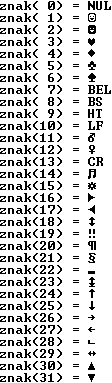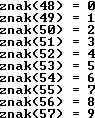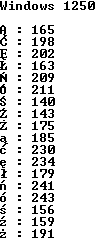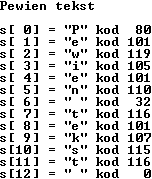Autor artykułu: mgr Jerzy Wałaszek
©2017 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2017 mgr
Jerzy Wałaszek
|
Sposoby reprezentacji znaków i łańcuchów znakowychASCIIWe współczesnych językach programowania znaki są podstawowym typem danych. W pamięci komputera znak jest przechowywany w postaci liczby, którą nazywamy kodem znaku (ang. character code). Każdy znak posiada swój własny kod. Aby różne urządzenia systemu komputerowego mogły w ten sam sposób interpretować kody znaków, opracowano kilka standardów kodowania liter. Bardzo rozpowszechniony jest standard ASCII:
ASCII – American Standard Code for Information
Interchange – Amerykański Standardowy Kod do Wymiany Informacji.
Znaki są zapamiętywane w postaci 8 bitowych kodów (pierwotnie było to 7 bitów, lecz później standard ASCII został poszerzony na 8 bitów, w których znalazły się różne znaki narodowe). Taki sposób reprezentacji znaków jest dzisiaj bardzo wygodny, ponieważ podstawowa komórka pamięci komputera IBM przechowuje właśnie 8 bitów. Dzięki temu znaki dobrze mieszczą się w pamięci. Typ ten jest w C++ reprezentowany przez char lub unsigned char. W pierwszym typie kody znaków spoza standardowego zestawu ASCII są ujemne (traktuje się je jako liczbę U2) i przyjmują wartości od -128 do -1. W drugim typie kody znaków spoza standardowego zestawu ASCII mają wartości od 128 do 255.
Przyjrzyjmy się dokładniej kodom ASCII w postaci binarnej: Podstawowy standard ASCII definiuje kody w zakresie od 0 do 127. Bitowo jest to 7 najmłodszych bitów kodu. Pozostałe kody od 128 do 255 to rozszerzony zestaw ASCII:
Kody ASCII 0-31W zakresie kodów od 0 do 31 są znaki sterujące
(ang. control characters). Spełniają one różne
funkcje.
Np. kod 13 oznacza przejście do następnej linii, kod 7 to dźwięk dzwonka.
Większość z tych kodów (za wyjątkiem 0,7,8,9,10 i 13) produkuje w konsoli znakowej użyteczne znaki:
Kody 32-127W tym zakresie mamy podstawowe znaki pisarskie. Kod
32 oznacza spację.
Cyfry mają kody od 48 (0) do 57 (9).
W powyższym kodzie xxxx jest wartością binarną cyfry: 0000 = 0, 0001 = 1, 0010 = 2, ..., 1001 = 9.
Litery duże mają kody od 65 (A) do 89 (Z). Litery małe mają kody od 97 (a) do 122 (z).
W powyższych kodach xxxxx oznacza binarny numer litery od 00001 = 1 do 11010 = 26. Zwróć uwagę, że litery małe różnią się od dużych bitem b5. Oznacza to, że np. kod litery 'a' jest większy o 32 od kodu litery 'A'. Aby z kodu dużej litery otrzymać kod małej, wystarczy ustawić na 1 bit b5. Podobnie, aby z kodu małej litery otrzymać kod duże, wystarczy wyzerować bit b5.
Kody 128-255Są to rozszerzone kody ASCII. Ich interpretacja zależy od
tzw. strony kodowej, która jest wybrana w systemie. Kody znaków
rozszerzonych mogą być traktowane jako liczby ujemne.
W polskich systemach Windows w konsoli znakowej jest zwykle wykorzystywana strona kodowa CP852. Niestety, sam system Windows wykorzystuje standard Windows 1250, w którym polskie literki posiadają inne kody niż ich odpowiedniki w konsoli znakowej.
Konsekwencją tego faktu jest to, że program napisany w edytorze pracującym w Windows nie będzie poprawnie wyświetlał polskich znaków (tablica znakowa s zawiera kody polskich znaków Windows 1250):
Należy dokonać odpowiedniej konwersji (tablica znakowa t zawiera poprawne kody polskich znaków dla konsoli CP852):
Problemy te znikają, jeśli zrezygnujemy z polskich znaków w trybie konsoli lub będziemy tworzyć tylko aplikacje dla GUI w Windows. Należy wspomnieć, że w systemie Linux nie występuje ten problem, ponieważ kodowanie polskich znaków jest jednolite w całym systemie (ale z kolei jest to jeszcze inna strona kodowa – ISO-8859-2, która jest standardem ogólnoświatowym). Jak widać, polscy programiści lekko nie mają.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Przechowywanie tekstu
Tekst jest przechowywany w pamięci w postaci ciągu znaków. Na końcu tego
ciągu umieszczany jest znak o kodzie 0 (NUL).
Ten sposób zapisu tekstów nosi nazwę cstring
(ang. łańcuch znakowy typu C). Jest on powszechnie stosowany w
języku C++.
Teksty możemy przechowywać w tablicach znakowych:
Zwróć uwagę, że przy inicjalizacji tablicy:
char s[] = "...";
automatycznie zostaje wstawiony na koniec znak NUL. Tablica przyjmuje taki rozmiar, aby pomieścić wszystkie znaki tekstu wraz ze znakiem NUL.
Tekst można odczytać z konsoli do tablicy znakowej za pomocą strumienia cin. Jednakże należy się przy tym zatroszczyć, aby tablica miała odpowiednio duży rozmiar. Prosty odczyt ze strumienia cin zwraca jeden wyraz, ponieważ spacja jest traktowana jako separator.
Pracując w konsoli, możesz bez problemu wprowadzać polskie znaki. Musisz jedynie pamiętać, iż posiadają one kody CP852, a nie Windows 1250. Będzie to miało znaczenie przy porównywaniu znaków. Jeśli chcesz odczytać cały wiersz znaków, to musisz skorzystać z funkcji składowej strumienia cin o nazwie getline(). Funkcja ta posiada następujące parametry:
cin.getline(s,n);lub
s – tablica znakowa lub wskaźnik do danych char. Tutaj
zostanie umieszczony wiersz znaków.
Problem może pojawić się, jeśli czytasz naprzemiennie z cin oraz z cin.getline(). Sprawdź poniższy program. Odczytuje on najpierw liczbę z cin. Następnie czyta wiersz znaków za pomocą funkcji getline(). I na koniec ponownie czyta liczbę z cin.
Co tutaj się stało? Gdy wprowadziłeś pierwszą liczbę (u mnie 20), to komputer nie zaczekał na wprowadzenie wiersza, lecz od razu przeszedł do odczytu drugiej liczby. Dlaczego? Otóż strumień cin po odczycie pierwszej liczby pozostawił w sobie znak końca wiersza '\n'. Gdy teraz wywołaliśmy funkcję getline(), to natrafiła ona od razu na ten znak i zakończyła odczyt. W efekcie użytkownik nie miał szansy wprowadzić swojego tekstu. Funkcja getline() usunęła ze strumienia znak '\n', a program przeszedł do odczytu drugiej liczby. Jak rozwiązać ten problem? Musimy użyć funkcji ignore(), która pobiera ze strumienia cin zadaną liczbę znaków, aż do napotkania znaku ograniczającego:
cin.ignore(n,d);n – liczba znaków do
pominięcia.
Ze strumienia cin możemy również pobierać pojedyncze znaki oraz ich ciągi za pomocą funkcji get():
kod = cin.get(); // zwraca kod ASCII znaku cin.get(c); // umieszcza znak w zmiennej znakowej c cin.get(s,n); // odczytuje n-1 znaków do tablicy znakowej s, dodając na końcu NUL cin.get(s,n,d); // jak wyżej, lecz do napotkania znaku ograniczającego d
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
PodsumowanieZmienna znakowa:
char c; // kody rozszerzone ASCII -1...-128 unsigned char c; // kody rozszerzone ASCII 128...256
Tekst jest utworzony z ciągu znaków zakończonych kodem NUL. Tablica znakowa:
char s[liczba_znaków + 1]; unsigned char s[liczba_znaków + 1;
Inicjalizacja tablicy znakowej tekstem (znak NUL jest automatycznie dołączany na koniec tekstu, a tablica przyjmuje odpowiedni rozmiar):
char s[] = "dowolny tekst"; unsigned char s[] = "dowolny tekst";
Zapis do strumienia cout:
cout << (int) c; // kod znaku cout << (int)(unsigned char) c; // kod znaku rozszerzonego ASCII cout << (char) kod; // znak o danym kodzie cout << s; // zapis tablicy znakowej
Odczyt ze strumienia cin:
cin >> s; // odczyt wyrazu, spacja i /n są znakami rozdzielającymi kod = cin.get(); // kod znaku ze strumienia cin.get(c); // znak ze strumienia cin.get(s,n); // odczyt n znaków ze strumienia do tablicy s cin.get(s,n,d); // odczyt do n znaków do tablicy s, aż do napotkania znaku d cin.getline(s,n); // odczyt do n znaków do tablicy s, aż do napotkania \n cin.getline(s,n,d); // odczyt do n znaków do tablicy s, aż do napotkania znaku d cin.ignore(n,d); // usuwa ze strumienie do n znaków aż do napotkania znaku d, który również usuwa |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Proste zadania
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Szyfr CezaraSzyfrowanie tekstów (ang. text encryption) ma na celu ukrycie ważnych informacji przed dostępem do nich osób niepowołanych. Historia kodów szyfrujących sięga czasów starożytnych. Już tysiące lat temu egipscy kapłani stosowali specjalny system hieroglifów do szyfrowania różnych tajnych wiadomości. Szyfr Cezara (ang. Ceasar's Code lub Ceasar's Cipher) jest bardzo prostym szyfrem podstawieniowym (ang. substitution cipher). Szyfry podstawieniowe polegają na zastępowaniu znaków tekstu jawnego (ang. plaintext) innymi znakami przez co zawarta w tekście informacja staje się nieczytelna dla osób niewtajemniczonych. Współcześnie szyfrowanie stanowi jedną z najważniejszych dziedzin informatyki – to dzięki niej stał się możliwy handel w Internecie, funkcjonują banki ze zdalnym dostępem do kont, powstał podpis elektroniczny oraz bezpieczne łącza transmisji danych. Przykładów zastosowania jest bez liku i dokładne omówienie tej dziedziny wiedzy leży daleko poza możliwościami tego artykułu. Szyfr Cezara został nazwany na cześć rzymskiego imperatora Juliusza Cezara, który stosował ten sposób szyfrowania do przekazywania informacji o znaczeniu wojskowym. Szyfr polega na zastępowaniu liter alfabetu A...Z literami leżącymi o trzy pozycje dalej w alfabecie:
Ostatnie trzy znaki X, Y i Z nie posiadają następników w alfabecie przesuniętych o trzy pozycje. Dlatego umawiamy się, iż alfabet "zawija się" i za literką Z następuje znów litera A. Teraz bez problemu znajdziemy następniki X → A, Y → B i Z → C. Przykład: Zaszyfrować zdanie: NIEPRZYJACIEL JEST BARDZO BLISKO. Poszczególne literki tekstu jawnego zastępujemy literkami szyfru Cezara zgodnie z powyższą tabelką kodu. Spacje oraz inne znaki nie będące literami pozostawiamy bez zmian:
NIEPRZYJACIEL JEST BARDZO BLISKO
Deszyfrowanie tekstu zaszyfrowanego kodem Cezara polega na wykonywaniu operacji odwrotnych. Każdą literę kodu zamieniamy na literę leżącą o trzy pozycje wcześniej w alfabecie.
Podobnie jak poprzednio trzy pierwsze znaki szyfru Cezara nie posiadają bezpośrednich odpowiedników liter leżących o trzy pozycje wcześniej, ponieważ alfabet rozpoczyna się dopiera od pozycji literki D. Rozwiązaniem jest ponowne "zawinięcie" alfabetu, tak aby przed literą A znalazły się trzy ostatnie literki X, Y i Z.
Do wyznaczania kodu literek przy szyfrowaniu i deszyfrowaniu posłużymy się operacjami modulo. Operacja modulo jest resztą z dzielenia danej liczby przez moduł. Wynik jest zawsze mniejszy od modułu. U nas moduł będzie równy 26, ponieważ tyle mamy liter alfabetu.
Jeśli c jest kodem ASCII dużej litery alfabetu (rozważamy tylko teksty zbudowane z dużych liter), to szyfrowanie kodem Cezara polega na wykonaniu następującej operacji arytmetycznej:
c = 65 + (c - 62) mod 26
Deszyfrowanie polega na zamianie kodu wg wzoru:
c = 65 + (c - 42) mod 26
Algorytm szyfrowania tekstu kodem CezaraWejścieŁańcuch tekstowy s Wyjście:Łańcuch tekstowy s zaszyfrowany kodem Cezara Elementy pomocnicze:
Lista kroków:
Algorytm deszyfrowania tekstu zaszyfrowanego kodem CezaraWejścieŁańcuch tekstowy s zaszyfrowany kodem Cezara Wyjście:Tekst jawny Elementy pomocnicze:
Lista kroków:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Szyfrowanie z pseudolosowym odstępemSzyfr Cezara posiada kilka wad, które uniemożliwiają praktyczne zastosowanie. Po pierwsze wystarczy odkryć wartość przesunięcia kodów (oryginalnie wynosi ono 3, lecz można je zmieniać w zakresie od 1 do 25), aby rozszyfrować całą wiadomość. W tym celu należy przeprowadzić 25 prób, co dla współczesnych komputerów nie stanowi żadnego problemu.
Po drugie, z uwagi na stałe przesunięcie kodów, te same znaki są zawsze szyfrowane tak samo. Jeśli na przykład zaszyfrujemy AAAAAAAAAA, to otrzymamy ciąg DDDDDDDDDD. Aby znacząco utrudnić rozszyfrowanie wiadomości zaprojektujemy szyfr, w którym przesunięcie kodów będzie się zmieniało w zakresie od 0 do 25 w trakcie szyfrowania znaków. Do tego celu potrzebna nam jest możliwość generacji tych samych ciągów liczbowych przy szyfrowaniu oraz rozszyfrowywaniu. Wykorzystamy generator pseudolosowy LCG, który startując od określonego ziarna tworzy zawsze te same ciągi liczb pseudolosowych. Kluczem szyfrującym będą parametry generatora oraz wartość ziarna pseudolosowego. Parametry generatora: moduł m, mnożnik a oraz przyrost c zostaną na stałe zdefiniowane w programie (możesz je zmienić, wtedy zmianie ulegnie sposób szyfrowania). Użytkownik będzie jedynie podawał wartość ziarna pseudolosowego Xo. Sposób projektowania generatora LCG opisaliśmy w rozdziale o liczbach pseudolosowych.
Projekt generatora LCGIm większy zakres generowanych liczb pseudolosowych, tym dłuższy okres powtarzania tworzonego ciągu. W efekcie trudniejsze jest złamanie szyfru. Kryptologia potrafi bez większych problemów łamać szyfry oparte na prostych generatorach pseudolosowych z uwagi na ich właściwości, dlatego nie są one stosowane w praktycznych systemach szyfrowania – użyty generator musi być kryptologicznie bezpieczny. My się tym nie będziemy przejmowali, ponieważ nasz projekt jest czysto dydaktyczny.
Wybieramy zakres od 0 do Xmax = 3956279999. Moduł m jest równy Xmax + 1 = 3956280000 Czynniki pierwsze modułu m = 3956280000 = 2 × 2 × 2 × 2 × 2 × 2 × 3 × 5 × 5 × 5 × 5 × 32969 Przyrost c = 7 × 11 × 17 = 1309 Mnożnik a - 1 = 2 × 2 × 3 × 5 × 32969 = 1978140, stąd a = 1978141. Podsumowując otrzymujemy następujący generator LCG: LCG(3956280000,1978141,1309,Xo) Ziarno Xo jest w zakresie od 0 do Xmax, czyli od 0 do 3956279999. Liczba ta będzie naszym kluczem szyfrującym.
SzyfrowanieZasada szyfrowania jest następująca:
Odczytujemy klucz i wprowadzamy go do ziarna pseudolosowego naszego generatora LCG. Na podstawie tego klucza generator LCG będzie tworzył ściśle określony ciąg liczb pseudolosowych. Odczytujemy następnie łańcuch s, który ma zostać zaszyfrowany. Zamieniamy wszystkie litery z małych na duże (nasz algorytm szyfruje tylko duże znaki). Przetwarzamy kolejne znaki tego łańcucha. Dla każdego znaku generujemy liczbę pseudolosową X. Teraz sprawdzamy, czy przetwarzany znak łańcucha s jest dużą literą od A do Z. Jeśli tak, to obliczamy jego kod ch i przekształcamy go zgodnie ze wzorem:
ch = 65 + (ch - 65 + X mod 26) mod 26
Wynik jest kodem zaszyfrowanego znaku – umieszczamy go w łańcuchu s na miejscu przetwarzanego znaku i kontynuujemy te same operacje aż do przetworzenia wszystkich znaków w s. Na końcu łańcuch s zwracamy jako wynik szyfrowania.
Algorytm szyfrowania z pseudolosowym odstępemWejście
Wyjście:Zaszyfrowany łańcuch s Elementy pomocnicze:
Lista kroków:
DeszyfrowanieZasada rozszyfrowywania jest prawie identyczna jak przy szyfrowaniu. Jedyna różnica leży we wzorze obliczania kodu znaku z kodu szyfru:
ch = 65 + (ch - 39 - X mod 26) mod 26
Algorytm deszyfrowania z pseudolosowym odstępemWejście
Wyjście:Rozszyfrowany łańcuch s Elementy pomocnicze:
Lista kroków:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe