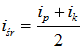Autor artykułu: mgr Jerzy Wałaszek
©2014 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek |
©2014 mgr
Jerzy Wałaszek
|
Wyszukiwanie binarne
Przez zbiór uporządkowany (ang. ordered set)
rozumiemy zbiór, w którym pomiędzy elementami zachowana jest pewna relacja,
która je porządkuje. Na przykład weźmy relację mniejszy lub równy. Powiemy,
że zbiór jest uporządkowany niemalejąco, jeśli dla dowolnych dwóch elementów
tego zbioru jest spełniony warunek:
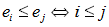
Oznacza to, że jeśli weźmiemy dwa dowolne elementy tego zbioru takie, że pierwszy poprzedza w tym zbiorze element drugi, to ten pierwszy nigdy nie będzie większy od drugiego. Czyli idąc w głąb zbioru, elementy są albo równe, albo coraz większe (nie maleją). Ta własność zbiorów uporządkowanych pozwala nam zastosować bardziej efektywne algorytmy wyszukiwania. Pierwszy z tych algorytmów to wyszukiwanie binarne. Postąpimy w sposób następujący.
Wyznaczymy element środkowy zbioru T. Sprawdzimy, czy jest on
poszukiwanym elementem. Jeśli tak, to element został znaleziony i możemy
zakończyć poszukiwania. Jeśli nie, to poszukiwany element jest albo
mniejszy od elementu środkowego, albo większy. Ponieważ zbiór jest
uporządkowany, to elementy mniejsze od środkowego będą leżały w
pierwszej połówce zbioru, a elementy większe w drugiej połówce. Zatem w
następnym obiegu zbiór możemy zredukować do pierwszej lub drugiej
połówki – jest w nich o połowę mniej elementów. Mając nowy zbiór
postępujemy w sposób identyczny – znów wyznaczamy element środkowy,
sprawdzamy, czy jest poszukiwanym elementem. Jeśli nie, to zbiór
dzielimy znów na dwie połowy – elementy mniejsze od środkowego i
elementy większe od środkowego. Poszukiwania kontynuujemy w odpowiedniej
połówce zbioru aż znajdziemy poszukiwany element lub do chwili, gdy po
podziale połówka zbioru nie zawiera dalszych elementów.
Ponieważ w każdym obiegu pętli algorytm redukuje liczbę elementów o połowę, to jego klasa złożoności obliczeniowej jest równa O(log n). Jest to bardzo korzystna złożoność. Na przykład w algorytmie wyszukiwania liniowego przy 1000000 elementów należało wykonać aż 1000000 porównań, aby stwierdzić, iż elementu poszukiwanego nie ma w zbiorze. W naszym algorytmie wystarczy 20 porównań. Oczywiście algorytm wyszukiwania liniowego może być zastosowany dla dowolnego zbioru. Nasz algorytm można stosować tylko i wyłącznie w zbiorze uporządkowanym. Ze względu na podział zbioru na kolejne połówki, ćwierci itd. algorytm nosi nazwę wyszukiwania binarnego (ang. binary search). Musimy uściślić sposób podziału zbioru na coraz mniejsze fragmenty. Zbiór odwzorowujemy w tablicy T składającej się z n elementów ponumerowanych kolejno od 0 do n-1. Określmy dwa indeksy:
ip – indeks pierwszego elementu tablicy T
ik – indeks końcowego elementu tablicy T
Indeksy ip i ik określają obszar zbioru w tablicy T. Początkowo będą oczywiście równe: ip = 0 oraz ik = n - 1. Na podstawie tych dwóch indeksów obliczamy indeks elementu środkowego isr:
Jeśli zbiór T jest uporządkowany niemalejąco, to:
Zatem w przypadku, gdy v < T[isr], to przechodzimy do pierwszej połówki, w której indeksy przebiegają od ip do isr - 1. Element T[isr] pomijamy, gdyż wiadomo, że o niego nam nie chodzi. Jeśli v > T[isr], to przechodzimy do drugiej połówki o indeksach od isr + 1 do ik.
Algorytm wyszukiwania binarnegoWejście
Wyjście:p = indeks elementu o wartości v
lub Zmienne pomocnicze
Lista kroków:
Porównaj ten algorytm z algorytmem bisekcji. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ćwiczenie
Na podstawie algorytmu napisz program, który wyszukuje zadaną wartość w
zbiorze uporządkowanym. Dodatkowo program powinien zliczać ilość obiegów
pętli w algorytmie i po zakończeniu wyświetlać tę ilość – posłuży to do
porównania efektywności tego algorytmu z następnym.
Pierwsza liczba oznacza ilość elementów w zbiorze. Druga liczba jest poszukiwanym elementem. Pozostałe liczby to elementy do przeszukania. Skopiuj te dane do notatnika, aby móc zmieniać drugą liczbę.
411 698 3 3 4 4 6 10 10 13 14 14 17 17 18 21 22 22 22 24 28 31 34 34 38 40 40 40 41 42 43 45 45 47 49 50 50 54 56 58 58 60 63 63 66 70 70 71 72 74 76 78 82 85 89 90 94 94 95 97 97 97 98 100 101 101 101 103 105 109 113 116 119 121 121 124 128 130 134 137 139 143 144 148 148 152 154 156 157 159 160 160 160 164 168 169 170 171 174 174 177 181 185 185 189 193 195 195 197 198 200 202 202 202 203 204 208 208 212 216 219 219 223 226 227 230 234 235 236 236 239 239 241 243 243 247 247 249 251 253 255 257 257 258 259 261 265 268 269 273 275 276 278 282 282 284 286 287 288 291 294 296 296 298 299 301 301 303 303 305 309 310 314 314 317 321 325 325 325 327 330 331 333 336 337 341 342 344 344 346 349 351 351 353 357 359 360 360 361 364 365 367 368 368 372 373 374 375 375 379 382 384 386 388 392 393 397 397 400 403 406 407 410 411 414 416 419 420 420 422 422 423 426 426 430 434 436 438 439 440 441 442 446 450 454 457 460 462 464 464 467 470 473 473 474 475 479 483 484 487 490 491 491 494 496 499 503 507 510 511 513 515 518 520 524 528 531 533 537 540 543 545 548 551 554 556 560 564 568 568 569 569 569 570 570 571 571 572 572 575 579 582 582 583 587 589 590 594 595 597 601 604 608 608 608 612 615 616 620 620 623 623 627 629 633 633 633 635 639 641 643 646 648 650 653 654 655 659 661 663 663 666 670 673 674 678 678 681 681 684 688 689 691 691 693 696 697 699 700 702 702 703 704 707 707 707 707 708 708 708 711 711 714 717 717 720 723 725 727 727 728 729 729 730 730 731 731 734 736 738 741 743 743 745 746 748 748 751 754 754 756 756 756 758 760 760 763 767 770 770 771 773 775 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wyszukiwanie interpolacyjneWyszukiwanie binarne (ang. binary search) zawsze szuka elementu o wartości v w środku zbioru. Tymczasem, jeśli założymy liniowy rozkład wartości elementów w przeszukiwanym zbiorze, to możemy precyzyjniej wytypować spodziewaną pozycję poszukiwanego elementu na podstawie jego wartości. Wzór jest następujący:
Powyższy wzór wyprowadzamy z prostej proporcji. Jeśli zbiór posiada liniowy rozkład elementów, to odległość wartości poszukiwanej v od T[ip] jest w przybliżeniu proporcjonalna do liczby elementów pomiędzy isr a ip:
Skoro tak, to zachodzi przybliżona proporcja:
Aby zrozumieć zaletę tego sposobu wyznaczania pozycji, przyjrzyjmy się poniższemu przykładowi, gdzie wyliczyliśmy pozycję wg wzoru z poprzedniego rozdziału oraz wg wzoru podanego powyżej. Poszukiwany element zaznaczono kolorem czerwonym:
Binarne wyznaczenie pozycji:
Interpolacyjne wyznaczenie pozycji:
Metoda interpolacyjna wyznacza pozycję zwykle dużo bliżej poszukiwanego elementu niż metoda binarna (w przykładzie trafiamy za pierwszym razem). Zauważ, iż w metodzie binarnej nie korzystamy zupełnie z wartości elementów na krańcach dzielonej partycji, czyli działamy niejako na ślepo. Natomiast metoda interpolacyjna wyznacza położenie w zależności od wartości elementów zbioru oraz wartości poszukiwanego elementu. Działa zatem celowo dostosowując się do zastanych w zbiorze warunków. Stąd jej dużo większa efektywność. Po wyznaczeniu położenia isr
pozostała część algorytmu jest bardzo podobna do wyszukiwania binarnego.
Sprawdzamy, czy element na pozycji isr posiada
poszukiwaną wartość
v. Jeśli tak, to wyszukiwanie kończy się zwróceniem pozycji isr.
W przeciwnym razie jeśli v jest mniejsze od elementu T[isr],
to poszukiwania kontynuujemy w lewej części zbioru od elementu T Wyszukiwanie interpolacyjne posiada klasę czasowej złożoności
obliczeniowej równą
Algorytm wyszukiwania interpolacyjnegoWejście
Wyjście:p = indeks elementu o wartości v
lub Zmienne pomocnicze
Lista kroków:
Porównaj ten algorytm z algorytmem regula falsi. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ćwiczenie
Porównaj efektywność wyszukiwania interpolacyjnego z wyszukiwaniem
binarnym.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe