|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2024 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2024 mgr Jerzy Wałaszek
|
ProblemW łańcuchu s należy wyznaczyć wszystkie
wystąpienia |
Profesor Donald Knuth przeanalizował dokładnie
algorytm
Morrisa-Pratta i zauważył, iż można go jeszcze
ulepszyć. Ulepszenie to polega na nieco innym sposobie wyznaczania
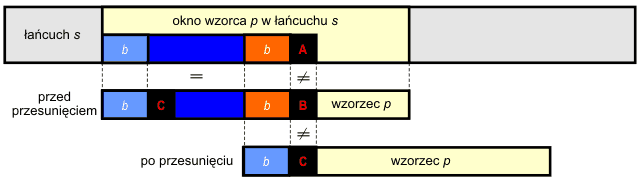
W celu uniknięcia po przesunięciu okna wzorca natychmiastowej niezgodności
musimy dodatkowo zażądać, aby
Tablicę szerokości
Przykład:
Wyznaczymy tablicę KMPNext dla wzorca ABACABAB – identyczny wzorzec jak w rozdziale o tworzeniu tablicy Π.
| Lp. | Tworzona tablica Next | Opis |
| 1. |
s : A B A C A B A B i : |
Element KMPNext[0] jest zawsze |
| 2. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0 ? ? ? ? ? ? ? |
Prefiks jednoznakowy
A
posiada zawsze |
| 3. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 ? ? ? ? ? ? |
Prefikso-sufiks prefiksu dwuznakowego
AB ma |
| 4. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 1 ? ? ? ? ? |
Prefikso-sufiks prefiksu
ABA ma szerokość 1
(obejmuje pierwszą i ostatnią literkę A).
Znak B leżący tuż za |
| 5. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 1-1 ? ? ? ? |
Prefiks
ABAC ma |
| 6. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 1-1 0 ? ? ? |
Prefiks
ABACA
posiada |
| 7. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 1-1 0-1 ? ? |
Prefiks
ABACAB
posiada |
| 8. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 1-1 0-1 3 ? |
Prefiks
ABACABA
posiada prefikso-sufiks |
| 9. |
s : A B A C A B A B i : 0 1 2 3 4 5 6 7 8 KMPNext[]:-1 0-1 1-1 0-1 3 2 |
Cały wzorzec ABACABAB posiada
|
Porównajmy tablicę Π z tablicą KMPNext:
| wzorzec | A | B | A | C | A | B | A | B | |
| indeks | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Π | -1 | 0 | 0 | 1 | 0 | 1 | 2 | 3 | 2 |
| KMPNext | -1 | 0 | -1 | 1 | -1 | 0 | -1 | 3 | 2 |
Algorytm KMP wyszukiwania wzorca wykorzystujący tablicę KMPNext jest
identyczny z algorytmem MP wykorzystującym tablicę
Π. W algorytmie KMP zastępujemy jedynie odwołania do tablicy
Π odwołaniami do tablicy KMPNext, która pozwala bardziej efektywnie wyszukiwać wystąpienia wzorców, ponieważ
pomijane są puste przebiegi. Klasa złożoności obliczeniowej jest równa O(m
+ n), gdzie m jest długością
K01: KMPNext[0] ← -1 ; na początku tablicy KMPNext wstawiamy wartownika K02: b ← -1 ; początkowo długość prefikso-sufiksu ustawiamy na -1 K03: Dla i = 1, 2, …, |s|: ; wyznaczamy długości prefikso-sufiksów wykonuj kroki K04…K06 ; dla prefiksów łańcucha s K04: Dopóki (b > -1)(s[b] ≠ s[i-1]): ; w pętli K04 szukamy prefikso-sufiksu b wykonuj b ← KMPNext[b] ; prefiksu wzorca, który da się rozszerzyć. ; Z pętli wychodzimy, jeśli natrafimy na wartownika lub prefikso-sufiks jest ; rozszerzalny. K05: b ← b + 1 ; rozszerzamy prefikso-sufiks. K06: Jeśli i = |s|
s[i] ≠ s[b], ; Jeśli następny znak wzorca różni się od to KMPNext[i] ← b, ; znaku tuż za prefikso-sufiksem, to w tablicy KMPNext inaczej KMPNext[i] ← KMPNext[b] ; umieszczamy szerokość prefikso-sufiksu. ; Inaczej w KMPNext umieszczamy zredukowaną szerokość prefikso-sufiksu K07: Zakończ
K01: Wyznacz tablicę KMPNext ; wyznaczamy tablicę maksymalnych ; prefikso-sufiksów algorytmem KMP. K02: pp ← -1 ; wstępna pozycja wzorca ustawiona na -1. K03: b ← 0 ; wstępną długość prefikso-sufiksu ustawiamy na 0. K04: Dla i = 0,1,…|s|-1: ; pętla wyznacza znaki łańcucha do wykonuj kroki K05…K10 ; porównania ze znakami wzorca. K05: Dopóki (b > -1)
|
Uwaga: Zanim uruchomisz program, przeczytaj wstęp do tego artykułu, w którym wyjaśniamy funkcje tych programów oraz sposób korzystania z nich. |
| Program generuje 79 znakowy łańcuch zbudowany z pseudolosowych kombinacji liter A i B oraz 5 znakowy wzorzec wg tego samego schematu. Następnie program wyznacza tablicę długości maksymalnych prefikso-sufiksów kolejnych prefiksów wzorca i wykorzystuje ją do znalezienia wszystkich wystąpień wzorca w łańcuchu. |
Pascal// Wyszukiwanie wzorca algorytmem KMP
// Data: 4.06.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------
program prg;
const
N = 79; // długość łańcucha s
M = 5; // długość wzorca p
var
s, p : ansistring;
KMPNext : array [0..M] of integer;
i, b, pp : integer;
begin
randomize;
// generujemy łańcuch s
s := '';
for i := 1 to N do s := s + chr(65 + random(2));
// generujemy wzorzec
p := '';
for i := 1 to M do p := p + chr(65 + random(2));
// dla wzorca obliczamy tablicę KMPNext
KMPNext[0] := -1;
b := -1;
for i := 1 to M do
begin
while(b > -1) and (p[b+1] <> p[i]) do b := KMPNext[b];
inc(b);
if(i = M) or (p[i+1] <> p[b+1]) then KMPNext[i] := b
else KMPNext[i] := KMPNext[b];
end;
// wypisujemy wzorzec p
writeln(p);
// wypisujemy łańcuch s
writeln(s);
// poszukujemy pozycji wzorca w łańcuchu
pp := 0; b := 0;
for i := 1 to N do
begin
while(b > -1) and (p[b+1] <> s[i]) do b := KMPNext[b];
inc(b);
if b = M then
begin
while pp < i - b do
begin
write(' '); inc(pp);
end;
write ('^'); inc(pp);
b := KMPNext[b];
end
end;
writeln;
end. |
// Wyszukiwanie wzorca algorytmem KMP
// Data: 4.06.2008
// (C)2020 mgr Jerzy Wałaszek
//-----------------------------
#include <iostream>
#include <string>
#include <cstdlib>
#include <ctime>
using namespace std;
const int N = 79; // długość łańcucha s
const int M = 5; // długość wzorca p
int main()
{
string s, p;
int KMPNext[M+1], i, b, pp;
srand(time(NULL));
// generujemy łańcuch s
s = "";
for(i = 0; i < N; i++)
s += 65 + rand() % 2;
// generujemy wzorzec
p = "";
for(i = 0; i < M; i++)
p += 65 + rand() % 2;
// dla wzorca obliczamy tablicę KMPNext
KMPNext[0] = b = -1;
for(i = 1; i <= M; i++)
{
while((b > -1) && (p[b] != p[i-1]))
b = KMPNext[b];
++b;
if((i == M) || (p[i] != p[b]))
KMPNext[i] = b;
else
KMPNext[i] = KMPNext[b];
}
// wypisujemy wzorzec
cout << p << endl;
// wypisujemy łańcuch s
cout << s << endl;
// poszukujemy pozycji wzorca w łańcuchu
pp = b = 0;
for(i = 0; i < N; i++)
{
while((b > -1) && (p[b] != s[i]))
b = KMPNext[b];
if(++b == M)
{
while(pp < i - b + 1)
{
cout << " "; pp++;
}
cout << "^"; pp++;
b = KMPNext[b];
}
}
cout << endl;
return 0;
} |
Basic' Wyszukiwanie wzorca algorytmem KMP
' Data: 4.06.2008
' (C)2020 mgr Jerzy Wałaszek
'-----------------------------
Const N = 79 ' długość łańcucha s
Const M = 5 ' długość wzorca p
Dim As String s, p
Dim As Integer KMPNext(M), i, b, pp
Randomize
' generujemy łańcuch s
s = ""
For i = 1 To N
s += Chr(65 + Cint(Rnd))
Next
' generujemy wzorzec
p = ""
For i = 1 To M
p += Chr(65 + Cint(Rnd))
Next
' dla wzorca obliczamy tablicę KMPNext
KMPNext(0) = -1: b = -1
For i = 1 To M
While(b > -1) And (Mid(p,b+1,1) <> Mid(p,i,1))
b = KMPNext(b)
Wend
b += 1:
if(i = M) Or (Mid(p,i+1,1) <> Mid(p,b+1,1)) Then
KMPNext(i) = b
Else
KMPNext(i) = KMPNext(b)
End If
Next
' wypisujemy wzorzec p
Print p
' wypisujemy łańcuch s
Print s
' poszukujemy pozycji wzorca w łańcuchu
pp = 0: b = 0
For i = 1 To N
While(b > -1) And (Mid(p,b+1,1) <> Mid(s,i,1))
b = KMPNext(b)
Wend
b += 1
If b = M Then
While pp < i - b
Print " ";: pp += 1
Wend
Print "^";: pp += 1
b = KMPNext(b)
End If
Next
Print
End |
Python
(dodatek)# Wyszukiwanie wzorca algorytmem KMP
# Data: 8.03.2024
# (C)2024 mgr Jerzy Wałaszek
#-----------------------------
import random
N = 79 # długość łańcucha s
M = 5 # długość wzorca p
# generujemy łańcuch s
s = ""
for i in range(N):
s += chr(random.randrange(65,67))
# generujemy wzorzec p
p = ""
for i in range(M):
p += chr(random.randrange(65,67))
# dla wzorca obliczamy tablicę KMPNext
KMPNext = [-1]
b = -1
for i in range(1,M+1):
while(b > -1) and (p[b] != p[i-1]):
b = KMPNext[b]
b += 1
if(i == M) or (p[i] != p[b]):
KMPNext.append(b)
else:
KMPNext.append(KMPNext[b])
# wypisujemy wzorzec p
print(p)
# wypisujemy łańcuch s
print(s)
# poszukujemy pozycji wzorca w łańcuchu
pp = 0
b = 0
for i in range(N):
while(b > -1) and (p[b] != s[i]):
b = KMPNext[b]
b += 1
if b == M:
while pp < i - b + 1:
print(" ", end="")
pp += 1
print("^", end="")
pp += 1
b = KMPNext[b]
print()
print()
|
| Wynik: |
BBBAB
BAAABBBABBAABAAABAAAABBBBAABABAABBABBBABAABABAAABBAABBABBAABABAABBBABBAAAAAAAAA
^ ^ ^
|
| Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2024 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone
pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
