w I-LO w Tarnowie
Materiały dla uczniów liceum
Wyjście Spis treści Wstecz Dalej

Tłumaczył: mgr Jerzy Wałaszek
©2026 mgr Jerzy Wałaszek
![]()
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Tłumaczył: mgr Jerzy Wałaszek |
©2026 mgr Jerzy Wałaszek
|
| Rok konkursu ACM |
| Tematy zadań konkursu |
Pułapka na myszy jest rodzajem gry w karty, w którą gra się następująco. Talia kart oznaczonych liczbami 1, 2, 3, ..., n jest rozkładana w dowolnej kolejności, karty są odkryte i ułożone w koło. Gracz rozpoczyna od pierwszej karty i liczy w koło zgodnie z kierunkiem rozkładania kart. Jeśli k-ta karta posiada numer k - takie zdarzenie nazywamy trafieniem (ang. hit) - to zostaje ona usunięta z koła i gracz znów rozpoczyna liczenie od 1.
Na przykład, jeśli talia składa się jedynie z 4 wykorzystywanych kart, a karty te zostaną rozłożone w kolejności 3214, to jako trafienie gracz otrzyma drugą kartę 2, następnie otrzymałby jako trafienie kartę 1, lecz gdyby poszedł dalej w nieskończoność, to nie uzyskałby kolejnego trafienia. Z drugiej strony, jeśli karty w talii byłyby w początkowym ułożeniu 1423, to gracz zebrałby wszystkie karty w kolejności 1, 2, 3, 4.
Załóż, że będziesz grał z talią 9 kart. Masz napisać program, który określi trafienia uzyskane przy określonym ułożeniu kart.
Na wejściu program otrzyma nieokreśloną liczbę wierszy, z których każdy będzie definiował uporządkowanie kart. Numery kolejnych kart w talii będą rozdzielone pojedynczą spacją. Pierwszy numer będzie określał numer na pierwszej karcie, drugi na drugiej, itd. Razem będzie 9 takich numerów. Wiersz z numerem 0 kończy dane wejściowe.
Dla każdego wiersza z danymi program powinien wypisać te dane, a następnie listę wszystkich uzyskanych trafień. Trafienia można wypisywać w dowolnym dogodnym formacie.
1 3 5 7 9 2 4 6 8 9 7 3 1 2 4 5 6 8 0 |
INPUT 1 3 5 7 9 2 4 6 8
HIT 1
HIT 8
INPUT 9 7 3 1 2 4 5 6 8
HIT 3
HIT 1
HIT 7
|
Graf (ang. graph) G jest zbiorem wierzchołków (ang. vertices) V oraz zbiorem krawędzi (ang. edges) E. Krawędź jest połączeniem pomiędzy dwoma (niekoniecznie różnymi) wierzchołkami. Spójny graf (ang. connected graph) jest grafem, w którym można po krawędziach przejść z każdego wierzchołka do każdego innego. Drzewo rozpinające (ang. spanning tree) T dla spójnego grafu G jest grafem, który posiada taki sam zbiór wierzchołków V i którego zbiór krawędzi E' jest podzbiorem (niekoniecznie właściwym) zbioru krawędzi E. Co więcej, T musi być grafem spójnym bez cykli, tj. pomiędzy dwoma dowolnymi wierzchołkami istnieje tylko jedna ścieżka przejścia po krawędziach. W ten sposób E' jest minimalnym podzbiorem E, takim iż T jest grafem spójnym. Drzewo rozpinające niekoniecznie jest unikalne.
Jako przykład, poniższy graf zawiera cztery węzły (1-4) i pięć krawędzi (A-E):
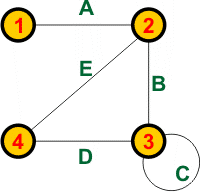
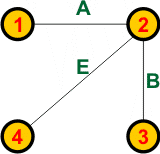
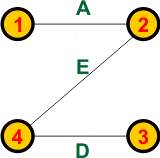
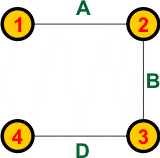
Dla tego grafu są możliwe trzy drzewa rozpinające:
 |
 |
 |
Masz napisać program, który wygeneruje drzewa rozpinające z grafów. Grafy będą się składały z co najwyżej 15 wierzchołków. Twój program powinien przetworzyć dowolną liczbę grafów wejściowych i dla każdego z nich wyświetlić krawędzie jednego z drzew rozpinających.
Dane wejściowe dla twojego programu będą się pojawiały w zestawach. Pierwszy wiersz zestawu zawiera liczbę n - ilość wierzchołków grafu G. Następnie pojawi się n wierszy, z których każdy reprezentuje jeden wierzchołek grafu oraz jego połączenia. Pierwszy z tych wierszy odnosi się do wierzchołka 1, drugi do wierzchołka 2, itd. Wiersz reprezentujący wierzchołek będzie zawierał n liczb określających krawędzie (połączenia) pomiędzy tym wierzchołkiem a pozostałymi wierzchołkami grafu. Liczby w wierszu odnoszą się do kolejnych wierzchołków grafu. Wartość 0 oznacza brak krawędzi, a 1 istnienie krawędzi pomiędzy wierzchołkiem określonym przez wiersz a wierzchołkiem określonym przez liczbę w wierszu. Na przykład, dla wiersza reprezentującego wierzchołek k pierwsza liczba 0 lub 1 określa, czy istnieje krawędź od wierzchołka k do wierzchołka 1, druga liczba określa istnienie krawędzi od wierzchołka k do wierzchołka 2, i-ta liczba w tym wierszu określa istnienie krawędzi od wierzchołka k do wierzchołka i. Dane wejściowe kończą się, jeśli pierwszy wiersz zawiera wartość 0.
Dla każdego zestawu danych reprezentującego graf należy wyświetlić listę par wierzchołków (po jednej parze na wiersz wydruku) określających krawędzie drzewa rozpinającego dla tego grafu. Na tej liście każda krawędź powinna być umieszczona dokładnie jeden raz.
4 0 1 0 1 1 0 1 1 0 1 1 1 0 1 1 0 0 |
THE CONNECTIONS ARE 1 - 2 2 - 3 2 - 4 |
Ten problem jest ćwiczeniem przekształcania jednowymiarowej listy liczb w dwuwymiarową tablicę ze zmienną liczbą kolumn. Liczby muszą być ułożone w tablicę, którą czyta się kolumnami od strony lewej do prawej. Długości kolumn powinny być wyrównane, tak aby wszystkie wiersze z wyjątkiem ostatniego były pełne. Puste miejsca w ostatnim wierszu powinny być umieszczone po jego prawej stronie.
Na wejściu program otrzyma liczbę n określającą ilość liczb na liście, następnie n liczb listy i na końcu liczbę c określającą liczbę kolumn w tworzonej tablicy.
17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 5 |
1 5 9 12 15 2 6 10 13 16 3 7 11 14 17 4 8 |
Pierwsza liczba n określa ilość liczb w liście do zamiany w tablicę. Następnie występuje n liczb listy. Na końcu pojawia się liczba c, która określa ilość kolumn tablicy do utworzenia.
17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 5 17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1 17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 2 0 |
C ROW SUMS 5 42 47 52 12 1 153 2 11 13 15 17 19 21 23 25 9 |
Rozważmy następujące układy figur geometrycznych:
a)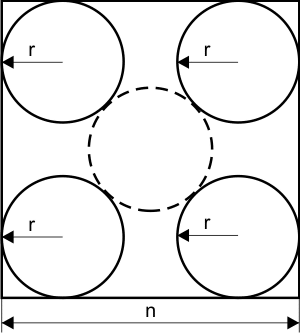 kształt = CIR |
b)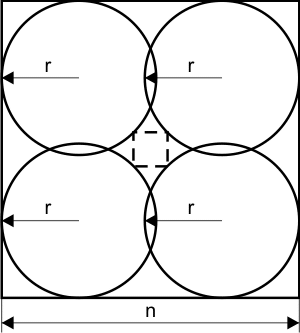 kształt = SQR |
Napisz program, który będzie przetwarzał wiersze zawierające następujące dane:
| n | - długość boku kwadratu |
| r | - promień 4 okręgów, które są umieszczone w rogach kwadratu i stykają się z dwoma jego bokami (zobacz na rysunki powyżej) |
| kształt | - CIR oznacza okrąg (ang. circle), SQR oznacza kwadrat (ang. square). |
Na podstawie kształtu twój program powinien wyliczyć powierzchnię największego wpisanego kwadratu (o bokach równoległych do boków kwadratu opisującego) lub koła, które leżą w całości wewnątrz dużego kwadratu i stykają się w co najwyżej 4 punktach z czterema okręgami.
Dane wejściowe będą zawarte w wierszach. Pierwsza liczba całkowita n określa długość boku dużego kwadratu (0 < n ≤ 100). Druga liczba rzeczywista r z dwoma miejscami po przecinku określa promień każdego z czterech wewnętrznych okręgów. Na końcu wystąpi 3 literowy tekst CIR lub SQR, który będzie określał rodzaj figury wpisanej.
Koniec danych wejściowych będzie oznaczony wartością n = 0.
Dla każdego wiersza z danymi program powinien wypisać odpowiednio oznaczone wartości dla n, r, kształtu oraz powierzchnię figury wpisanej z dokładnością do 0.1.
Jednym z ważnych składników wielu współczesnych systemów informacyjnych jest słownik danych (ang. data dictionary), który definiuje własności elementów danych w rekordach danych. Problem ten wymaga użycia prostego słownika danych (listy elementów danych oraz ich postaci) w celu sprawdzenia poprawności zawartości transakcji wejściowych i do utworzenia raportu błędów.
Plik wejściowy o nazwie in.txt zawiera dwa zbiory danych zbudowane z wierszy. Pierwszy zbiór zawiera nie więcej niż 15 wierszy i kończy się wierszem, który w pierwszych dwóch znakach posiada 00. Wiersze te będą ułożone w porządku rosnącym względem pozycji startowej (patrz niżej). Każdy wiersz w tym zbiorze będzie się składał z 80 znaków i będzie opisywał jeden element danych w sposób następujący (pierwszy znak w wierszu jest w kolumnie 1):
| Kolumny | Zawartość |
| 1-2 | Pozycja startowa p w wierszu operacji (0 < p ≤ 80), liczba całkowita |
| 4-5 | Długość pola f (1 ≤ f ≤ 80), liczba całkowita |
| 7 | Rodzaj pola: = 1 liczbowe (zawiera cyfry, znaki +/-, kropki dziesiętne lub spacje) = 2 alfanumeryczne (zawiera dowolne znaki) = 3 data w postaci MMDDYY (to pole musi zawierać dokładnie 6 cyfr, lecz może posiadać spacje w dowolnym miejscu. Również: 1 ≤ MM ≤ 12 i 1 ≤ DD ≤ 31). |
| 9 | Obecność: = 1 pole wymagane (nie może być puste) = 2 pole opcjonalne |
| 11-30 | Nazwa elementu danych (używana tylko do wydruku) |
| 31-80 | Nieużywane |
Możesz założyć poprawność i spójność wszystkich danych słownikowych. Twój program nie jest odpowiedzialny za sprawdzanie znaków w polach nie określonych w słowniku danych.
Drugi zbiór danych zawiera transakcje do sprawdzenia za pomocą reguł słownika dostarczonych w pierwszym zbiorze. Format wierszy zależy od definicji w słowniku. Jednakże wiadomo, że każdy wiersz będzie posiadał długość 80 znaków. Koniec pliku zasygnalizuje koniec drugiego zbioru danych.
Raport na temat nieprawidłowych wierszy z danymi powinien być utworzony w następującym formacie:
ERRONEOUS TRANSACTIONS (BŁĘDNE TRANSAKCJE)
XXX................XXX
message 1
message 2
...
...
...
XXX................XXX
message 1
message 2
...
...
...
|
Gdzie XXX...XXX oznacza błędną transakcję ze zbioru wejściowego, a message i składa się z nazwy składnika danych ze słownika, za którą następuje krótkie wyjaśnienie natury błędu w języku angielskim. Typowe wiadomości błędów są następujące:
SSNO IS MISSING (BRAKUJE) SALARY IS NOT NUMERIC (NIE JEST LICZBĄ) BIRTHDAY HAS MONTH > 12 (MA MONTH > 12) NETPAY CONTAINS AN EMBEDDED BLANK (ZAWIERA OSADZONĄ SPACJĘ) |
Uwaga: dla pól liczbowych liczby muszą być poprawnie zapisane, lecz nie muszą być wyrównane do prawej krawędzi pola. Dla dat przyjmij, że wszystkie miesiące mają po 31 dni.
Firma HYPOXIA Properties, Ltd. zajmuje się sprzedażą domków z pni. Cena ich usług zależy od powierzchni w stopach zamawianego modelu oraz od tego, czy pracę wykonuje firma sama HYPOXIA, czy właściciel w swoim zakresie. Chociaż ich konstrukcje domków z pni oraz zestawy do samodzielnego montażu są bardzo dobre, HYPOXIA ma pewne trudności w wyliczaniu powierzchni, ponieważ podłogi posiadają różne kształty i rozmiary.
Założyciel firmy, John Hardwood, pragnie posiadać program komputerowy, który by wspomagał te obliczenia. Kosztorysant firmy chciałby móc wprowadzać dane opisujące wymiary domku, średnice pni i ich długości, liczbę pożądanych pięter, itp., a otrzymywać w wyniku powierzchnię domku w stopach kwadratowych (zaokrągloną do najbliższej stopy kwadratowej) oraz koszt domku (w dolarach).
Plany podłóg są kodowane przez podanie, począwszy od dowolnego narożnika, listy kolejnych par (kierunek, długość), które definiują parametry domku, gdzie kierunkiem jest zawsze N, S, E lub W, a wymiary są podawane w całych stopach. Na przykład dla domku o następujących wymiarach:
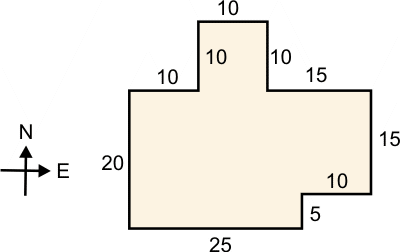
kodowanie mogłoby być następujące: (N,20), (E,10), (N,10), (E,10), (S,10), (E,15), (S,15), (W,10), (S,5), (W,25).
Koszty domków z pni są obliczane zgodnie z następującymi regułami:
Na wejściu programu może pojawić się dowolna liczba opisów domków z pni. Każdy opis takiego domku wymaga następujących danych:
długości i średnicy pni:
T6, T8 - pnie o długości 8
stóp i średnicach 6 lub 8 cali
F6, F8 - pnie o
długości 10 stóp i średnicach 6 lub 8 cali
liczby pięter: 1 lub 2 (pamiętaj, że w systemie anglosaskim dom dwupiętrowy, to nasz jednopiętrowy, ponieważ parter jest tam liczony jako pierwsze piętro!)
kto będzie budował: T - HYPOXIA, F - klient we własnym zakresie
liczby narożników n (n ≤ 18)
n par: kierunek N, S, E lub W i odległość
Ciąg opisów kończy się, jeśli pierwszą daną jest 00.
Dla każdego opisu domku odczytanego z wejścia program powinien wypisać powierzchnię opisanego planu podłogi oraz wyliczony koszt usługi (zaokrąglony do najbliższego dolara).
Binarne drzewo gry (ang. binary game tree) jest drzewem binarnym, w którym każdy węzeł posiada albo 0, albo 2 potomków. Każdy liść drzewa (węzeł bez potomków) ma skojarzone ze sobą dane. Dwóch potomków dowolnego węzła wewnętrznego reprezentuje wynik wykonania lub niewykonania określonego ruchu, a wartość w liściu drzewa jest miarą przydatności w zwycięstwie ruchów wzdłuż ścieżki prowadzącej od korzenia do tego liścia. Drzewo przedstawia ruchy dla dwóch graczy; korzeń oraz wszystkie węzły o parzystej odległości od korzenia (odległość wyrażana jest na drzewie liczbą krawędzi, po których należy przejść, aby dojść od korzenia do wybranego węzła) są ruchami do wyboru przez gracza A, natomiast węzły o odległości nieparzystej od korzenia są ruchami dla gracza B. Poniżej przedstawiono przykład:
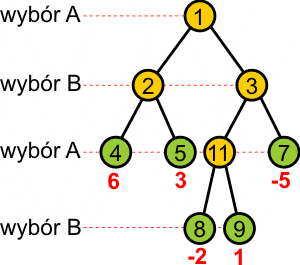
Gracz A stara się zmaksymalizować wartość wybranych ruchów, natomiast gracz B stara się zminimalizować korzyści gracza A przez wybieranie ścieżki o niższej wartości. W dowolnym węźle reprezentującym wybór dla A gracz A wybierze wartość wyższą, a w dowolnym węźle reprezentującym wybór dla B gracz B wybierze wartość niższą. W ten sposób wartością drzewa wewnętrznego jest albo wartość maksymalna, albo minimalna jego poddrzew w zależności o tego, czy pierwotne poddrzewo jest odpowiednio dla gracza A lub B.
Dla przykładowego drzewa gry mamy:
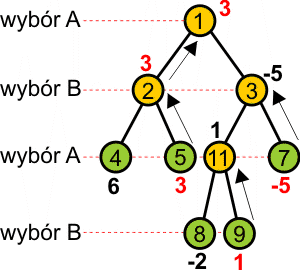
Danymi wejściowymi dla twojego programu będą opisy kilku binarnych drzew gry. Masz określić wartość (dla A) każdego drzewa Na wyjściu ma się pojawić jedynie wartość drzewa, nie musisz drukować drzewa w całości. Drzewo będzie posiadało co najwyżej 15 węzłów.
Dane dla tego problemu są ułożone w zestawach w pliku in.txt. Każdy zestaw może zawierać od jednego do 15 wierszy z danymi; pierwszy wiersz opisuje korzeń drzewa (węzeł numer 1), a każdy kolejny wiersz opisuje następny węzeł o wyższym numerze. Każdy wiersz będzie zawierał trzy liczby:
| n - numer węzła dla lewego potomka
(1 ≤ n 20) m - numer węzła dla prawego potomka (1 ≤ m 20) Powyższe dwie liczby przyjmują wartość 0, jeśli węzeł jest liściem v - wartość liścia (-99 ≤ v ≤ 99) lub zero, jeśli węzeł nie jest liściem. |
Każdy zestaw kończy się wierszem, w którym lewy potomek ma numer -1, a pozostałe dwie wartości przyjmują 0.
Dane wejściowe kończą się wraz z plikiem.
Dla każdego zestawu danych należy podać wartość drzewa.
2 3 0 4 5 0 6 7 0 0 0 6 0 0 3 0 0 0 (Zauważ, że węzeł nr 6 nie jest używany) 0 0 -5 0 0 -2 0 0 1 0 0 0 (Węzeł nr 10 też nie jest używany) 8 9 0 -1 0 0 (Koniec zestawu) |
3 |
Wielomian P(x) = a0x0 + a1x1 + a2x2 + ... + anxn może być przedstawiony jako zbiór uporządkowanych par, w których pierwszy element pary jest współczynnikiem, a drugi element jest wykładnikiem zmiennej x.
Na przykład wielomian P(x) = 7 + 3x2 + 4x9 + 17x21 reprezentuje zbór par (7,0), (3,2), (4,9), (17,21).
Masz napisać program, który wczyta nieokreśloną liczbę par definicji wielomianów - każda para definiuje dwa wielomiany. Następnie dla każdej pary wejściowych wielomianów program powinien wyprowadzić na wyjście uporządkowane wg wykładników pary współczynnik, wykładnik, które odnoszą się do iloczynu wczytanych wielomianów (wielomiany wejściowe są podobnie zapisane).
Dane występują w parach. W każdej parze są zdefiniowane dwa wielomiany. Definicja wielomianu rozpoczyna się od liczby określającej ilość par współczynnik, wykładnik - pary te będą uporządkowane wg rosnących wykładników. Wszystkie współczynniki i wykładniki są nieujemnymi liczbami całkowitymi o wartości mniejszej od 100. Każdy wielomian wejściowy nie będzie zawierał więcej niż 9 składników.
Dane wejściowe kończą, jeśli liczba par jest równa zero.
Dla każdej wczytanej z wejścia pary wielomianów należy obliczyć wielomian będący ich iloczynem i wyprowadzić na wyjście pary współczynnik, wykładnik tego wielomianu. Pary te powinny być odpowiednio opisane i wyprowadzone w porządku rosnących wykładników.
3 3 0 16 3 23 5
(wielomian: P(x) = 3 + 16x3 + 23x5) |
COEFF EXP
6 2
62 5
46 7
160 8
230 10
|
(wielomian wynikowy: P(x) = 6x2 + 62x5 + 46x7 + 160x8 + 230x10)
|
|
Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2026 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.