
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0
©2010 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
|
Autor artykułu: mgr Jerzy Wałaszek, wersja1.0 |
©2010 mgr
Jerzy Wałaszek
|
Drzewo binarne jest hierarchiczną
strukturą danych, której elementy będziemy nazywali węzłami
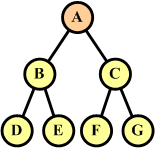
Węzły są połączone krawędziami symbolizującymi następstwo kolejnych elementów w strukturze drzewa binarnego. Według rysunku po prawej stronie węzeł A posiada dwa węzły potomne: B i C. Węzeł B nosi nazwę lewego potomka (ang. left child node), a węzeł C nosi nazwę prawego potomka (ang. right child node).
Z kolei węzeł B posiada węzły potomne
D i E, a węzeł C
ma węzły potomne F i G. Jeśli dany
węzeł nie posiada dalszych węzłów potomnych, to jest w strukturze drzewa
binarnego
węzłem terminalnym. Taki węzeł nosi nazwę
liścia
Rodzicem, przodkiem (ang. parent node) lub węzłem nadrzędnym będziemy nazywać węzeł leżący na wyższym poziomie hierarchii drzewa binarnego. Dla węzłów B I C węzłem nadrzędnym jest węzeł A. Podobnie dla węzłów D i E węzłem nadrzędnym będzie węzeł B, a dla F i G będzie to węzeł C.
Węzeł nie posiadający rodzica nazywamy korzeniem
drzewa binarnego
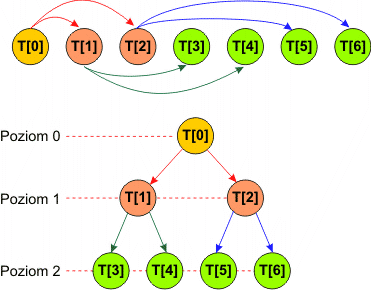
Jeśli chcemy przetwarzać za pomocą komputera struktury drzew binarnych, to musimy zastanowić się nad sposobem reprezentacji takich struktur w pamięci. Najprostszym rozwiązaniem jest zastosowanie zwykłej tablicy n elementowej. Każdy element tej tablicy będzie reprezentował jeden węzeł drzewa binarnego. Pozostaje nam jedynie określenie związku pomiędzy indeksami elementów w tablicy a położeniem tych elementów w strukturze drzewa binarnego.
Zastosujmy następujące odwzorowanie:
Dla węzła k-tego wyprowadzamy następujące wzory:
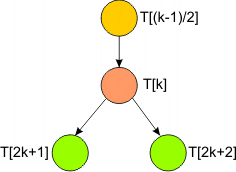 |
węzeł nadrzędny ma indeks równy (k - 1) / 2
(dzielenie całkowitoliczbowe)
k - węzeł bieżący
|
Sprawdź, iż podane wzory są również spełnione w drzewach binarnych o większych rozmiarach niż prezentuje nasz przykład (pomocna może być kartka papieru).
Binarne drzewo jest zrównoważone i uporządkowane, jeśli na wszystkich poziomach za wyjątkiem ostatniego posiada maksymalną liczbę węzłów, a na poziomie ostatnim węzły są ułożone kolejno od lewej strony. Innymi słowy, jeśli ostatni węzeł drzewa binarnego posiada numer i-ty, to drzewo zawiera wszystkie węzły od numeru 0 do i.
Warunek ten gwarantuje nam, iż każdy element tablicy będzie reprezentował pewien węzeł w drzewie binarnym - czyli w tej strukturze nie wystąpią dziury.
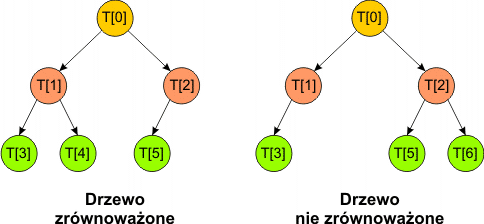
Drzewo po lewej stronie nie posiada węzła
Drzewo po prawej stronie nie posiada węzła
W uporządkowanych i zrównoważonych drzewach binarnych bardzo
prosto można sprawdzić, czy
Kopiec jest drzewem binarnym, w którym wszystkie węzły spełniają następujący warunek (zwany warunkiem kopca):
Węzeł nadrzędny jest większy lub równy węzłom potomnym (w porządku malejącym relacja jest odwrotna - mniejszy lub równy).
Konstrukcja kopca jest nieco bardziej skomplikowana od konstrukcji drzewa binarnego, ponieważ musimy dodatkowo troszczyć się o zachowanie warunku kopca.
Przykład:
Skonstruować kopiec z elementów zbioru
| Operacja | Opis |
|---|---|
|
7 5 9 6 7 8 10 |
Budowę kopca rozpoczynamy od pierwszego elementu zbioru, który staje się korzeniem. |
 7 5 9 6 7 8 10 |
Do korzenia dołączamy następny element. Warunek kopca jest zachowany. |
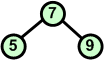 7 5 9 6 7 8 10 |
Dodajemy kolejny element ze zbioru. |
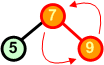 |
Po dodaniu elementu 9 warunek kopca przestaje być spełniony. Musimy go przywrócić. W tym celu za nowy węzeł nadrzędny wybieramy nowo dodany węzeł. Poprzedni węzeł nadrzędny wędruje w miejsce węzła dodanego - zamieniamy węzły 7 i 9 miejscami. |
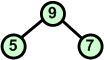 |
Po wymianie węzłów 7 i 9 warunek kopca jest spełniony. |
 7 5 9 6 7 8 10 |
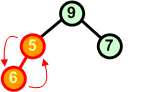
Dołączamy kolejny element 6. Znów warunek kopca przestaje być spełniony - zamieniamy miejscami węzły 5 i 6. |
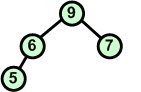 |
Po wymianie węzłów 5 i 6 warunek kopca jest spełniony. |
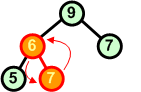 7 5 9 6 7 8 10 |
Dołączamy kolejny element 7. Warunek kopca przestaje obowiązywać. Zamieniamy miejscami węzły 6 i 7. |
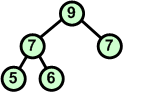 |
Po wymianie węzłów 6 i 7 warunek kopca obowiązuje. |
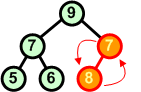 7 5 9 6 7 8 10 |
Dołączamy kolejny węzeł. Powoduje on naruszenie warunku kopca, zatem wymieniamy ze sobą węzły 7 i 8. |
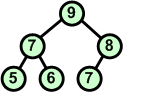 |
Po wymianie węzłów 7 i 8 warunek kopca znów obowiązuje. |
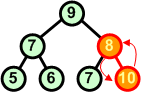 7 5 9 6 7 8 10 |
Dołączenie ostatniego elementu znów narusza warunek kopca. Zamieniamy miejscami węzeł 8 z węzłem 10. |
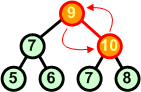 |
Po wymianie węzłów 8 i 10 warunek kopca został przywrócony na tym poziomie. Jednakże węzeł 10 stał się dzieckiem węzła 9. Na wyższym poziomie drzewa warunek kopca jest naruszony. Aby go przywrócić znów wymieniamy miejscami węzły, tym razem węzeł 9 z węzłem 10. |
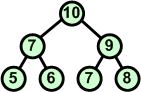 |
Po wymianie tych węzłów warunek kopca obowiązuje w całym drzewie - zadanie jest wykonane. |
Charakterystyczną cechą kopca jest to, iż korzeń zawsze jest największym (w porządku malejącym najmniejszym) elementem z całego drzewa binarnego.
Poniżej przedstawiamy algorytm konstrukcji kopca z elementów zbioru.
Dane wejściowe
| T[ ] | - Tablica zawierająca elementy do wstawienia do kopca. Numeracja elementów rozpoczyna się od 0. |
| n | - Ilość elementów w zbiorze, n
|
Dane wyjściowe
| T[ ] | - Tablica zawierająca kopiec |
Zmienne pomocnicze
| i | - zmienna licznikowa pętli umieszczającej kolejne elementy zbioru w
kopcu,
i
|
| j,k | - indeksy elementów leżących na ścieżce od wstawianego
elementu do korzenia, j,k |
| x | - zmienna pomocnicza przechowująca tymczasowo element wstawiany do kopca |
Lista kroków
| Krok 1: | i ← 1 | ; rozpoczynamy od potomka korzenia |
| Krok 2: | Jeśli i ≥ n, to zakończ | |
| Krok 3: | x ← T[i] | ; zapamiętujemy wstawiany element |
| Krok 4: | k ← i | ; warunek wstępny dla pętli |
| Krok 5: | j ← k | ; j - bieżący element |
| Krok 6: | k ← (j - 1) / 2 | ; k - element nadrzędny |
| Krok 7: | Jeśli j = 0 lub T[k] ≥ x, to idź do kroku 10 | ; kończymy, jeśli jesteśmy w korzeniu lub warunek kopca już spełniony |
| Krok 8: | T[j] ← T[k] | ; przenosimy element nadrzędny do bieżącego |
| Krok 9: | Idź do kroku 5 | ; przechodzimy na wyższy poziom kopca |
| Krok 10: | T[j] ← x | ; wstawiamy element do kopca |
| Krok 11: | i ← i + 1 | |
| Krok 12: | Idź do kroku 2 |
Przykładowe dane dla programu
Poniższy program tworzy kopiec i wyświetla jego zawartość w postaci liniowej. Dane dla programu są w znanej nam postaci: liczba elementów, elementy:
15
7 9 13 21 13 8 16 31 18 11 22 45 29 41 62
// Tworzenie kopca
// (C)2011 ILO w Tarnowie
// KOŁO INFORMATYCZNE
//-----------------------
#include <iostream>
using namespace std;
int main()
{
int * T, n, i, j, k, x;
// odczytujemy liczbę elementów tablicy
cin >> n;
// tworzymy tablicę dynamicznie
T = new int[n];
// odczytujemy elementy tablicy
for(i = 0; i < n; i++) cin >> T[i];
// konstruujemy kopiec
for(i = 1; i < n; i++)
{
x = T[i];
k = i;
while(true)
{
j = k;
k = (j - 1) / 2;
if((j == 0) || (T[k] >= x)) break;
T[j] = T[k];
}
T[j] = x;
}
// wyświetlamy wynik
for(i = 0; i < n; i++) cout << T[i] << " ";
cout << endl << endl;
// zwalniamy pamięć
delete [] T;
return 0;
}
|
Zasada jest następująca:
Przykład:
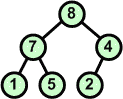
Dokonaj rozbioru następującego kopca:
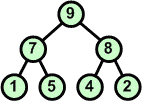
| Operacja | Opis | ||
|---|---|---|---|
 9 |
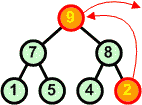
Rozbiór kopca rozpoczynamy od korzenia, który usuwamy ze struktury kopca. W miejsce korzenia wstawiamy ostatni liść. | ||
 |
 |
 |
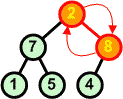
Poprzednia operacja zaburzyła strukturę kopca. Idziemy zatem od korzenia w dół struktury przywracając warunek kopca - przodek większy lub równy od swoich potomków. Praktycznie polega to na zamianie przodka z największym potomkiem. Operację kontynuujemy dotąd, aż natrafimy na węzły spełniające warunek kopca. |
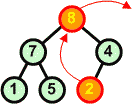 8 9 |
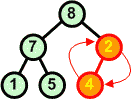
Usuwamy z kopca kolejny korzeń zastępując go ostatnim liściem | ||
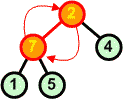 |
 |
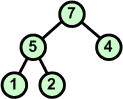 |
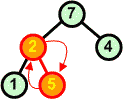
W nowym kopcu przywracamy warunek kopca. |
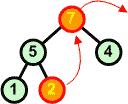 7 8 9 |
Usuwamy z kopca kolejny korzeń zastępując go ostatnim liściem | ||
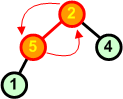 |
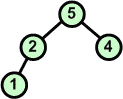 |
W nowym kopcu przywracamy warunek kopca. W tym przypadku już po pierwszej wymianie węzłów warunek koca jest zachowany w całej strukturze. |
|
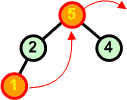 5 7 8 9 |
Usuwamy z kopca kolejny korzeń zastępując go ostatnim liściem | ||
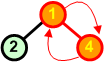 |
 |
Przywracamy warunek kopca w strukturze. |
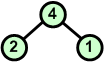
|
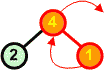 4 5 7 8 9 |
Usuwamy z kopca kolejny korzeń zastępując go ostatnim liściem | ||
 |
 |
Przywracamy warunek kopca w strukturze. |
|
 2 4 5 7 8 9 |
Usuwamy z kopca kolejny korzeń zastępując go ostatnim liściem. | ||
|
1 2 4 5 7 8 9 |
Po wykonaniu poprzedniej operacji usunięcia w kopcu pozostał tylko jeden element - usuwamy go. Zwróć uwagę, iż usunięte z kopca elementy tworzą ciąg uporządkowany. | ||
Operację rozbioru kopca można przeprowadzić w miejscu. Jeśli mamy
zbiór
Dane wejściowe
| T[ ] | - Tablica zawierająca poprawną strukturę kopca. Elementy są numerowane począwszy od 0. |
| n | - Ilość elementów w zbiorze, n
|
Dane wyjściowe
| T[ ] | - Tablica zawierająca elementy pobrane z kopca ułożone w porządku rosnącym |
Zmienne pomocnicze
| i | - zmienna licznikowa pętli pobierającej kolejne elementy z kopca,
i
|
| j,k | - indeksy elementów leżących na ścieżce w dół od korzenia, j,k
|
| m | - indeks większego z dwóch elementów potomnych, m
|
Lista kroków
| Krok 1: | i ← n - 1 | ; rozbiór rozpoczynamy od ostatniego elementu |
| Krok 2: | Jeśli i < 1, to zakończ | ; idziemy w dół kopca aż do korzenia |
| Krok 3: | Wymień T[0] z T[i] | ; zamieniamy korzeń z ostatnim elementem |
| Krok 4: | j ← 0; k ← 1 | ; przywracamy warunek kopca idąc w dół |
| Krok 5: | Jeśli k ≥ i, to idź do kroku 11 | |
| Krok 6: | Jeśli (k + 1 < i) i (T[k
+ 1] > T[k]), to m ← k +
1 inaczej m ← k |
; Ustalamy indeks większego z potomków |
| Krok 7: | Jeśli T[m] ≤ T[j], to idź do kroku 11 | ; jeśli warunek kopca jest zachowany, to wychodzimy z petli |
| Krok 8: | Wymień T[j] z T[m] | ; inaczej wymieniamy rodzica z potomkiem |
| Krok 9: | j ← m; k ← 2j + 1 | ; przechodzimy na niższy poziom w kopcu |
| Krok 10: | Idź do kroku 5 | |
| Krok 11: | i ← i - 1 | |
| Krok 12: | Idź do kroku 2 |
Przykładowe dane dla programu
Poniższy program rozbiera kopiec i wyświetla wynik tego rozbioru. Dane dla programu są w znanej nam postaci: liczba elementów, elementy:
15
62 22 45 18 21 29 41 7 13 11 13 8 16 9 31
// Rozbiór kopca
// (C)2011 ILO w Tarnowie
// KOŁO INFORMATYCZNE
//-----------------------
#include <iostream>
using namespace std;
int main()
{
int * T, n, i, j, k, x, m;
// odczytujemy liczbę elementów tablicy
cin >> n;
// tworzymy tablicę dynamicznie
T = new int[n];
// odczytujemy elementy tablicy
for(i = 0; i < n; i++) cin >> T[i];
// rozbieramy kopiec
for(i = n - 1; i > 0; i--)
{
x = T[0]; T[0] = T[i]; T[i] = x;
j = 0; k = 1;
while(k < i)
{
if((k + 1 < i) && (T[k + 1] > T[k])) m = k + 1;
else m = k;
if(T[m] <= T[j]) break;
x = T[j]; T[j] = T[m]; T[m] = x;
j = m; k = j + j + 1;
}
}
// wyświetlamy wynik
for(i = 0; i < n; i++) cout << T[i] << " ";
cout << endl << endl;
// zwalniamy pamięć
delete [] T;
return 0;
}
|
Zwróć uwagę, że wynikiem jest posortowany zbiór. Nic w tym dziwnego - rozbiór kopca zawsze rozpoczyna się od korzenia. Korzeń w kopcu zawiera największy element. Zatem tablica jest wypełniana od końca w dół coraz mniejszymi elementami w miarę jak kopiec staje się coraz mniejszy.
Na podstawie tych dwóch algorytmów ułóż algorytm sortowania przez kopcowanie.
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe