w I-LO w Tarnowie
Materiały dla uczniów liceum
Wyjście Spis treści Wstecz Dalej

Autor artykułu: mgr Jerzy
Wałaszek
Konsultacje: Wojciech Grodowski, mgr inż. Janusz Wałaszek
©2024 mgr Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy
Wałaszek |
©2024 mgr Jerzy Wałaszek
|
Za rok narodzin współczesnej elektroniki możemy przyjąć rok 1874, kiedy niemiecki fizyk, laureat Nagrody Nobla, Ferdinand Braun odkrył, że złącza metali z niektórymi kryształami przewodzą prąd tylko w jednym kierunku. Odkrycie to pozwoliło później stworzyć przyrządy półprzewodnikowe, które dzisiaj spotykamy w urządzeniach elektronicznych.
Następnym "wielkim wynalazkiem" była lampa elektronowa, tzw. dioda próżniowa, którą w roku 1904 skonstruował angielski fizyk John Fleming. Zasada działania diody próżniowej jest następująca:

Pierwsza dioda próżniowa
Jeśli jednak zamienimy biegunowość napięcia, to elektrony będą przyciągane przez katodę i odpychane przez anodę. Anoda sama nie wytwarza elektronów. Katoda przechwytuje wyrzucone przez siebie elektrony. Prąd przestanie płynąć pomiędzy elektrodami.
W efekcie otrzymamy przyrząd elektronowy, który pełni rolę jakby "zaworu": przepuszcza prąd tylko w jednym kierunku.
Tego typu lampy znalazły duże zastosowanie w radioodbiornikach.
Kolejny krok zrobił amerykański wynalazca, Lee de Forest, który umieścił w diodzie próżniowej dodatkową elektrodę pomiędzy katodą a anodą. Elektroda ta miała postać siatki i tak też została nazwana. Powstała trioda próżniowa. Otóż okazało się, że przykładając napięcie elektryczne do siatki można wpływać na prąd, który przepływa pomiędzy katodą i anodą. Co więcej, małe zmiany napięcia na siatce wywoływały duże zmiany prądu katodowego. Powstał przyrząd elektronowy, który potrafił wzmacniać sygnały elektryczne. Trioda próżniowa otworzyła drogę dla całej epoki lamp elektronowych. Dzięki nim budowano radioodbiorniki, telewizory, radary oraz pierwsze komputery, np. ENIAC posiadał 18 tysięcy lamp elektronowych. Nawet dzisiaj lampy elektronowe są wciąż jeszcze stosowane w niektórych urządzeniach, np. we wzmacniaczach akustycznych najwyższej klasy.

Wnętrze starego telewizora lampowego
Lampy elektronowe, pomimo swoich niewątpliwych zalet, posiadają wiele wad. Wykonywane były z baniek szklanych, zatem należało się z nimi ostrożnie obchodzić, ponieważ były bardzo podatne na uszkodzenia mechaniczne. Działanie lampy opiera się na emisji cieplnej elektronów, zatem katoda musiała być ciągle podgrzewana. Wymagało to stosowania w urządzeniach elektronicznych dodatkowych obwodów żarzenia lamp. Efektem ubocznym był wzrost temperatury w urządzeniu oraz straty energii na podgrzewanie katod. Lampy elektronowe opierały się znacznej miniaturyzacji, w efekcie urządzenia były dosyć duże. Dzisiejszy telefon komórkowy w epoce lamp miałby wielkość bloku mieszkalnego i na pewno nie dałoby się go zmieścić w kieszeni. Żywotność lamp również była ograniczona – po paru latach użytkowania katody ulegały degeneracji i przestawały sprawnie emitować elektrony. W rezultacie lampa przestawała działać i należało ją wymienić na nową. Urządzenie lampowe po włączeniu zasilania potrzebowało pewnego czasu, zanim zaczynało działać. W tym czasie lampy musiały osiągnąć odpowiednią temperaturę katod, aby wystąpiła termoemisja elektronów.

Eksperymentalny tranzystor z roku 1947
W roku 1947 zespół naukowców z Laboratorium Bella, John Bardeen, William Shockley i Walter Brattain, wykonał pierwszy element półprzewodnikowy, zwany tranzystorem. Rozpoczęła się nowa era w elektronice: półprzewodniki. Półprzewodnik jest ciałem stałym, które wykazuje pewne unikalne własności elektryczne (omawiamy je dalej w tym rozdziale). Jego działanie opiera się na procesach kwantowych w skali atomowej. Tranzystor jest odpowiednikiem triody próżniowej. Jednak zasada jego działania jest zupełnie inna. Tranzystory nie posiadają katod termoemisyjnych, nie muszą zatem mieć obwodów żarzenia. Są dużo mniejsze od lamp i łatwo poddają się miniaturyzacji (np. współczesne tranzystory są już tak małe, że można je zobaczyć jedynie pod mikroskopem). Początkowo tranzystory ustępowały parametrami lampom próżniowym, lecz szybko nadrobiły tę lukę i zaczęły wypierać lampy z urządzeń elektronicznych. Dzięki tranzystorom, urządzenia stały się mniejsze, pobierały mniej energii i były bardziej niezawodne.

Pierwszy odbiornik radiowy na tranzystorach
(1954 rok)
W roku 1958 w firmie Texas Instruments amerykański inżynier Jack Kilby wpadł na pomysł, aby w jednej obudowie umieścić kilka tranzystorów, które są ze sobą połączone w układ spełniający określoną funkcję. W ten sposób narodził się pierwszy układ scalony.

Układ scalony skonstruowany przez Jacka Kilby'ego
(rok 1958)
Układy scalone zawierały w swoim wnętrzu coraz więcej tranzystorów – dzisiaj liczba ta przekroczyła dziesiątki milionów. Układy scalone spowodowały miniaturyzację urządzeń elektronicznych. To dzięki nim twój telefon komórkowy mieści się w kieszeni, inaczej musiałbyś go wozić za sobą ciężarówką.

Współczesny układ scalony
W świecie makroskopowym mamy do czynienia z wielkościami analogowymi, czyli takimi, które mogą się płynnie zmieniać w założonych granicach. Na przykład, jeśli w pewnym obwodzie płynie prąd o natężeniu 1A, to nie istnieje żadne prawo elektryczności, które zabraniałoby płynięcia w tym obwodzie prądu o natężeniu 1,01A (wystarczy odrobinę zmienić parametry elementów tworzących ten obwód lub napięcie zasilające).
Tymczasem w świecie subatomowym (tj. na poziomie atomowym i niżej) okazało się, że energia nie może być emitowana lub zmieniana w dowolnym zakresie, lecz musi koniecznie przyjmować ściśle określone wartości, które nazywamy kwantami. Dlaczego nie widzimy tych kwantów. Są po prostu dla nas bardzo małe. Wyobraź sobie, że masz zbiornik z wodą. Woda może z tego zbiornika wypływać rurką. W rurce masz zainstalowany licznik przepływu wody i regulator. Dopóki ilości wypływającej wody są nieporównywalnie większe od wielkości pojedynczej cząsteczki wody, będziesz mógł pobierać wodę ze zbiornika w sposób analogowy, np. 3 litry, 3,01 litra, itd. Co się jednak stanie, gdy rurka stanie się tak cienka, że w końcu będą mogły przez nią przepływać pojedyncze cząsteczki wody. Teraz już pobieranie wody ze zbiornika przestanie być analogowe, ponieważ cząsteczki wody tworzą zbiór niepodzielnych elementów (tzn. jeśli je rozdzielisz na atomy wodoru i tlenu, z których się składają, to przestaniesz mieć wodę). Możemy ze zbiornika pobrać 1 cząsteczkę, 2 cząsteczki, itd. Nie możesz jednak pobrać 3,01 cząsteczki. Woda staje się skwantowana. Można ją pobierać ze zbiornika tylko w ściśle określonych porcjach, które są wielokrotnościami liczby cząsteczek wody. W świecie makroskopowym też tak było, tylko z uwagi na rozmiary tych cząsteczek różnica pomiędzy 3 litrami wody a 3,01 litra wody w odniesieniu do liczby cząsteczek wody jest bardzo duża, dlatego wydaje się nam, że jest to wielkość ciągła.
Podobnie dzieje się z energią. Na poziomie atomowym energia nie może być przekazywana w sposób ciągły, lecz w paczkach, kwantach energii. Konsekwencje tego faktu są ogromne. Dzięki nim istnieje cały nasz wszechświat. Przykładem jest budowa atomu.
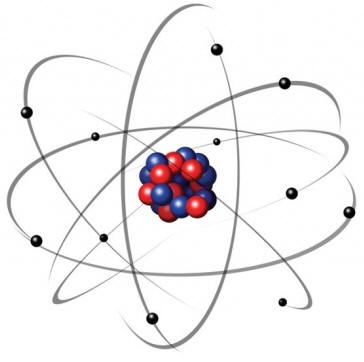
Zwykle atom przedstawiany jest jako jądro zbudowane z protonów (cząstka o ładunku dodatnim) i neutronów (cząstka bez ładunku) oraz z krążących wokół niego elektronów. Jeśli rozważymy ten model z punktu widzenia fizyki klasycznej, to dojdziemy do kilku wniosków sprzecznych z rozumowaniem:
Ludzie wyobrażają sobie cząstki subatomowe jako kuleczki, tymczasem mechanika kwantowa mówi nam, że bardziej podobne są do rozmytej chmury. Chmura ta jest określona przez prawdopodobieństwo, że dana cząstka elementarna znajdzie się w danym miejscu przestrzeni. Co więcej, cząstka elementarna może jednocześnie być w kilku miejscach. To już jest dla większości ludzi zupełnie niezrozumiałe. To tak, jakby uczeń jednocześnie odrabiał lekcje w domu, grał z kolegami w piłkę na boisku szkolnym, był z koleżanką w kinie i opalał się na plaży w Hiszpanii. Tymczasem zgadza się to w 100% z wynikami doświadczeń. Świat subatomowy jest światem rozmytym, którym rządzi przypadek. Nie można dokładnie zmierzyć położenia elektronu i jednocześnie określić jego pędu. Jeśli określimy jedno, to drugie się rozmyje i na odwrót. Jest to tzw. zasada nieoznaczoności. Dlatego elektrony w atomie tworzą chmurę prawdopodobieństwa wokół jądra.
Dziwną cechą świata subatomowego jest tzw. efekt tunelowy. Pozwala on przejść cząstce przez barierę, której normalnie nie powinna przejść. To tak, jakbyś podszedł do betonowego muru i nagle znalazł się po drugiej stronie. Doświadczenie pokazuje nam, że w świecie cząstek elementarnych takie zjawiska zachodzą.
Dziwnych zjawisk w świecie subatomowym jest mnóstwo. Niektóre (np. splątanie kwantowe) przeraziły samego Einsteina! Jeśli chcesz wiedzieć więcej na ten temat, a nie bawi cię perspektywa spędzenia wielu lat na nauce matematyki wyższej i mechaniki kwantowej, to proponuję ci lekturę świetnych książek amerykańskiego fizyka prof. Michio Kaku.
Są to materiały, które nie posiadają w swoim wnętrzu wolnych ładunków elektrycznych (elektronów lub jonów) mogących się w nich swobodnie poruszać. Dlatego izolatory nie przewodzą prądu elektrycznego (nie jest to tak do końca prawdą, ponieważ nawet przez najlepszy izolator zawsze jakiś prąd płynie, lecz jest on tak mały, że praktycznie możemy go pominąć). Oporność izolatorów jest bardzo duża (megaomy).
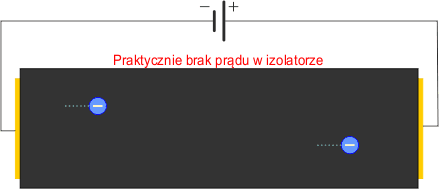
Izolatory nazywamy również dielektrykami. Izolatorami są: powietrze, szkło, drewno, ceramika, tworzywa sztuczne, guma. Gdy napięcie przyłożone do izolatora wzrasta, to w pewnym momencie nastąpi tzw. przebicie, czyli nagły wzrost prądu. Zjawisko to możesz obserwować w naturze podczas burzy. Tarcie w chmurach wywołuje wzrost ładunku. Gdy napięcie pomiędzy chmurą a ziemią przekroczy napięcie przebicia powietrza (około 32 kV na 1 cm – wyobraź sobie jak duże musi być napięcie, skoro niektóre błyskawice mają nawet kilka kilometrów długości!!!), następuje jonizacja gazu i gwałtowny przepływ prądu w postaci błyskawicy. Wyładowanie w izolatorze stałym zwykle niszczy jego strukturę, dlatego zawsze należy dobierać odpowiednią grubość izolatora w zależności od przewidywanego napięcia pracy.
Z izolatorami spotkasz się przy wszelkich przewodach elektrycznych, które są pokryte warstwą izolacji, która zapobiega zwarciom oraz przebiciom.
Są to materiały, które posiadają swobodne ładunki elektryczne. Mogą to być ciała stałe (najczęściej metale), płyny (tzw. elektrolity, w których znajdują się jony dodatnie lub ujemne) lub gazy w postaci zjonizowanej. Oporność przewodników jest bardzo mała.
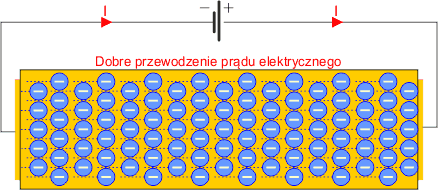
Przewodnikami są wszystkie metale (najlepiej przewodzą srebro i miedź). Spowodowane jest to tym, iż atomy metali, tworząc strukturę krystaliczną (tak, metal jest kryształem), posiadają niewykorzystane elektrony na ostatnich orbitach, tzw. elektrony walencyjne, które łatwo oddzielają się od atomu i mogą się swobodnie poruszać wewnątrz przewodnika. Inne przewodniki to: woda, grafit.
Przy przewodnikach należy wspomnieć o pewnej grupie materiałów, które w niskiej temperaturze wykazują zerową oporność elektryczną. Stan taki nazywamy nadprzewodnictwem, a materiały nadprzewodnikami. Nadprzewodnictwo jest efektem kwantowym i można je wyjaśnić tylko za pomocą praw mechaniki kwantowej. Z nadprzewodnikami zwykle nie będziesz miał do czynienia, ponieważ efekt nadprzewodnictwa pojawia się dopiero w temperaturach bliskich zera bezwzględnego, a te raczej trudno wytworzyć bez specjalistycznej i bardzo drogiej aparatury. Nadprzewodniki posiadają jednak wiele ciekawych własności. Obecnie trwają intensywne poszukiwania tzw. nadprzewodników wysokotemperaturowych, które wykazywałyby nadprzewodnictwo w temperaturze pokojowej. Gdyby takie materiały udało się znaleźć, zrewolunicjowałoby to naszą cywilizację.
Są to materiały, które wykazują cechy zarówno izolatorów jak i przewodników. Atomy półprzewodnika wykorzystują wszystkie elektrony walencyjne do utworzenia siatki krystalicznej. Nie ma zatem swobodnych elektronów. Jednakże w pewnych warunkach może dojść do wybicia elektronu walencyjnego (np. pod wpływem temperatury, która wywołuje drgania atomów w siatce krystalicznej półprzewodnika) i stanie się on swobodnym elektronem, który będzie uczestniczył w przepływie prądu. Jednakże atom półprzewodnika, który utracił elektron walencyjny, staje się jonem dodatnim, czyli otrzymuje ładunek dodatni. Fizycznie jon ten nie może się przemieszczać w półprzewodniku, ponieważ jest uwięziony w siatce kryształu. Jednakże może przechwycić elektron swobodny, który został wybity z innego atomu siatki. Dojdzie do tzw. rekombinacji ładunków. Schwytany elektron zneutralizuje ładunek dodatni atomu. W efekcie ładunek dodatni zmieni położenie w strukturze półprzewodnika – przemieści się do atomu, który poprzednio stracił elektron walencyjny. Efekt będzie taki sam, jakby ten ładunek się swobodnie przemieszczał. Proces ten jest wyjaśniony na poniższych rysunkach:
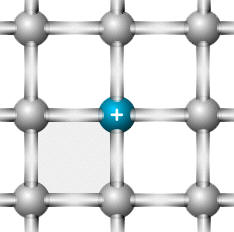 Dziura: atom z brakującym elektronem walencyjnym |
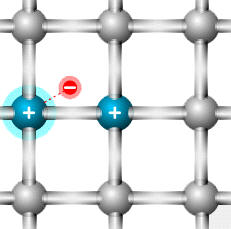 Inny atom traci elektron walencyjny i staje się nową dziurą |
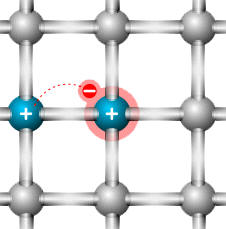 Dziura przechwytuje elektron i staje się normalnym atomem w sieci |
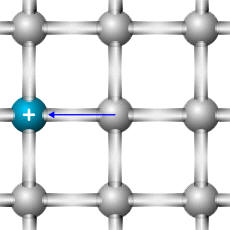 Efekt rekombinacji: dziura "zmieniła" swoje położenie |
W półprzewodniku występują zatem oba rodzaje nośników ładunków: elektrony o ładunku ujemnym i dziury o ładunku dodatnim. Mamy dwa rodzaje prądów: prąd elektronowy płynący od minusa do plusa zasilania oraz prąd dziurowy płynący od plusa do minusa zasilania.
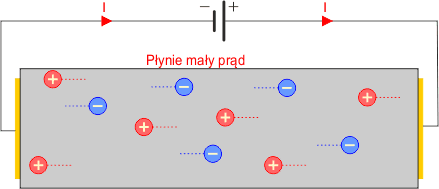
Do półprzewodników należą: krzem, german, arsenek galu.
Przez wstawienie do struktury półprzewodnika obcych atomów o innej wartościowości można uzyskać większą koncentrację elektronów lub dziur. Np. jeśli w siatce krystalicznej czterowartościowego krzemu umieścimy trójwartościowe atomy indu lub glinu, to utworzą one tylko 3 wiązania, pozostawiając jedno nieobsadzone. W miejscu tym powstanie dziura. Półprzewodnik, w którym koncentracja dziur jest większa od koncentracji elektronów, nazywamy półprzewodnikiem typu p.

Jeśli w siatce krystalicznej krzemu umieścimy atom z pięcioma elektronami w powłoce walencyjnej (fosfor, arsen), to powstaną cztery wiązania z krzemem, lecz jeden elektron nie będzie związany. Może się on odłączać od atomu i uczestniczyć w przepływie prądu. Półprzewodnik z przewagą nośników ujemnych nazywamy półprzewodnikiem typu n.

Mamy dwa kryształy półprzewodnika typu n i typu p.
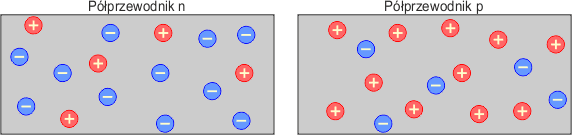
Kryształy łączymy ze sobą. W obszarze styku powstaje różnica w koncentracji nośników większościowych: dla półprzewodnika n są to elektrony, a dla półprzewodnika p są to dziury.
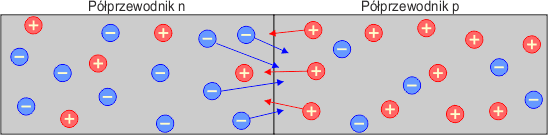
Powoduje to tzw. dyfuzję nośników, czyli przechodzenie, przenikanie nośników z obszaru o ich większej koncentracji do obszaru o koncentracji mniejszej. Zatem elektrony z półprzewodnika n będą dyfundowały do półprzewodnika p, a dziury z półprzewodnika p będą dyfundowały do półprzewodnika n. Po przejściu nośniki będą rekombinowały z nośnikami większościowymi, co spowoduje zmniejszenie ilości tych ostatnich w obszarze złącza, ponieważ każda rekombinacja typu dziura-elektron powoduje neutralizację nośnika ładunku. W efekcie po obu stronach złącza pojawią się obszary o większej koncentracji elektronów w półprzewodniku typu p i dziur w półprzewodniku typu n, czyli odwrotnie niż w pozostałej części tych półprzewodników.
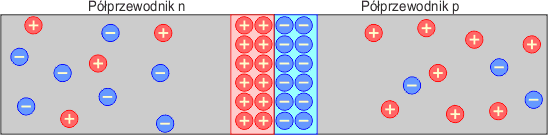
W obszarze styku powstanie tzw. ładunek przestrzenny, który uniemożliwi dalszą dyfuzję nośników większościowych (ładunek dodatni dziur w półprzewodniku typu n zatrzyma dyfuzję tych dziur z półprzewodnika typu p, a ładunek ujemny elektronów w półprzewodniku typu p zatrzyma dyfuzję elektronów z półprzewodnika typu n). W obszarze styku powstaje zatem bariera zwana warstwą zaporową, w której praktycznie nie występują nośniki większościowe dla danego półprzewodnika.
Po krótkiej chwili stan złącza się ustabilizuje. Załóżmy teraz, że do półprzewodnika typu p przyłożymy plus zasilania a do półprzewodnika typu n minus zasilania.
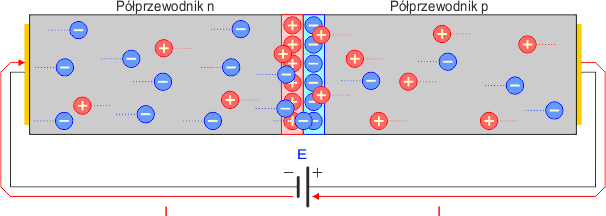
Pod wpływem pola elektrycznego elektrony w półprzewodniku typu n będę się poruszały w kierunku złącza p-n, a w półprzewodniku typu p dziury będą również poruszały się w kierunku złącza. Obszar złącza ulegnie zmniejszeniu (zewnętrzne pole elektryczne ściśnie je). Koncentracja ładunków w obszarze złącza powoduje powstanie w tym miejscu tzw. bariery potencjału. Dla krzemu wynosi ona około 0,6...0,8V, dla germanu około 0,2...0,3V. Jeśli napięcie zewnętrzne przezwycięży tę barierę, to nośniki ładunków przejdą przez nią i zacznie płynąć prąd elektryczny. Złącze zacznie przewodzić prąd elektryczny. Mówimy, że jest spolaryzowane w kierunku przewodzenia.
Odwróćmy teraz biegunowość napięcia zasilającego i do półprzewodnika typu p podłączmy ujemny biegun zasilania a do półprzewodnika typu n dodatni.
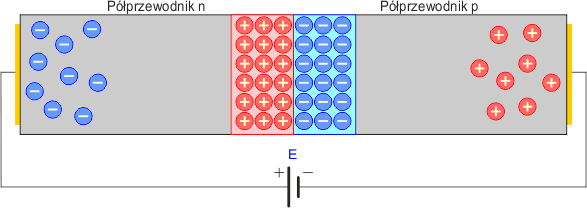
Odwrotny kierunek pola spowoduje, że nośniki większościowe odpłyną od złącza p-n. Bariera potencjału się zwiększy, ponieważ będzie wspomagana przez zewnętrzne pole elektryczne. W efekcie prąd przestanie płynąć (będzie płyną jedynie niewielki prąd zwany prądem wstecznym). Złącze przestanie praktycznie przewodzić prąd elektryczny. Mówimy, że jest spolaryzowane w kierunku zaporowym.
Jeśli będziemy zwiększać napięcie przyłożone do półprzewodników ze spolaryzowanym zaporowo złączem, to nośniki mniejszościowe, które uczestniczą w przepływie prądu wstecznego, zaczną nabierać coraz większej energii. Ich zderzenia z siecią półprzewodnika powodują powstawanie nowych nośników ładunków. W efekcie przy pewnym napięciu wstecznym prąd gwałtownie narasta. Nazywamy to przebiciem lawinowym lub prądem Zenera. Jeśli prąd przebicia lawinowego nie przekroczy maksymalnego prądu złącza, to złącze nie ulegnie zniszczeniu.
Podane tutaj wyjaśnienia działania złącza p-n są jedynie poglądowe. Jeśli chcesz wiedzieć więcej na ten temat, musisz zapoznać się z pasmową teorią przewodnictwa.
Przyjrzyjmy się teraz wykresowi prądu złącza p-n w funkcji napięcia. Na osi poziomej mamy napięcie przyłożone do półprzewodników p i n. Na osi pionowej mamy prąd, który popłynie przez złącze p-n przy danym napięciu:
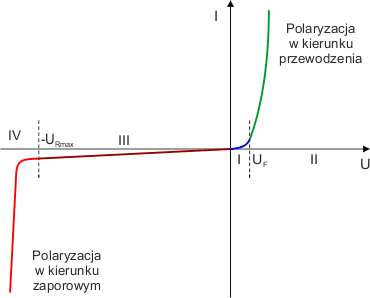
Wykres podzielony jest na cztery części.
Charakterystyka po stronie napięć ujemnych jest zwykle rysowana ze zmianą skali, ponieważ maksymalne napięcie wsteczne może wynosić kilkaset wolt.
Złącze p-n tworzy element elektroniczny zwany diodą. O diodach pisaliśmy na samym początku tego rozdziału w historii elektroniki. Dioda (ang. diode) jest elementem, który przewodzi prąd tylko w jednym kierunku polaryzacji. Dioda półprzewodnikowa przewodzi prąd elektryczny, gdy do jej półprzewodnika p przyłożymy biegun dodatni a do półprzewodnika n biegun ujemny napięcia zasilającego i napięcie to jest większe od napięcia bariery potencjału UF. Na schematach elektrycznych diodę przedstawia się za pomocą symbolu:
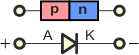
Połączenia z półprzewodnikami są w diodzie wyprowadzone na zewnątrz w postaci dwóch elektrod: A – anoda (podłączana do plusa zasilania) i K – katoda (podłączana do minusa zasilania). Wewnątrz obudowy anoda jest połączona z półprzewodnikiem typu p a katoda z półprzewodnikiem typu n. Strzałka w symbolu diody wskazuje kierunek przepływu prądu elektrycznego: od anody do katody.
Najprostszym modelem diody jest przyjęcie, że jest ona elementem idealnym. Oznacza to, że przewodzi tylko w jednym kierunku. W trakcie przewodzenia posiada zerową oporność. Charakterystyka diody idealnej wygląda następująco:
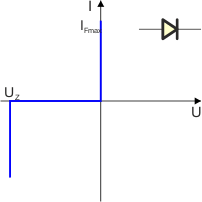
UZ jest to napięcie wsteczne, przy którym następuje lawinowy wzrost prądu wstecznego. Napięcie to nazywa się często napięciem Zenera, a diodę, która pracuje w tej części charakterystyki nazywa się diodą Zenera. Symbol diody Zenera jest nieco inny:
Diody Zenera pracują spolaryzowane w kierunku zaporowym.
Diody często wykorzystuje się do prostowania napięcia przemiennego. Najprostszy układ prostujący wygląda następująco:
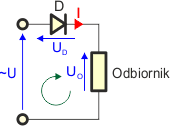
Składa się on z odbiornika oraz połączonej z nim szeregowo diody D. Przeanalizujemy ten układ, posługując się wykresami:
Układ tworzy zamknięte oczko sieci, musi zatem w nim obowiązywać II prawo Kirchhoffa:

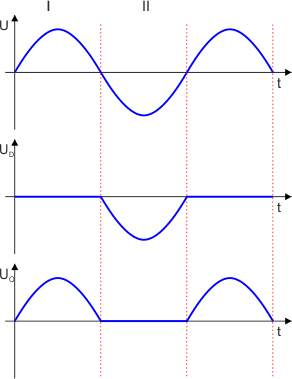
W I połówce przebiegu napięcia zasilającego dioda jest spolaryzowana w kierunku przewodzenia. Zgodnie z jej charakterystyką idealną napięcie na diodzie wynosi 0. Skoro tak, to całe napięcie zasilające odkłada się na odbiorniku.
W II połówce dioda jest spolaryzowana zaporowo i nie przewodzi prądu. Możemy uznać, że posiada nieskończenie dużą oporność. Skoro tak, to całe napięcie zasilające odłoży się na diodzie. Na odbiornik trafi wtedy napięcie zero. Prąd przestanie płynąć w obwodzie.
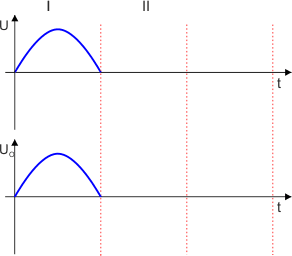
Prostownik zawierający jedną diodę nazywamy prostownikiem jednopołówkowym, ponieważ napięcie występuje na odbiorniku tylko przez jedną połówkę przebiegu napięcia zasilającego.
Prostownik dwupołówkowy można zbudować przy pomocy czterech diod:
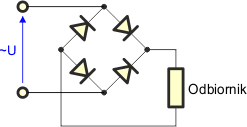
Układ taki nosi nazwę mostka Graetza lub prostownika mostkowego. W dzisiejszych czasach tego typu układy prostownicze możesz bez problemów kupić w każdym sklepie elektronicznym. Przeanalizujmy działanie mostka Graetza przy założeniu, że zbudowano go z diod idealnych.
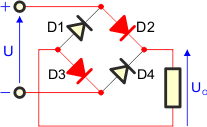
W kierunku przewodzenia zostaną spolaryzowane diody D2 i D3. Pozostałe dwie diody, D1 i D4, są spolaryzowane zaporowo i nie przewodzą prądu. Na odbiorniku odłoży się napięcie równe napięciu zasilającemu. Strzałka pokazuje zwrot tego napięcia.
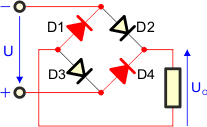
Napięcie zasilające zmienia polaryzację (druga połówka funkcji sinus jest ujemna). W kierunku przewodzenia zostaną spolaryzowane diody D1 i D4, natomiast diody D2 i D3, które przewodziły w pierwszej połówce, teraz będą spolaryzowane zaporowo. Na odbiorniku znów odłoży się całe napięcie zasilające. Zwróć uwagę, że polaryzacja napięcia na odbiorniku nie zmienia się, pomimo zmiany polaryzacji napięcia zasilającego – strzałka wciąż wskazuje do góry. Dzieje się tak dlatego, że prąd płynie przez prostownik inną drogą niż poprzednio.
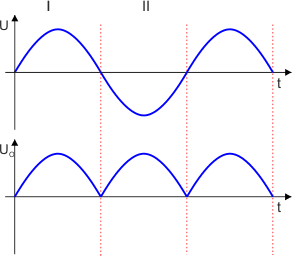
Na odbiorniku pojawiają się obie połówki napięcia zasilającego. Takie zasilanie jest bardziej korzystne od zasilania jednopołówkowego.
Jak widzisz, nawet prosty model diody pozwala analizować układy elektroniczne. Co się w nich zmieni w przypadku diody rzeczywistej? W kierunku przewodzenia należy uwzględnić spadek napięcia na diodzie, który w praktyce dla diod krzemowych jest równy około 0,6...0,8V. Wynika stąd, że prostownik jednopołówkowy da nam maksymalne napięcie wyjściowe mniejsze średnio o około 0,7V, a prostownik dwupołówkowy mniejsze o około 1,4V. Tę różnicę należy uwzględnić przy doborze napięcia zasilającego. Gdy przez diodę rzeczywistą przepływa prąd, to wydziela się na niej moc:

Projektując prostownik należy dobrać diody, tak aby ich prąd maksymalny IF był większy od założonego prądu pracy (na przykład nasz układ pobiera prąd 1A, to stosujemy diody o prądzie 5A). Zagadnienia te omówimy w części praktycznej.
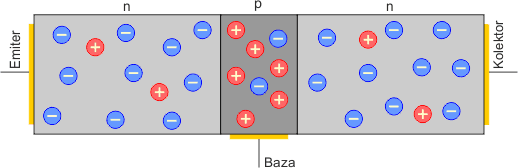
Rysunek powyżej jest tylko rysunkiem poglądowym. W rzeczywistym tranzystorze warstwy półprzewodnikowe wyglądają tak:
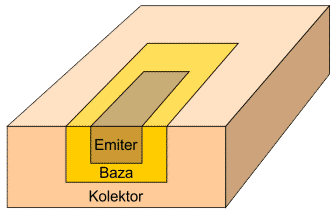
Elektrody tranzystora posiadają swoje nazwy, które odzwierciedlają ich funkcje:
Na styku warstw półprzewodnikowych powstają dwa złącza p-n i tworzy się na nich bariera potencjału:
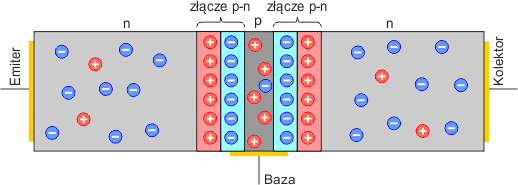
Jeśli spolaryzujemy złącze baza-emiter w kierunku przewodzenia (baza będzie mieć potencjał wyższy od potencjału emitera) napięciem UBE, to w obwodzie baza-emiter popłynie prąd elektryczny IBE. Elektrony, które są nośnikami większościowymi w półprzewodniku n emitera, przejdą przez barierę potencjału na złączu B-E i znajdą się w półprzewodniku p bazy. Będą one przyciągane przez elektrodę Bazy, ponieważ posiada ona potencjał dodatni.
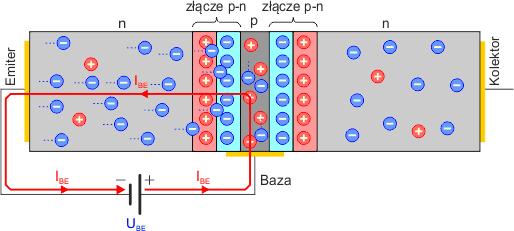
Warstwa bazy w tranzystorze jest bardzo cienka. Jeśli teraz spolaryzujemy złącze baza-kolektor zaporowo (do kolektora przyłożymy potencjał wyższy od potencjału bazy i oczywiście wyższy od potencjału kolektora), to kolektor zacznie przyciągać ładunki ujemne, które przeszły z półprzewodnika n emitera do półprzewodnika p bazy. W efekcie w obwodzie kolektor-emiter popłynie dużo większy prąd niż w obwodzie baza-emiter. Część elektronów z emitera zrekombinuje z dziurami w półprzewodniku bazy, jednakże strata ta nie jest większa niż 1%.
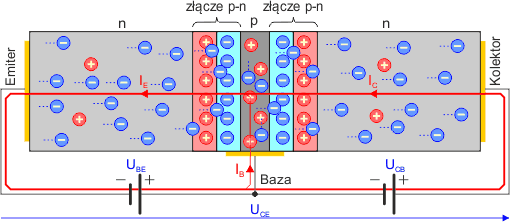
Prąd bazy IB jest niewielki. Prąd kolektora IC jest z kolei duży. Małe zmiany prądu bazy wywołują duże zmiany prądu kolektora. Na tej zasadzie opiera się funkcja wzmacniania sygnałów przez tranzystor. Współczynnik wzmocnienia prądowego tranzystora (tzw. parametr h21E) wyraża się wzorem:

Wartość tego współczynnika β zależy od typu tranzystora, wynosi zwykle ponad 100 (czyli przy prądzie bazy 1mA prąd kolektora wyniesie 100mA). Większość mierników uniwersalnych pozwala na pomiar wzmocnienia prądowego.
Pozostałe wzory, które mogą się przydać, to:

W tranzystorze pnp powstają identyczne zjawiska, należy jedynie odwrócić biegunowość napięć baza-emiter oraz kolektor-baza.
Na schemacie elektrycznym tranzystory oznaczamy w sposób następujący:
npn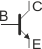 lub
lub
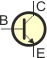 |
pnp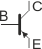 lub lub
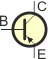 |
Kierunek strzałki, podobnie jak w przypadku diod, obrazuje kierunek płynięcia prądu elektrycznego (nie elektronów!) przez tranzystor (emiter–kolektor). Dla tranzystorów npn do kolektora dołączamy biegun (+), a do emitera biegun (–). W tranzystorach pnp należy postąpić na odwrót (nie podłączaj jeszcze zasilania, doczytaj do końca ten artykuł).
Uwaga:
Oznaczenia UE, UB i UC oznaczają napięcia na końcówkach tranzystora względem wybranego punktu w układzie elektronicznym. Najczęściej jest to punkt wspólny, który dołączamy do minusa zasilania i nazywamy go masą (ang. ground, GND). Napięcia pomiędzy końcówkami tranzystora oznaczamy zawsze za pomocą indeksów dwuliterowych:
UBE – napięcie
pomiędzy bazą a emiterem
UCB – napięcie pomiędzy
kolektorem a bazą
UCE – napięcie pomiędzy
kolektorem a emiterem
Przy projektowaniu obwodów elektronicznych z tranzystorami należy zastosować pewien model matematyczny, który umożliwi wykonanie obliczeń. Modeli takich opracowano dużo. My przyjmiemy najprostszy model, który przedstawia tranzystor jako dwie połączone ze sobą diody (pamiętaj jednak, że z dwóch diod tranzystora nie uda ci się zbudować).
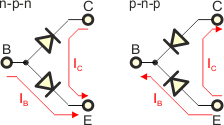
W modelu przyjmijmy następujące założenia (dla tranzystora n-p-n):



Punkt 4 demonstruje nam użyteczność tranzystora: jest to element, w którym mały prąd bazy wpływa na duży prąd kolektora. Projektując układ tranzystorowy nie należy się opierać ściśle na wartości współczynnika β, który nawet dla tranzystorów tego samego typu może przyjmować duży zakres wartości, np. od 50...200. Co gorsze, wartość tego współczynnika zależy również od wartości prądu kolektora, napięcia miedzy kolektorem a emiterem oraz od temperatury złącz p-n w tranzystorze.
W układzie elektronicznym należy również zadbać, aby napięcie baza-emiter nie przekraczało wartości 0,6...0,8V. Jest to napięcie przewodzenia złącza p-n baza-emiter. Przekroczenie tej wartości powoduje duży wzrost prądu bazy. Napięcie to ma tendencję do samoregulacji, czyli ustala się automatycznie na odpowiednim poziomie. Wynika z tego, że:

Prąd kolektora nie jest prądem przewodzenia "diody baza-kolektor", ponieważ złącze to jest spolaryzowane zaporowo. Wpływający prąd kolektora jest specyficznym wynikiem działania tranzystora (dlatego tranzystora nie uda się zbudować z dwóch diod).
Nasz uproszczony model pozwala dosyć łatwo zrozumieć działanie wielu układów elektronicznych, w których wykorzystany jest tranzystor bipolarny. Przeanalizujmy poniższy układ:
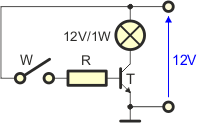
Układ złożony jest z:
Układ jest zasilany napięciem stałym 12V. Gdy wyłącznik W jest rozwarty, to prąd bazy wynosi 0, zatem zgodnie z punktem 4 naszego modelu prąd kolektora również wynosi 0. Żarówka nie świeci.
Gdy włączymy wyłącznik W powstanie obwód bazy przez który popłynie prąd bazy:
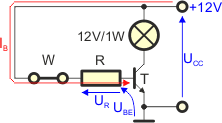
Zgodnie z II prawem Kirchhoffa:

Prąd bazy wywoła prąd kolektora:

Jeśli prąd bazy będzie miał odpowiednią wartość, to żarówka zaświeci. Naszym zadaniem jest dobór wartości rezystora R, aby tak się stało. Najpierw policzmy potrzebną wartość prądu kolektora. Otrzymamy ją z parametrów żarówki:

Teraz wyliczamy wartość prądu bazy:

Wzmocnienie prądowe przyjąłem na poziomie 50. Jeśli tranzystor będzie miał większą betę, to tym lepiej. I tak prąd kolektora jest ograniczony przez żarówkę.
Gdy mamy prąd bazy, wykorzystujemy prawo Ohma i II prawo Kirchhoffa dla obwodu bazy:

Ostatecznie:
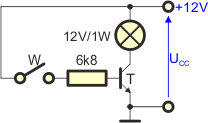
W tym konkretnym układzie korzystne byłoby nawet wstawienie mniejszego opornika, np. 5k lub nawet 1k. Większy prąd bazy uodporniłby ten układ na różne niekorzystne zdarzenia (np. na spadek wzmocnienia prądowego). W obwodzie kolektora prąd nie przekroczy wartości maksymalnej dla żarówki, czyli większy prąd bazy nie zwiększy prądu kolektora powyżej założonej wartości.
W opisanym powyżej układzie tranzystor pracuje jako przełącznik. W układach przełączających prądy bazy powinny być kilkakrotnie większe, niż wynika to z punktu 4. Taki większy prąd bazy powoduje nasycenie tranzystora.
Więcej na ten temat znajdziesz w części praktycznej.
Na początek opiszemy tzw. tranzystor JFET (ang. Junction Field Effect Tranzystor). Jest to polowy tranzystor złączowy. Przede wszystkim składa się on z jednolitej warstwy półprzewodnika typu n lub rzadziej typu p, wzdłuż której została odpowiednio umieszczona druga warstwa półprzewodnika odwrotnego typu:
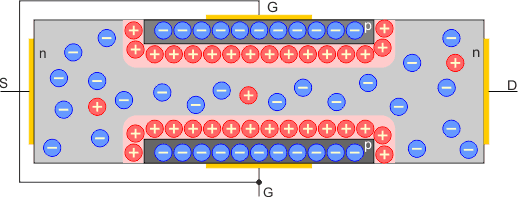
Na styku obu warstw półprzewodników tworzy się znane nam złącze p-n. Dziury z półprzewodnika typu p przenikają do obszarów półprzewodnika typu n leżących przy złączu i powodują rekombinację ładunków większościowych, czyli elektronów. Powoduje to powstanie przy złączu ładunku dodatniego, który powstrzymuje dalszy przepływ dziur z półprzewodnika typu p. Podobnie elektrony z półprzewodnika n przedostają się przez złącze i tworzą przy nim ładunek ujemny, rekombinując z obecnymi tam dziurami. Proces ten prowadzi do powstania bariery potencjału na styku tych dwóch półprzewodników.
W warstwie podstawowej tworzy się kanał, poprzez który mogą przepływać elektrony (lub dziury dla półprzewodnika p – tego typu tranzystory polowe JFET spotyka się rzadziej). Do końców tej warstwy podłączone są dwie elektrody, które nazywa się źródłem S (ang. source) i drenem D (ang. Drain). Trzecia elektroda, zwana bramką G (ang Gate), podłączona jest do drugiej warstwy półprzewodnika.
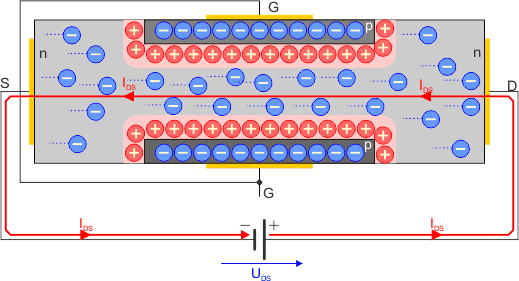
Jeśli do źródła S i drenu D przyłożymy napięcie UDS, to popłynie prąd elektryczny IDS. W takiej konfiguracji nie ma znaczenia polaryzacja tego napięcia – tranzystor JFET przewodzi w obu kierunkach na linii S-D.
Jeśli jednak złącze G-S spolaryzujemy ujemnie, tzn. do bramki G przyłożymy niższy potencjał od potencjału źródła S, to złącze p-n zostanie spolaryzowane zaporowo. Bariera potencjału wzrośnie oraz powiększy się obszar ładunku przestrzennego, ponieważ nośniki większościowe odpłyną w kierunku elektrod. Obszar tego ładunku jest jałowy, pozbawiony nośników większościowych. W efekcie przekrój czynny kanału zmniejsza się, co powoduje wzrost oporności pomiędzy źródłem S a drenem D. Prąd IDS maleje.
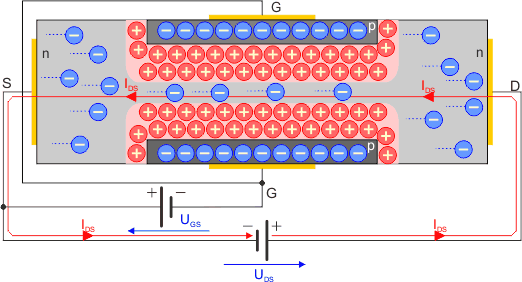
Przy pewnym napięciu UGS obszar ładunku przestrzennego obejmuje cały przekrój czynny półprzewodnika typu n i kanał zostaje zamknięty. Prąd IDS przestaje płynąć.
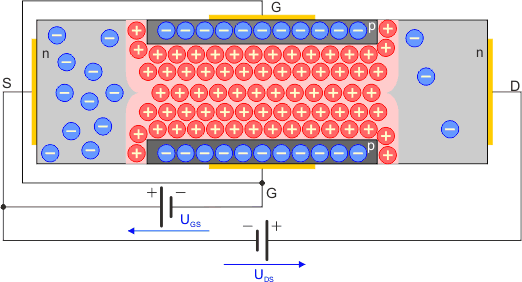
Wynika z tego, że tranzystor JFET działa jak zawór, a regulatorem przepływu jest ujemne napięcie na bramce G. Ponieważ w trakcie pracy złącze G-S spolaryzowane jest zaporowo (przy polaryzacji w kierunku przewodzenia tranzystor JFET traci swoje własności), to w obwodzie bramki tranzystora polowego prąd praktycznie nie płynie. Oporność wejściowa ma wartość kilku megaomów. Sterowanie odbywa się za pomocą ujemnego napięcia UGS. Dla tranzystorów JFET z kanałem typu p polaryzacje napięć są odwrotne.
Na schematach elektrycznych tranzystory JFET oznacza się następująco:
| JFET-N | JFET-P | |
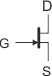 lub lub 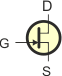 |
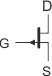 lub lub 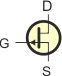 |
Charakterystyka prądowo-napięciowa tranzystora N JFET wygląda tak:
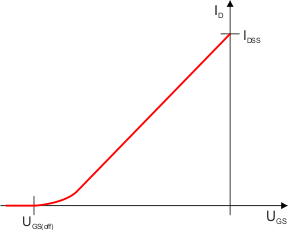 |
| ID – prąd drenu IDSS – prąd nasycenia dren-żródło UGS – napięcie bramka-źródło UGS(off) – napięcie odcięcia bramka-źródło |
Charakterystyka prądowo-napięciowa dla tranzystora P JFET jest odwrócona:
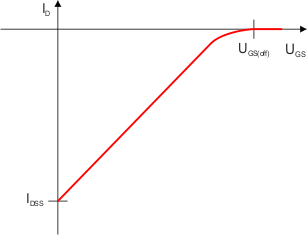
Tranzystor MOSFET (ang. Metal-Oxide Semiconductor Field-Effect Transistor) jest zwany również tranzystorem polowym z izolowaną bramką. Zbudowany jest inaczej niż tranzystor JFET i posada inne parametry. Dzisiaj jest to najpowszechniej stosowany tranzystor polowy. Znajdziesz go praktycznie w każdym urządzeniu cyfrowym: w komputerach, telefonach, pamięciach, itp.
Poniżej przedstawiamy kolejne etapy powstawania tranzystora MOSFET. Materiałem wyjściowym jest półprzewodnik typu p (istnieją również wersje z półprzewodnikiem typu n).
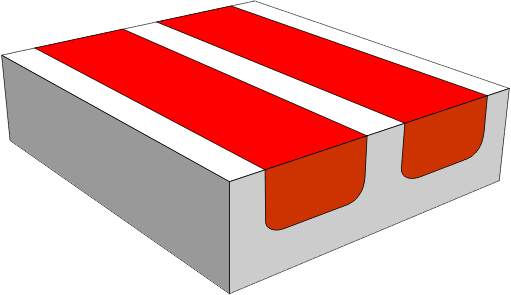
W materiale półprzewodnika typu p zostają wytworzone dwa obszary półprzewodnika typu n z silnym domieszkowaniem. Obszary te posiadają swobodne elektrony, które mogą się poruszać.
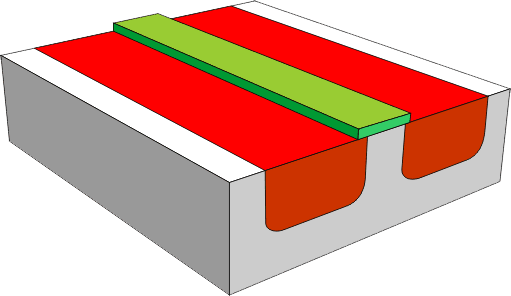
Pomiędzy obszarami typu n zostaje dodana warstwa izolacyjna z dwutlenku krzemu.
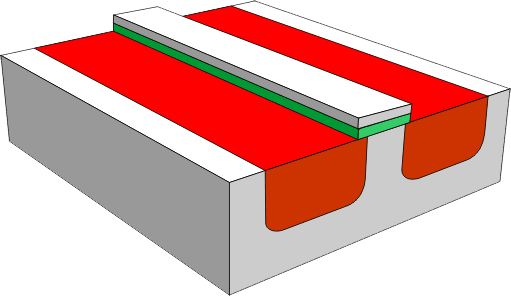
Na warstwę izolacyjną zostaje nałożona warstwa aluminium, która będzie pełniła rolę elektrody G (ang. G: gate, czyli bramka) tranzystora.
Na koniec na całość zostaje nałożona warstwa izolacyjna z otworami na elektrody.
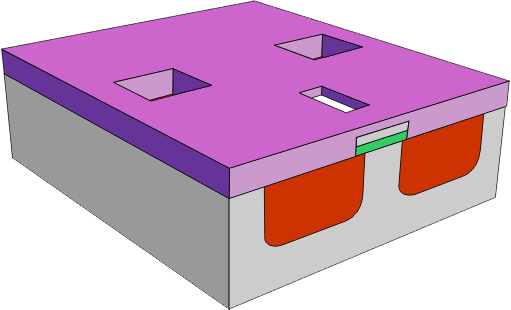
W otworach zostają umieszczone metalowe elektrody. Tranzystor MOSFET jest gotowy (wystarczy umieścić go w odpowiedniej obudowie):
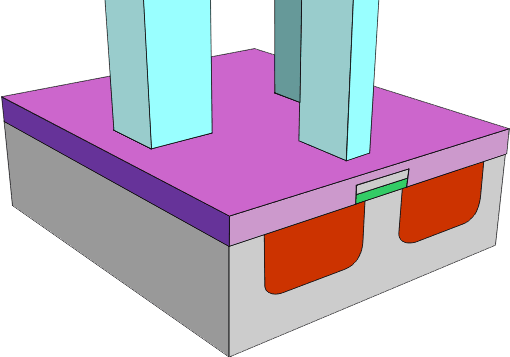
Teraz przejdźmy do zasady działania takiego tranzystora.
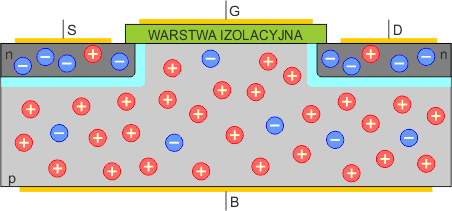
Tranzystor MOSFET posiada cztery elektrody:
Podłoże B jest zwykle wewnętrznie połączone ze źródłem S, dlatego na zewnątrz wyprowadzone są tylko trzy elektrody: S, G i D.
Zasada działania tranzystora MOSFET opiera się na sterowaniu przepływem prądu od źródła S do drenu D za pomocą bramki G. Jeśli do bramki G nie jest przyłożone żadne napięcie, to prąd nie będzie płynął pomiędzy S i D, ponieważ między tymi elektrodami nie ma swobodnych nośników ładunku. Na styku półprzewodników typu p i typu n tworzą się dwa złącza p-n, z których jedno jest zawsze spolaryzowane zaporowo bez względu na zwrot napięcia przyłożonego do S i D.
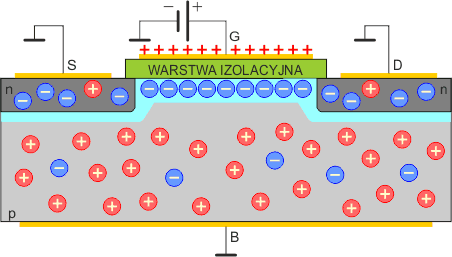
Jeśli jednak przyłożymy do bramki G napięcie dodatnie w stosunku do S i B, to spowoduje ono przyciągnięcie elektronów z półprzewodnika typu p i jednoczesne odepchnięcie dziur. Ponieważ bramka G jest izolowana od półprzewodnika typu p, to nie popłynie tutaj praktycznie żaden prąd. Wszystko odbywa się na zasadzie oddziaływań elektrostatycznych.
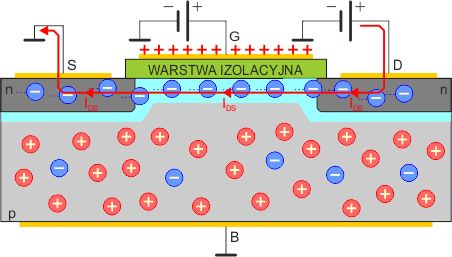
Powstanie w ten sposób kanał n, który umożliwi przepływ elektronom ze źródła S do drenu D. Zwiększając napięcie bramki wpływamy na szerokość tego kanału, a to z kolei ma wpływ na oporność linii S-D. Im kanał szerszy, tym ma mniejszą oporność.
Na schematach elektrycznych stosuje się następujące oznaczenia dla tranzystorów MOSFET:
| MOSFET-N | MOSFET-P | |
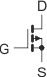 lub lub  |
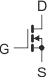 lub lub  |
Charakterystyka prądowo-napięciowa dla tranzystora MOSFET-N jest następująca:
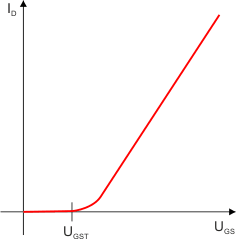
i dla tranzystora MOSFET-P:
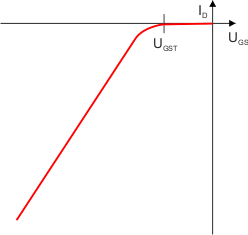 |
| ID – prąd drenu UGS – napięcie bramka-źródło UGST – napięcie progowe bramka-źródło |
Zaletą tranzystorów polowych jest to, że sterowanie odbywa się za pomocą napięcia przyłożonego do bramki. Bramka praktycznie nie pobiera prądu, czyli nie obciąża źródła. W świecie techniki cyfrowej jest to bardzo cenna własność. Pozwala ona tworzyć urządzenia o bardzo małym poborze energii, co jest szczególnie ważne przy pracy na zasilaniu bateryjnym. Tranzystory polowe dają się miniaturyzować, np. współczesne układy cyfrowe mogą zawierać dziesiątki milionów takich tranzystorów (np. pamięci komputerowe).
Więcej o tranzystorach polowych znajdziesz w części praktycznej.
| Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2024 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone
pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.