
Autor artykułu: mgr Jerzy Wałaszek, wersja 1.0
©2008 mgr
Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Autor artykułu: mgr Jerzy Wałaszek, wersja 1.0 |
©2008 mgr
Jerzy Wałaszek
|
Zapoznaj się z artykułem o binarnym kodowaniu liczb
W języku C++ mamy następujące 3 typy zmiennoprzecinkowe:
| float | 32 bity Pojedyncza precyzja - 7-8 cyfr znaczących Zakres ±3,4 × 1038 |
| double | 64 bity Podwójna precyzja - 16-16 cyfr znaczących Zakres ±1,8 × 10308 |
| long double | 80 bitów Rozszerzona precyzja - 19-20 cyfr znaczących Zakres ±1,1 × 104932 |
Zakres typów zmiennoprzecinkowych jest zwykle dosyć duży, zatem bardziej interesującym nas parametrem będzie precyzja. Z poprzedniej lekcji pamiętamy (czy aby na pewno?), iż liczby zmiennoprzecinkowe są liczbami przybliżonymi. Precyzja danego kodu FP określa, jak dokładnie jest pamiętana liczba. Na przykład dla typu float liczba może posiadać tylko około 8 cyfr znaczących. Oznacza to, iż pierwsze 7-8 cyfr liczby zostanie zapamiętane dokładnie, lecz pozostałe nie:
1234567890 → 1234567???float
Typ float wymyślono w czasach oszczędności pamięci - komputery nie posiadały jej wiele i była ona strasznie droga. Dzisiaj to się zmieniło. Pamięć kupujemy za grosze i jest ona liczona w gigabajtach. Z tego powodu nie ma sensu stosowanie typu float. Umówmy się, iż w znaczeniu typ zmiennoprzecinkowy będziemy zawsze rozumieli typ double, który pozwala zapamiętywać liczby z precyzją 15 cyfr.
Historia typu long double jest trochę inna. We wczesnych czasach powszechnej komputeryzacji mikroprocesory potrafiły wykonywać działania tylko na liczbach całkowitych. Operacje zmiennoprzecinkowe realizowano programowo, tzn. za pomocą specjalnie napisanych programów, które potrafiły wykonywać działania arytmetyczne na liczbach FP przy wykorzystaniu dostępnych operacji całkowitoliczbowych. Sposób ten był bardzo wolny. Dlatego bardzo szybko opracowano specjalizowane układy, które realizowały operacje FP sprzętowo, czyli szybko. Układy te nazywano koprocesorami arytmetycznymi, ponieważ współpracowały ściśle z podstawowym procesorem w komputerze, niejako uzupełniając jego listę rozkazów o operacje na danych FP.
W następnym etapie rozwoju koprocesor arytmetyczny został zintegrowany z mikroprocesorem w jednym układzie scalonym - stało się tak już od modelu i486, poprzednika współczesnego Pentium. Wewnętrznie koprocesor arytmetyczny przechowuje liczby FP w postaci kodu 80-bitowego. Typ long double to właśnie wewnętrzna reprezentacja liczb FP w koprocesorze arytmetycznym. Powodem takiego rozwiązania jest minimalizacja błędów zaokrągleń, które powstają w trakcie obliczeń. Wyniki są przekształcane na typy double lub float i są dokładniejsze, niż byłyby przy obliczeniach przeprowadzanych bezpośrednio w tych formatach.
Jednakże typ long double jest specyficzny dla procesorów Intel i nie jest dostępny na innych komputerach - VAX, CRAY itp. Dlatego pisząc oprogramowanie przenośne, nie używaj niestandardowych typów danych.
Jeśli w programie chcemy używać zmiennych przechowujących liczby FP, to musimy je najpierw zadeklarować, jak wszystkie inne zmienne w programie.
Przykłady:
float
a,b,c; // trzy zmienne a, b i c pojedynczej
precyzji
double x,y; // dwie zmienne x i y podwójnej
precyzji
long double z;
// zmienna z o rozszerzonej precyzji
Gdy zmienna jest zadeklarowana możemy nadawać jej wartość instrukcją przypisania. W przeciwieństwie do zmiennych całkowitych, zmienne FP mogą przechowywać liczby ułamkowe:
Przykłady:
x = 15.765;
y = 165.44;
Zmienne FP można stosować w wyrażeniach:
Przykłady:
x = 12.67 *
y;
x = sqrt(x);
|
UWAGA: Operator dzielenia posiada w języku C++ dwie funkcje:
Należy na to zwrócić baczną uwagę, ponieważ może prowadzić do trudnych w wykryciu błędów rachunkowych. |
Rozważmy prosty program:
#include <iostream> using namespace std; main() { double x; x = 0; while(x != 1) { x += 0.1; cout << x << endl; } cout << endl << endl; system("PAUSE"); } |
W programie jest pętla, która wykonuje się dopóki x jest różne od 1. Przed wejściem do pętli zmiennej x nadajemy wartość 0. W pętli x zwiększamy o 1/10 i wyświetlamy . Zatem w każdym kolejnym obiegu x jest większe. Wnioskujemy tak:
obieg nr 1: x : 0 → 0.1
obieg nr 2: x: 0.1 → 0.2
obieg nr 3: x: 0.2 → 0.3
...
obieg nr 9: x: 0.8 → 0.9
obieg nr 10: x: 0.9 → 1.0 - koniec obiegów, ponieważ warunek
kontynuacji pętli x != 1 staje się fałszywy
Uruchamiamy program i co się okazuje. Pętla, zamiast zatrzymać się w obiegu 10 na wartości x = 1, idzie dalej w nieskończoność. Dlaczego tak się dzieje? Przypomnij sobie poprzednią elekcję. Wyliczaliśmy na niej wartość ułamka dziesiętnego 1/10 w systemie dwójkowym:
0.1(10) = 0.000110011001100...
Otrzymujemy nieskończony ułamek okresowy. Tymczasem mantysa w typie zmiennoprzecinkowym double zawiera skończoną liczbę bitów. Oznacza to, iż ułamka 0.1 nie da się dokładnie zapamiętać, tylko z pewnym przybliżeniem. Zatem do x faktycznie dodajemy nie 1/10, ale przybliżenie 1/10. W wyniku po 10 dodawaniach nie otrzymamy dokładnie wartości 1, tylko wartość bliską 1. Różnica jest bardzo mała, ale jest! Dla komputera x oraz 1 to zupełnie inne liczby, ponieważ ich kody FP są różne! Stąd warunek kontynuacji pętli x != 1 jest zawsze prawdziwy, bo x nigdy nie będzie równe 1. Pętla kontynuuje się w nieskończoność.
Tego rodzaju błędy pojawiają się bardzo często w programach pisanych przez początkujących programistów, którzy nie mają zielonego pojęcia o podstawowych własnościach liczb zmiennoprzecinkowych i wynikających z tych własności konsekwencjach. Dlatego w naszym liceum nauka programowania z wykorzystaniem liczb zmiennoprzecinkowych jest poprzedzona wprowadzeniem do tego typu danych.
|
UWAGA: Liczb zmiennoprzecinkowych NIE WOLNO do siebie przyrównywać. Powód jest bardzo prosty. Skoro liczby FP są liczbami przybliżonymi, to wszelkie rachunki z ich wykorzystaniem obarczone są pewnym małym błędem wynikającym z precyzji zapisu zmiennoprzecinkowego. Przyrównywanie wyniku obliczeń do innej wartości FP może dać niewłaściwy efekt, ponieważ obie wartości mogą się od siebie różnić - chociaż z matematycznego punktu widzenia powinny być równe. |
Problem rozwiązujemy stosując otoczenia. Wyobraźmy sobie, iż chcemy sprawdzić, czy pewna wartość zmiennoprzecinkowa WFP jest równa wartości dokładnej WD. Zamiast porównywać te dwie wartości ze sobą, sprawdzimy, czy na osi liczbowej leżą wystarczająco blisko siebie. Pojęcie "wystarczająco blisko" określa dokładność porównania.
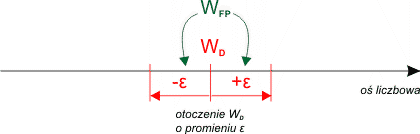
Otoczmy punkt WD promieniem ε. Powiemy, że wartość WFP wpada w otoczenie o promieniu ε liczby WD, jeśli liczby te różnią się od siebie nie więcej niż ε. Zapisujemy to następująco:
| WD - WFP | ≤ ε
WD - wartość dokładna
WFP - zmiennoprzecinkowa wartość przybliżona
ε - akceptowalne przybliżenie, czyli otoczenie wartości WD, w którym
wszystkie wartości traktujemy jako równe WD.
Wartość otoczenia ε przyjmuje się zwykle bardzo małą, np. 0.000001. Jednakże nie jest to wcale takie proste, jak wygląda na pierwszy rzut oka. W profesjonalnych programach informatycy szacują wartość błędów obliczeniowych (na studiach informatycznych jest taki dział w ramach metod numerycznych) i na tej podstawie dobierają właściwą wartość ε. Ponieważ wymaga to zwykle znajomości matematyki na poziomie znacznie przewyższającym możliwości pojmowania ucznia w liceum, my będziemy przyjmowali za ε wartości empiryczne.
Wniosek:
Zamiast WFP == WD stosujemy w C++ fabs(WD - WFP) <= EPS
Zamiast WFP != WD stosujemy w C++ fabs(WD - WFP) > EPS
fabs(x) jest funkcją zwracającą wartość bezwzględną ze zmiennoprzecinkowego wyrażenia x. Aby mieć do niej dostęp, w programach musimy dołączyć plik nagłówkowy:
#include <cmath>
Program z początku rozdziału zmieniamy następująco:
#include <iostream> #include <cmath> using namespace std; main() { const double EPS = 0.000001; // otoczenie epsilon double x; x = 0; while(fabs(1 - x) > EPS ) { x += 0.1; cout << x << endl; } cout << endl << endl; system("PAUSE"); } |
Liczby zmiennoprzecinkowe są standardowo wyświetlane w strumieniu konsoli cout z dokładnością do 6 cyfr po przecinku.
double x = 3.12345678;
cout << x << endl;
Wynik:
3.123456
Jeśli wartość liczby zwiększy się (lub zmniejszy), to strumień cout zacznie stosować notację naukową:
double x = 312345678;
cout << x << endl;
Wynik:
3.12346e+008
double x = 0.00000312345678;
cout << x << endl;
Wynik:
3.12346e-006
Zapis naukowy jest niczym innym jak zmiennoprzecinkowym zapisem w systemie dziesiętnym. W zapisie tym podaje się wartość dziesiętną mantysy oraz wartość dziesiętną cechy:
3.123456e+008
mantysa m = 3.123456
cecha c = 8
W = m × 10c = 3.123456 × 108
3.123456e-006
mantysa m = 3.123456
cecha c = -6
W = m × 10c = 3.123456 × 10-6
Zachowaniem się strumienia cout możemy sterować stosując tzw. manipulatory, czyli funkcje przesyłane do strumienia. Aby uzyskać dostęp do manipulatorów strumieni, w programie należy dołączyć nowy plik nagłówkowy:
#include <iomanip>
Po tej operacji możemy przesyłać do strumienia następujące manipulatory:
| Manipulator | Znaczenie |
| setprecision(n) | Liczby ułamkowe będą wyświetlane z n cyframi po przecinku. Przykład:
Wynik:
|
| fixed | Ustala standardowy sposób wyświetlania liczb. Stosuje się razem z setprecision(). |
| scientific | Liczby będą wyświetlane zawsze w notacji naukowej. W tym przypadku
setprecision() ustawia liczbę cyfr ułamkowych mantysy. Przykład:
Wynik:
|
| setw(n) | Następny element (dowolny, nie tylko liczba)
wysłany do strumienia cout będzie wyświetlony w polu o szerokości n znaków.
Standardowo elementy są dosuwane do prawej krawędzi pola. Przykład:
Wynik:
|
| left | Ustala lewostronne wyrównanie dla elementów wyświetlanych po manipulatorze setw(). |
| right | Przywraca prawostronne wyrównanie elementów wyświetlanych po setw() |
| setfill(c) | Ustawia znak c wypełnienia pola po setw(). Standardowo jest to spacja,
lecz manipulatorem setfill() możemy ustawić wypełnianie pola dowolnym
znakiem. Przykład:
Wynik:
|
 | I Liceum Ogólnokształcące |
Pytania proszę przesyłać na adres email: i-lo@eduinf.waw.pl
W artykułach serwisu są używane cookies. Jeśli nie chcesz ich otrzymywać,
zablokuj je w swojej przeglądarce.
Informacje dodatkowe