Autor artykułu: mgr Jerzy Wałaszek
©2017 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2017 mgr
Jerzy Wałaszek
|
Języki programowania
Język programowania (ang.
programming language) umożliwia wydawanie poleceń
komputerowi. W pierwszych komputerach stosowano binarne kody
instrukcji, które bezpośrednio rozumie komputer . Procesor
najpierw pobiera kod instrukcji, a następnie analizuje go i na
podstawie odpowiednich pól wykonuje określone operacje. Na
przykład, w jednym z pierwszych komputerów Konrada Zuse program
był tworzony na taśmie filmowej w postaci dziurek, które
odzwierciedlały binarną postać instrukcji.
Taśma filmowa z kodem programu
Gdy liczba instrukcji maszyny cyfrowej rosła, a same instrukcje stawały się coraz bardziej skomplikowane, wymyślono język asemblera (ang. assembler language). Zamiast binarnych kodów instrukcji w języku asemblera stosuje się ich nazwy symboliczne (jak ADD, SUB, JMP). Dzięki temu łatwiej je zapamiętać, a i sam program staje się dużo prostszy.
Procesor rozumie tylko i wyłącznie swój kod binarny. Dlatego tworząc programy w asemblerze musimy je kompilować, czyli zamieniać na postać binarną. Konwersji takiej dokonuje program, który również nazywamy asemblerem. Pierwszy asembler musiał jednak być napisany bezpośrednio w kodzie binarnym. Asembler daje programiście dostęp do wszystkich składników komputera. Jednakże tworzenie programu jest bardzo żmudne, ponieważ każdą operację należy rozbijać na poszczególne instrukcje procesora. Np. sprawdzenie, czy komórki o etykietach L1 i L2 są sobie równe, wymaga kilku instrukcji procesora:
Czyż nie byłoby lepiej zapisać:
I tak dochodzimy do koncepcji języków wysokiego poziomu – HLL (ang. High Level Language). Asembler, a tym bardziej kod binarny instrukcji procesora, to języki niskiego poziomu – LLL (ang. Low Level Language), które operują bezpośrednio na zasobach komputera: na procesorze, pamięci, rejestrach wejścia/wyjścia. Aby w nich efektywnie programować, programista musi posiadać dużą wiedzę na temat budowy komputera oraz urządzeń towarzyszących. Również musi dokładnie wiedzieć, w jaki sposób realizować złożone polecenia. Pomyłki w kodzie są trudne do wyłapania. Wszystko to powoduje, że chociaż asembler jest bardzo potężnym narzędziem, to jednak jest również bardzo trudny w opanowaniu i mało efektywny przy dużych projektach. Dzisiaj w asemblerze tworzone są tylko fragmenty programów, które muszą być naprawdę szybkie i efektywne. Język wysokiego poziomu oddala się od sprzętu komputera i pozwala tworzyć bardziej abstrakcyjne konstrukcje, które zbliżone są do pojęć matematycznych. Dzięki temu programista może dużo szybciej tworzyć złożone programy, niż jest to możliwe w asemblerze. Wszystkie języki wysokiego poziomu muszą być przetwarzane na postać binarną (nie dotyczy to języków interpretowanych, tzw. skryptowych, o których dowiemy się później). Konwersję taką wykonuje program zwany kompilatorem (ang. compiler). Pierwsze języki wysokiego poziomu zaczęły się pojawiać po II Wojnie Światowej. Wcześniej stosowano kody binarne oraz asemblery. Poniżej podajemy chronologiczną listę najważniejszych języków programowania (niech cię nie przeraża ich liczba, i tak nie są to wszystkie języki programowania):
|
||||||||||||||||||||||
Język programowania C++
Język C++ jest językiem programowania stworzonym przez Bjarne Stroustrupa, profesora Texas A&M University. Jest to język wysokiego poziomu i należy do grupy języków kompilowanych. Oznacza to, iż programista w edytorze tworzy tekst programu, który następnie jest przekazywany do kompilatora. Kompilator analizuje otrzymany tekst i na jego podstawie tworzy program wynikowy zawierający binarne instrukcje dla procesora.
Języki wysokiego poziomu są bardziej czytelne dla ludzi. Jednakże procesor nie potrafi bezpośrednio wykonywać zawartych w takim programie poleceń - program musi być przetłumaczony do postaci zrozumiałej dla procesora, czyli do binarnych kodów instrukcji maszynowych. Do programowania w języku C++ będziemy używali zintegrowanego środowiska programowania (ang. IDE - Integrated Developement Environment), które zawiera edytor oraz kompilator. Na lekcjach oprzemy się o darmowe środowisko Code::Blocks oraz o pakiet Borland C++ Builder 6.0 Personal Edition, które można pobrać z sieci Internet. Na komputerze domowym ucznia musi być bezwzględnie zainstalowane podane środowisko programowania, aby mógł wykonywać ćwiczenia w domu. |
||||||||||||||||||||||
Instalacja Code::Blocks w systemie Windows
Code::Blocks jest bardzo wygodną, darmową i legalną aplikacją,
która służy do tworzenia programów w języku C i C++. Jest to tzw.
zintegrowane środowisko programowania IDE (ang.
Integrated Developement Environment), które zawiera edytor kodu z
kolorowaniem składni, kompilator oraz program uruchomieniowy. Praca w
środowisku zintegrowanym jest bardzo wygodna i szybka, ponieważ bierze
ono na siebie wiele operacji, które programista musiałby wykonywać
ręcznie, pracując bez takiego środowiska.
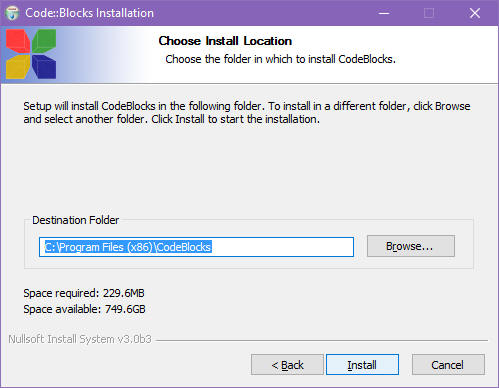
Poniższy opis dotyczy instalacji CodeBlocs 16.01 w systemie Windows 10. Dla innych systemów Windows instalacja jest praktycznie identyczna. Pobranie instalatoraPrzejdź do strony: Wybierz opcję:
Download the binary release
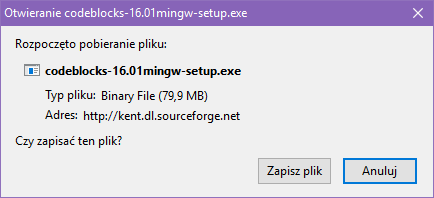
Spowoduje to przejście do strony pobierania aplikacji. U samej góry wybierz swój system operacyjny, mianowicie Windows XP / Vista / 7 / 8.x / 10. Dla systemu Windows dostępne jest kilka wersji instalatora. Code::Blocks. Dla naszych potrzeb należy wybrać instalator z kompilatorem MingW. W przypadku wersji 16.01 będzie to plik o nazwie codeblocks-16.01mingw-setup.exe. Po prawej stronie wybierz źródło ładowania: Sourceforge.net. Przejdziesz w ten sposób do witryny Sourceforge, z zostanie automatycznie załadowany instalator Code::Blocks. Jeśli twoją przeglądarką sieci jest Firefox, to pojawi się okienko:
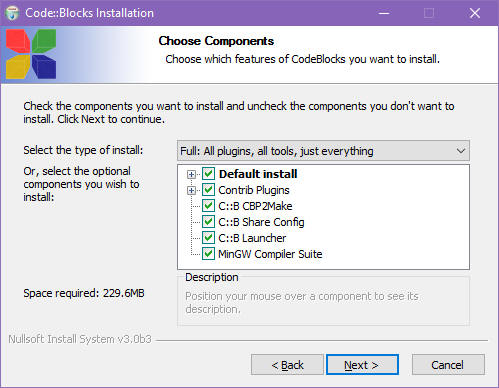
W oknie wybierz przycisk Zapisz plik. Plik zostanie pobrany i zapisany na twoim dysku w katalogu przeznaczonym na odczytane z sieci pliki (zależy on od ustawień przeglądarki Firefox). InstalacjaUruchom instalator. Zaczną się pojawiać kolejne okienka dialogowe instalacji. Poniżej masz przetłumaczoną ich treść. Jest to typowy proces instalacyjny i, jeśli nie masz jakiś specjalnych powodów, to po prostu zatwierdzaj je klikając na przycisk Next.
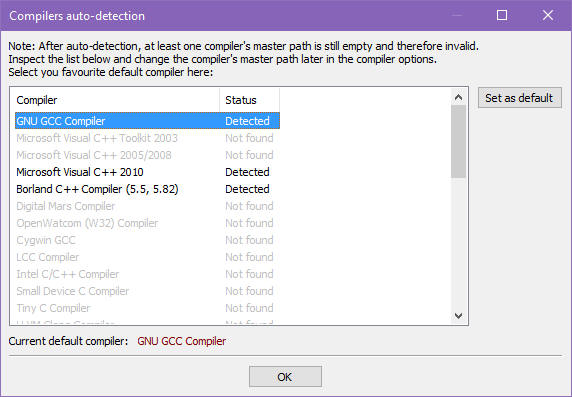
Uruchomienie i test instalacjiUruchom Code::Blocks (Launcher). Przy pierwszym uruchomieniu Code::Blocks musi wybrać kompilator, który będzie używany do kompilacji programów. Jeśli wybrałeś instalację z MIngW, to kompilator taki został zainstalowany wraz z Code::Blocks. W oknie automatycznego wykrywania zainstalowanych kompilatorów, które się pojawi, zaznacz GNU GCC Compiler i kliknij w przycisk Set as default (ustaw jako standardowy).
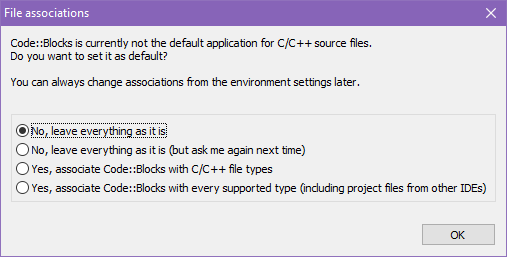
Kliknij w przycisk OK. Przed uruchomieniem IDE aplikacja wyświetli następujące okno dialogowe:
Ustawia się tutaj skojarzenia plików źródłowych C i C++ ze środowiskiem Code::Blocks. Pozostaw okienko bez zmian, chyba że dokładnie wiesz co i dlaczego robisz. Kliknij przycisk OK. Pojawi się okno startowe.
|
||||||||||||||||||||||
Projekt w Code::BlocksUtwórz na dysku katalog na projekty programów w języku C++.
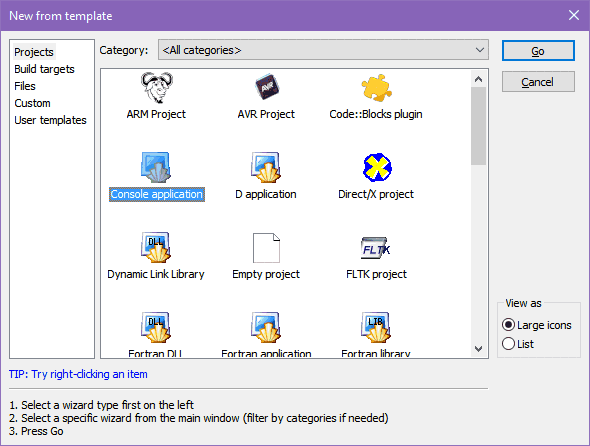
Uruchom Code::Blocks. Na ekranie startowym zobaczysz opcję Create a new project (Utwórz nowy projekt). Kliknij ją lewym przyciskiem myszki. Zostanie otwarte okienko dialogowe wyboru typu projektu:
Wybierz opcję Console application (Aplikacja konsoli). Co to jest aplikacja konsoli? Kiedyś, dawno temu, gdy jeszcze nie powstał system Windows, komputery programowane były w systemie DOS w trybie znakowym. Ekran wyświetlał ustalony zestaw znaków. Tryb ten pojawia się czasem na niektórych starszych komputerach IBM-PC przy starcie systemu, zanim Windows/Linux przejmą kontrolę. Ekran w trybie tekstowym wyglądał tak:
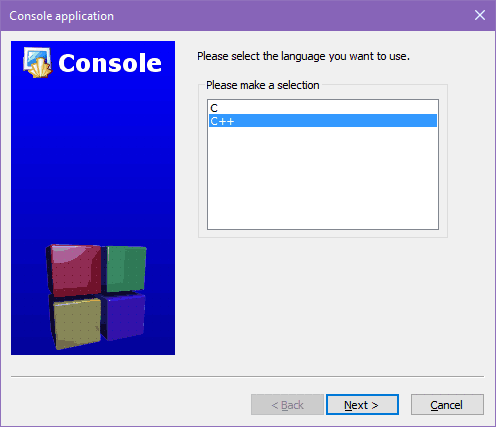
Na dzisiejszych komputerach tryb ten stał się już przestrzały, jednak wciąż możemy go symulować w Windows oraz w Linuxie. Zaletą konsoli jest prostota używania. Nie musisz walczyć z procedurami graficznymi Windows, aby wyświetlić wynik działania swojego programu: po prostu przesyłasz do konsoli tekst, a ten zostanie pokazany. Gdy będziesz programował mikrokontrolery, to nawet taka prosta konsola nie będzie dostępna. Ale o tym później. Gdy wybierzesz aplikację konsoli, to twój program otrzyma możliwość wysyłania tekstu do konsoli oraz odczytywania informacji, którą użytkownik wprowadził z klawiatury. Zatwierdź wybór w oknie dialogowym przez kliknięcie w przycisk Go. Pojawi się następne okno dialogowe z wyborem języka projektu:
Zaznaczasz C++ i klikasz w przycisk Next. Pojawi się następne okno dialogowe, które jest bardzo ważne.
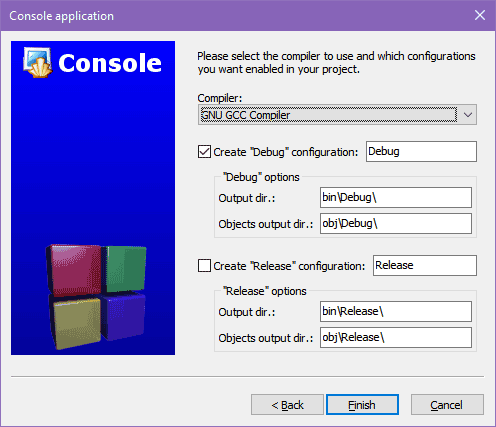
W polu Project title (nazwa projektu) wpisz wybraną przez siebie nazwę dla projektu. Nazwę tę otrzyma również program wynikowy. Dla prostoty będziemy sobie projekty kolejno numerować. Ten jest pierwszy, wpisz zatem nazwę p01 (projekt nr 1). W polu Folder to create peroject in (katalog dla projektu) należy wpisać ścieżkę do katalogu, który utworzyłeś na swoje projekty. Nauczyciel poda ci, co należy tutaj wpisać. Nie kieruj się zawartością tego pola na powyższym obrazku, ponieważ to odnosi się do mojego prywatnego komputera, na którym przygotowuję ten artykuł. Jeśli nie pamiętasz ścieżki do katalogu, w którym ma zostać utworzony projekt, to kliknij lewym przyciskiem myszki przycisk z trójkropkiem, a następnie wybierz odpowiedni katalog. Pozostałych pól nie zmieniaj, ponieważ Code::Blocks zarządza nimi automatycznie: Project filename (nazwa pliku projektu) określa nazwę pliku, w którym środowisko zapisuje informacje o twoim programie. Plik projektu posiada standardowo taką samą nazwę jak ta w pierwszym polu i rozszerzenie cbp (Code::Blocks project). Resulting filename (wynikowa nazwa pliku) Code::Blocks dla każdego projektu tworzy osobny katalog o nazwie takiej samej, jaką ma projekt – dzięki temu pliki nie będą się mieszały w różnych projektach. Katalog ten jest umieszczany w katalogu, którego ścieżkę dostępu umieścisz w drugim polu. Do katalogu projektu trafia plik projektu i tutaj możemy zobaczyć pełną ścieżkę dostępu do tego pliku. Kliknij w przycisk Next. Pojawi się ostatnie okno dialogowe:
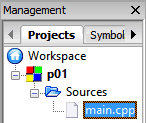
W tym oknie określa się sposób generacji programu wynikowego. Konfiguracją wybraną jest tryb Debug (uruchomieniowy). W tym trybie kompilator umieszcza w kodzie programu dodatkowe informacje, które programista może wykorzystać do śledzenia wykonania programu i wyłapywania błędów. Kod jest przez to dłuższy i może działać nieco wolniej. Tryb Release (wydawniczy) jest używany, gdy program został już uruchomiony i nie zawiera błędów. Nas to nie dotyczy, ponieważ będziemy pisać bardzo proste programy. Nic tu nie zmieniaj, kliknij przycisk Finish. Środowisko utworzy projekt programu. Na bocznym panelu Management (zarządzanie – jeśli panel jest niewidoczny, wciśnij Shift+F2) rozwiń drzewko projektu i kliknij dwukrotnie w plik main.cpp.
Spowoduje to załadowanie pliku do edytora. Czcionkę w edytorze możesz szybko powiększać lub pomniejszać wciskając Ctrl i kręcąc kółkiem myszki lub naciskając klawisze + - na klawiaturze numerycznej. Ponieważ rozpoczynasz naukę języka C++, usuń wszystko z edytora i wprowadź poniższy kod.
Program w języku C++ zbudowany jest z tzw. funkcji, czyli fragmentów kodu, które można wielokrotnie używać. Najprostszy program posiada tylko jedną funkcję, która nosi nazwę main (główna). Nazwa ta musi być pisana małymi literami, ponieważ język C++ rozróżnia duże i małe litery. Wykonanie programu w języku C++ zawsze rozpoczyna się od kodu w funkcji main, dlatego jest to główna funkcja programu. Powyższy program zawiera pustą funkcję main, czyli po prostu nic nie robi, lecz można go skompilować i uruchomić, a o to nam w tym momencie chodzi. Aby skompilować program (czyli utworzyć na dysku plik programu z rozszerzeniem exe), kliknij myszką na ikonę (na pasku narzędziowym u góry okna):
lub naciśnij klawisze Ctrl+F9. Tekst programu zostanie przekazany do kompilatora, który zamieni go w program uruchamialny o rozszerzeniu exe. Postęp kompilacji możesz obserwować na dolnym panelu – jeśli jest niewidoczny, naciśnij klawisz F2. Pojawi się tam następujący tekst:
-------------- Build: Debug in p01 (compiler: GNU GCC Compiler)--------------- mingw32-g++.exe -Wall -fexceptions -g -c D:\cprj\p01\main.cpp -o obj\Debug\main.o mingw32-g++.exe -o bin\Debug\p01.exe obj\Debug\main.o Output file is bin\Debug\p01.exe with size 27.77 KB Process terminated with status 0 (0 minute(s), 1 second(s)) 0 error(s), 0 warning(s) (0 minute(s), 1 second(s))
W tym momencie interesuje cię tylko ostatni tekst, w którym pojawi się informacja o wykrytych błędach (errors) i ostrzeżeniach (warnings) oraz o czasie kompilacji. Jeśli w programie znajdą się błędy, to nie powstanie program uruchamialny. Gdy kompilacja przebiegnie bez błędów, to będziesz mógł uruchomić swój program. Można to zrobić z poziomu Windows lub z poziomu środowiska Code::Blocks. Na lekcjach będziemy korzystali najczęściej z tego drugiego sposobu. Aby uruchomić program, myszką na ikonę (na pasku narzędziowym u góry okna):
Program zostanie uruchomiony i na ekranie pojawi się okno konsoli, w którym będzie wyświetlony napis:
Napis ten pochodzi nie z programu (bo nasz program przecież nic nie robi), lecz ze środowiska Code::Blocks. Informuje cię ono, że program zakończył działanie, zwracając kod 0 (w nawiasie jest podana wartość szesnastkowa tego kodu), a czas wykonania wyniósł 0,047s. Gdy naciśniesz jakiś klawisz (najlepiej ESC), okno konsoli zostanie zamknięte i powrócisz do edytora. Funkcja main() zwraca wartość całkowitą, którą można wykorzystać (i często to się robi) do przekazania dodatkowych informacji przez program - np. czy wykonanie powiodło się, czy też wystąpił jakiś błąd. Do zwracania wartości przez funkcję używamy polecenia return. Jeśli je pominiesz, to funkcja zwróci zero. Zmień program w edytorze na poniższy:
Instrukcję języka C++ kończy się za pomocą średnika. Dlatego po liczbie 155 mamy średnik. Jeśli teraz skompilujesz i uruchomisz program, w oknie konsoli pojawi się informacja:
Instrukcja return kończy działanie funkcji. Ponieważ jest to ostatnia instrukcja w naszym programie, jej wykonanie powoduje zwrócenie odpowiedniego kodu i zakończenie działania programu. Zwykle program w C++ musi odczytywać dane z konsoli i wyprowadzać na nią wyniki swojego działania. Operacje wejścia/wyjścia nie są częścią definicji języka C++, lecz osobną biblioteką. Jeśli chcemy z nich korzystać, to musimy poinformować kompilator o obiektach, które tych operacji dokonują. Definicje obiektów zawarte są w tzw. plikach nagłówkowych (ang. header files), które dołączamy do programu dyrektywą #include. Wpisz poniższy program:
Pliki nagłówkowe są bardzo wygodnym rozwiązaniem - zamiast w każdym programie wpisywać żmudnie definicje tych samych obiektów, wpisujemy jedynie prostą dyrektywę. Przed rozpoczęciem kompilacji plik źródłowy jest wstępnie obrabiany przez tzw. preprocesor. Wyszukuje on w programie źródłowym swoich poleceń, które nazywamy dyrektywami preprocesora. Np. polecenie #include każe preprocesorowi zastąpić się zawartością odpowiedniego pliku nagłówkowego, który jest wstawiany w miejscu tej dyrektywy. Następnie tak zmieniony plik wędruje do kompilatora, który ma już pod ręką wszystkie potrzebne definicje. Plik nagłówkowy iostream definiuje tzw. strumienie wejścia/wyjścia konsoli (ang. input output streams). Strumień wyjścia cout (ang. console output) pozwala wyświetlać informację w oknie konsoli. Strumień wejścia cin (ang. console input) z kolei pozwala odczytywać informację wpisaną przez użytkownika z klawiatury. Wpisz poniższy program:
Po uruchomieniu zobaczymy w oknie konsoli napis:
<< jest operatorem przesłania danych do strumienia. endl to tzw. manipulator powodujący przejście z wydrukiem do następnego wiersza w oknie konsoli. Dzięki niemu po napisie Jestem twoim programem w C++ mamy jeden pusty wiersz odstępu. Zamiast manipulatora endl można w tekście umieszczać znaki końca wiersza - \n:
Zauważ, że na końcu pierwszego tekstu nie dodajemy średnika, ponieważ instrukcja nie jest tutaj jeszcze zakończona. Po prostu kontynuujemy przesyłanie dalszej części tekstu w drugim wierszu. Nazwy cout oraz endl są poprzedzone napisem std::. Jeśli go usuniesz, to program nie da się skompilować, ponieważ kompilator nie potrafi odnaleźć cout i endl. Napis std to tzw. przestrzeń nazw, w której żyją obiekty biblioteki STL. Wyobraź sobie ją jako worek z napisem std. Poza tym workiem nazwy zdefiniowanych w nim obiektów są niedostępne, o ile nie poprzedzisz je napisem std:: - wtedy kompilator będzie po prostu wiedział, gdzie ich szukać. Możesz jednakże poinformować kompilator, że chcesz standardowo korzystać z danej przestrzeni nazw - do tego celu służy dyrektywa using namespace, za którą wpisujemy nazwę przestrzeni nazw. Gdy taką dyrektywę umieścisz w swoim programie, to nie będziesz musiał poprzedzać nazw cout, cin i innych z STL kwalifikatorem std:: - do duże ułatwienie. Dyrektywa using namespace std mówi po prostu kompilatorowi, że jeśli nie znajdzie danej nazwy w standardowym środowisku, to ma jej poszukać w "worku" o nazwie std. Przestrzenie nazw zmniejszają ryzyko konfliktów nazw różnych obiektów i z tego powodu znalazły się w języku C++. Uwierz nam, to dobry wynalazek. Wpisz poniższy program:
Na początku programu umieszczamy zwykle krótki komentarz informujący użytkownika o przeznaczeniu danego programu, autorze i dacie utworzenia. Komentarze mamy za darmo - nie są one przenoszone do programu wynikowego i w żaden sposób nie zwiększają jego pojemności ani nie zmniejszają szybkości działania. Komentujmy zatem programy - staną się o wiele czytelniejsze nawet dla samych ich autorów - szczególnie po upływie kilku tygodni od daty utworzenia.
PodsumowanieProgram w języku C++ posiada następującą strukturę:
|
||||||||||||||||||||||
Zmienne
Zwykle chcemy przetwarzać w programie pewne dane. Do ich przechowywania
służą zmienne (ang. variables). Zmienna jest
fragmentem pamięci komputera, w którym program przechowuje określoną
informację. Przed pierwszym użyciem zmiennej musimy ją zadeklarować, czyli
określić rodzaj przechowywanej w niej informacji oraz nazwę, poprzez którą
będziemy się odwoływali w programie do tej informacji. Deklaracja zmiennej w
języku C++ jest następująca:
typ_danych nazwa_zmiennej;
Przykłady deklaracji zmiennych:
int a; // zmienna a jest zmienną U2 int a,b,c,d; // w jednej definicji można umieścić kilka zmiennych unsigned int x1,x2,wynik; // zmienne NBC
Często informacja jest wprowadzana do zmiennych z klawiatury komputera. W ten sposób użytkownik może podać dane, które komputer następnie przetworzy w programie. Odczytu danych z klawiatury dokonujemy w języku C++ przy pomocy strumienia cin (ang. console input – wejście konsoli). Składnia jest następująca
cin >> nazwa_zmiennej;
W jednym rozkazie można odczytywać informacje do kilku różnych zmiennych:
cin >> a >> b >> c; // Odczyt kolejno do zmiennej a, b i c
W programie nie ma polskich znaków. Spowodowane jest to ty, iż firma Microsoft przyjęła inny sposób kodowania polskich literek w graficznym systemie Windows i inny w znakowym systemie konsoli. Rozwiązanie tego problemu pokażę później, na lekcji o tekstach w C++. Przykładowe uruchomienie
|
||||||||||||||||||||||
Operator przypisania
Do przetwarzania danych w programie C++ używany jest operator przypisania
(ang. assignement operator). Posiada ona następującą postać:
zmienna = wyrażenie;
Komputer oblicza wartość wyrażenia i wynik umieszcza w podanej zmiennej. Znaku = nie traktuj jako równość matematyczną, jest to symbol operacji przypisania.
Wyrażenie z operatorem przypisania posiada wartość równą wartości wyrażenia po prawej stronie operatora. Przykład:
cout << (a = 5) << endl; Wynikiem wykonania tej instrukcji jest liczba 5, ponieważ to stoi po prawej stronie operatora =. Dzięki tej własności możemy w języku C++ przypisać tę samą wartość do kilku zmiennych. Zamiast pisać:
a = 5; b = 5; c = 5;
możemy zapisać prościej:
a = b = c = 5; |
||||||||||||||||||||||
Instrukcje modyfikacji zmiennej
Język C++ posiada dwa użyteczne operatory do zwiększania i zmniejszania
zawartości zmiennej:
++ - zwiększa zawartość zmiennej o 1-- - zmniejsza zawartość zmiennej o 1
Operatory te można stosować na dwa sposoby:
++ zmienna lub
zmienna ++ lub
zmienna --
Jeśli operacja zwiększania zmiennej jest samodzielną instrukcją, to nie ma znaczenia, który z tych sposobów użyjemy. Poniższe dwa programy dają identyczne wyniki:
W obu programach tworzone są dwie zmienne a i b. Zmiennej a nadajemy wartość 125, a zmiennej b 30. Następnie program zwiększa zawartość zmiennej a o 1 do 126, a zawartość zmiennej b zmniejsza o 1 do 29. Na koniec zawartości zmiennych są kolejno wyświetlane i otrzymujemy liczby 126 i 29. W pierwszym programie operatory ++ i -- stosujemy przed zmiennymi, a w drugim po zmiennych. Jeśli operator zwiększania ++ lub zmniejszania -- zastosujemy do zmiennej użytej w wyrażeniu, to bardzo istotne jest, którą z form wybierzemy:
++ zmienna, -- zmienna : najpierw modyfikuje zawartość zmiennej, a
następnie wynik jest używany do obliczeń w wyrażeniuzmienna ++, zmienna -- : w wyrażeniu stosowana jest bieżąca
zawartość zmiennej, a następnie po wyliczeniu wyrażenia zmienna jest
modyfikowana.
Przykład:
Poniższe dwa programy dają różne wyniki:
Programy różnią się jedynie sposobem umieszczenia operatorów ++ oraz -- w
stosunku do modyfikowanej zmiennej. W obu przypadkach zmienna a
przyjmuje na końcu wartość 126, a zmienna b 29. Jednakże w
pierwszym programie do zmiennej c trafi 126 i do d 29,
a w drugim do c trafi 125, a do
d 30. W pierwszym programie zmienna a w wyrażeniu Na opisane wyżej zjawisko należy bardzo uważać w programach C++, gdyż często prowadzi ono do trudno wykrywalnych błędów. Najbezpieczniej jest modyfikować zmienną poza wyrażeniami, lecz często robi się to wewnątrz wyrażeń w celu optymalizacji kodu. Wybór jest twój - zostałeś ostrzeżony.
Poza prostymi operatorami zwiększania lub zmniejszania o 1 zawartości zmiennej, język C++ posiada bogatą gamę operatorów modyfikacji:
zmienna += wyrażenie; - zwiększa zawartość zmiennej o wartość
wyrażenia:
Podane powyżej operatory modyfikacji (jak również instrukcje przypisania) mogą wystąpić w wyrażeniach, lecz odradzamy takie rozwiązania poza szczególnymi wyjątkami - prowadzą one do bardzo zawiłych kodów, które trudno później analizować:
a = 1; b = 2; c = 3; a = c + (b += 5 * (c *= 3 + b)); // odpowiedz bez uruchamiania, jaki będzie wynik w a? |
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe