|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
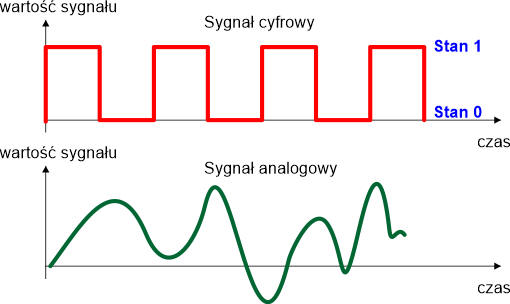
Transmisja cyfrowa wykorzystywana jest w sieciach komputerowych do przesyłania informacji w postaci bitów, co odróżnia ją od transmisji analogowej, gdzie przesyłany jest sygnał ciągły, analogowy:
Sygnał (prąd, napięcie, natężenie światła, fala radiowa) przesyłany jest w tzw. torze transmisyjnym (ang. transmission path). Zadaniem toru transmisyjnego jest przesłanie informacji cyfrowej od komputera nadawczego do komputera odbiorczego. Typowy tor transmisji danych cyfrowych składa się z następujących elementów:
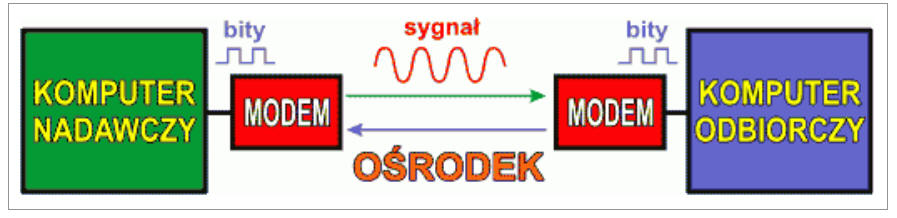
Komputer nadawczy przekazuje modemowi nadawczemu informację cyfrową do przesłania. Modem jest specjalnym urządzeniem, które informację cyfrową w postaci bitów zamienia na odpowiedni dla danego ośrodka sygnał (falę radiową, prąd elektryczny, światło lasera itp). Sygnał przenosi się (propaguje) przez ośrodek transmisyjny (przestrzeń, przewód elektryczny, światłowód itp). Po drugiej stronie toru transmisyjnego sygnał dociera do modemu odbiorczego. Modem odbiorczy odczytuje sygnał i, odpowiednio go interpretując, wydobywa z niego informację cyfrową, którą nadał modem odbiorczy. Wydobyta informacja jest przekazywana do komputera odbiorczego. Kanał transmisyjny posiada zwykle łączność w obu kierunkach. Kanałem zwrotnym komputer odbiorczy może przekazywać potwierdzenie odbioru danych - tzw. transmisja z potwierdzeniem (ang. hand shaking transmission).
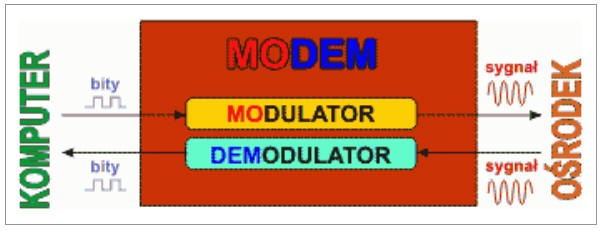
Nazwa MODEM pochodzi od nazw MODULATOR i DEMODULATOR. Modulator jest układem wewnątrz modemu, który odpowiednio kształtuje (moduluje) sygnał wysyłany do ośrodka w zależności od przesyłanej informacji cyfrowej. Sygnał ten nazywamy sygnałem nośnym (ang. carrier). Demodulator wykonuje zadanie odwrotne - odebrany z ośrodka sygnał przekształca (demoduluje) z powrotem w informację cyfrową dla komputera odbiorczego.
Słowo modulacja (ang. modulation) oznacza kształtowanie różnych parametrów sygnału do przesłania przez ośrodek za pomocą informacji cyfrowej, którą ten sygnał ma przenieść. Sygnał najczęściej ma formę zbliżoną do kształtu sinusoidy (wykres funkcji f(x) = sin(x)) i jest sygnałem okresowym (czyli takim, który powtarza się po określonym czasie). Fala sinusoidalna jest bardzo rozpowszechnionym rodzajem fali w przyrodzie. Jeśli wrzucisz do spokojnego stawu kamień, to powstałe, rozchodzące się fale będą właśnie falami sinusoidalnymi. Zobaczmy jakie parametry fali sinusoidalnej można modulować (kształtować):
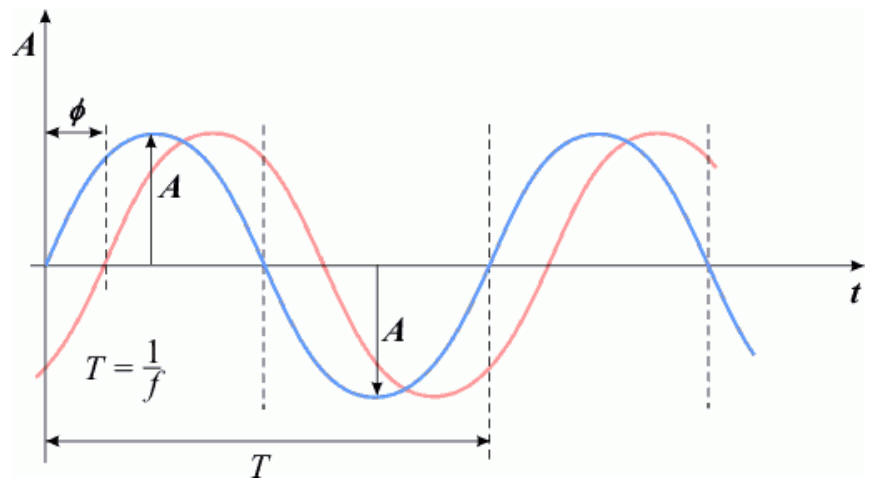
Fala sinusoidalna zmienia się w czasie odchylając się w górę i w dół od położenia naturalnego. Wartość maksymalnego odchylenia od położenia równowagi nazywamy amplitudą sygnału i oznaczamy literką A:
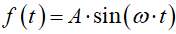 |
||
| A | – | amplituda sygnału |
| t | – | czas |
| ω | – | prędkość kątowa |
Drugim istotnym parametrem sygnału sinusoidalnego jest okres T. Jest to czas, po upływie którego fala zaczyna się powtarzać - przyjmuje te same wartości wychylenia. Okres mierzymy w sekundach. Bezpośrednio z okresem związana jest częstotliwość fali, czyli liczba okresów w ciągu jednej sekundy - oznaczana literką f. Pomiędzy okresem T a częstotliwością f zachodzi prosty związek:
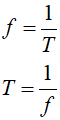 |
||
| f | – | częstotliwość |
| T | – | okres |
Jednostką częstotliwości jest Hz (Herz - od nazwiska niemieckiego pioniera techniki radiowej, Heinricha Rudolfa Herza). Np. fala, o okresie 0,2 sekundy ma częstotliwość 5 Hz, ponieważ w jednej sekundzie mieści się jej pięć okresów. Wyższe jednostki częstotliwości to:
1 kHz = 1000 Hz = 1000 okresów w ciągu jednej sekundy 1 MHz = 1000 kHz = 1.000.000 Hz 1 GHz = 1000 MHz = 1.000.000 kHz = 1.000.000.000 Hz
Trzecim parametrem jest przesunięcie fazowe φ. Sygnał przesunięty fazowo posiada taką samą amplitudę oraz okres, lecz w stosunku do sygnału nie przesuniętego przyjmuje wartości wychylenia z pewnym opóźnieniem. Miarą przesunięcia fazowego jest kąt w radianach:
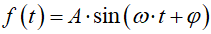 |
||
| A | – | amplituda sygnału |
| t | – | czas |
| ω | – | prędkość kątowa |
| φ | – | przesunięcie fazowe |
Mamy zatem trzy różne parametry sygnału, które można modulować:
Sygnał zmodulowany jednym z powyższych sposobów przenosił będzie informację cyfrową, czyli bity. Transmisja pojedynczych bitów jest transmisją szeregową. Dla każdego bitu przewidziany jest pewien krótki czas transmisji zwany oknem transmisji bitu (ang. bit transmit window) lub ramką bitu (ang. bit transmit frame). Bity są przesyłane jeden po drugim.
W modulacji amplitudy kształtujemy amplitudę sygnału w zależności od przesyłanego bitu 0 lub 1. Umówmy się, iż bit 0 będzie reprezentowany sygnałem o małej amplitudzie, a bit 1 będzie reprezentowany sygnałem o amplitudzie dużej.

Amplitudy dla bitu 0 i 1 muszą być tak dobrane, aby łatwo dały się odróżnić od siebie po stronie odbiorczej toru transmisyjnego.
Modem odbiera od komputera nadawczego informację cyfrową w postaci bitów. Wykorzystując stany bitów modem nadawczy moduluje odpowiednio amplitudę sygnału nośnego i wysyła go do ośrodka transmisyjnego. Poniżej przedstawiamy w dużym uproszczeniu przykładowy kształt sygnału zmodulowanego amplitudowo dla informacji binarnej 11010100.
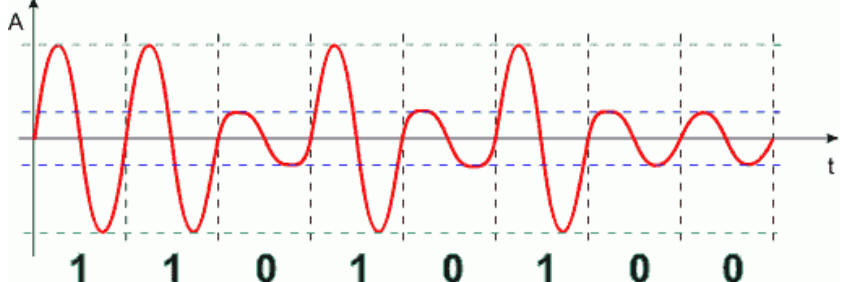
Transmisja z modulacją amplitudy jest mało odporna na zakłócenia. Przez zakłócenie rozumiemy obcy sygnał, który losowo pojawia się w kanale transmisyjnym i oddziałuje na sygnał nadawany. Zakłócenia powstają z różnych powodów - wyładowania atmosferyczne, praca różnych urządzeń elektrycznych,, promieniowanie kosmiczne itp. Sygnał zakłócający dodaje się do sygnału nadawanego zmieniając w ten sposób kształt jego fali.
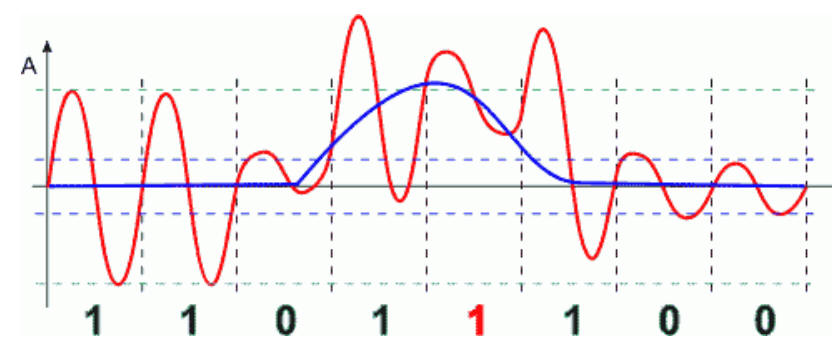
Na powyższym rysunku sygnał zakłócający (niebieski) spowodował taką zmianę sygnału nadawanego, iż nastąpiło przekłamanie jednego bitu, zaznaczonego pod wykresem na czerwono.
W modulacji częstotliwości kształtujemy częstotliwość sygnału (długość okresu). W oknie bitu 0 częstotliwość jest niska, w oknie bitu 1 częstotliwość jest wysoka. Częstotliwości bitów 0 i 1 są tak dobrane, aby można je było łatwo odróżnić po stronie odbiorczej.
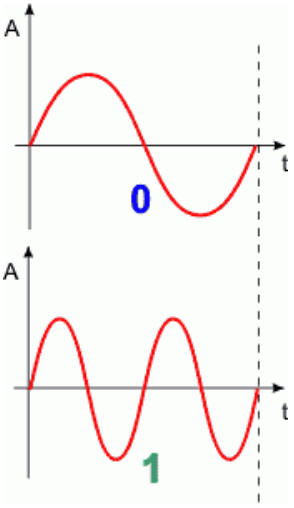
Na powyższym rysunku częstotliwość dla 1 jest dwa razy wyższa od częstotliwości dla 0. W praktyce stosunki tych częstotliwości są inne (ze względu na tzw. harmoniczne, czyli fale pochodne o częstotliwościach będących wielokrotnościami częstotliwości fali podstawowej), ale zasada pozostaje taka sama.
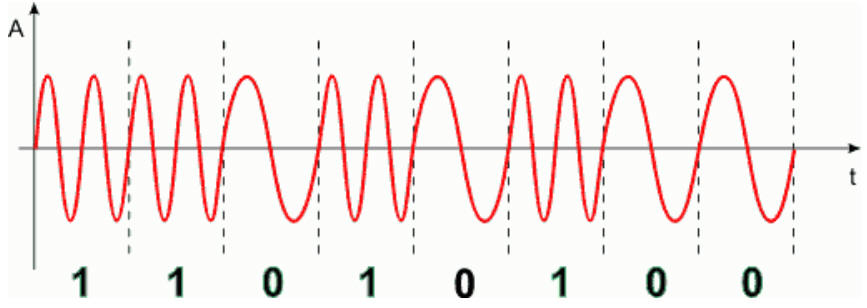
Powyżej widzimy kształt sygnału zmodulowanego częstotliwościowo dla danych binarnych 11010100. Ponieważ amplituda sygnału nie niesie informacji, zakłócenia amplitudowe do pewnego stopnia nie wpływają na przekazywaną informację. Dlatego modulacja FM jest dużo bardziej odporna na zakłócenia niż modulacja AM.
W modulacji fazy kształtujemy przesunięcie fazowe. Umówmy się, iż dla bitu 0 przesunięcie wynosi 0 radianów, a dla bitu 1 przesunięcie wynosi π radianów (o takim sygnale mówimy, iż posiada fazę przeciwną).
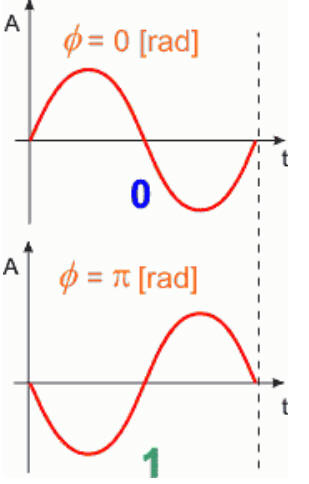
Poniżej przedstawiamy przebieg sygnału zmodulowanego fazowo dla danych binarnych 11010100. Zwróć uwagę, iż zmiana fazy występuje wtedy, gdy kolejne bity zmieniają swój stan np. z 1 na 0 lub z 0 na 1. Zamiast wykrywania przesunięć fazowych można jedynie wykrywać zmianę fazy (co jest dużo prostsze) i odpowiednio zmieniać stan odbieranych bitów.
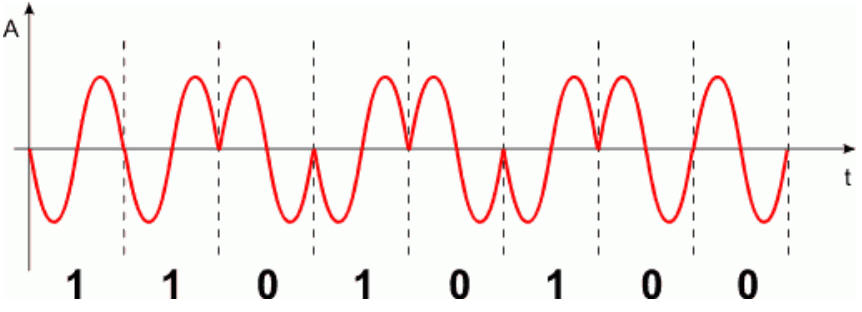
Transmisja PM jest bardzo odporna na zakłócenia.
Aby zwiększyć przepustowość kanału transmisyjnego (ilość przesyłanej informacji w jednostce czasu) często łączy się ze sobą kilka modulacji (np. AM i FM). W ten sposób można zwielokrotnić postać sygnału, a co za tym idzie w oknie bitowym przesyłać nie pojedynczy bit lecz kilka bitów. Dla przykładu zademonstrujemy taką modulację AM/FM. Naraz będą przesyłane dwa bity wg schematu:
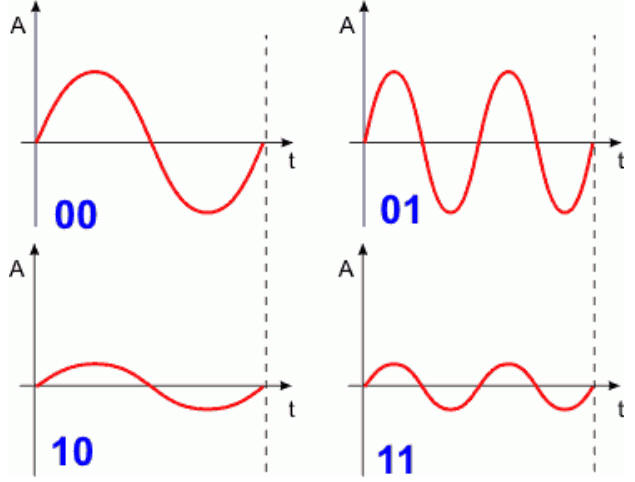
Sygnał modulujemy amplitudowo i częstotliwościowo wg dwóch bitów danych. Czyli naraz przesyłane są dwa bity informacji. Poniżej przedstawiamy przykładowy kształt sygnału dla danych binarnych 11010100. Zwróć uwagę, iż informację tą przesyłamy w dwa razy krótszym czasie niż w przypadku modulacji prostej. Zwielokrotniliśmy przepustowość kanału transmisyjnego.
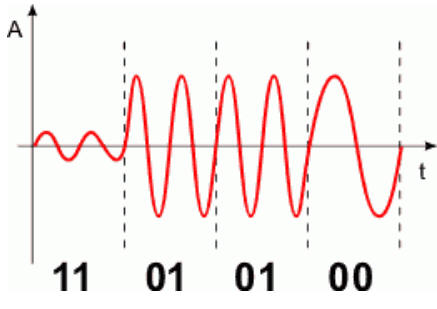
Pokazane sposoby modulacji nie wyczerpują wszystkich stosowanych w praktyce metod kształtowania sygnału. Naszym celem było jedynie naszkicowanie problemów transmisji cyfrowej i sposobów ich rozwiązania.
Szybkość transmisji cyfrowej wyraża się w jednostkach zwanych bodami (ang. baud rate):
1 bod = 1 bit w ciągu jednej sekundy
Większe jednostki to:
1 kilo bod = 1000 bitów / sekundę 1 mega bod = 1000 kilo bodów = 1.000.000 bodów
W trakcie przesyłania sygnału przez ośrodek transmisyjny mogą pojawić się różne zakłócenia, które spowodują deformację przesyłanego sygnału. Zakłócenia wywoływane są na przykład przez wyładowania atmosferyczne, maszyny elektryczne, silniki spalinowe, promieniowanie kosmiczne oraz wiele innych czynników zależnych od wybranego ośrodka transmisji. Nie zawsze da się te czynniki wyeliminować. Jeśli zakłócony sygnał dotrze do odbiornika, to może być nieprawidłowo odczytany. W transmisji cyfrowej błąd (przekłamanie) polega na odczycie bitu o stanie przeciwnym w stosunku do nadanego:
nadano bit 1 ... odebrano bit 0 nadano bit 0 ... odebrano bit 1
Błąd może być pojedynczy lub seryjny - dotyczący grupy kolejnych bitów. Ochrona transmisji przed błędami polega na odpowiednim kodowaniu przesyłanej informacji. Aby zrozumieć problem, przyjrzyjmy się poniższemu schematowi:
1011 → 10(1:>0)1 → 1001
Nadajnik wysyła informację cyfrową 1011 (cokolwiek by ona znaczyła). W trakcie przesyłu tej informacji przez kanał transmisyjny pojawia się zakłócenie, które powoduje, iż odbiornik odbiera informację 1001. Porównując informację nadaną i odebraną od razu zauważymy różnicę na przedostatniej pozycji, gdzie zamiast bitu 1 pojawił się bit 0. Doszło do przekłamania przesyłanej informacji. Ponieważ informacja nie była w żaden sposób zabezpieczona, to odbiornik nie ma pojęcia, iż odebrał dane z przekłamaniem. Przecież nadajnik mógł równie dobrze wysłać dane 1001.
1011 |
→ |
10(1:>0)1
|
→ |
1001
|
1011 |
→ |
1011 |
→ |
1011
|
Pierwszym narzucającym się rozwiązaniem tego problemu jest przesyłanie informacji dwukrotnie. Ponieważ odbiornik "wie", iż informacja odebrana podwójnie, powinna być taka sama, może ją sobie porównać. Na przedostatniej pozycji jest różnica. Teraz odbiornik wie już, iż odebrał dane z błędem. Kanałem zwrotnym może poprosić nadajnik o powtórzenie ostatniej transmisji danych.
Zwróć uwagę, iż w tym systemie nie wiemy, które z dwóch odebranych słówek jest poprawne, a które zawiera błąd. Sama różnica nie wystarcza do odtworzenia właściwej informacji. Dlatego taki kod nazywamy kodem wykrywającym błędy – kodem detekcyjnym (ang. EDC – Error Detection Code). Prawdopodobieństwo, iż błąd pojawi się w obu przekazach na tej samej pozycji (wtedy słówka będą oba błędne, ale takie same, co spowoduje ich akceptację przez odbiornik), jest naprawdę bardzo małe.
W praktyce nikt o zdrowych zmysłach nie zgodziłby się na opisany powyżej system zabezpieczania transmisji przed błędami. Powodem jest dwukrotny spadek przepustowości (ilości przesyłanej informacji w jednostce czasu) kanału transmisyjnego – ponieważ każdą informację musimy przesyłać dwa razy. Jeśli błędy pojawiają się w kanale transmisyjnym bardzo rzadko, stosuje się bardziej oszczędny system kodowania przesyłanej informacji, zwany transmisją z bitem parzystości (ang. parity checking).
Polega to na tym, iż do przesyłanego słówka dodajemy jeden bit o takim stanie, aby liczba wszystkich bitów o stanie 1 w tak powiększonym słowie informacyjnym była parzysta (czyli podzielna przez 2). Załóżmy, iż przesyłamy słówka 4-bitowe. Poniżej przedstawiamy kilka przykładów rozszerzania takich słówek do 5-bitowych z bitem parzystości. Umówmy się, iż dodatkowy bit dodajemy na początku nowego słowa:
| słówko informacyjne |
słówko z bitem parzystości |
| 0000 | 00000 |
| 0001 | 10001 |
| 0011 | 00011 |
| 0110 | 00110 |
| 1011 | 11011 |
| 1110 | 11110 |
| 1111 | 01111 |
Co nam to dało? Otóż dużo. Odbiornik wie teraz, iż zawsze w odebranym słowie liczba bitów o stanie 1 powinna być parzysta. Może to sobie sprawdzić. Jeśli otrzyma liczbę nieparzystą, to znaczy, iż któryś z bitów został odebrany z przekłamaniem:
Wynika z tego, iż pojedynczy błąd powoduje utratę parzystości w odebranym słówku danych. Również nieparzysta liczba błędów (1,3,5,...) wywoła taką utratę parzystości. Natomiast błędy parzyste (na 2, 4, 6 ... bitach) przejdą niezauważone, ponieważ nie powodują one utraty parzystości (spróbuj to udowodnić). Ponieważ jednak system ten stosuje się w przypadku, gdy błędy pojawiają się bardzo rzadko, to możemy śmiało założyć, iż wystąpienie błędu podwójnego (parzystego) jest prawie niemożliwe.
Zabezpieczenie transmisji bitem parzystości jest już bardziej ekonomiczne od dwukrotnego przesyłania każdego słowa informacyjnego. Spadek szybkości transmisji jest tym mniejszy, im więcej bitów informacyjnym mają przesyłane słowa danych.
Kod korekcyjny (ang. ECC - Error Correction Code) ma za zadanie odtworzenie, naprawę informacji w przypadku wystąpienia błędu (lub błędów) spowodowanych zakłóceniami sygnału w kanale transmisyjnym. Kody ECC stosujemy zwykle tam, gdzie:
Najprymitywniejszym kodem ECC jest po prostu trzykrotne przesyłanie każdego bitu danych. Jeśli w trakcie transmisji nastąpi przekłamanie jednego bitu, to dwa pozostałe pozwolą odtworzyć właściwy bit danych.
| Nadajnik |
Kanał transmisyjny |
Odbiornik | ||
1 |
... |
111 ... 011
|
... |
011 → 1
|
0 |
... |
000 ... 001
|
... |
001 → 0
|
1 |
... |
111 ... 101
|
... |
101 → 1 |
1 |
... |
111 ... 110
|
... |
110 → 1
|
W powyższym przykładzie występuje błąd w trakcie każdej transmisji trójki bitów. Dlatego po stronie odbiornika odebrane trójki zawierają różne bity. Za bit nadany odbiornik przyjmuje bit powtarzający się najczęściej. Oczywiście system ten zawiedzie, gdy przekłamane zostaną dwa bity w trójce.
Potrójne przesyłanie danych nie jest stosowane w praktyce - przepustowość kanału transmisyjnego spada trzykrotnie, na co nikt nie mógłby sobie pozwolić ze względów ekonomicznych. Jeśli błędy pojawiają się rzadko w kanale transmisyjnym, to przesyłaną informację można zabezpieczyć kodem Hamminga. Kod ten, wynaleziony przez Richarda Hamminga w 1950 roku, pozwala naprawić pojedyncze przekłamania bitów w odebranym słowie binarnym. Poniżej przedstawiamy konstrukcję słówek kodu Hamminga dla wiadomości 4-bitowych.
Na początek będzie nam potrzebna tablica liczb binarnych o wartościach od 0 do 7:
| dziesiętnie | binarnie |
0 |
000 |
1 |
001 |
2 |
010 |
3 |
011 |
4 |
100 |
5 |
101 |
6 |
110 |
7 |
111 |
Słówko danych składa się z 4 bitów b4b3b2b1. Bity te umieszczamy w słówku kodu Hamminga w sposób następujący:
| Numer pozycji : | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Słowo kodu Hamminga: |
b4 |
b3 |
b2 |
x4 |
b1 |
x2 |
x1 |
Pozycje o numerach będących kolejnymi potęgami liczby 2 (1, 2, 4, 8, 16, ...) są tzw. pozycjami kontrolnymi. Oznaczyliśmy je literką x. Pozycje kontrolne musimy obliczyć na podstawie słowa danych. Zróbmy to na konkretnym przykładzie. Niech nasze słowo informacyjne ma wartość:
b4b3b2b1 = 1011
Bity informacyjne wpisujemy na odpowiednie pozycje w słowie kodu Hamminga:
| Numer pozycji : | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Słowo kodu Hamminga: |
1 |
0 |
1 |
x4 |
1 |
x2 |
x1 |
Zapiszmy wszystkie numery pozycji, na których występują bity o stanie 1. Są to pozycje 7, 5 i 3. Wykorzystując tabelkę konwersji dziesiętno-dwójkowej zapiszmy wyznaczone numery pozycji binarnie: 7 = 111, 5 = 101 i 3 = 011. Teraz otrzymane liczby binarne wpisujemy do poniższej tabelki:
x4 |
x2 |
x1 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
Aby wyznaczyć kolejne pozycje kontrolne x4, x2 i x1, pionowo w kolumnach uzupełniamy bity bitem parzystości (w danej kolumnie liczba bitów 1 musi być parzysta). Otrzymane w ten sposób bity parzystości są wartościami dla pozycji kontrolnych:
x4 |
x2 |
x1 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
Bity parzystości kolumn przepisujemy do odpowiednich pozycji kontrolnych w słowie kodowym Hamminga:
| Numer pozycji : | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Słowo kodu Hamminga: |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
Gotowe, utworzyliśmy słowo kodu Hamminga dla danej informacji: 1011 → 1010101.
Teraz przesyłamy wyznaczone powyżej słowo kodu Hamminga 1010101 przez kanał transmisyjny. Występuje przekłamanie na pozycji nr 6 i w efekcie odbiornik odbiera słowo 1110101.
| Numer pozycji : | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Odebrane słowo kodu Hamminga: |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
Odbiornik wyznacza pozycje wszystkich bitów 1 w odebranym słowie: 7, 6, 5, 3 i 1. Numery pozycji przekształca na kod binarny zgodnie z podaną wcześniej tabelą konwersji:
7 = 111, 6 = 110, 5 = 101, 3 = 011 i 1 = 001.
Binarne numery pozycji odbiornik umieszcza w tabeli i każdą kolumnę uzupełnia bitem parzystości:
| 7 |
1 |
1 |
1 |
| 6 |
1 |
1 |
0 |
| 5 |
1 |
0 |
1 |
| 3 |
0 |
1 |
1 |
| 1 |
0 |
0 |
1 |
| bit parzystości |
1 |
1 |
0 |
Otrzymaliśmy wartość 110. Wg tabeli konwersji jest to liczba 6, która oznacza pozycję w słowie kodowym Hamminga, na której wystąpiło przekłamanie. Ponieważ przekłamanie w transmisji cyfrowej polega na odebraniu bitu o stanie przeciwnym do nadanego, zatem wystarczy zanegować (zmienić stan na przeciwny) bit na pozycji 6, aby otrzymać nadane słowo Hamminga:
| Numer pozycji : |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
| Naprawione słowo kodu Hamminga: |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
Teraz usuwamy bity kontrolne i otrzymujemy informację nadaną: 1011. Jeśli w trakcie transmisji błąd nie wystąpi, to odbiornik otrzyma w wyniku dekodowania pozycję 000 = 0. W takim przypadku usuwa jedynie bity kontrolne.
Znajdź kody Hamminga dla danych: 0000, 1111, 1001. W otrzymanych kodach zmień stan dowolnego bitu na przeciwny i sprawdź, czy odbiornik może naprawić taki kod.
Podane w tym artykule informacje nie wyczerpują zagadnienia kodów korekcyjnych. Zainteresowanych tym tematem czytelników odsyłamy do źródeł w Internecie dotyczących kodów Golay'a, Reeda-Mullera i Reeda-Salomona. Wymagają one zaawansowanej arytmetyki binarnej, wykraczającej poza zakres materiału dla szkoły średniej i dlatego zostały tutaj pominięte. Z drugiej strony kody te są stosowane w popularnym sprzęcie Audio-CD oraz DVD do korekcji błędów odczytu z nośników cyfrowych. Kody ECC Reeda-Salomona pozwalają odtworzyć informację przy wystąpieniu tzw. błędów seryjnych, czyli ciągu kolejnych przekłamanych bitów (powstających np. przy zarysowaniu nośnika CD/DVD). Dzięki nim odtwarzacze CD, DVD i Blu-ray mogą poprawnie odczytywać zarysowane i poplamione płyty cyfrowe (oczywiście tylko do pewnego stopnia). Inteligentne urządzenia odtwarzające nawet radzą sobie w sytuacji, gdy fragment danych jest niemożliwy do odtworzenia. W takim przypadku, aby zapobiec nieuniknionym trzaskom w odtwarzanym nagraniu, w miejsce uszkodzonego fragmentu utworu wstawiany jest fragment bezpośrednio poprzedzający uszkodzenie. Niewprawne ucho nawet nie zauważy tego oszustwa w odtwarzanym utworze muzycznym. Podobnie postępuje się w przypadku filmów na nośnikach cyfrowych.
 |
Kanał transmisyjny jest drogą, trasą, po której przesyłane są informacje w postaci bitów. Kanały transmisyjne mogą być przewodowe, światłowodowe lub radiowe.
Pierwsze sieci komputerowe powstały niedługo po powstaniu pierwszych komputerów elektronicznych. Spowodowane to było chęcią udostępnienia drogiego komputera centralnego (ang. mainframe computer) wielu użytkownikom:

Komputer centralny w latach 60-tych XX wieku
Do komputera centralnego podłączone były tzw. terminale sieciowe, na których pracowali użytkownicy sieci. Terminale były dużo prostsze w budowie od komputera centralnego, który zajmował się obliczeniami i głównym przetwarzaniem danych. Terminale służyły zwykle do przygotowywania informacji dla komputera centralnego oraz do otrzymywania wyników obliczeń z tego komputera. Używanie terminali pozwalało bardziej efektywnie wykorzystywać moc obliczeniową komputera centralnego. Tego typu rozwiązania stosowane są do dzisiaj.
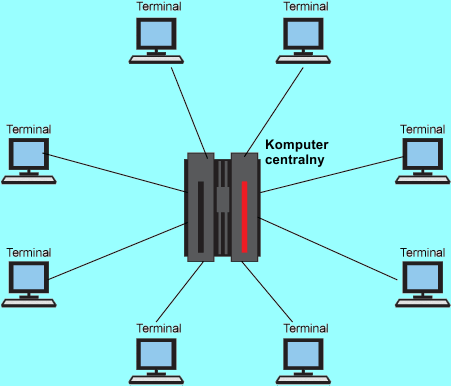 |
Głównym celem sieci komputerowej (ang. computer network) jest wymiana informacji pomiędzy komputerami tworzącymi tę sieć. Współczesne sieci komputerowe są bardzo skomplikowane i poznamy tylko ich podstawowe funkcje. Pełną wiedzę zdobywa się na specjalistycznych studiach informatycznych.
Zdefiniujmy najpierw podstawowe słownictwo:
 |
Sieć komputerowa (ang. computer network) Zbiór komputerów rozmieszczonych na pewnym obszarze i połączonych ze sobą kanałami transmisyjnymi w celu wymiany informacji. |
 |
Serwer sieciowy (ang. network server) Wydzielony w sieci komputer, zwykle o dużej mocy obliczeniowej i pojemnych dyskach twardych, który steruje pracą sieci i udostępnia różne usługi - pocztę elektroniczną, składowanie plików i programów, dostęp do Internetu, komunikację i wymianę danych w obrębie sieci, itp. |
 |
Administrator sieci, admin (ang. network administrator) Osoba legitymująca się studiami informatycznymi o kierunku związanym z zarządzaniem i administrowaniem sieci komputerowych, posiadająca wieloletnie doświadczenie w pracy z sieciami. ich konfiguracją oraz utrzymaniem. Odpowiada za całość funkcjonowania sieci, ustawia różne serwisy dla użytkowników, zarządza kontami użytkowników oraz ich prawami dostępu do zasobów sieciowych, reaguje na ataki z Internetu, aktualizuje oprogramowanie sieciowe. Administrator sieci jest wydzielonym zawodem informatycznym. Zawodów informatycznych jest dzisiaj ponad 20. Są to określone specjalizacje, które wymagają dedykowanych studiów, podobnie jak specjalizacje lekarskie: kardiolog, okulista, dentysta, chirurg... |
 |
Stacja robocza, terminal sieciowy (ang. workstation) Komputer podłączony do sieci, korzystający z jej zasobów.
|
 |
Użytkownik sieci (ang. network user) Osoba pracująca na terminalu sieciowym. Użytkownicy posiadają w sieci różne prawa (np. dostępu do wybranych usług lub zasobów). Użytkownik o największych prawach jest awatarem (ang. avatar). |
LAN (ang. Local Area Network) - sieć lokalna:
Jest to mała sieć komputerowa zawierająca do kilkuset komputerów zgrupowanych fizycznie na niedużym obszarze, takim jak szkoła, biuro firmy, lotnisko, szpital, fabryka, instytut naukowy, itp. Kanały transmisyjne realizowane są zwykle za pomocą kabli elektrycznych lub radia (przykładem jest standard Ethernet).
MAN (ang. Metropolitan Area Network) - sieć miejska:
Jest to duża sieć komputerowa zawierająca dziesiątki tysięcy komputerów, która rozprzestrzenia się na większym obszarze, obejmującym od kilku budynków do granic strefy miejskiej. Cechuje się szybką transmisją danych. Zwykle sieć posiada kilkunastu różnych właścicieli, którzy zarządzają jej fragmentami. Kanały transmisyjne realizowane są zwykle za pomocą światłowodów o dużej przepustowości lub techniką radiową.
WAN (ang. Wide Area Network) - sieć rozległa:
Jest to sieć komputerowa pokrywająca rozległy obszar wykraczający poza granice miast, regionów, a nawet państw. Przykładem największej sieci WAN jest Internet oplatający całą Ziemię, a wkrótce również obecny w kosmosie. Ilość komputerów wchodzących w skład tej sieci zwykle nie jest ograniczona i liczy się ją milionami sztuk. Typowymi kanałami komunikacyjnymi w sieciach WAN są linie telefoniczne, połączenia krótkofalowe oraz kanały satelitarne. Sieci WAN często łączą ze sobą sieci LAN i MAN w większe grupy.
 |
| Bob Metcalfe |
Na początku lat siedemdziesiątych ubiegłego wieku w Centrum Badawczym Korporacji Xerox w Palo Alto (znanego w świecie pod nazwą PARC - ang. Palo Alto Research Center) naukowiec o nazwisku Bob Metcalfe zaprojektował i przetestował pierwszą na świecie sieć komputerową Ethernet (sieć komputerowa to grupa komputerów połączonych ze sobą kanałami transmisyjnymi do wymiany danych cyfrowych). W trakcie prac nad znalezieniem sposobu przyłączenia komputera "Alto" firmy Xerox do drukarki Metcalfe wynalazł rozwiązanie problemu fizycznego połączenia urządzeń za pomocą kabli elektrycznych. Rozwiązanie to nazwał Ethernet. Sieci Ethernet stały się od tego czasu najpopularniejsze na całym świecie i najpowszechniej używane. Standard Ethernet rozwijał się i obejmował coraz więcej nowych rozwiązań i technologii wraz z dojrzewaniem idei sieci komputerowych, lecz podstawy działania pozostały w zasadzie takie same jak w pierwszej sieci opracowanej przez Metcalfe'a. Pierwotny Ethernet realizował wymianę danych poprzez pojedynczy kabel, który współdzieliły wszystkie urządzenia w danej sieci. Po podłączeniu jakiegoś urządzenia do takiego kabla mogło ono prowadzić wymianę danych z dowolnym innym urządzeniem, które było również podłączone do tego kabla. Zasada ta pozwala rozbudowywać sieć w celu dołączania nowych urządzeń bez konieczności modyfikacji tych urządzeń, które już są dołączone do sieci.
Ethernet jest technologią niedużych, lokalnych sieci komputerowych, które zwykle działają w obrębie pojedynczego budynku, łącząc urządzenia znajdujące się blisko siebie. Długość kabla Ethernet zwykle nie przekracza kilkaset metrów. Nowoczesne rozwiązania pozwoliły zwiększyć te odległości do dziesiątek kilometrów. W transmisji danych stosowane są protokoły komunikacyjne. Protokół sieciowy jest zbiorem zasad, wg których prowadzona jest wymiana danych w sieci. Odpowiada on językowi ludzi. Aby czytać ten artykuł, musisz rozumieć język polski. Podobnie, aby dwa urządzenia w sieci komputerowej mogły wymieniać ze sobą dane, muszą oba rozumieć ten sam protokół komunikacyjny.
Urządzenia pracujące we wspólnej sieci Ethernet są podłączone do wspólnego medium transmisyjnego, które umożliwia przesyłanie sygnałów elektrycznych. Historycznie medium transmisyjne było realizowane za pomocą kabla koncentrycznego (ang. coaxial cable), lecz obecnie zwykle stosuje się skręconą parę przewodów (ang. twisted pair cable) lub włókna światłowodowe (ang. optical fiber cable).
 |
 |
 |
| Kabel koncentryczny | Skrętka | Włókno światłowodowe |
Pojedyncze, wspólne medium transmisyjne nazywamy segmentem Ethernet.
Urządzenie podłączone do segmentu nazywamy węzłem (ang. node), terminalem lub stacją roboczą (ang. workstation).
Węzły komunikują się ze sobą za pomocą krótkich wiadomości nazywanych ramkami (ang. frames), które przekazują fragmenty informacji o różnej długości. Ramki możemy porównać do zdań w naszym języku. Budowę zdania w języku polskim definiuje gramatyka. W sieci Ethernet budowę ramki określa protokół sieciowy. Istnieją ścisłe reguły co do minimalnej i maksymalnej długości ramek (liczby bitów, które ramka w sobie zawiera) oraz co do ich zawartości. Każde urządzenie podłączone do sieci Ethernet posiada swój adres sieciowy, czyli numer identyfikacyjny, zwany adresem MAC (ang. Media Access Control - Kontrola Dostępu do Medium). Ramki muszą zawierać w sobie adresy urządzenia nadającego ramkę oraz urządzenia, które ma tę ramkę odebrać, czyli adres nadawcy i odbiorcy informacji. Dany adres w sposób jednoznaczny definiuje węzeł sieciowy, jak numer PESEL jednoznacznie identyfikuje podatnika w naszym kraju. Dwa urządzenia Ethernet nie mogą posiadać identycznego adresu sieciowego.
Budowa ramki Ethernet wygląda w uproszczeniu następująco:
| Preambuła | SFD |
Adres docelowy |
Adres źródłowy |
Opcjonalne pole 802.1Q |
Typ Ethernet lub długość |
Dane | CRC |
Przerwa między ramkami |
|---|---|---|---|---|---|---|---|---|
7 bajtów 10101010
|
1 bajt 10101011 |
6 bajtów |
6 bajtów |
(4 bajty)
|
2 bajty |
46–1500 bajtów |
4 bajty |
12 bajtów |
|
|
64–1522 bajtów |
|
||||||
72–1530 bajtów |
|
|||||||
84–1542 bajtów |
||||||||
Preambuła oznacza początek ramki. Przesyłany wzór bitowy - naprzemiennie 1 i 0 - pozwala dobrze zsynchronizować urządzenia nadawczo-odbiorcze węzłów.
SFD (ang. Start Frame Delimiter - ogranicznik początku ramki) jest bajtem przesyłanym po rozbiegówce. Oznacza on koniec rozbiegówki.
Adres docelowy zawiera tzw. numer MAC odbiorcy ramki. W sieci Ethernet numery MAC są 6 bajtowe. Numer ten jest albo ustalany przez wytwórcę urządzenia, albo definiowany przez administratora sieci w urządzeniach, których adresy MAC można konfigurować.
Adres źródłowy definiuje urządzenie, które daną ramkę wysyła.
Pole Typ Ethernet zawiera albo dane określające rodzaj używanego protokołu Ethernet dla ramek sterujących, albo długość ramki dla ramek z danymi.
Pole z danymi może zawierać od 46 do 1500 bajtów danych.
Pole CRC zawiera 32 bitową sumę kontrolną (ang. Cyclic Redundancy Check - Cykliczne Sprawdzanie Nadmiarowości), która umożliwia wykrywanie błędów w przesyłanych danych.
Przerwa między ramkami (ang. interframe gap) składa się z 12 bajtów o stanie równym ciszy w medium. Musi ona wystąpić przed próbą wysłania kolejnej ramki. W trakcie przerwy inne węzły mogą próbować rozpocząć transmisję swoich własnych ramek - patrz dalej.
W zależności od stosowanego w sieci Ethernet medium istnieją różne sposoby podłączania kabla sieciowego do komputera. W każdym przypadku komputer musi być wyposażony w specjalną kartę sieciową, która posiada odpowiednie gniazda (współcześnie produkowane komputery przenośne posiadają gniazda Ethernet w swoim standardowym wyposażeniu).
 |
 |
 |
| Wtyczka na kabel koncentryczny | Wtyczka na skrętkę | Wtyczka na włókno światłowodowe |
 |
 |
 |
| Karta Ethernet z
gniazdkiem na kabel koncentryczny |
Karta Ethernet z
gniazdkiem na skrętkę |
Karta Ethernet z
gniazdkiem na włókno światłowodowe |
Technologia kabla koncentrycznego dzisiaj jest już przestarzała. Powszechnie są stosowane kable ze skrętek oraz kable światłowodowe. Te ostatnie pozwalają na dużo wyższe prędkości transmisji, ponieważ kabel światłowodowy jest odporny na różne zakłócenia, z którymi muszą walczyć kable elektryczne - wyładowania atmosferyczne, zakłócenia przemysłowe, pola magnetyczne, sprzężenia pasożytnicze, itp.
Ponieważ sygnał w medium Ethernet dociera do każdego podłączonego węzła, adres docelowy jest niezbędny do określenia zamierzonego odbiorcy ramki sieciowej.

Przykładowo na powyższym rysunku gdy komputer 2 wysyła dane do drukarki 3, to ramkę sieciową odbierają również komputery 1 i 4. Jednakże, gdy węzeł odbiera ramkę, to sprawdza adres odbiorcy, aby dowiedzieć się, czy jest ona dla niego przeznaczona. Jeśli nie, odrzuca ramkę, nie czytając nawet jej zawartości. W sieci Ethernet istnieje tzw. adres rozsiewczy (ang. broadcast address), który dotyczy wszystkich węzłów w sieci. Jeśli adres docelowy w ramce jest adresem rozsiewczym, to ramka zostanie odczytana i przetworzona przez wszystkie węzły. System ten pozwala rozsyłać w sieci różne wiadomości sterujące.
Ethernet steruje przesyłem danych pomiędzy węzłami sieci za pomocą technologii CSMA/CD (ang. Carrier-Sense Multiple Access with Collision Detection - wielodostęp z wykrywaniem sygnału nośnego oraz wykrywaniem kolizji). Gdy jeden z węzłów w sieci Ethernet przesyła dane, wszystkie pozostałe węzły "słyszą" tę transmisję. W trakcie transmisji protokół zabrania innym węzłom rozpoczynania własnej transmisji - nie miałoby to sensu, ponieważ doszłoby do zakłócenia obu sygnałów, i żaden z węzłów nie byłby w stanie przesłać swoich danych - to zupełnie tak samo, jak dwóch lub więcej ludzi próbuje jednocześnie coś mówić, zakłócając się nawzajem. Gdy pewien węzeł chce transmitować dane, czeka aż medium będzie wolne od innych transmisji - czyli do momentu, gdy przestanie wykrywać sygnał nośny. Dopiero wtedy próbuje wysłać swoją ramkę danych.
Może się jednakże zdarzyć, iż w tym samym momencie inny węzeł wykrył koniec transmisji i sam również rozpoczął swoją własną transmisję. Węzły Ethernet nasłuchują medium w trakcie wysyłania swoich danych, aby upewnić się, że są jedynymi transmitującymi w tym czasie dane. Jeśli "usłyszą" swoje sygnały wracające w postaci zniekształconej, co zdarza się, gdy inny węzeł rozpocznie w tym samym czasie transmisję, to "wiedzą", że doszło do kolizji. Pojedynczy segment Ethernet czasami jest nazywany domeną kolizyjną, ponieważ żadne dwa węzły nie mogą w nim przesyłać danych w tym samym czasie bez wywołania kolizji. Gdy węzły wykryją kolizję, przerywają transmisję, odczekują przypadkowy okres czasu i ponawiają próbę wysłania ramki, gdy wykryją ciszę w medium.
Przypadkowa długość przerwy jest bardzo ważną częścią protokołu. Gdy dwa węzły wchodzą ze sobą w kolizję po raz pierwszy, to oba będą musiały ponownie przesyłać dane. Przy następnej nadarzającej się okazji oba węzły uczestniczące w poprzedniej kolizji będą posiadały dane przygotowane do wysłania. Gdyby wysyłały te dane przy pierwszej ciszy w medium, to najprawdopodobniej doszłoby między nimi do kolejnej kolizji, a później do następnej, następnej... Dzięki przypadkowemu okresowi opóźnienia sytuacja taka jest mało prawdopodobna i jeden z węzłów jako pierwszy zacznie transmisję. Wtedy drugi, zgodnie z protokołem, będzie musiał czekać na ponowną ciszę w medium. Przypadkowość przerw gwarantuje, iż każdy z węzłów posiada równe szanse w dostępie do medium i będzie mógł wysłać swoje dane.
Pojedynczy, wspólnie używany kabel może być podstawą pełnej sieci Ethernet. Jednakże w tym przypadku powstają praktyczne ograniczenia maksymalnego rozmiaru takiej sieci, które wiążą się z ograniczeniami długości wspólnie wykorzystywanego kabla.
Sygnały elektryczne podróżują wzdłuż kabla bardzo szybko - prawie z szybkością światła, lecz, w miarę trwania tej podróży, słabną, a elektryczne interferencje z sąsiednich urządzeń (na przykład świetlówek, silników, linii energetycznych, transformatorów, itp.) mogą zniekształcać sygnał. Dlatego kabel powinien być na tyle krótki, aby urządzenie znajdujące się na jego drugim końcu było w stanie odebrać czyste sygnały z minimalnym opóźnieniem. To nakłada ograniczenie w maksymalnej odległości pomiędzy dwoma urządzeniami (zwane średnicą sieci - ang. network diameter) w sieci Ethernet. Dodatkowo, ponieważ przy technologii CSMA/CD tylko jedno urządzenie może przesyłać dane w określonym momencie, istnieje praktyczne ograniczenie co do liczby urządzeń, które mogą współistnieć w pojedynczej sieci. Podłączenie zbyt wielu węzłów do wspólnego segmentu powoduje wzrost kolizji w dostępie do medium. Każdy węzeł musiałby czekać przez nadmiernie długi okres czasu zanim otrzymałby szansę rozpoczęcia własnej transmisji.
Z tego powodu inżynierowie opracowali wiele urządzeń sieciowych, które usuwają te niedogodności.
 |
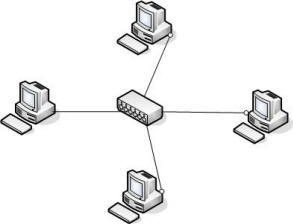 |
| Koncentrator Ethernet | Sieć typu gwiazda oparta na koncentratorze. |
Pierwszym popularnym medium Ethernet był koncentryczny kabel miedziany. Maksymalna długość takiego kabla wynosiła 500 metrów. W dużych budynkach czy w środowiskach campusów akademickich taka długość kabla nie zawsze była wystarczająca do podłączenia wszystkich urządzeń sieciowych. Z tego powodu został opracowany tzw. koncentrator sieciowy (ang. network repeater lub network hub). Koncentratory łączą ze sobą wiele segmentów Ethernet, nasłuchując każdy z nich i powtarzając usłyszany sygnał w każdym podłączonym segmencie. Dzięki koncentratorom można znacząco zwiększyć średnicę sieci - w jednej sieci może być wiele koncentratorów.
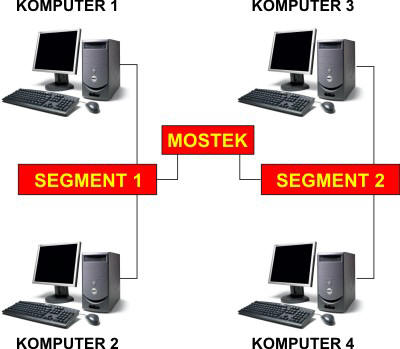
Innym rozwiązaniem problemu dużej liczby węzłów jest podział segmentu sieci na wiele oddzielnych segmentów. Problemem jest jednak to, iż rozdzielone segmenty nie mogą się ze sobą komunikować. Aby to umożliwić, zaprojektowano urządzenia łączące segmenty sieci, które nazywają się mostkami sieciowymi (ang. network bridges). Łączą one ze sobą dwa lub więcej segmentów Ethernet, zwiększając średnicę sieci, podobnie jak robią to koncentratory, lecz mostki dodatkowo pozwalają regulować ruch w sieci. Potrafią one odbierać oraz nadawać dane jak każdy węzeł Ethernet, lecz zasada ich działania jest inna. Mostek sam z siebie nie wysyła żadnych danych (nie jest to do końca prawdą, ponieważ mostki przesyłają pomiędzy sobą specjalne ramki Ethernet, które pozwalają im komunikować się ze sobą, jednakże dane te nie są przeznaczone dla węzłów w sieci i są przez nie ignorowane), lecz, podobnie jak koncentrator, przesyła dalej tylko to, co usłyszy od innych węzłów. Zadaniem mostków jest przekazywanie danych pomiędzy segmentami sieci, kiedy jest to konieczne. Na powyższym rysunku mostek łączy segment 1 z segmentem 2. Załóżmy, iż jeden z komputerów 1...4 wysyła ramkę danych. Ramka dociera do mostka. Teraz mostek sprawdza, czy adresatem tej ramki jest komputer w innym segmencie sieci niż nadawca. Jeśli tak, przesyła ramkę do segmentu nadawcy. Jeśli odbiorcą ramki jest komputer w tym samym segmencie sieci (np. komputer 1 przesyła dane do komputera 2 lub komputer 3 do komputera 4), mostek nie przekazuje jej do innych segmentów - tutaj jest różnica w pracy w stosunku do koncentratora. Dzięki temu mostek zmniejsza ogólny ruch w sieci jako całość. Węzły są podzielona na grupy, które w swoich segmentach mogą prowadzić niezależną transmisję danych, która nie zakłóca transmisji w innych segmentach sieci (np. komputery 1-2 oraz 3-4 mogą przesyłać dane między sobą w tym samym czasie). Również przesył ramki do innego segmentu ogranicza się tylko do segmentu odbiorcy ramki - pozostałe segmenty nie są zakłócane zbędną dla nich transmisją. Dzięki tym własnościom mostki przyczyniają się do zmniejszenia obciążenia sieci i pozwalają na efektywniejszą wymianę danych przy dużej liczbie węzłów.
Nowoczesny Ethernet często zupełnie nie przypomina swojego historycznego przodka. Dawniej węzły sieci łączone były ze sobą za pomocą długich kabli koncentrycznych, dzisiaj stosuje się skręcone pary przewodów lub światłowody. Stary Ethernet zapewniał transmisję na poziomie 10 megabitów na sekundę, nowoczesne sieci mogą pracować z szybkościami 100 (skrętka), czy nawet 1000 megabitów (światłowody) !
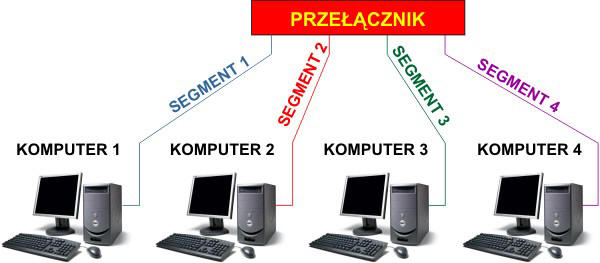
Najbardziej uderzającym postępem we współczesnych sieciach Ethernet jest stosowanie przełączanego Ethernetu. Sieci przełączane zastępują przestarzałe wspólne medium transmisyjne. W sieciach tych każdy węzeł posiada swój własny segment sieciowy, niezależny od innych. Segmenty te są podłączone do urządzenia zwanego przełącznikiem sieciowym (ang. network switch), który działa podobnie do mostka sieciowego, lecz potrafi połączyć ze sobą naraz wiele z tych segmentów. Niektóre współczesne przełączniki sieciowe potrafią współpracować z dziesiątkami oddzielnych segmentów. Ponieważ w każdym segmencie jedynymi urządzeniami jest przełącznik sieciowy oraz węzeł końcowy, to przełącznik odczytuje każdą ramkę danych, zanim dotrze ona do innego węzła. Następnie przełącznik przesyła dalej odebraną ramkę do właściwego segmentu, tak jak mostek, lecz ponieważ w każdym segmencie jest tylko jeden węzeł, ramka dociera tylko do jej zamierzonego adresata. Pozwala to na prowadzenie wielu równoległych transmisji w sieci przełączanej.
Przełączany Ethernet udostępnił kolejną korzyść: Ethernet full-duplex. Termin full-duplex oznacza w transmisji danych możliwość równoczesnego nadawania i odbierania informacji (analogia do połączenia telefonicznego, gdzie obaj rozmówcy się nawzajem słyszą). Stary Ethernet był typu half-duplex, co oznaczało, że informacja w danym czasie mogła być przesyłana tylko w jednym kierunku (pojedynczy kabel nie pozwalał na dwukierunkową transmisję). W całkowicie przełączalnej sieci węzły porozumiewają się tylko z przełącznikiem sieciowym i nigdy bezpośrednio ze sobą. Z tego powodu sieci przełączane wykorzystują albo skręcane pary przewodów, albo włókna światłowodowe, w których kanały odbioru i nadawania danych są od siebie odseparowane.
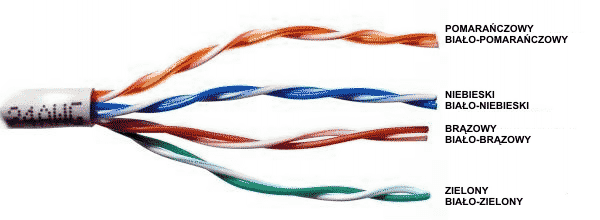 |
  |
| Skrętka UTP (ang. Unshielded Twisted Pair) | Wtyk RJ-45 dla skrętki UTP |
W takim rodzaju środowiska węzły Ethernet mogą zaniechać procesu wykrywania kolizji i transmitować wedle woli, ponieważ są jedynymi urządzeniami z dostępem do medium w danym segmencie sieci. Dzięki temu węzeł może wysyłać dane do przełącznika sieciowego w tym samym czasie, gdy przełącznik przesyła dane do węzła - obie transmisje odbywają się w oddzielnych kanałach i nie dochodzi do ich zakłócania - uzyskujemy środowisko wolne od kolizji.
W latach 60-tych ubiegłego wieku panowała zimna wojna pomiędzy dwoma mocarstwami - Związkiem Sowieckim i Stanami Zjednoczonymi. Kryzys kubański pokazał, iż granica wybuchu wojny termojądrowej jest niebezpiecznie cienka. Z tego powodu Departament Obrony USA stworzył Agencję Zaawansowanych Projektów Badawczych ARPA (ang. Advanced Research Project Agency), która zajęła się opracowaniem planów i budową rozległej sieci komputerowej odpornej na atak nuklearny. Pod koniec lat 60 powstaje ARPANET - sieć komputerowa łącząca cztery węzły w różnych regionach południowo zachodnich stanów USA. Podstawową cechą sieci ARPANET jest niezależność węzłów oraz brak centralnego ośrodka. Dzięki temu zniszczenie fragmentu sieci nie powoduje jej zablokowania jako całości.
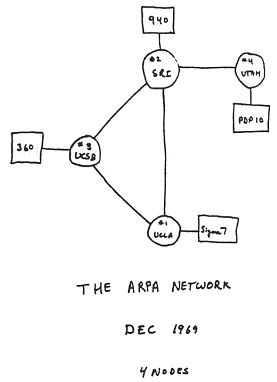 |
Sieć ARPA Rok 1969 Węzeł 1 UCLA sierpień Węzeł 2 Stanford Research Institute (SRI) październik Węzeł 3 University of California Santa Barbara (UCSB) listopad Węzeł 4 University of Utah grudzień
obok - oryginalny szkic sieci |
Sieć ARPANET była systematycznie rozbudowywana - dołączano do niej coraz więcej węzłów z innych ośrodków naukowych, instytucji rządowych, banków, firm prywatnych i państwowych.
 |
Grudzień, 1969 |
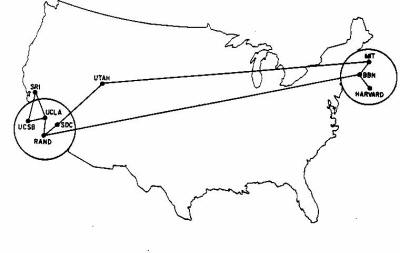 |
Czerwiec, 1970 |
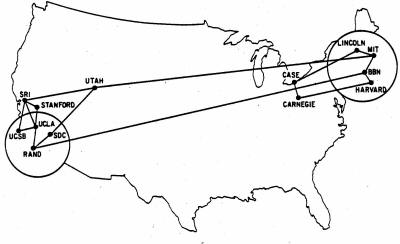 |
Grudzień, 1970 |
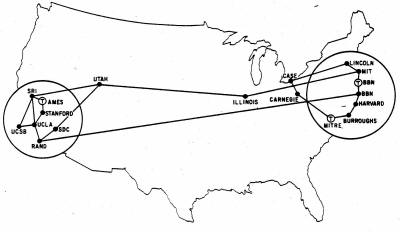 |
Wrzesień, 1971 |
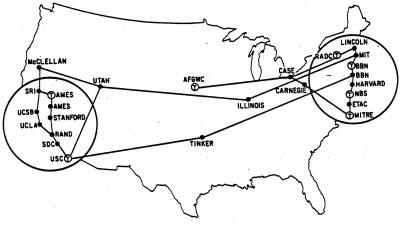 |
Marzec, 1972 |
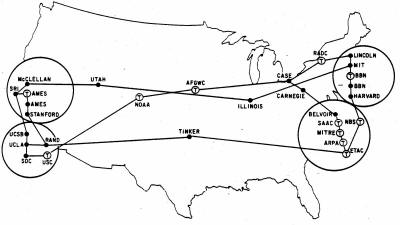 |
Sierpień, 1972 |
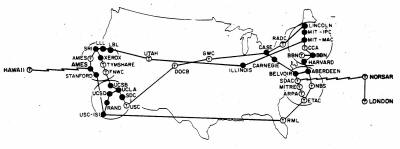 |
Wrzesień, 1973 |
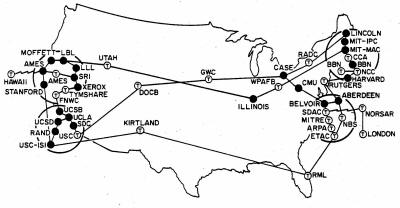 |
Czerwiec, 1974 |
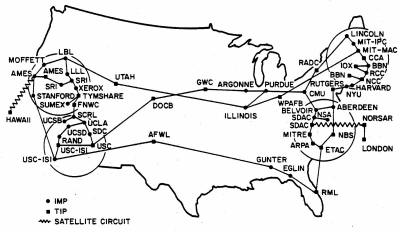 |
Lipiec, 1975 |
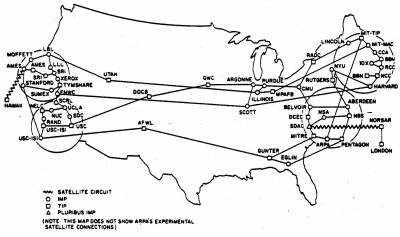 |
Lipiec, 1976 |
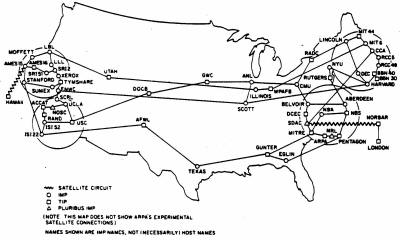 |
Lipiec, 1977 |
Pod koniec lat 80-tych ARPANET objęła swoim zasięgiem całą Ziemię - powstał znany nam Internet.
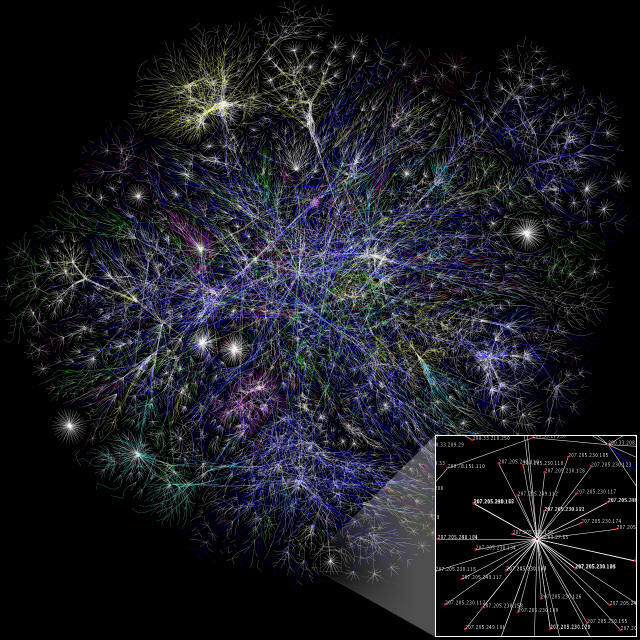
Internet jest obecnie tworem bardzo skomplikowanym. Powyższy obrazek w dużym uproszczeniu przedstawia jego strukturę. Całość przypomina system nerwowy mózgu człowieka - nie zdziwiłbym się, gdyby w niedalekiej przyszłości okazało się, iż Internet wytworzył samoświadomość. Ale wróćmy do rzeczy.
W przeciwieństwie do sieci lokalnej Internet nie łączy ze sobą pojedynczych komputerów, lecz całe sieci komputerowe. Stąd pochodzi jego nazwa:
INTER NET między - sieć
Sieci są połączone za pomocą tzw. sieci szkieletowej (ang. backbone network), która zbudowana jest ze szybkich kanałów transmisyjnych oraz komputerów kierujących przepływem danych - routerów. Routery wybierają w sieci szkieletowej najlepsze trasy dla przesyłanych danych oraz dbają o obejścia zablokowanych lub przeciążonych fragmentów sieci. Dzięki nim informacja trafia niezawodnie do odbiorcy.
Komputery w sieci Internet posiadają przydzielone unikalne numery, które służą do ich identyfikacji. Numery te nazywamy adresami IP. Służą one routerom do określania ścieżki przesyłu danych pomiędzy dwoma komputerami w sieci Internet - analogicznie jak w przypadku połączenia telefonicznego. W wersji 4 protokołu internetowego adresy IP składają się z 4 bajtów (nowa wersja protokołu nr 6 definiuje już 16 bajtowe adresy IP). Adres IP zapisujemy jako czwórkę liczb z zakresu od 0 do 255, rozdzielone kropkami:
nnn.nnn.nnn.nnn gdzie nnn = 0...255
Przykład:
192.193.225.12, 87.66.139.253, 221.188.164.1
Wszystkich możliwych adresów IP jest 256 × 256 × 256 × 256 = 2564 = 4294967296, czyli ponad 4 mld. Ponieważ Internet łączy ze sobą nie pojedyncze komputery, ale całe sieci komputerowe, adresy IP dzielą się na kilka klas (dzisiaj podział ten nie jest już tak sztywny jak dawniej). Adres IP zawiera numer sieci komputerowej oraz numer komputera wewnątrz tej sieci.
W klasie A pierwszy bajt określa numer sieci, a pozostałe 3 bajty są numerem hosta wewnątrz tej sieci:
1...126.hhh.hhh.hhh
Pierwszy bajt może przyjmować wartości tylko od 1 do 126 (0 i 127 są używane do specjalnych celów w sieci). Wynika z tego, iż w klasie A może być tylko 126 dużych sieci komputerowych, a w każdej z nich może znaleźć się 256 × 256 × 256 = 2563 = 16777216 hostów, czyli ponad 16 mln. Ponieważ duże sieci nieefektywnie gospodarują swoimi adresami IP, od 1997 roku mniejsze sieci wypożyczają część numerów klasy A dla swoich hostów. Wymagało to oczywiście odpowiedniej przebudowy oprogramowania routerów, tak aby dane były kierowano do właściwych węzłów, które znajdują się poza siecią posiadającą pulę adresów IP klasy A.
W klasie B dwa pierwsze bajty adresu IP zawierają numer sieci. Pozostałe dwa bajty zawierają numer hosta wewnątrz danej sieci:
128...191.sss.hhh.hhh
Pierwszy bajt przyjmuje wartości od 128 do 191 (64 możliwe wartości). Chodzi o to, aby numer IP klasy B nie wchodził w zakres numerów IP klasy A. Drugi bajt numeru sieci ma wartość dowolną. Zatem w klasie B może być 64 × 256 = 16384 sieci, a w każdej z nich może być do 256 × 256 = 2562 = 65536 hostów.
W klasie C numer sieci zawiera się w 3 pierwszych bajtach. Numer hosta podaje ostatni, czwarty bajt:
192...223.sss.sss.hhh
Pierwszy bajt przyjmuje wartości od 192 do 223 (32 wartości), pozostałe dwa bajty są dowolne, zatem sieci może być 32 × 256 × 256 = 2097152, czyli ponad 2 mln. W każdej z sieci klasy C może wystąpić do 254 hostów (numer 0 i 255 są zarezerwowane na wewnętrzne potrzeby komutacyjne w sieci).
Podsumujmy:
| Klasa | Adres IP | Liczba sieci | Liczba hostów |
| A | 1-126.h.h.h | 126 | 16777216 |
| B | 127-191.s.h.h | 16384 | 65536 |
| C | 192-223.s.s.h | 2097152 | 254 |
Dzisiaj podział na klasy nie jest już tak sztywny jak dawniej. Dzięki rozwojowi oprogramowania sieciowego numery klas A i B mogą być przekierowywane do mniejszych sieci, co umożliwia ich efektywniejsze wykorzystywanie.
eduinf.waw.pl
| pl | – | domena główna, w tym przypadku oznacza nasz kraj. |
| waw | – | poddomena domeny pl. W domenie pl są również poddomeny krakow, onet, wp, interia, google itp. |
| eduinf | – | poddomena należąca do waw.pl. |
Nazwy domenowe zastępują numery IP. Np. zamiast wpisywać do przeglądarki numer IP 142.250.203.131 (sprawdź to) prościej i czytelniej jest wpisać google.pl. Pojawia się tylko jeden problem - routery potrzebują adresów IP, zatem w celu nawiązania połączenia w Internecie nazwa domenowa musi zostać przekształcona na odpowiadający jej numer IP. Możemy to porównać z telefonowaniem do kolegi, którego nazwisko znamy, lecz nie wiemy jaki posiada numer telefoniczny. Problem rozwiązujemy wyszukując numer w książce telefonicznej. Na szczęście w sieci Internet również istnieją "książki telefoniczne" dla nazw domenowych. Nazywamy je serwerami nazw domenowych - w skrócie DNS (ang. Domain Name Server).
Połączenie przy pomocy nazwy domenowej wygląda następująco:
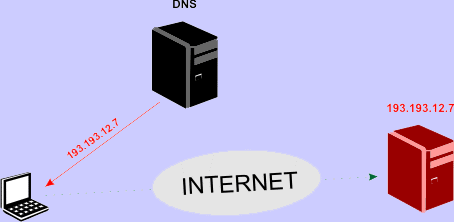
Załóżmy, że nasz komputer chce się połączyć poprzez Internet z komputerem o nazwie domenowej www.uczniak.pl. Nie może tego zrobić bezpośrednio, ponieważ do połączenia potrzebny jest numer IP komputera docelowego, a tego numeru nasz komputer nie zna.
 |
Nasz komputer łączy się zatem ze swoim serwerem nazw domenowych DNS i przesyła mu nazwę www.uczniak.pl. Adres IP serwera DNS jest jednym z parametrów konfiguracyjnych połączenia komputera z Internetem, co zobaczysz za chwilę.
 |
Serwer DNS przeszukuje swoją bazę danych w poszukiwaniu nazwy www.uczniak.pl (w praktyce jest to o wiele bardziej skomplikowane, lecz nie będziemy tutaj wchodzić w szczegóły techniczne działania DNS-ów).
 |
Gdy serwer znajdzie adres IP 193.193.12.7 odpowiadający nazwie domenowej www.uczniak.pl, to odsyła go z powrotem do naszego komputera.
 |
Mając numer IP komputera docelowego, nasz komputer może nawiązać z nim połączenie poprzez sieć Internet.
 |
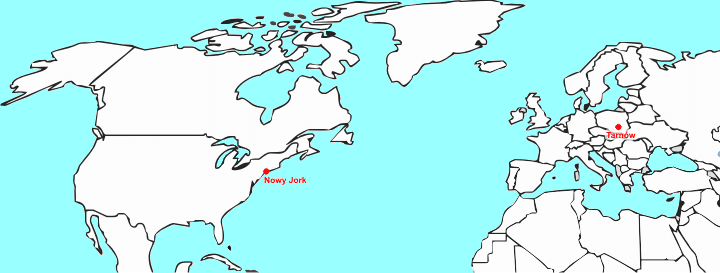 |
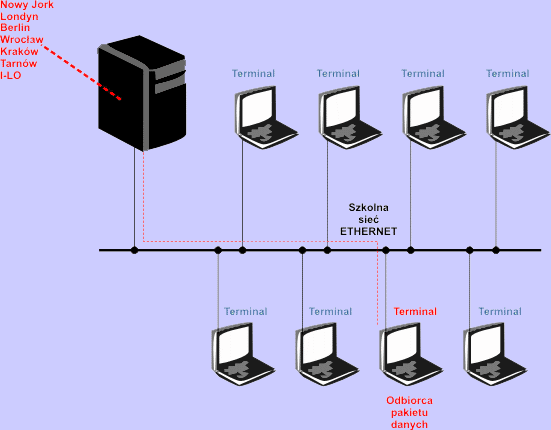
Na podstawie adresu IP zawartego w danych routery stwierdzają, że odbiorca pakietu jest gdzieś w Europie. Kierują zatem dane do serwera europejskiego, np. w Londynie (rzeczywista trasa może być inna, gdyż zależy od faktycznej infrastruktury sieciowej, tutaj chodzi nam jedynie o pokazanie zasady działania tego procesu).
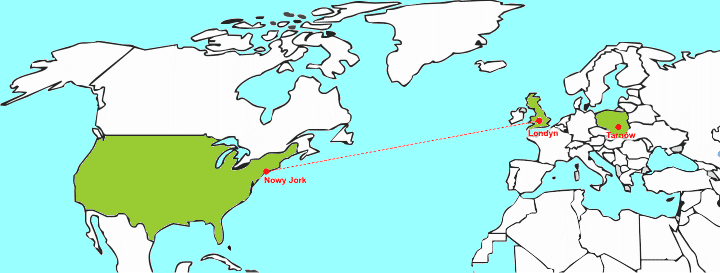 |
Router w Londynie znów patrzy na adres IP zawarty w pakiecie i na jego podstawie stwierdza, że odnosi się on do jakiejś sieci w Europie Środkowej. Wysyła pakiet do routera w Berlinie.
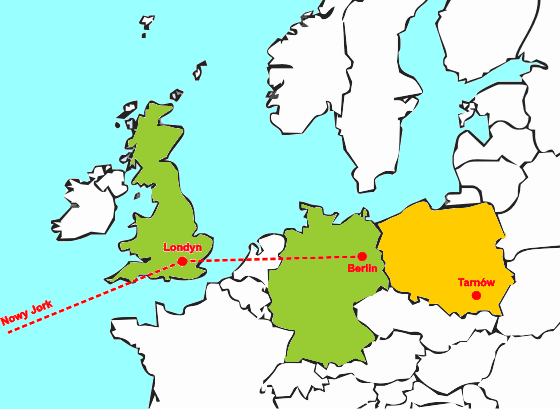 |
Router w Berlinie analizuje adres IP zawarty w przesyłanym pakiecie i stwierdza, że jego sieć docelowa leży w Polsce. Przesyła pakiet do routera we Wrocławiu.
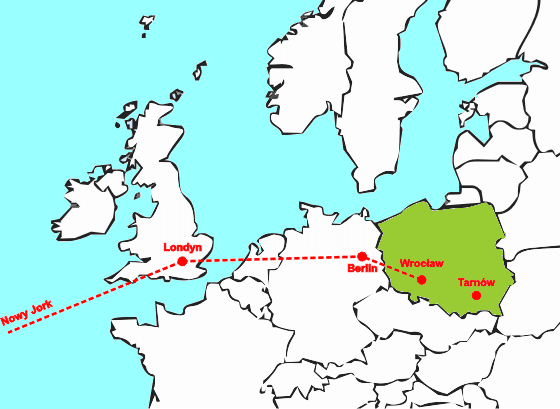 |
Router we Wrocławiu stwierdza, że adres IP pakietu odnosi się do sieci w okolicach Krakowa. Przesyła pakiet do routera w Krakowie.
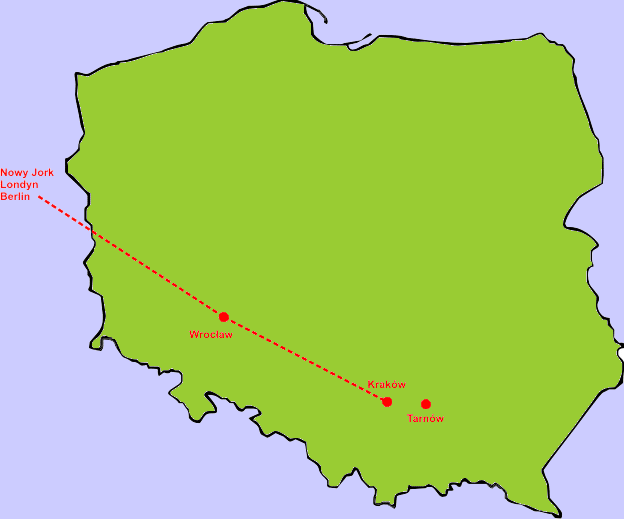 |
Router w Krakowie stwierdza, że sieć o danym adresie IP znajduje się w Tarnowie. Pakiet jest przesyłany do routera w Tarnowie, a dalej do routera w I LO w Tarnowie.
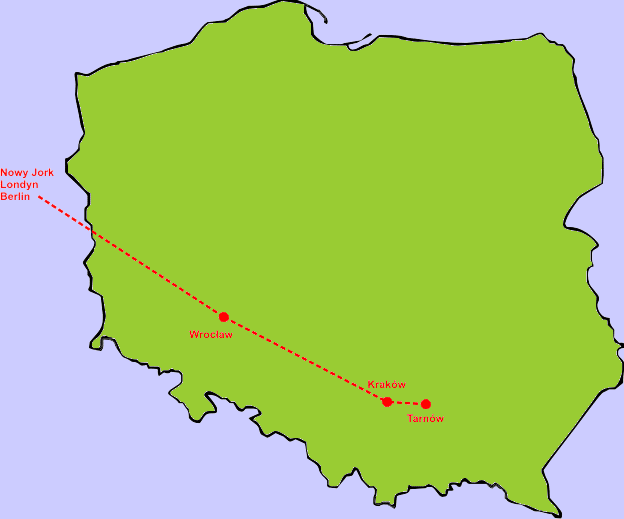 |
W końcu pakiet danych odbiera nasz router szkolny. Teraz na podstawie adresu komputera zawartego w drugiej części adresu IP pakiet danych jest kierowany do właściwego komputera w sieci LAN.
 |
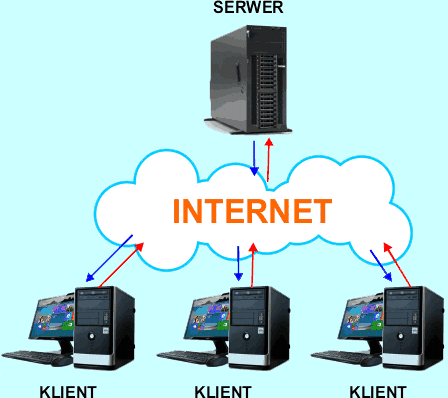 |
Wygląda to w ten sposób, iż klienci wysyłają do serwera żądania obsługi. Jeśli serwer zaakceptuje żądanie danego klienta, to zwraca odpowiedź, w której umieszczona jest pożądana przez klienta informacja. Jeden serwer może obsługiwać wielu klientów. Serwery są zwykle komputerami o dużej mocy obliczeniowej, aby sprawnie mogły obsługiwać żądania od swoich klientów. Każdy komputer dostępny w sieci może stać się serwerem lub klientem określonej usługi sieciowej po uruchomieniu na nim odpowiedniego oprogramowania (czasami komputery są zabezpieczane przez administratorów sieci przed dostępem z zewnątrz, co utrudnia instalowanie na nich oprogramowania serwerowego). Serwer jest dawcą usługi sieciowej, klient jest odbiorcą tej usługi, a Internet jest środowiskiem sieciowym, w którym ta usługa jest wykonywana.
Opiszmy klika podstawowych usług sieciowych.
Poczta elektroniczna jest obecnie powszechną usługą sieciową, która umożliwia użytkownikom przesyłanie do siebie wiadomości w postaci plików tekstowych, które nazywamy listami elektronicznymi lub w skrócie mejlami. Do realizacji tej usługi wykorzystuje się powszechnie model klient serwer.
Klient poczty elektronicznej to program działający na komputerze użytkownika sieci (coraz częściej może nim być zwykła przeglądarka sieciowa, gdy usługa poczty realizowana jest wewnątrz usługi stron internetowych). Program ten pozwala użytkownikowi tworzyć mejle, przesyłać je do serwera poczty oraz pobierać z serwera poczty mejle przesłane tam przez innych użytkowników sieci. W celu współpracy z serwerem poczty klient tworzy na serwerze tzw. konto pocztowe. Konto otrzymuje nazwę unikalną dla każdego klienta. Używane jest ono do tworzenia tzw. adresu e-mail, który składa się z nazwy konta oraz z nazwy domenowej serwera poczty. Np.:
| i-lo@eduinf.waw.pl i-lo - nazwa konta pocztowego @ - znak łączący, tzw. małpa eduinf.waw.pl - nazwa domenowa serwera poczty |
Adres e-mail identyfikuje serwer poczty oraz klienta tego serwera. Używany jest on do adresowania listów e-mail.
Serwer poczty elektronicznej jest komputerem z zainstalowanym oprogramowaniem pocztowym. Dla każdego konta pocztowego serwer tworzy tzw. skrzynki pocztowe, w których gromadzone są listy użytkowników. Skrzynek może być wiele rodzajów. Oto najważniejsze z nich:
Zasada pracy klienta poczty z serwerem jest następująca:
| nazwa_konta@nazwa_domenowa_serwera_poczty |
Usługa przesyłania plików w sieci Internet nosi nazwę usługi FTP (ang. File Transfer Protocol - Protokół Przesyłania Plików). Serwer FTP udostępnia klientom zasoby swoich dysków. Dla klienta FTP są one widoczne jako dysk sieciowy, na którym znajdują się różne katalogi z plikami. Po połączeniu się z serwerem FTP klient może zarówno pobierać z niego pliki jak również przesyłać na serwer swoje pliki (do wydzielonego katalogu serwera).
Dostęp do zasobów serwera może być zabezpieczony hasłem lub anonimowy. W tym drugim przypadku klient nie musi podawać hasła dostępowego. Konto anonimowe zwykle posiada przydzielonych mniej zasobów serwera.
Komputer może stać się serwerem FTP po zainstalowaniu odpowiedniego oprogramowania - tak jest w naszej pracowni, na komputerze nauczycielskim zainstalowany jest serwer FileZilla. Serwer ten działa tylko w obrębie pracowni komputerowej.
Klientem FTP jest aplikacja Filezilla, którą każdy z naszych uczniów ma zainstalowaną na swoim komputerze w pracowni. Sposób obsługi klienta FTP omówiliśmy na poprzednich lekcjach.

Zasada pracy klienta FTP z serwerem jest następująca:
Strona WWW (ang. World Wide Web - Ogólnoświatowa Sieć, czyli Internet) jest zwykłym plikiem tekstowym, w którym za pomocą języka HTML (ang. Hyper Text Markup Language - Język Znaczników Hipertekstowych) opisana jest treść strony. Aby zobaczyć faktyczną treść strony WWW, w przeglądarce internetowej kliknij puste miejsce na wyświetlanej stronie WWW prawym przyciskiem myszki i z menu kontekstowego wybierz opcję Pokaż źródło (nazwa tej opcji zależy od używanej przeglądarki - tutaj odwołujemy się do Internet Explorera). W okienku tekstowym zobaczysz dosyć skomplikowany tekst. Przykładowo, początek tej strony WWW wygląda mniej więcej tak:
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-2"> <meta http-equiv="Content-Language" content="pl"> <title>Usługi w Internecie</title> <meta name="keywords" content="liceum, informatyka, technologia informacyjna, nauka, dydaktyka, programowanie,matura"> <meta name="description" content="Artykuł zawiera treści dydaktyczne lekcji informatyki oraz technologii informacyjnej w liceum"> <link rel="stylesheet" type="text/css" href="../../../001.css"> <base target="_top"> </head> <body> <table border="0" width="100%" cellpadding="0" style="border-collapse: collapse"> <tr> <td width="164" style="text-align: left" valign="top" class="menu_l"> ... </body> </html> |
Może wydać ci się to skomplikowane, lecz odbiorcą tej informacji nie ma być człowiek ale oprogramowanie klienta WWW. Znacznik HTML to napis ujęty w nawiasy trójkątne. Na przykład na początku dokumentu widzimy znacznik <html>. Jeśli przewiniesz stronę na koniec tekstu, to zobaczysz znacznik </html> - jest to tzw. znacznik zamykający bloku. Treść ujęta pomiędzy znacznikami <html> i </html> jest interpretowana jako zapis w języku HTML - obecnie w Internecie występują również inne standardy kodowania stron WWW. Inną parą znaczników jest <head> i </head>. Obejmują one tzw. nagłówek strony WWW, w którym specjalne znaczniki definiują jej parametry - np. znaczniki <title> i </title> określają tytuł strony, który pojawia się na pasku tytułowym okienka przeglądarki. Następnym charakterystyczną parą znaczników jest <body> i </body>. Obejmują one treść strony, czyli to, co się pojawi w oknie przeglądarki. Podsumowując, strona WWW zapisana w języku HTML posiada następującą budowę:
<html>
<head>
...
informacje na temat parametrów strony
...
<title>Tytuł strony</title>
...
</head>
<body>
...
treść strony
...
</body>
</html>
|
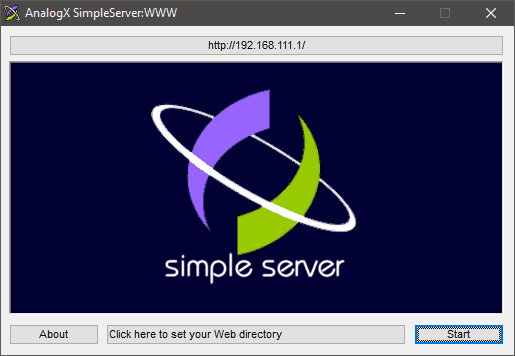
Usługa WWW lub HTTP (ang. Hyper Text Transfer Protocol - Protokół Przesyłania Hipertekstu) polega na przesyłaniu przez serwer plików stron WWW do połączonych z nim klientów. Stronom WWW mogą towarzyszyć również inne pliki - np. obrazki, dźwięki, animacje i filmy. Pliki te również są przesyłane przez serwer. Serwerem WWW może stać się każdy komputer podłączony do Internetu i posiadający publiczny numer IP. Proponuję pobrać z Internetu najprostszy serwer WWW firmy AnalogX. Znajdziemy go wpisując w google.pl hasło:
analogx simple server |
Po zainstalowaniu tego serwera i uruchomieniu użytkownik w zasadzie musi jedynie podać startową stroną WWW (klikając przycisk z napisem Click here to set your Web directory), która ma być automatycznie przesyłana przez serwer do klientów, oraz uruchomić usługę (klikając na przycisk Start). Z serwerem można się łączyć za pomocą numeru IP, który widnieje u góry okna programu.
Klientem WWW lub HTTP jest każda przeglądarka sieci Internet - Internet Explorer, Firefox, Mozilla, Opera, Google Chrome, Apple Safari i inne - jest w czym wybierać.
Zasada współpracy serwera WWW z klientami tej usługi jest następująca:
Naciśnij klawisze Window+R. W pasku tekstowym wpisz:
cmd
i kliknij przycisk OK. Spowoduje to uruchomienie okna tekstowego konsoli, w którym możemy wpisywać polecenia za pomocą tekstu. Wpisujemy zatem:
ipconfig
Polecenie to wyświetli nam podstawowe informacje o naszym połączeniu internetowym:
IPv4 Address - określa numer IP naszego komputera Subnet Mask - rozdziela numer sieci od numeru hosta Default Gateway - numer IP serwera, poprzez który jesteśmy podłączeni do Internetu.
Jeśli wydamy polecenie ipconfig /all , to otrzymamy pełne informacje o konfiguracji naszego połączenia internetowego. Między innymi dostajemy informacje o numerach IP serwerów DNS, z którymi współpracuje nasz komputer przy zamianie nazw domenowych na odpowiadające im numery IP.
Adres publiczny jest adresem komputera, który jest widoczny w całej sieci Internet. Jeśli pracujesz w sieci domowej lub szkolnej, to twój komputer może nie posiadać adresu publicznego, tylko adres lokalny. Adresy lokalne są widoczne tylko wewnątrz sieci lokalnej. Jak to sprawdzić? Bardzo prosto. Odczytaj adres IP swojego komputera. Jeśli rozpoczyna się on od 192.168.0 to jest adresem lokalnym. Drugim sposobem, jest wejście na stronę:
https://www.whatismyip.com/
Następnie sprawdzamy, czy adres IP naszego komputera jest taki sam, jak adres IP podany na stronie. Jeśli tak, to mamy adres publiczny. Jeśli nie, to mamy adres lokalny. Normalnie to w niczym nie przeszkadza, jedynie problemy zaczną się, gdybyśmy zechcieli udostępniać w Internecie jakieś usługi. Wtedy musisz posiadać adres publiczny lub skorzystać z firm, które sprzedają udostępnianie takich usług. Ja na przykład korzystam z firmy udostępniającej mi serwer WWW, który obsługuje ten serwis.
Zwróć uwagę, iż na komputerach w pracowni pierwsze trzy bajty każdego numeru IP są takie same - jest to numer naszej sieci. Ostatni bajt jest natomiast na każdym komputerze inny - jest to numer komputera wewnątrz danej sieci. Zapisz sobie numer IP swojego komputera, serwera oraz DNS.
Wpisz w oknie konsoli:
ping IP_twojego_komputera ping IP_serwera ping IP_DNS
ping onet.pl ping wp.pl ping google.pl
Polecenie ping pozwala odpytać docelowy komputer. Polega to na przesłaniu krótkiego pakietu danych do komputera, którego adres IP lub nazwę domenową podamy jako parametr. Jeśli komputer docelowy jest obecny w sieci (nawet w Japoni) i nie ma filtrowanej łączności z siecią, to odbierze przesłany pakiet i wyśle potwierdzenie. W ten sposób możemy przetestować połączenie z wybranym komputerem w sieci. Dodatkową cechą polecenia ping jest automatyczna zamiana nazw domenowych na odpowiadające im numery IP, dzięki temu możemy szybko sprawdzić, jaki numer IP odpowiada danej nazwie domenowej:
C:\>ping eduinf.waw.pl
Pinging eduinf.waw.pl [5.252.230.154] with 32 bytes of data:
Reply from 5.252.230.154: bytes=32 time=9ms TTL=54
Reply from 5.252.230.154: bytes=32 time=9ms TTL=54
Reply from 5.252.230.154: bytes=32 time=9ms TTL=54
Reply from 5.252.230.154: bytes=32 time=9ms TTL=54
Ping statistics for 5.252.230.154:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 9ms, Maximum = 9ms, Average = 9ms
Innym ciekawym poleceniem jest:
tracert adres IP tracert nazwa domenowa
Umożliwia ono śledzenie trasy połączenia w sieci szkieletowej, po której przesyłane są pakiety danych od naszego komputera do komputera docelowego (ang. tracert - trace route, czyli śledź trasę).
C:\>tracert www.google.pl Tracing route to www.google.pl [142.250.203.131] over a maximum of 30 hops: 1 <1 ms <1 ms <1 ms 192.168.0.1 2 1 ms 1 ms 1 ms static-66-1.is.net.pl [82.115.66.1] 3 1 ms 1 ms 1 ms 10.10.140.254 4 1 ms <1 ms <1 ms host-89-228-5-138.dynamic.mm.pl [89.228.5.138] 5 <1 ms <1 ms <1 ms host-89-228-5-137.dynamic.mm.pl [89.228.5.137] 6 1 ms <1 ms <1 ms host-176-221-99-245.dynamic.mm.pl [176.221.99.245] 7 10 ms 10 ms 12 ms host-176-221-97-39.dynamic.mm.pl [176.221.97.39] 8 9 ms 9 ms 9 ms host-89-228-4-5.dynamic.mm.pl [89.228.4.5] 9 9 ms 9 ms 9 ms c-093105142037.vectranet.pl [93.105.142.37] 10 * * * Request timed out. 11 * * * Request timed out. 12 * 9 ms 9 ms 142.250.163.0 13 9 ms 9 ms 9 ms 142.250.37.193 14 10 ms 10 ms 10 ms 209.85.253.225 15 9 ms 9 ms 9 ms waw07s06-in-f3.1e100.net [142.250.203.131] Trace complete.
ipconfig - informacja o numerach IP
naszego komputera oraz serwera udostępniającego połączenie z Internetem
ping - pozwala przetestować połączenie z wybranym komputerem w sieci
tracert - pozwala prześledzić trasę przesyłu pakietów do zadanego
komputera w sieci
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.
