
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2013 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2013 mgr
Jerzy Wałaszek
|
 Bjarne Stroustrup - (C)Wikipedia |
Język C++ jest językiem programowania stworzonym przez Bjarne Stroustrupa, profesora Texas A&M University. Jest to język wysokiego poziomu (ang. HLL - High Level Language), co oznacza, iż oddala się on od struktury wewnętrznej komputera pozwalając programiście skupić się nad samym algorytmem.
Język C++ należy do grupy języków kompilowanych. Oznacza to, iż programista w edytorze tworzy tekst programu, który następnie jest przekazywany do kompilatora. Kompilator analizuje otrzymany tekst i na jego podstawie tworzy program wynikowy zawierający binarne instrukcje dla procesora.
| Przykład: Instrukcja przypisania w języku C++: a = (b + c) * d; zostaje zamieniona na ciąg rozkazów maszynowych dla procesora: mov eax,[b] ; pobranie do akumulatora b add eax,[c] ; dodanie do akumulatora c mul [d] ; wymnożenie akumulatora przez d mov [a],eax ; umieszczenie wyniku w a |
Podane powyżej polecenia są umieszczane w programie wynikowym w postaci swoich kodów binarnych (odpowiednich ciągów bitów 0 lub 1). Z przytoczonego powyżej przykładu wynika jasno, iż języki wysokiego poziomu są bardziej czytelne dla ludzi. Jednakże procesor nie potrafi bezpośrednio wykonywać zawartych w takim programie poleceń - program musi być przetłumaczony do postaci zrozumiałej dla procesora, czyli do binarnych kodów instrukcji maszynowych.
|
tworzenie tekstu programu |
→ |
kompilacja tekstu na język maszynowy |
→ |
uruchomienie programu wynikowego |
Do programowania w języku C++ będziemy wykorzystywać dwa środowiska:
Oba środowiska są dostępne do darmowego pobrania z sieci.
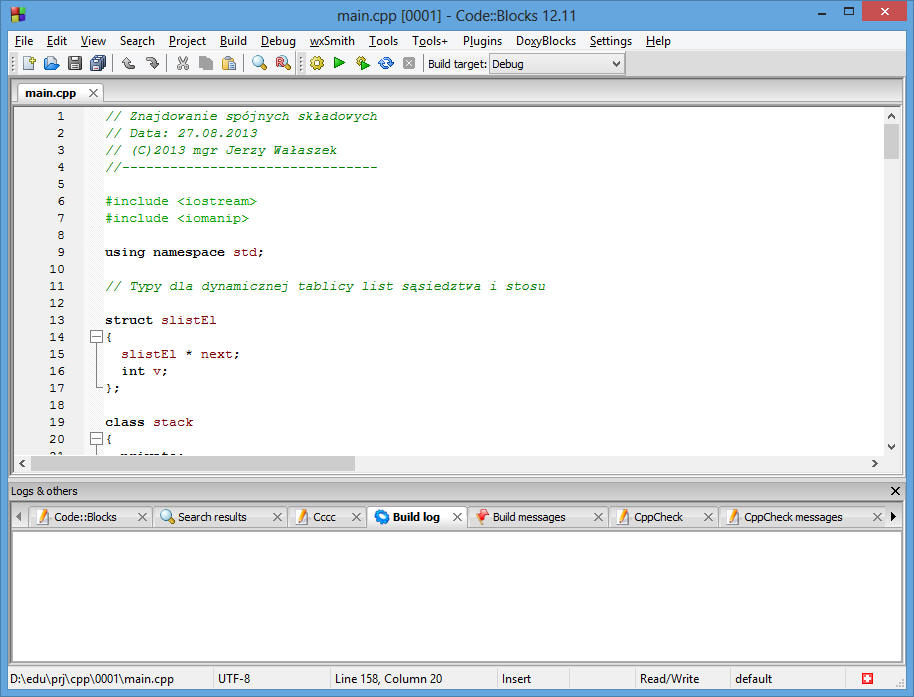
Code::Blocks jest bardzo dobrym środowiskiem programowania w języku C++. Wykorzystuje ono doskonały kompilator MingW, który pozwala tworzyć programy dla Windows i dla Linuxa. Licencja umożliwia tworzenie również programów komercyjnych
 |
|
  |
 |
Borland C++ Builder jest środowiskiem do szybkiego tworzenia aplikacji okienkowych – RAD (ang. Rapid Application Development), lecz przy jego pomocy można również tworzyć zwykłe programy w C++. Środowisko to nie jest już rozwijane przez firmę Borland, jednakże wciąż nadaje się znakomicie do nauki programowania. Licencja pozwala tworzyć jedynie programy niekomercyjne.
Przy instalacji środowiska Borland C++ Builder potrzebujesz publicznego klucza i kodu aktywacyjnego:
Serial Number: 49b2-9z8py-4s7pv
Authorization Key: t2d-zy7
Po instalacji możesz zarejestrować produkt w firmie Borland. W tym celu musisz założyć sobie konto. Nie jest to skomplikowane i można tego dokonać wprost z programu instalacyjnego. Po rejestracji, która jest darmowa, staniesz się legalnym użytkownikiem pakietu. Jeśli nie zarejestrujesz pakietu, to wciąż będziesz mógł korzystać ze wszystkich jego funkcji.
W systemach Windows 7/8 pakiet Borland C++ Builder należy uruchamiać z uprawnieniami administratora.
W edytorze programów mogą się pojawić kłopoty z wprowadzaniem polskich znaków. Np. zamiast ś zostaje otwarte okienko dialogowe. Możemy tę funkcję wyłączyć wprowadzając drobną modyfikację do rejestru Windows:Po uruchomieniu środowiska Borland C++ Builder problem powinien zniknąć.
Programy normalnie utworzone w środowisku Borland C++ Builder wykorzystują biblioteki DLL, które to środowisko zainstalowało w systemie. Zaletą takiego rozwiązania jest dosyć krótki kod programu - kilkadziesiąt kilobajtów. Niestety, jeśli zechcesz przesłać komuś gotowy program, a ten ktoś nie będzie miał zainstalowanego środowiska Borland C++ Builder, to program po prostu się nie uruchomi, zgłaszając przy starcie brak bibliotek DLL. Na szczęście istnieje proste rozwiązanie tego problemu:
Zapisz i przekompiluj swój projekt. Objętość programu wzrośnie do kilkuset kilobajtów, jednakże teraz program wszystko będzie zawierał w sobie i nie wystąpi już brak bibliotek DLL przy jego uruchomieniu na innym komputerze.
Pusty program w języku C++ wygląda następująco:
int main()
{
return 0;
}
|
Tworzy go funkcja main(). Jest to główna funkcja, od której rozpoczyna się wykonanie programu. Funkcja jest grupą poleceń, które zostaną wykonane, gdy funkcja zostanie wywołana gdzieś w programie. Funkcję main() wywołuje system operacyjny, gdy program zostaje załadowany do pamięci komputera i jest uruchamiany. Funkcję w języku C++ tworzymy wg schematu:
| typ_wyniku | – | określa typ danych, które funkcja zwraca |
| nazwa_funkcji | – | identyfikuje nazwę funkcji. Nazwa w języku C++ może być zbudowana z dużych i małych liter, cyfr oraz znaku _. Duże i małe litery są rozróżniane. Pierwszym znakiem nazwy nie może być cyfra (cyfry rozpoczynają stałe liczbowe). |
| lista_argumentów | – | określa dane, które są przekazywane do funkcji
w czasie jej wywołania. Lista ta ma postać: typ_argumentu nazwa_argumentu, typ_argumentu nazwa_argumentu, ... typ_argumentu określa typ danych, które są przekazywane w
argumencie do funkcji z programu, który ją wywołuje |
| treść_funkcji | – | polecenia, które zostaną wykonane w momencie wywołania funkcji. |
Instrukcja return zwraca wynik i kończy działanie funkcji. Po tej instrukcji następuje powrót do programu, który funkcję wywołał. W przypadku funkcji main() return kończy działanie programu, w zwracana wartość może być wykorzystana przez system. Wartość 0 oznacza, że program zakończył się z sukcesem.
Każda pojedyncza instrukcja w języku C++ musi kończyć się średnikiem. Brak średnika jest błędem i kompilator odmówi tłumaczenia takiego programu.
Komentarze służą do dokumentowania programu oraz do wyjaśniania niektórych jego fragmentów. Komentarze są całkowicie ignorowane przez kompilator i nie pojawiają się w programie wynikowym. Programy warto opatrywać komentarzami, ponieważ nawet sam twórca programu często zapomina, jak program dokładnie działa i jakie funkcje pełnią poszczególne elementy – szczególnie dotyczy to programów dużych.
W języku C++ mamy dwa rodzaje komentarzy:
// Komentarz wierszowy, obowiązuje do końca wiersza /* Komentarz blokowy, który może obejmować dowolną liczbę wierszy w programie */ |
Zwykle chcemy w programie coś wyświetlać w oknie konsoli lub odczytywać dane, które do programu wprowadza użytkownik. Język C++ nie posiada rozkazów, które obsługują bezpośrednio operacje we/wy. W tym celu korzystamy z różnych funkcji, które udostępniają nam różne biblioteki. W C++ bardzo popularną biblioteką jest STL (ang. Standard Template Library – Biblioteka Standardowych Szablonów). STL zawiera bardzo wiele użytecznych obiektów. Między innymi tzw. strumienie wejścia/wyjścia. Strumień (ang. stream) jest obiektem, który umożliwia przesyłanie danych. Jeśli interesuje nas wyświetlanie tekstu w oknie konsoli, to będziemy korzystali ze strumienia konsoli. Aby uzyskać wygodny dostęp do tego strumienia, musimy dołączyć do naszego programu odpowiedni plik nagłówkowy, który zawiera definicję obiektu strumienia konsoli. Robimy to tak:
#include <iostream>
using namespace std;
int main()
{
cout << "Witamy w C++" << endl;
return 0;
}
|
| #include <plik_nagłówkowy> | – | dyrektywa preprocesora, która wstawia w trakcie kompilacji wybrany plik do tekstu programu. Kompilator widzi nasz plik źródłowy tak, jakby w tym miejscu znajdowała się treść wybranego pliku. Dzięki temu rozwiązaniu nie musimy wprowadzać do programu definicji często wykorzystywanych elementów. |
| iostream | – | plik nagłówkowy biblioteki STL, który definiuje strumień wejścia/wyjścia na konsolę znakową, czyli okienko tekstowe Windows. |
| using namespace std; | – | obiekty biblioteki STL są zdefiniowane wewnątrz tzw. przestrzeni nazw std. Chodzi o to, aby nazwy tych obiektów nie kolidowały z nazwami obiektów utworzonych przez użytkownika. Dyrektywa ta informuje kompilator, że korzystamy z takiej przestrzeni nazw. Bez niej każdy element STL należałoby poprzedzić odpowiednim kwalifikatorem: np. std::cout. |
| cout | – | strumień wyjścia na konsolę (ang. console output). Dane przesłane do tego strumienia pojawią się w oknie konsoli znakowej. |
| << | – | to jest operator przesłania danych do strumienia.
Składnia operatora jest bardzo prosta: strumień << dane Operatory << można łączyć: strumień << dane1 << dane2 << ... |
| endl | – | tzw. manipulator, czyli funkcja powodująca przeniesienie wydruku na początek kolejnego wiersza (endl = end of line = koniec wiersza). |
Podstawowe typy danych w C++ to:
| int | – | liczba całkowita, 32 bitowa, ze znakiem. Zakres od -231 do 231 - 1 |
| unsigned int | – | liczba całkowita, 32 bitowa, bez znaku. Zakres od 0 do 232 - 1 |
| long long | – | liczba całkowita, 64 bitowa, ze znakiem. Zakres od -263 do 263 - 1 |
| unsigned long long | – | liczba całkowita, 64 bitowa, bez znaku. Zakres od 0 do 264 - 1 |
| float | – | liczba zmiennoprzecinkowa, 32 bitowa, pojedynczej precyzji. Dokładność 7-8 cyfr znaczących. Niezalecana. |
| double | – | liczba zmiennoprzecinkowa, 64 bitowa, podwójnej precyzji. Dokładność 15 cyfr znaczących. Zalecana. |
| long double | – | liczba zmiennoprzecinkowa, 80 bitowa, rozszerzonej precyzji. Dokładność 20 cyfr znaczących. Nieprzenośna na inne platformy. |
| bool | – | typ logiczny, który przyjmuje tylko dwie wartości: false – 0 lub true – 1, 8 bitów |
| unsigned char | – | typ znakowy, odpowiada literze w kodzie ASCII, 8 bitów. Zakres od 0 do 255. Może być traktowany jako liczba 8 bitowa bez znaku. |
| signed char | – | typ znakowy, odpowiada literze w kodzie ASCII, 8 bitów, Zakres od -128 do 127. Może być traktowany jako liczba 8 bitowa ze znakiem |
| char | – | jeden z powyższych dwóch typów w zależności od ustawień kompilatora. |
Jeśli nie będą obecne specyficzne wymagania, to standardowo będziemy stosować następujące typy danych:
int double bool char
Stała jest elementem, który posiada stałą wartość. W języku C++ mamy następujące rodzaje stałych:
W programie można stosować nazwy symboliczne, które tworzymy następująco:
const typ nazwa_stałej = wartość; const int MAXW = 15; const double PI = 3.1415; const char ID = 'x';
Przykład:
#include <iostream>
using namespace std;
int main()
{
cout << 255 << '=' << 0xff << endl;
return 0;
}
|
#include <iostream>
using namespace std;
const double PI = 3.14159265358979;
const double R = 3;
int main()
{
cout << "R = " << R << endl
<< "Obw = " << 2 * PI * R << endl;
return 0;
}
|
Zmienna jest obiektem, który przechowuje dane w programie. Przed pierwszym użyciem zmienna musi zostać utworzona. Robimy to w sposób następujący:
typ nazwa;
Typ określa rodzaj informacji, którą zmienna będzie przechowywała. Nazwa zmiennej umożliwia odwołanie się do niej w programie. Nazwa może składać się z małych i dużych liter, cyfr oraz znaku _. Pierwszym znakiem zmiennej nie może być cyfra.
int a; double x;
W jednej definicji można tworzyć wiele zmiennych:
int a,b,c; double x,y,z;
Zmiennym można nadawać wartości początkowe w trakcie definicji:
int a = 5, b = 14;
Zmienne należy definiować przed pierwszym użyciem w programie. Zasięg zmiennej, czyli jej widoczność, zależy od miejsca zdefiniowania. Zmienne definiowane na samym początku programu są zmiennymi globalnymi, które są widoczne we wszystkich funkcjach. Zmienne zdefiniowane wewnątrz funkcji są zmiennymi lokalnymi, które są widoczne tylko w funkcji, w której zostały zdefiniowane. Zmienne globalne i lokalne mogą posiadać te same nazwy. W takim przypadku zmienne lokalne "przykrywają" zmienne globalne.
#include <iostream>
using namespace std;
int a = 15; // zmienna globalna a
// Funkcja nr 1
void f1()
{
int a = 55; // zmienna lokalna a
cout << "W f1() zmienna a = " << a << endl;
}
// Funkcja nr 2
void f2()
{
cout << "W f2() zmienna a = " << a << endl;
}
int main()
{
f1(); // wywołujemy funkcję nr 1
f2(); // wywołujemy funkcję nr 2
return 0;
}
|
Jeśli w funkcji posiadającej zmienną lokalną o takiej samej nazwie jak zmienna globalna chcemy odwołać się do zmiennej globalnej, to jej nazwę musimy poprzedzić operatorem zakresu ::
#include <iostream>
using namespace std;
int a = 15; // zmienna globalna a
int main()
{
int a = 333; // zmienna lokalna
cout << a << endl; // odwołanie do zmiennej lokalnej
cout << ::a << endl; // odwołanie do zmiennej globalnej
return 0;
}
|
Operator przypisania (ang. assignment operator) umożliwia zmianę zawartości zmiennej. Składnia jest następująca:
zmienna = wyrażenie;
Komputer najpierw wylicza wartość wyrażenia po prawej stronie operatora, a następnie wynik jest umieszczany w zmiennej po lewej stronie operatora. W wyrażeniu mogą występować stałe, zmienne, funkcje oraz operatory arytmetyczne i logiczne.
#include <iostream>
using namespace std;
const double PI = 3.14159265358979;
int main()
{
double o,p,r;
r = 3; // promień koła
o = 2 * PI * r; // obwód koła
p = PI * r * r; // pole koła
cout << "r = " << r << endl
<< "o = " << o << endl
<< "p = " << p << endl;
return 0;
}
|
Przypisanie w języku C++ posiada wartość (równą temu, co zostało przypisane). Umożliwia to łańcuchowe inicjowanie zmiennych:
a = b = c = d = 5; // wszystkie zmienne a, b, c i d otrzymają wartość 5
| + | – | dodawanie: |
c = a + 5; |
| - | – | odejmowanie: |
c = a - 5; |
| * | – | mnożenie: |
c = a * b; |
| / | – | dzielenie: |
c = a / 5; |
| % | – | reszta z dzielenia: |
c = a % 5; |
Uwaga: operator dzielenia zachowuje się różnie w zależności od typu argumentów. Jeśli argumenty są całkowite, to wynik dzielenia jest zaokrąglany do liczby całkowitej. Jest to tak zwane dzielenie całkowitoliczbowe. Jeśli jeden z argumentów jest zmiennoprzecinkowy, to wynik jest również zmiennoprzecinkowy (ułamkowy):
#include <iostream>
using namespace std;
int main()
{
double a;
a = 5 / 2; cout << a << endl; // dzielenie całkowite
a = 5 / 2.0; cout << a << endl; // dzielenie zmiennoprzecinkowe
a = 5.0 / 2; cout << a << endl; // dzielenie zmiennoprzecinkowe
return 0;
}
|
W języku C++ każde wyrażenie arytmetyczne może zostać potraktowane jak wyrażenie logiczne. Wyrażenie o wartości zero posiada wartość logiczną false, a wyrażenie o wartości różnej od zera posiada wartość logiczną true.
#include <iostream>
using namespace std;
int main()
{
cout << !5 << endl
<< !0 << endl;
return 0;
}
|
Uwaga: operacje logiczne podlegają tzw. zasadzie zwarcia. Jeśli pierwsze wyrażenie a jest różne od zera, to wynik operacji jest już przesądzony i wyrażenie b nie jest wcale obliczane. Ma to znaczenie wtedy, gdy w wyrażeniu b wywołujemy jakieś funkcje – w takim przypadku funkcje te nie zostaną wywołane.
#include <iostream>
using namespace std;
int main()
{
cout << (0 || 0) << endl
<< (7 || 0) << endl
<< (0 || 1) << endl
<< (2 || -5) << endl;
return 0;
}
|
Uwaga: tutaj również obowiązuje zasada zwarcia. Jeśli pierwsze wyrażenie a jest równe zero, to wynik operacji jest przesądzony i wyrażenie b nie jest wyliczane.
#include <iostream>
using namespace std;
int main()
{
cout << (0 && 0) << endl
<< (7 && 0) << endl
<< (0 && 1) << endl
<< (2 && -5) << endl;
return 0;
}
|
| == | – | równe: |
a == b |
| != | – | różne: |
a != 5 |
| < | – | mniejsze: |
a < 3 |
| <= | – | mniejsze lub równe: |
a <= b |
| > | – | większe: |
a > b + 1 |
| >= | – | większe lub równe: |
a >= b |
Uwaga: wartości zmiennoprzecinkowych nie wolno do siebie przyrównywać, ponieważ obliczenia na liczbach tego typu są zwykle obarczone błędem:
#include <iostream>
using namespace std;
int main()
{
double a = 0.7;
a = a + 0.1;
a = a + 0.1;
a = a + 0.1; // a powinno być teraz równe 1
cout << (a == 1) << endl;
return 0;
}
|
Powodem tego błędu w tym programie jest to, że dane są zapamiętywane w systemie binarnym. Ułamek dziesiętny 0,1 w systemie dwójkowym ma nieskończone rozwinięcie, podobnie jak 1/3 w systemie dziesiętnym to 0,333.... Liczba 0,1 nie jest zapamiętywana dokładnie, lecz z pewnym bardzo małym błędem. Jednakże błąd ten powoduje, że trzykrotne dodanie 0,1 do 0,7 nie daje liczby 1, lecz liczbę bardzo bliską 1. Natomiast porównanie wykonywane jest z wartością dokładną 1. Ponieważ a się nieco różni od 1, wynikiem porównania jest fałsz, czyli zero. Aby program zadziałał wg intencji programisty, należy zbadać nie to, czy a jest równe 1, lecz czy różnica |a - 1| jest dostatecznie mała, czyli czy jest spełniony warunek:
Wartość ε jest dokładnością przybliżenia. Zwykle jest to bardzo mała liczba, np. 0,000001 (teoria doboru dokładności przybliżenia jest dosyć skomplikowana – dokładnie omawia się ją na studiach w ramach analizy numerycznej, a w liceum damy sobie z tym spokój).
#include <iostream>
#include <cmath>
using namespace std;
const double EPS = 0.000001; // dokładność obliczeń
int main()
{
double a = 0.7;
a = a + 0.1;
a = a + 0.1;
a = a + 0.1; // a jest w przybliżeniu równe 1
cout << (fabs(a - 1) < EPS) << endl;
return 0;
}
|
Uwaga: w programie jest wykorzystywana funkcja obliczająca wartość bezwzględną fabs(x). Jej definicja znajduje się w pliku nagłówkowym cmath.
Język C++ pozwala przeprowadzać operacje na poszczególnych bitach argumentów. Operacja bitowa, w przeciwieństwie do logicznej, zmienia zawartość odpowiadających sobie bitów.
Uwaga: nie myl operatora przesuwu bitów << z operatorem zapisu do strumienia <<. One tylko wyglądają tak samo.
5 << 2 = 1012 << 2 = 101002 = 2010
#include <iostream>
using namespace std;
int main()
{
cout << (5 << 2) << endl; // w nawiasie jest przesuw bitów!
return 0;
}
|
12 >> 2 = 11002 >> 2 = 112 = 310
#include <iostream>
using namespace std;
int main()
{
cout << (12 >> 2) << endl; // w nawiasie jest przesuw bitów!
return 0;
}
|
5 | 18 = 101 | 10010 00101 | 10010 ------- 10111 = 23
#include <iostream>
using namespace std;
int main()
{
cout << (5 | 18) << endl;
return 0;
} |
7 & 19 = 111 & 10011 00111 & 10011 ------- 00011 = 3
#include <iostream>
using namespace std;
int main()
{
cout << (7 & 19) << endl;
return 0;
} |
5 ^ 12 = 101 & 1100 0101 ^ 1100 ------ 1001 = 9
#include <iostream>
using namespace std;
int main()
{
cout << (5 ^ 12) << endl;
return 0;
} |
Zawartość zmiennej możemy zwiększyć o 1 przy pomocy operatora ++ lub zmniejszyć o 1 przy pomocy operatora --. Operatory te mogą stać przed zmienną lub za zmienną:
zmienna++; ++zmienna; zmienna--; --zmienna;
Różnica występuje wtedy, gdy tego typu operacja jest traktowana jako wyrażenie (np. w przypisaniu lub w argumencie wywołania funkcji). W takim przypadku umieszczenie operatora ++ lub -- za zmienną powoduje, że w wyrażeniu zmienna ma swoją starą wartość. Zwiększenie lub zmniejszenie nastąpi dopiero po wyliczeniu wyrażenia. Jeśli operator ++ lub -- umieścimy przed zmienną, to zmienna najpierw zostanie zmodyfikowana, a dopiero po tej operacji jej nowa wartość będzie użyta w wyrażeniu.
#include <iostream>
using namespace std;
int main()
{
int a = 5, b = 5;
cout << a << " " << b << endl; // przed modyfikacją
cout << ++a << " " << b++ << endl; // modyfikacja
cout << a << " " << b << endl; // po modyfikacji
return 0;
}
|
Konstrukcje typu:
zmienna = zmienna operator wyrażenie;
zastępujemy często formą uproszczoną:
zmienna operator= wyrażenie;
a += 10; // zwiększenie a o 10 a -= 5; // zmniejszenie a o 5 a *= 4; // pomnożenie a przez 4, itd.
Strumień cin umożliwia odczyt danych wprowadzonych przez użytkownika z klawiatury. Składnia operacji jest następująca:
cin >> zmienna;
Dane można odczytywać do kilku zmiennych:
cin >> zmienna1 >> zmienna 2 >> ...
#include <iostream>
using namespace std;
const double PI = 3.14159265358979;
int main()
{
double r,o,p;
cout << "Obliczanie obwodu i pola kola\n"
"-----------------------------\n\n";
cout << "r = "; cin >> r; // odczytujemy promień koła
o = 2 * PI * r; // obliczamy obwód
p = PI * r * r; // obliczamy pole
cout << endl
<< "obwod = " << o << endl
<< "pole = " << p << endl;
return 0;
}
|
Wyprowadzając dane często musimy przedstawiać je w określonym formacie. Do tego celu służą manipulatory, czyli funkcje, które współpracują ze strumieniem. Aby uzyskać dostęp do manipulatorów, należy dołączyć plik nagłówkowy iomanip. Manipulatory używamy następująco:
| setprecision(n) | – | na wydruku liczb zmiennoprzecinkowych będzie n cyfr po przecinku |
| fixed | – | liczby zmiennoprzecinkowe będą wyświetlane jako
część całkowita, kropka dziesiętna, część ułamkowa. Np. 12.765 |
| scientific | – | liczby zmiennoprzecinkowe będą wyświetlane w
postaci naukowej jako mantysa, e, wykładnik. Np. 2.5e3 (2,5 x 103 = 2500) |
| setw(n) | – | ustawia długość pola wydruku na n znaków. Działa tylko dla następnego elementu przesyłanego do strumienia |
| left | – | element zostanie wydrukowany w polu z dosunięciem do lewej krawędzi |
| right | – | element będzie wydrukowany w polu z dosunięciem do prawej krawędzi |
| setfil(z) | – | określa znak, którym zostanie wypełniona ta część pola wydruku, której nie zajął drukowany w nim element. |
| endl | – | powoduje przejście z wydrukiem na początek nowego wiersza |
| dec | – | liczby całkowite są drukowane lub wprowadzane (cin) jako dziesiętne |
| hex | – | liczby całkowite są drukowane lub wprowadzane (cin) jako szesnastkowe |
| oct | – | liczby całkowite są drukowane lub wprowadzane (cin) jako ósemkowe |
#include <iostream>
#include <iomanip>
using namespace std;
const double PI = 3.14159265358979;
int main()
{
double r,o,p;
cout << setprecision(2) << fixed;
cout << "Obliczanie obwodu i pola kola\n"
"-----------------------------\n\n";
cout << "r = "; cin >> r; // odczytujemy promień koła
o = 2 * PI * r; // obliczamy obwód
p = PI * r * r; // obliczamy pole
cout << endl
<< "obwod = " << setw(8) << o << endl
<< "pole = " << setw(8) << p << endl;
return 0;
}
|
Instrukcja if pozwala podejmować decyzje w zależności od spełnienia określonego warunku. Posiada ona następującą składnię:
if(wyrażenie) instrukcja1; else instrukcja2;
Jeśli wyrażenie ma wartość różną od zera (czyli jest prawdziwe), to zostaje wykonana instrukcja1, a instrukcja2 będzie zupełnie pominięta. Z kolei gdy wyrażenie ma wartość 0 (czyli jest fałszywe), to pomijana jest instrukcja1, a wykonana zostaje instrukcja2.
Czasami instrukcja2 jest zbędna. Możemy wtedy użyć wersji uproszczonej:
if(wyrażenie) instrukcja;
Uwaga: każdą pojedynczą instrukcję w języku C++ można zastąpić instrukcją blokową o postaci:
{
dowolny ciąg instrukcji
}
Przy tej modyfikacji instrukcja if przyjmuje postać:
if(warunek)
{
ciąg instrukcji wykonywanych, gdy warunek jest prawdziwy
}
else
{
ciąg instrukcji wykonywanych, gdy warunek jest fałszywy
}
lub
if(warunek)
{
ciąg instrukcji wykonywanych, gdy warunek jest prawdziwy
}
Zwróć uwagę, że po instrukcji blokowej nie umieszcza się średnika zamykającego instrukcję. Funkcję tę pełni tutaj klamerka zamykająca blok. Zmienne utworzone wewnątrz bloku są widoczne tylko w obrębie tego bloku.
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
const double EPS = 0.000001; // dokładność obliczeń
int main()
{
double a,b,c,delta,x1,x2;
cout << setprecision(4) << fixed;
cout << "Rownanie kwadratowe\n\n"
" 2\n"
"ax + bx + c = 0\n\n";
cout << "a = "; cin >> a; // odczytujemy współczynniki
cout << "b = "; cin >> b;
cout << "c = "; cin >> c;
cout << endl;
delta = b * b - 4 * a * c; // obliczamy wyróżnik
if(fabs(delta) < EPS)
{
// pierwiastek podwójny
x1 = -b / 2 / a;
cout << "x = " << setw(10) << x1 << endl;
}
else if(delta > 0)
{
// dwa pierwiastki
x1 = (-b - sqrt(delta)) / 2 / a;
x2 = (-b + sqrt(delta)) / 2 / a;
cout << "x1 = " << setw(10) << x1 << endl
<< "x2 = " << setw(10) << x2 << endl;
}
else
{
// brak pierwiastków
cout << "BRAK PIERWIASTKOW RZECZYWISTYCH" << endl;
}
return 0;
}
|
Pętle (ang. loops) umożliwiają wielokrotne wykonywanie tych samych rozkazów, co jest potrzebne np. przy przetwarzaniu ciągów danych, tablic, list, itp. Wyróżniamy dwa rodzaje pętli warunkowych w języku C++.
while(wyrażenie) instrukcja;
lub
while(wyrażnie)
{
dowolny ciąg instrukcji
}
Komputer wylicza wartość wyrażenia. Jeśli jest różna od zera (czyli jest prawdziwa), to wykonuje instrukcję (lub ciąg instrukcji w bloku) i wraca z powrotem na początek pętli do obliczania wyrażenia. Jeśli wyrażenie jest równe zero (fałszywe), to instrukcja nie zostanie wykonana, a pętla nie będzie się dalej wykonywać – komputer przejdzie do wykonywania pierwszej instrukcji za pętlą.
Zwróć uwagę, że jeśli na początku pętli wyrażenie jest równe zero, to instrukcja w pętli nie będzie wykonana ani jeden raz.
#include <iostream>
using namespace std;
int main()
{
unsigned int n = 1;
while(n) cout << (n <<= 1) << endl;
return 0;
}
|
do instrukcja; while(wyrażenie);
lub
do
{
dowolny ciąg instrukcji
} while(wyrażenie);
Komputer wykonuje instrukcję zawartą w pętli (lub ciąg instrukcji w bloku), po czym oblicza wartość wyrażenia. Jeśli jest różna od zera (czyli prawdziwa), to wraca na początek pętli i ponownie wykonuje instrukcję. Jeśli wyrażenie jest równe zero (fałszywe), to pętla zostaje przerwana.
Zauważ, że pętla do while zawsze wykonuje się przynajmniej raz.
#include <iostream>
using namespace std;
int main()
{
unsigned int n = 1;
do cout << (n <<= 1) << endl; while(n);
return 0;
}
|
i = wartość_początkowa; // inicjujemy licznik
while(i <= wartość_końcowa)
{
instrukcje wykonywane w pętli
i++; // modyfikacja licznika
}
#include <iostream>
using namespace std;
int main()
{
unsigned int i = 1;
while(i <= 10)
{
cout << i << " ";
i++;
}
cout << endl;
return 0;
} |
Ponieważ pętle tego typu są bardzo często wykorzystywane w programach w języku C++, to stworzono dla nich osobną instrukcję o następującej składni:
for(inicjalizacja; warunek_kontynuacji; modyfikacja) instrukcja;
lub
for(inicjalizacja; warunek_kontynuacji; modyfikacja)
{
instrukcje wykonywane w pętli
}
| inicjalizacja | – | instrukcja wykonywana przed rozpoczęciem
petli. Najczęściej instrukcja ta nadaje licznikowi wartość
początkową:for(i = 1;... |
| warunek_kontynuacji | – | wyrażenie, które jest obliczane na początku
każdego obiegu pętli. Jeśli ma wartość różną od zera, to
pętla wykonuje zawartą w niej instrukcję i znów wraca do
obliczania warunku – dokładnie tak samo jak w pętli typu
while. Najczęściej wyrażenie to określa granicę, do której
ma dojść licznik:for(i = 1; i <= 10;... |
| modyfikacja | – | instrukcja wykonywana na końcu każdego
obiegu pętli. Najczęściej zmienia ona wartość licznika
pętli:for(i = 1; i <= 10; i++)... |
| instrukcja | – | tutaj umieszczamy instrukcję, która ma być
w pętli powtarzana:for(i = 1; i <= 10; i++) cout << i << endl; |
#include <iostream>
using namespace std;
int main()
{
unsigned int i;
for(i = 1; i <= 10; i++) cout << i << " ";
cout << endl;
return 0;
}
|
Tablica jest obiektem, który przechowuje zadaną liczbę elementów tego samego typu. Tablicę deklarujemy następująco:
typ nazwa_tablicy[liczba_elementów]; int a[10]; // tablica 10 liczb całkowitych double x[100]; // tablica 100 liczb zmiennoprzecinkowych o podwójnej precyzji char c[1000]; // tablica 1000 znaków ASCII
Elementy tablicy są przechowywane w jednolitym bloku pamięci. Każdy element posiada numer, który nazywamy indeksem. Numeracja rozpoczyna się od 0.
int a[5]; // elementy: a[0] a[1] a[2] a[3] a[4], elementu a[5] w tej tablicy nie ma!!!
Dostęp do elementów tablicy uzyskujemy poprzez nazwę tablicy oraz indeks podany w nawiasach kwadratowych. Tablice idealnie nadają się do przetwarzania w pętlach iteracyjnych:
// Generacja liczb Fibonacciego
//-----------------------------
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int i,f[31];
f[0] = 0;
f[1] = 1;
for(i = 2; i <= 30; i++) f[i] = f[i-2] + f[i-1];
for(i = 0; i <= 30; i++) cout << setw(2) << i << setw(10) << f[i] << endl;
return 0;
}
|
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe