisujemy wzorzec
writeln(p);
// wypisujemy łańcuch
writeln(s);
// dla wzorca obliczamy tablicę Last
for i := 0 to zk-zp do Last[i] := 0;
for i := 1 to M do Last[ord(p[i])- zp] := i;
// Etap I obliczania tablicy BMNext
for i := 0 to M do BMNext[i] := 0;
i := M; b := M+1; Pi[i] := b;
while i > 0 do
begin
while(b <= M) and (p[i] <> p[b]) do
begin
if BMNext[b] = 0 then BMNext[b] := b-i;
b := Pi[b];
end;
dec(b); dec(i); Pi[i] := b;
end;
// Etap II obliczania tablicy BMNext
b := Pi[0];
for i := 0 to M do
begin
if BMNext[i] = 0 then BMNext[i] := b;
if i = b then b := Pi[b];
end;
// szukamy pozycji wzorca w łańcuchu
pp := 1; i := 1;
while i <= N-M+1 do
begin
j := M;
while(j > 0) and (p[j] = s[i+j-1]) do
dec(j);
if j = 0 then
begin
while pp < i do
begin
write(' '); inc(pp);
end;
write('^'); inc(pp);
inc(i, BMNext[0]);
end
else
inc(i, max(BMNext[j],j-Last[ord(s[i+j-1])-zp]));
end;
writeln;
end. |
// Wyszukiwanie wzorca pełnym algorytmem BM
// Data: 10.06.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------------------
#include <iostream>
#include <string>
#include <cstdlib>
#include <ctime>
using namespace std;
const int N = 79; // długość łańcucha s
const int M = 5; // długość wzorca p
const int zp = 65; // kod pierwszego znaku alfabetu
const int zk = 66; // kod ostatniego znaku alfabetu
int main()
{
string s, p;
int Last[zk-zp+1], BMNext[M+1], Pi[M+1], b, i, j, pp;
srand(time(NULL));
// generujemy łańcuch s
s = "";
for(i = 0; i < N; i++)
s += zp + rand() % (zk-zp+1);
// generujemy wzorzec p
p = "";
for(i = 0; i < M; i++)
p += zp + rand() % (zk-zp+1);
// wypisujemy wzorzec
cout << p << endl;
// wypisujemy łańcuch
cout << s << endl;
// dla wzorca obliczamy tablicę Last
for(i = 0; i <= zk-zp; i++)
Last[i] = -1;
for(i = 0; i < M; i++)
Last[p[i]-zp] = i;
// Etap I obliczania tablicy BMNext
for(i = 0; i <= M; i++)
BMNext[i] = 0;
i = M; b = M+1; Pi[i] = b;
while(i > 0)
{
while((b <= M) && (p[i-1] != p[b-1]))
{
if(BMNext[b] == 0) BMNext[b] = b-i;
b = Pi[b];
}
Pi[--i] = --b;
}
// Etap II obliczania tablicy BMNext
b = Pi[0];
for(i = 0; i <= M; i++)
{
if(BMNext[i] == 0) BMNext[i] = b;
if(i == b) b = Pi[b];
}
// szukamy pozycji wzorca w łańcuchu
pp = i = 0;
while(i <= N-M)
{
j = M-1;
while((j > -1) && (p[j] == s[i+j])) j--;
if(j == -1)
{
while(pp < i)
{
cout << " "; pp++;
}
cout << "^"; pp++;
i += BMNext[0];
}
else i += max(BMNext[j+1],j-Last[s[i+j]-zp]);
}
cout << endl;
return 0;
} |
Basic' Wyszukiwanie wzorca pełnym algorytmem BM
' Data: 10.06.2008
' (C)2020 mgr Jerzy Wałaszek
'-----------------------------------------
Const N = 79 ' długość łańcucha s
Const M = 5 ' długość wzorca p
Const zp = 65 ' kod pierwszego znaku
Const zk = 66 ' kod ostatniego znaku
' Funkcja wyznacza większą z dwóch liczb
'---------------------------------------
Function max (Byval a As Integer,_
Byval b As Integer)_
As Integer
If a > b Then max = a Else max = b
End Function
Dim As String s, p
Dim As Integer Last(zk-zp), BMNext(M), Pi(M)
Dim As Integer b, i, j, pp
Randomize
' generujemy łańcuch s
s = ""
For i = 1 To N
s += Chr(zp+Cint(Rnd*(zk-zp)))
Next
' generujemy wzorzec p
p = ""
For i = 1 To M
p += Chr(zp+Cint(Rnd*(zk-zp)))
Next
' wypisujemy wzorzec
Print p
' wypisujemy łańcuch
Print s
' dla wzorca obliczamy tablicę Last
For i = 0 To zk-zp
Last(i) = 0
Next
For i = 1 To M
Last(Asc(Mid(p,i,1))- zp) = i
Next
' Etap I obliczania tablicy BMNext
For i = 0 To M: BMNext(i) = 0: Next
i = M: b = M + 1: Pi(i) = b
While i > 0
While(b <= M) And_
(Mid(p,i,1) <> Mid(p,b,1))
If BMNext(b) = 0 Then BMNext(b) = b-i
b = Pi(b)
Wend
b -= 1: i -= 1: Pi(i) = b
Wend
' Etap II obliczania tablicy BMNext
b = Pi(0)
For i = 0 To M
If BMNext(i) = 0 Then BMNext(i) = b
If i = b Then b = Pi(b)
Next
' szukamy pozycji wzorca w łańcuchu
pp = 1: i = 1
While i <= N - M + 1
j = M
While (j > 0) And_
(Mid(p,j,1) = Mid(s,i+j-1,1))
j -= 1
Wend
If j = 0 Then
While pp < i
Print " ";: pp += 1
Wend
Print "^";: pp += 1
i += BMNext(0)
Else
i += max(BMNext(j),_
j-Last(Asc(Mid(s,i+j-1,1))-zp))
End If
Wend
Print
End |
Python
(dodatek)# Wyszukiwanie wzorca pełnym algorytmem BM
# Data: 10.03.2024
# (C)2024 mgr Jerzy Wałaszek
#-----------------------------------------
import random
N = 79 # długość łańcucha s
M = 5 # długość wzorca p
zp = 65 # kod pierwszego znaku alfabetu
zk = 66 # kod ostatniego znaku alfabetu
# generujemy łańcuch s
s = ""
for i in range(N):
s += chr(random.randrange(zp, zk+1))
# generujemy wzorzec p
p = ""
for i in range(M):
p += chr(random.randrange(zp, zk+1))
# wypisujemy wzorzec
print(p)
# wypisujemy łańcuch
print(s)
# dla wzorca obliczamy tablicę Last
Last = [-1] * (zk-zp+1)
for i in range(M):
Last[ord(p[i])-zp] = i
# Etap I obliczania tablicy BMNext
BMNext = [0] * (M + 1)
Pi = [0] * (M + 1)
i = M
b = M + 1
Pi[i] = b
while i > 0:
while (b <= M) and (p[i-1] != p[b-1]):
if BMNext[b] == 0:
BMNext[b] = b - i
b = Pi[b]
i -= 1
b -= 1
Pi[i] = b
# Etap II obliczania tablicy BMNext
b = Pi[0]
for i in range(M + 1):
if BMNext[i] == 0: BMNext[i] = b
if i == b: b = Pi[b]
# szukamy pozycji wzorca w łańcuchu
pp,i = 0,0
while i <= N - M:
j = M - 1
while (j > -1) and (p[j] == s[i + j]):
j -= 1
if j == -1:
while pp < i:
print(" ", end="")
pp += 1
print("^", end="")
pp += 1
i += BMNext[0]
else:
i += max(BMNext[j+1],j-Last[ord(s[i+j])-zp])
print()
print()
|
| Wynik: |
BABAA
AABBABABAAAABBBABBAABABAABBBBBAABBAAAABABAABBABBBBBABBABBBABABBBABAABBBAABBABBA
^ ^ ^ ^
|
| Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2024 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone
pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
