MP001 - drzewa poszukiwań binarnych - BST
MP002 - drzewa AVL
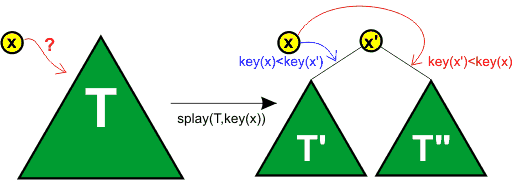
Podstawową zaletą drzew BST jest złożoność O(log n) operacji wyszukiwania elementu, ale tylko wtedy, gdy drzewo jest zrównoważone. Aby zagwarantować zrównoważenie, wymyślono struktury danych z różnymi ograniczeniami (ang. constrained data structures) - np. drzewa AVL. Jednakże operacje wstawiania i usuwania elementu w drzewie AVL są dosyć skomplikowane. Dodatkowo w węzłach musimy przechowywać informację o ich zrównoważeniu. Dużo prostszą strukturą danych są samoorganizujące się drzewa BST (ang self-adjusting binary search trees), zwane czasami drzewami Splay (ang. splay trees). Wynalazcami tej struktury danych są Daniel Dominic Sleator oraz Robert Endre Tarjan. Nazwa drzew pochodzi od operacji splay(T,x) (czytaj splej), która wyszukuje w drzewie T węzeł x i umieszcza go w korzeniu drzewa. Jeśli w drzewie T nie ma węzła x, to w korzeniu jest umieszczany taki węzeł x' drzewa T, iż pomiędzy x a x' nie istnieje w tym drzewie żaden inny węzeł.
Przemieszczanie węzła x w hierarchii drzewa T dokonywane jest przy pomocy rotacji, które poznaliśmy przy okazji drzew AVL. W przypadku drzew Splay operacje te upraszczają się, ponieważ nie musimy się martwić o współczynniki zrównoważenia bf, których tutaj po prostu nie ma. Istnieją trzy zasady wykonywania rotacji w drzewie Splay:
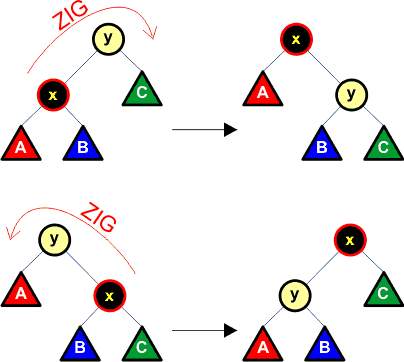
Zasada nr 1 (zig):
Jeśli rodzicem y węzła x jest korzeń drzewa T, to wykonujemy rotację pojedynczą, w której uczestniczą rodzić y oraz węzeł x. Rotacja taka kończy operację splay. Poniższy rysunek przedstawia sposób wykonania rotacji.
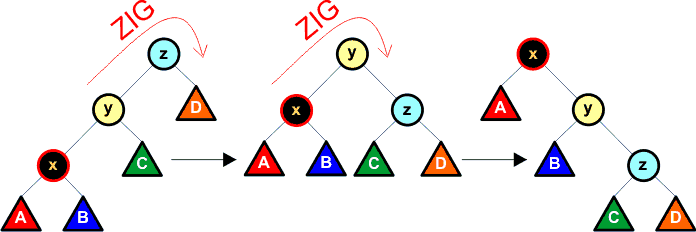
Zasada nr 2 (zig-zig):
Jeśli rodzic y węzła x nie jest korzeniem, a zarówno y jak i x są jednocześnie prawymi lub jednocześnie lewymi dziećmi, to wykonujemy dwie rotacje: najpierw rotacja z dziadkiem z i rodzicem y, a następnie rotacja z rodzicem y i węzłem x. Poniżej przedstawiamy sposób wykonania tych rotacji (przypadek lustrzany działa identycznie, zatem nie został uwzględniony na rysunku):
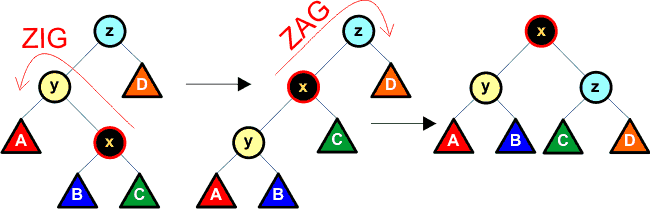
Zasada nr 3 (zig-zag):
Jeśli rodzic y nie jest korzeniem, a węzły x i y są naprzemiennie lewym i prawym dzieckiem, to najpierw wykonujemy rotację węzła y z węzłem x, a następnie rotację nowego rodzica x (jest to teraz węzeł z) z węzłem y. Poniżej przedstawiamy sposób wykonania tych rotacji:
Rotacja zig oraz para rotacji zig-zig lub zig-zag nosi nazwę kroku rozchylającego (ang. splaying step). Kroki rozchylające wykonujemy dotąd, aż węzeł x znajdzie się w korzeniu drzewa.
Operacja splay(T,x) składa się zatem z dwóch faz. W pierwszej wykonujemy operację wyszukania węzła x w strukturze drzewa T. Jeśli węzeł x nie zostanie znaleziony, to za x przyjmujemy ostatni niepusty węzeł, przez który przeszła operacja wyszukiwania. W drugiej fazie wykonujemy kroki rozchylające dotąd, aż węzeł x zostanie przesunięty do korzenia drzewa T.
Algorytm operacji splay
Wejście:
root - korzeń drzewa BST k - klucz węzła, który ma znaleźć się w korzeniu drzewa BST Wyjście:
Jeśli węzeł o kluczu x znajduje się w drzewie BST, to zostaje umieszczony w korzeniu. Jeśli węzeł o kluczu x nie występuje w drzewie BST, to w korzeniu zostaje umieszczony jego bezpośredni poprzednik lub następnik.
Dane pomocnicze:
x, y - węzły drzewa BST key(w) - klucz węzła w left(w) - lewy potomek węzła w right(w) - prawy potomek węzła w p(w) - rodzic węzła w Lista kroków
K01: x ← root ; rozpoczynamy fazę poszukiwania węzła o kluczu k K02: Jeśli x = NIL, zakończ ; drzewo jest puste K03: Jeśli key(x) = k, idź do K08 ; znaleźliśmy węzeł o kluczu k K04: y ← x ; zapamiętujemy bieżący węzeł K05: Jeśli k < key(x), to x ← left(x)
inaczej x ← right(x); przechodzimy do potomka węzła x K06: Jeśli x ≠ NIL, idź do kroku K03 ; kontynuujemy wyszukiwanie K07: x ← y ; w drzewie nie ma węzła o kluczu k, za x przyjmujemy poprzednik lub następnik K08: Jeśli p(x) = NIL, zakończ ; węzeł x znalazł się w korzeniu drzewa K09: Jeśli p(p(x)) = NIL, wykonaj rotację ZIG i zakończ ; rotacja ZIG umieszcza x w korzeniu drzewa K10: Jeśli left(p(p(x))) = p(x) i left(p(x)) = x
lub right(p(p(x))) = p(x) i right(p(x)) = x,
to wykonaj rotację ZIG-ZIG i idź do K08; badamy odpowiednie przypadki K11: Wykonaj rotację ZIG-ZAG K12: Idź do K08 Strukturę węzłów drzewa BST deklarujemy następująco:
struct BSTNode { BSTNode * p, * left, * right; int key; }Funkcja splay w C++ wygląda następująco:
Zdefiniujemy teraz podstawowe operacje na drzewie BST wykorzystujące opisaną powyżej operację splay(T,x).
search(T, k)
Wyszukanie elementu w drzewie BST polega na wykonaniu operacji splay(T, x), a następnie sprawdzeniu, czy korzeń drzewa zawiera poszukiwany element x. Jeśli tak, operacja search zwraca jego adres, a jeśli nie, zwraca adres pusty.
Wejście:
root - korzeń drzewa BST k - klucz węzła, którego poszukujemy w drzewie BST Wyjście:
Adres węzła o kluczu k lub NIL, gdy drzewo BST nie zawiera takiego węzła.
Dane pomocnicze:
key(w) - klucz węzła w left(w) - lewy potomek węzła w right(w) - prawy potomek węzła w p(w) - rodzic węzła w Lista kroków
K01: Jeśli root = NIL, zakończ z NIL ; drzewo jest puste K02: splay(root, k) ; rozdzielamy drzewo BST i umieszczamy w korzeniu węzeł o najbliższym kluczu k' K03: Jeśli key(root) = k, zakończ z root
inaczej zakończ z NIL; sprawdzamy, czy drzewo BST zawiera poszukiwany węzeł Funkcja search w C++ :
insert(T,x)
Operacja wstawiania nowego elementu do drzewa BST wygląda następująco:
Jeśli drzewo BST jest puste, to węzeł x umieszczamy w korzeniu i kończymy operację wstawiania.
Wykonujemy operację splay(T, key(x)), która w korzeniu drzewa BST umieści element x' o kluczu będącym bezpośrednim poprzednikiem lub następnikiem klucza wstawianego elementu x. Jeśli klucz x jest taki sam jak klucz x', to element x usuwamy z pamięci - drzewo posiada już węzeł o takim kluczu.
W przeciwnym razie węzeł x wstawiamy odpowiednio jako lewe dziecko x' (gdy x' jest następnikiem x, czyli key(x) < key(x')) lub jako prawe dziecko x' (gdy x' jest poprzednikiem x, czyli key(x') < key(x)).
Wejście:
root - korzeń drzewa BST x - węzeł do wstawienia w drzewie BST Wyjście:
true - węzeł x został wstawiony do drzewa BST
false - węzeł x nie został wstawiony, węzeł usunięto z pamięciDane pomocnicze:
key(w) - klucz węzła w left(w) - lewy potomek węzła w right(w) - prawy potomek węzła w p(w) - rodzic węzła w Lista kroków
K01: left(x) ← NIL ; inicjujemy pola wstawianego węzła K02: right(x) ← NIL K03: p(x) ← NIL K04: Jeśli root = NIL, root ← x i zakończ z true ; drzewo było puste, zatem x staje się korzeniem K05: splay(root, key(x)) ; rozdzielamy drzewo K06: Jeśli key(root) = key(x), usuń x i zakończ z false ; drzewo posiada już węzeł o takim kluczu K07: Jeśli key(x) > key(root), idź do K12 K08: left(x) ← left(root) ; wstawiamy x jako lewe dziecko korzenia K09: Jeśli left(x) ≠ NIL, p(left(x)) ← x K10: left(root) ← x ; rodzicem x staje się korzeń drzewa K11 Idź do K15 K12: right(x) ← right(root) ; wstawiamy x jako prawe dziecko korzenia K13: Jeśli right(x) ≠ NIL, p(right(x)) ← x K14: right(root) ← x K15: p(x) ← root K16 Zakończ z true Funkcja insert w C++ :
delete(T,k)
Operacja usunięcia węzła o kluczu k jest kilkuetapowa.
Jeśli korzeń drzewa jest pusty, kończymy zwracając NULL.
Wykonujemy operację splay(T, k).
Jeśli korzeń drzewa zawiera element o kluczu różnym od k, kończymy zwracając NULL. W drzewie BST nie ma elementu o poszukiwanym kluczu.
Odłączamy korzeń od jego dzieci zapamiętując go np. w zmiennej x. Jeśli dzieci są puste, to drzewo zawierało tylko usunięty węzeł. W korzeniu umieszczamy NULL i zwracamy zapamiętany adres w x.
W przeciwnym razie nad niepustym dzieckiem wykonujemy ponownie operację splay. Do korzenia dołączamy pozostałego potomka i zwracamy x.
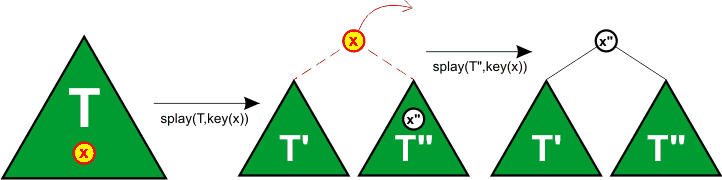
Wejście:
root - korzeń drzewa BST k - klucz węzła do usunięcia z drzewa BST Wyjście:
adres usuniętego węzła lub NIL, jeśli węzeł o kluczu k nie występował w drzewie BST
Dane pomocnicze:
x, y - węzeł drzewa key(w) - klucz węzła w left(w) - lewy potomek węzła w right(w) - prawy potomek węzła w p(w) - rodzic węzła w Lista kroków
K01: Jeśli root = NIL, zakończ z NIL ; drzewo BST jest puste K02: splay(root, k) K03: Jeśli key(root) ≠ k, zakończ z NIL ; w drzewie BST nie ma elementu o kluczu k K04: x ← root ; zapamiętujemy znaleziony element K05: root ← left(x); y ← right(x) ; zastępujemy x jego lewym dzieckiem K06: Jeśli root ≠ NIL, p(left(lroot)) ← NIL i idź do K09 K07: root ← right(x); y ← NIL ; zastępujemy x jego prawym dzieckiem K08: Jeśli root ≠ NIL, p(right(root)) ← NIL K09: splay(root, k) ; druga operacja splay K10: Jeśli root = NIL lub y = NIL, idź do K13 ; drzewo zawierało tylko jeden węzeł lub poddrzewo y było puste K11 p(y) ← root ; poddrzewo y dołączamy do korzenia K12: Jeśli key(y) < key(root), to left(root) ← y
inaczej right(root) ← yK13: Zakończ z x Funkcja delete w C++ :
Zbalansowane drzewa BST zostały zaprojektowane w celu zredukowania pesymistycznego czasu wykonywania operacji. Jednakże w typowych aplikacjach wykonuje się na nich nie pojedyncze operacje lecz całe serie, zatem istotne znaczenie ma czas wykonania takiej serii operacji (np. sprawdzenie poprawności ortograficznej tekstu wymaga wielu poszukiwań w drzewie BST słownika - przynajmniej tyle razy, ile wyrazów zawiera tekst). W takiej sytuacji zamiast optymalizować pojedyncze operacje na drzewie BST, lepszym celem będzie zoptymalizowanie czasu zamortyzowanego ciągu operacji, gdzie przez czas zamortyzowany (ang. amortized time) autorzy tej struktury rozumieją średni czas operacji w przypadku pesymistycznym dla ciągu operacji na drzewie BST.
Właśnie opisane powyżej samoorganizujące się drzewa BST pozwalają zoptymalizować czas zamortyzowany. Pomiędzy operacjami drzewo może znajdować się w dowolnym stanie, jednakże przy każdej operacji zostaje ono przebudowane na korzyść przyszłych operacji. Zauważ, iż dzięki operacji splay często wykorzystywane elementy wędrują w pobliże korzenia drzewa BST. Zatem kolejny dostęp do nich będzie już dużo szybszy.
Samoorganizujące się struktury danych posiadają kilka zalet w stosunku do struktur zbalansowanych o różnych ograniczeniach:
- W sensie zamortyzowanym nie są one dużo gorsze od struktur z ograniczeniami (np. drzew AVL), a ponieważ przebudowują się one według bieżących potrzeb, to w pewnych sytuacjach (np. częsty dostęp do ograniczonej grupy elementów) mogą być nawet bardziej efektywne.
- Wymagają mniej miejsca w pamięci, ponieważ węzły drzewa BST nie muszą zapamiętywać dodatkowych danych (np. w stylu współczynników zrównoważenia bf w drzewach AVL). Jeśli przy operacjach na drzewie wykorzystamy stos, to również zbędne może stać się pole rodzica p.
- Algorytmy dostępu do danych oraz przebudowywania drzewa są koncepcyjnie dużo prostsze i łatwiejsze do implementacji.
Samoorganizujące się drzewa BST posiadają jednakże dwie potencjalne wady:
- Wymagają więcej lokalnych regulacji, szczególnie podczas dostępu do danych. Struktury z ograniczeniami wymagają regulacji tylko przy przebudowie drzewa, a nie przy dostępie do danych.
- Pojedyncze operacje w ciągu mogą być kosztowne, co może się okazać wadą w rzeczywistych aplikacjach.
Program testujący strukturę samoorganizujących się drzew BST.
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe