w I-LO w Tarnowie
Materiały dla uczniów liceum
Wyjście Spis treści Wstecz Dalej

Autor artykułu: mgr Jerzy Wałaszek
©2024 mgr Jerzy Wałaszek
I LO w Tarnowie
![]()
|
Serwis Edukacyjny w I-LO w Tarnowie Materiały dla uczniów liceum |
Wyjście Spis treści Wstecz Dalej
Autor artykułu: mgr Jerzy Wałaszek |
©2024 mgr Jerzy Wałaszek
|
| SPIS TREŚCI |
| Podrozdziały |
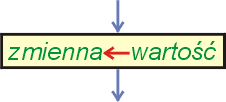
Przypisanie jest podstawową operacją wykonywaną przez każdy program niezależnie od zastosowanego do jego utworzenia języka programowania. Przypisanie polega na umieszczeniu w zmiennej (w PMC jest to komórka pamięci) informacji.
Poniższy fragment programu umieszcza w zmiennej o nazwie
A liczbę o wartości 115:
...
A: DAT 0 ;definicja zmiennej
...
LDA #115 ;załaduj liczbę 115 do akumulatora
STA A ;zawartość akumulatora umieść w komórce A
...
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA |
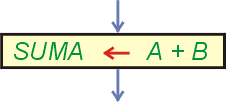
Wartość umieszczana w komórce może być wynikiem obliczeń. Napiszemy prosty
program w asemblerze PMC, który odczyta i zsumuje
zawartość dwóch komórek pamięci, a wynik tej operacji umieści w trzeciej
komórce:
RUN START
A: DAT 15 ;pierwsza liczba
B: DAT 8 ;druga liczba
SUMA: DAT 0 ;tutaj zostanie umieszczona suma A i B
START: LDA A ;pobierz do akumulatora zawartość komórki A
ADD B ;dodaj do akumulatora zawartość B
STA SUMA ;wynik umieść w komórce SUMA
Zobacz na:etykieta, zmienna, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, ADD |
Zapamiętaj!Przypisanie umieszcza w komórce wartość. Wartość tę najpierw obliczamy w akumulatorze, a następnie umieszczamy wyliczoną zawartość akumulatora we wskazanej komórce pamięci. |
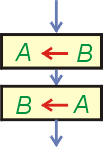
W wielu algorytmach (np. porządkujących ciągi liczbowe) należy dokonać wymiany pomiędzy sobą zawartości dwóch zmiennych. Operacji tej nie można wykonać w sposób przedstawiony na lewym diagramie. Już pierwsze przypisanie powoduje, iż w obu zmiennych A i B będzie zawartość zmiennej B. Zawartość A jest niszczona. W efekcie druga operacja nic nie zmieni. Na wyjściu w obu zmiennych pozostanie zawartość zmiennej B, a nie o to nam chodziło.
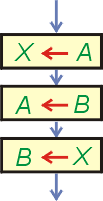
Aby zrobić to poprawnie, musimy wprowadzić dodatkową zmienną pomocniczą, która posłuży do chwilowego przechowania danych. Operacja wymiany zawartości dwóch zmiennych wymaga trzech kroków, co przedstawia prawy diagram.
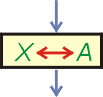
Symbolicznie wymianę zawartości zapisujemy w sposób pokazany powyżej. Musimy jednak pamiętać, iż nie jest to operacja pojedyncza - wymaga trzech instrukcji procesora.
Poniższy program korzysta z tego schematu do wymiany zawartości zmiennych
A i B.
RUN START
A: DAT 65
B: DAT 5
X: DAT 0 ;zmienna pomocnicza
START: LDA A ;umieszczamy A w X
STA X
LDA B ;przesyłamy B do A
STA A
LDA X ;przesyłamy X do B
STA B
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA |
W programach występuje często potrzeba sprawdzenia, czy pewna zmienna jest równa zero lub nie. Sprawdzenia takiego dokonujemy za pomocą rozkazu skoku warunkowego JZR w sposób następujący:
...
LDA zmienna ;pobieramy zawartość zmiennej do akumulatora
JZR #ZERO ;testujemy akumulator
... ;wykonujemy tutaj, gdy zmienna <> 0
JMP #KONIEC ;wyjście poza koniec instrukcji warunkowych
ZERO: ... ;wykonujemy tutaj, gdy zmienna = 0
KONIEC: ... ;dalsza część programu
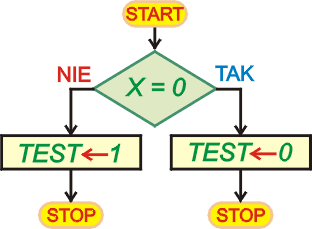
Napiszemy teraz program, który przetestuje w opisany powyżej sposób zawartość
komórki
X i w zależności od wyniku wpisze do komórki
TEST 0, gdy X
= 0 lub 1, gdy X <> 0.
RUN START
X: DAT -4 ;tutaj jest testowana zmienna
TEST: DAT 0 ;tutaj będzie wynik testu
START: LDA X ;pobieramy zawartość zmiennej X
JZR #ZR1 ;skaczemy do obsługi przypadku, gdy x=0
LDA #1 ;x<>0, do TEST wpiszemy 1
ZR1: STA TEST ;w TEST umieszczamy 0 lub 1.
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JZR |
Powyższy program został zoptymalizowany. Zauważ, iż po pobraniu zawartości zmiennej X do akumulatora możemy ją wykorzystać do umieszczenia w zmiennej TEST w przypadku, gdy jest równa zero. W przeciwnym razie zawartość akumulatora zmieniamy na 1 przed umieszczeniem jej w zmiennej TEST. Tego typu decyzje muszą być dokładnie przeanalizowane.
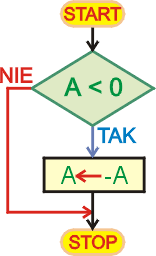
Następny program oblicza wartość bezwzględną zawartości komórki A. Wartość bezwzględna ma następującą definicję:

Obliczenia polegają na zbadaniu wartości A. Jeśli jest ona ujemna, to obliczamy wartość przeciwną i wpisujemy do A. Jeśli A wynosi 0 lub jest dodatnie, pozostawiamy ją bez zmian.
Wartość przeciwną obliczamy odejmując zawartość zmiennej A
od 0. Można też zanegować wszystkie bity operacją XOR #0B1111111111111111,
a następnie dodać wartość 1. Wyjaśnienie znajduje się w rozdziale opisującym
kod U2.
RUN START
A: DAT -14 ;liczba, dla której obliczymy moduł
START: LDA A ;pobieramy zawartość zmiennej
JMI #ZM1 ;jeśli < 0, to zmieniamy
JMP #KON1 ;jeśli nie, to pozostawiamy w spokoju
ZM1: LDA #0 ;zmieniamy znak A
SUB A
STA A
KON1:
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JMI, SUB |
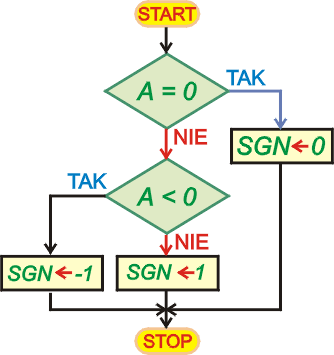
Następny program oblicza wartość funkcji znaku (SIGNUM). Funkcja ta zdefiniowana jest następująco:

Program obliczy funkcję SIGNUM dla zawartości komórki
A, a wynik umieści w komórce SGN. W programie
wykonywane są dwa testy. Najpierw na wartość zero. W takim przypadku do
SGN wpisujemy zero. Jeśli test na zero zawiedzie, to liczba w zmiennej
A jest albo większa od zera, albo mniejsza. Drugi test ma
to sprawdzić i wpisać do SGN odpowiednią wartość.
RUN START
A: DAT -6 ;komórka zawiera argument
SGN: DAT 0 ;tutaj trafi wartość SIGNUM(LB1)
START: LDA A ;pobieramy argument
JZR #SGNZ ;A = 0?
JMI #SGNM ;A < 0?
LDA #1 ;A > 0, więc SGN = 1
JMP #SGNZ ;umieść wynik w SGN
SGNM: LDA #-1 ;A < 0, więc SGN = -1
SGNZ: STA SGN ;wynik umieszczamy w SGN
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JZR, JMI |
Procesor PMC nie posiada bezpośrednich rozkazów do porównania dwóch liczb. Operację tę wykonujemy za pomocą odejmowania i badania wyniku rozkazami skoków warunkowych. Załóżmy, iż mamy dwie liczby a i b. Badając ich różnicę możemy dowiedzieć się wszystko o wzajemnej relacji tych liczb:
jeśli a - b < 0,
to a < b
jeśli
a - b = 0, to a = b
jeśli
a - b > 0, to
a > 0
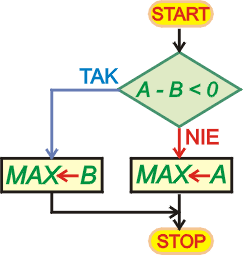
Poniższy program porównuje zmienne A i
B i wpisuje do zmiennej
MAX większą z nich. Test polega na sprawdzeniu znaku
różnicy tych zmiennych. Jeśli różnica
A - B jest mniejsza od zera, to mamy pewność, iż
B > A (patrz uwagi na końcu tego
paragrafu). W takim przypadku do zmiennej
MAX przesyłamy zawartość zmiennej
B. Jeśli test na wartość mniejszą od zera zawiedzie, to
albo
A = B, albo
A > B. W obu przypadkach możemy w zmiennej
MAX umieścić zawartość zmiennej
A.
RUN START
A: DAT -15 ;pierwsza porównywana liczba
B: DAT 7 ;druga porównywana liczba
MAX: DAT 0 ;tutaj trafi większa z A i B
START: LDA A ;obliczamy różnicę A - B
SUB B
JMI #MAX2 ;jeśli mniejsza od 0, to MAX <- B
LDA A ;inaczej MAX <- A
JMP #MAXE
MAX2: LDA B
MAXE: STA MAX ;wynik umieszczamy w MAX
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JMI, SUB |
UWAGA: Należy zdawać sobie sprawę, iż programy tego typu będą działały poprawnie tylko wtedy, gdy różnica obu liczb leży w dozwolonym zakresie 16 bitowych liczb w kodzie U2 (-32768, 32767).
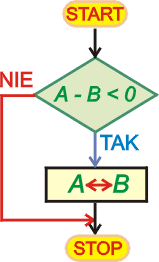
Kolejny program uporządkuje dwie liczby w porządku rosnącym. Porządkowanie
będzie polegało na porównaniu obu liczb, a następnie wymianie zawartości, jeśli
pierwsza liczba jest większa od drugiej. Przy porównaniu badamy znak różnicy
tych liczb. Liczby są przechowywane w komórkach A i
B.
RUN START
A: DAT 15 ;pierwsza liczba
B: DAT 10 ;druga liczba
X: DAT 0 ;zmienna pomocnicza
START: LDA B ;badamy różnicę B - A
SUB A
JMI #ZAM ;jeśli mniejsza od zera, Wymieniamy A z B
JMP #KON ;inaczej kończymy
ZAM: LDA A ;wymieniamy zawartość A z B
STA X
LDA B
STA A
LDA X
STA B
KON: ;gotowe, A i B uporządkowane
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JMI, SUB |
Pętla (ang. loop) jest grupą instrukcji wykonywanych cyklicznie przez program. Pętle stanowią jedną z podstawowych konstrukcji każdego większego programu. Dzięki nim można w jednorodny sposób przetwarzać np. poszczególne elementy tablic, ciągów, wykonywać wielokrotnie powtarzające się operacje. Umiejętne stosowanie pętli znacznie upraszcza strukturę programu.
Cechą charakterystyczną każdej pętli jest wykonywanie skoku z jej końca na początek. Dzięki temu instrukcje zawarte wewnątrz mogą być wielokrotnie wykonywane.
Z uwagi na sposób zakończenia wykonywania instrukcji rozróżniamy dwa rodzaje pętli:
Pętla nieskończona powstaje, jeśli na końcu grupy instrukcji umieścimy rozkaz skoku bezwarunkowego na początek tej grupy. Instrukcje objęte takim skokiem będą wykonywane w nieskończoność. Tego typu pętle stosuje się czasami przy różnych demonstracjach, gdy chcemy, aby program ciągle się wykonywał. Jednak dobrą praktyką programowania jest raczej unikanie tego typu konstrukcji.
Poniższy program zwiększa w kółko o 1 zawartość zmiennej A.
RUN START
A: DAT 0
START: INC A ;zwiększ o 1 zawartość A
JMP #START ;wykonuj w kółko
Cechą charakterystyczną pętli warunkowej jest sprawdzanie warunku powtarzania instrukcji objętych taką pętlą. Warunek ten może być sprawdzany na początku pętli (przed wykonaniem instrukcji wewnętrznych) lub na końcu pętli (po wykonaniu instrukcji wewnętrznych).
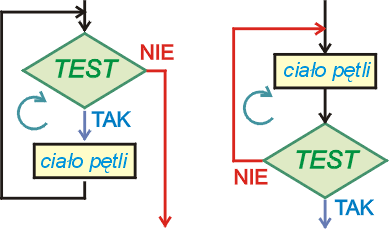
Jeśli już na początku pętli warunek nie jest spełniony, to pętla nie wykona się ani jeden raz - nastąpi skok do instrukcji poza pętlą. Instrukcje wewnętrzne są wykonywane, jeśli warunek jest spełniony (można również konstruować pętle przy niespełnianiu warunku).
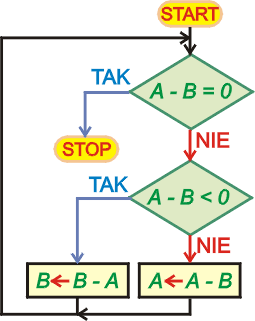
Jako przykład napiszemy program wykorzystujący pętlę do znalezienia największego wspólnego dzielnika dwóch liczb. NWD jest największą z liczb, które bez reszty dzielą obie liczby. Zastosujemy bardzo prosty algorytm, zwany algorytmem Euklidesa (właściwie jest to modyfikacja tego algorytmu). Znalezienie największego wspólnego dzielnika dwóch liczb polega na odejmowaniu od liczby większej liczby mniejszej aż obie liczby będą sobie równe. Wynik jest właśnie największym wspólnym dzielnikiem obu liczb.
Zastosowana metoda może nie jest najbardziej efektywną, ale posiada istotną
zaletę - jest prosta i łatwa do realizacji. Dużo szybciej rozwiązuje się taki
problem stosując operację modulo (reszta z dzielenia dwóch liczb). Warunek jest
sprawdzany na początku pętli. Jeśli jest spełniony, to następuje natychmiastowe
wyjście z pętli (instrukcja JZR #NWDE). Jeśli warunek
nie jest spełniony, to są wykonywane powtarzane operacje, a na ich końcu
umieszcza się skok bezwarunkowy do początku pętli (instrukcje
JMP #START).
RUN START
A: DAT 30 ;pierwsza liczba
B: DAT 72 ;druga liczba
START: LDA A ;sprawdzamy warunek A-B = 0
SUB B
JZR #NWDE ;jeśli A-B = 0, kończymy pętlę
JMI #NWD2 ;B > A ?
STA A ;tutaj A > B, więc A<-A-B
JMP #START ;i kontynuujemy pętlę
NWD2: LDA B ;tutaj B > A, więc B<-B-A
SUB A
STA B
JMP #START ;zapisujemy i kontynuujemy
NWDE: ;koniec, NWD jest w obu zmiennych A i B
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JMI, SUB |
Drugi rodzaj pętli warunkowej sprawdza warunek na końcu pętli. W tym przypadku instrukcje są powtarzane w pętli, aż warunek stanie się prawdziwy. Wtedy pętla jest przerywana. Zasadniczą różnicą w stosunku do poprzedniego typu pętli jest to, iż zawsze wykonana zostanie przynajmniej jeden raz, bez względu na spełnienie bądź niespełnienie warunku kontynuacji pętli.
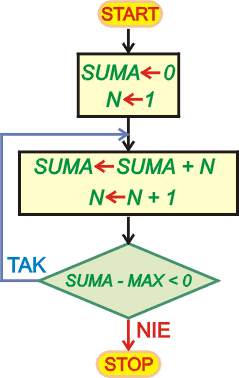
Następny program oblicza sumę kolejnych liczb naturalnych, aż osiągnie ona
lub przekroczy zadaną wartość. Na początku zmienna SUMA
musi przyjąć wartość 0 (jeszcze nic nie zsumowaliśmy),
a pierwsza liczba do sumowania ma wartość 1 i jest ustawiana w zmiennej
N. W pętli do sumy dodajemy zawartość N. Następnie
N zwiększamy o 1. Teraz wykonujemy sprawdzenie, czy SUMA
przekracza zadaną wartość MAX. Sprawdzenie polega na
zbadaniu znaku różnicy SUMA - MAX.
Jeśli różnica ta jest mniejsza od zera, to jeszcze musimy sumować i pętla jest
kontynuowana. Z chwilą, gdy różnica przestanie być ujemna, pętla jest kończona.
Wynik sumowania można odczytać na panelach programu i pamięci w komórce o
etykiecie SUMA.
RUN START
MAX: DAT 1000 ;tutaj określamy wartość graniczną
N: DAT 1 ;pierwsza liczba naturalna
SUMA: DAT 0 ;wartość początkowa sumy
START: LDA SUMA ;SUMA <- SUMA + N
ADD N
STA SUMA
INC N ;N <- N + 1
SUB MAX ;SUMA > MAX?
JMI #START ;kontynuujemy, jeśli nie.
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMI, ADD, SUB, INC |
Iteracja jest to jeden obieg pętli. Pętla iteracyjna jest odmianą pętli warunkowej. Cechą charakterystyczną jest to, iż posiada ona licznik wykonań (iteracji), który służy do określania warunku zakończenia pętli. Pętle iteracyjne wykonują się zadaną liczbę razy. Można je konstruować na podstawie opisanych wcześniej pętli warunkowych
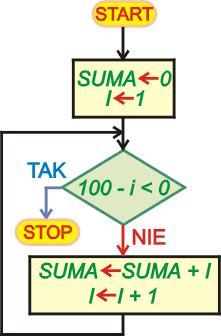
Poniższy program oblicza sumę 100 kolejnych liczb naturalnych poczynając od liczby 1. Podobnie jak w poprzednim przykładzie przed rozpoczęciem pętli ustalamy, iż SUMA ma zawartość 0, a zmienna I, zliczająca kolejne obiegi pętli, przyjmuje zawartość 1. Sprawdzenie warunku zakończenia pętli wykonujemy na jej początku. Obliczamy różnicę 100 - I. Jeśli różnica ta jest ujemna, to zmienna I przekroczyła wartość 100 i pętlę kończymy - w zmiennej SUMA mamy wynik sumowania 100 kolejnych liczb naturalnych. W pętli sumujemy zawartość zmiennych SUMA oraz I umieszczając wynik w zmiennej SUMA. Na końcu pętli zwiększamy o 1 zawartość licznika obiegów i wykonujemy skok do sprawdzania warunku zakończenia pętli.
Zwróć uwagę, iż licznik obiegów pętli I
pełni w tym prostym programie podwójną rolę. Zlicza obiegi oraz używany jest
do sumowania kolejnych liczb naturalnych.
RUN START
SUMA: DAT 0 ;wynik sumowania
I: DAT 1 ;licznik pętli
START: LDA #100 ;jeśli i > 100, pętlę przerywamy
SUB I
JMI #EX1
LDA SUMA ;SUMA <- SUMA + I
ADD I
STA SUMA
INC I ;I <- I + 1
JMP #START ;następny obieg
EX1:
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JMI, ADD, SUB, INC |
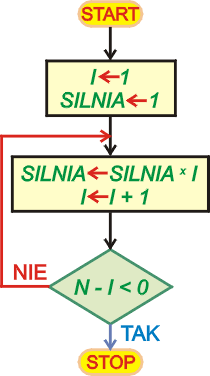
Następny przykład programowy oblicza
n! (n - silnia), dla podanej
wartości
n. Silnia rośnie bardzo szybko, więc
n nie może być zbyt duże - maksymalnie 7. Skorzystamy
dla odmiany z pętli iteracyjnej zbudowanej na podstawie pętli warunkowej
sprawdzającej warunek kontynuacji na końcu pętli. Niech czytelnik spróbuje
przeanalizować sposób działania tego programu.
RUN START
N: EQU 6 ;stała N określa silnię
I: DAT 1 ;zmienna licznikowa
SILNIA: DAT 1 ;wartość silni
START: LDA SILNIA ;SILNIA <- SILNIA * I
MUL I
STA SILNIA
INC I
LDA #N ;i > n?
SUB I
JMI #EX1 ;kończymy pętlę, jeśli tak
JMP #START ;kontynuujemy, jeśli nie
EX1:
Zobacz na:etykieta, stała, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JMI, SUB, MUL, INC |
Dotychczas operowaliśmy na grupach bitów tworzących wartość liczbową. PMC posiada również możliwość przetwarzania poszczególnych bitów dzięki operacjom RLA, AND, ORA oraz XOR. Do podstawowych operacji na bitach zaliczymy ustawianie, zerowanie, zaprzeczanie i testowanie bitu. Każda komórka pamięci PMC przechowuje dane w postaci 16 bitów. Bity te są ponumerowane od 0 do 15:
| Komórka pamięci PMC | |||||||||||||||
| b15 | b14 | b13 | b12 | b11 | b10 | b9 | b8 | b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
Aby ustawić bit na i-tej pozycji na 1, należy najpierw przygotować maskę bitową. Maska jest 16 bitowym słowem, w którym na i-tej pozycji bit ma stan 1, a wszystkie pozostałe bity mają stany 0 (maska może mieć ustawionych więcej niż jeden bit, co pozwoli wykonać operację ustawiania na kilku pozycjach jednocześnie jednym poleceniem). Po przygotowaniu maski dokonujemy operacji OR z argumentem:
argument ← argument OR maska
0111001000000000
- argument
OR
0000000000010000
- maska
0111001000010000
-
wynik
Spowoduje to ustawienie w argumencie bitu na 1 na tej pozycji, na której w masce bit jest również ustawiony na 1. Wszystkie inne bity argumentu pozostają bez zmian.
Poniższy program ustawia zadany bit zmiennej A. Numer bitu do ustawienia zadany jest w zmiennej N. Program wykonuje następujące operacje symboliczne (operacja << oznacza przesunięcie bitów w lewo o zadaną liczbę pozycji).
A ← A OR (1 << N)
RUN START
N: dat 12 ;ustawiony zostanie 12 bit zmiennej A
A: dat 0x00FF ;zmienna, w której ustawiony zostanie bit
START: LDA #1 ;ACR <- 1
RLA N ;ACR <- 1 << N
ORA A ;ACR <- A OR (1 << N)
STA A ; A <- A OR (1 << N)
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, RLA, ORA |
Jeśli pozycja bitu do ustawienia jest bezpośrednio znana i nie zmienia się, to zamiast tworzyć maskę można użyć odpowiedniej wartości liczbowej, np. w zapisie binarnym. Poniższy fragment kodu ustawia na 1 dwa skrajne bity akumulatora:
...
MASKA: DAT 0B1000000000000001 ;maska dla operacji OR
...
ORA MASKA ;ustawia b15 i b0
...
Jeśli ustawiany bit znajduje się na pozycji od 0 do 9, to maska może być podana jako argument natychmiastowy:
...
ORA #0B1000000000 ;ustawia bit b9 na 1
...
W przypadku zerowania bitu musimy utworzyć maskę, tak aby na pozycji zerowanego bitu miała bit o stanie 0, a na pozostałych pozycjach występowały bity o stanie 1. Maskę tę używamy następnie w operacji AND z argumentem:
argument ← argument AND maska
0111001111111100
- argument
AND
1111111111101111
- maska
0111001111101100
-
wynik
Na wszystkich pozycjach argumentu, dla których bity maski przyjmują stan 1, pozostaną bity o stanach niezmienionych. Na pozycji, dla której bit maski ma stan 0, bit będzie wyzerowany.
Poniższy program zeruje bit zmiennej A o numerze przechowywanym w zmiennej N. Wykonywane są następujące operacje:
A ← A AND NOT (1 << N)
RUN START
N: dat 2 ;wyzerowany zostanie 2 bit zmiennej A
A: dat 0x00FF ;zmienna, w której wyzerowany zostanie bit
START: LDA #1 ;ACR <- 1
RLA N ;ACR <- 1 << N
XOR #-1 ;ACR <- NOT (1 << N)
AND A ;ACR <- A AND NOT (1 << N)
STA A ; A <- A AND NOT (1 << N)
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, RLA, AND, XOR |
Powyższy program można zoptymalizować i skrócić o jedną instrukcję (XOR), jeśli będziemy tworzyć maskę od razu ze wszystkimi bitami odpowiednio ustawionymi. Można to osiągnąć wpisując do akumulatora wartość -2, która w kodzie U2 posiada wszystkie bity ustawione na 1 za wyjątkiem bitu 0, który ma stan 1:
-2(1) = 1111111111111110(U2)
Operacja RLA dokonuje obrotu bitów, więc wykonanie np. instrukcji RLA #5 spowoduje obrót wszystkich bitów akumulatora o pięć pozycji w lewo:
1111111111111110
- przed wykonaniem RLA #5
1111111111011111
- po wykonaniu RLA #5
Zmodyfikowany program jest następujący:
RUN START
N: dat 2 ;wyzerowany zostanie 2 bit zmiennej A
A: dat 0x00FF ;zmienna, w której wyzerowany zostanie bit
START: LDA #-2 ;ACR <- 0B1111111111111110
RLA N ;ACR <- 0B1111111111111110 RLA N
AND A ;ACR <- A AND NOT (0B1111111111111110 RLA N)
STA A ; A <- A AND NOT (0B1111111111111110 RLA N)
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, RLA, AND |
Negacja bitu ma na celu zmianę jego stanu na przeciwny. Dokonujemy tego budując identyczną maskę jak w przypadku ustawiania bitu, którą następnie używamy w operacji EXOR z argumentem:
argument ← argument EXOR maska
0111001000111000
- argument
EXOR
0000000010010000
- maska
0111001010101000
- wynik
Poniższy program zmienia stan zadanego bitu zmiennej A na przeciwny. Numer bitu zadany jest w zmiennej N. Program wykonuje następujące operacje symboliczne.
A ← A EXOR (1 << N)
RUN START
N: dat 5 ;zostanie zmieniony stan b5 zmiennej A
A: dat 0x00FF
START: LDA #1 ;ACR <- 1
RLA N ;ACR <- 1 << N
XOR A ;ACR <- A EXOR (1 << N)
STA A ; A <- A EXOR (1 << N)
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, RLA, XOR |
Jeśli pozycja bitu jest znana i nie zmienia się, to zamiast tworzyć maskę można użyć odpowiedniej wartości liczbowej, np. w zapisie binarnym. Poniższy fragment kodu zmienia stan bitów górnej połówki rejestru ACR - bity od b8 do b15:
...
MASKA: DAT 0B1111111100000000 ;maska dla operacji XOR
...
XOR MASKA ;zmieniamy stan górnej połowy bitów
...
Jeśli zmieniany bit znajduje się na pozycji od 0 do 9, to maska może być podana jako argument natychmiastowy:
...
XOR #0B1000000000 ;zmienia stan bitu b9
...
Testowanie bitu ma na celu stwierdzenie, czy znajduje się on w stanie 0 lub 1. Z zadaniem tym spotkać się możemy np. przy odczycie stanu klawiatury portu IOP, gdzie każdy odczytany bit informuje procesor o stanie skojarzonego z nim przycisku. Testowanie wykonuje się zerując wszystkie pozostałe bity i pozostawiając nienaruszony testowany bit. Teraz wystarczy sprawdzić, czy wynik tej operacji jest równy zero (testowany bit ma wartość 0) lub, czy jest różny od zera (testowany bit ma wartość 1). Zerowanie bitów uzyskamy przez utworzenie maski z ustawionym bitem na pozycji bitu testowanego i wykonaniem operacji AND z tak przygotowaną maską.
0111001000111000
- argument
AND
0000000000010000
- maska
0000000000010000
- wynik <> 0, bit ma stan 1
0111001000111000
- argument
AND
0000000010000000
- maska
0000000000010000
- wynik = 0, bit ma stan 0
Poniższy program sprawdza stan N-tego bitu zmiennej A. Jeśli bit ten ma stan 1, to wpisuje liczbę 1 do zmiennej A1. W przeciwnym razie wpisuje 1 do zmiennej A0.
RUN START
N: DAT 4 ;numer testowanego bitu
A: DAT 0X00FF ;zmienna, której bit będzie testowany
A0: DAT 0 ;ustawiane, jeśli bit ma stan 0
A1: DAT 0 ;ustawiane, jeśli bit ma stan 1
START: LDA #1 ;ACR <- 1
RLA N ;ACR <- 1 << N
AND A ;ACR <- A AND (1 << N)
JZR #TST0 ;bit = 0?
LDA #1 ;jeśli nie, to A1 <- 1
STA A1
JMP #TSTE
TST0: LDA #1 ;jeśli tak, to A0 <- 1
STA A0
TSTE:
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JZR, RLA, AND |
Procedura jest fragmentem programu, który może być wielokrotnie wywoływany przy pomocy instrukcji JSR z różnych miejsc w programie. Ponieważ instrukcja JSR zapamiętuje na stosie procesora adres powrotu (adres bezpośrednio za wywołującym ją rozkazem JSR), to może wrócić w odpowiednie miejsce programu przy pomocy instrukcji RTS. W procedurach umieszcza się zwykle często wykonywany kod, np. wypisujący teksty, odczytujący liczbę, dokonujący obliczeń jakiejś funkcji, itp.
Przedstawiony program wykorzystuje trzykrotnie procedurę do wykonania następującej operacji symbolicznej:
A ←
A + B
A
← A + B
A
← A + B
Trzykrotnie obliczana jest suma zmiennych A i B. Ponieważ wynik umieszczony zostaje w zmiennej A, to po pierwszym sumowaniu otrzymujemy:
A ← A + B
po drugim sumowaniu otrzymujemy
A ← (A + B) + B
i po trzecim otrzymujemy
A ← ((A + B) + B) + B
czyli
A ← A + 3B
RUN START
A: DAT 15
B: DAT 10
START: JSR #SUMA ;wywołujemy procedurę sumowania A i B
JSR #SUMA
JSR #SUMA
JMP #0 ;zakończenie programu
SUMA: LDA A ;procedura obliczania sumy A i B
ADD B
STA A
RTS #0 ;powrót do programu wywołującego
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JSR, RTS, AD |
Osobnym problemem jest komunikacja z procedurą, czyli przekazywanie do niej parametrów. Jeśli obliczenia wykonywane przez procedurę dotyczą tylko jednego argumentu (np. wyliczenie wartości jakiejś funkcji jednoargumentowej), to zarówno argument jak i wynik może być przekazany poprzez akumulator.
W następnym programie demonstrujemy ten sposób komunikacji tworząc procedurę zmieniającą zawartość akumulatora na przeciwną w kodzie U2. Program wykonuje następujące operacje symboliczne:
A
← -A
B
← -B
C
← A + B
RUN START
A: DAT 15
B: DAT -5
C: DAT 0 ;tutaj trafi wynik sumowania -A i -B
START: LDA B ;ACR <- B
JSR #COMPL ;ACR <- -ACR, czyli -B
STA B ;B <- -B
LDA A ;ACR <- A
JSR #COMPL ;ACR <- -ACR, czyli -A
STA A ;A <- -A
ADD B ;ACR <- A + B
STA C ; C <- A + B
JMP #0 ;kończymy wykonywanie programu
COMPL: XOR #-1 ;negujemy wszystkie bity ACR
INC #1 ;teraz ACR <- -ACR
RTS #0 ;powrót z wynikiem w ACR
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMP, JSR, RTS, ADD |
Jeśli procedura wymaga więcej parametrów lub zwraca więcej wyników niż jeden, to do komunikacji z nią wykorzystujemy zarezerwowane do tego celu zmienne. W poniższym programie znajduje się procedura obliczająca większą z dwóch liczb, które umieszczamy w zmiennych MAXA i MAXB należących do tej procedury. Wynik procedura zwraca w akumulatorze. Następnie program główny znajduje największą wartość z trzech zmiennych A, B i C..
RUN START
A: DAT 10 ;zmienne A, B i C przechowują liczby, wśród
B: DAT 5 ;których poszukujemy największej
C: DAT 11
WYNIK: DAT 0 ;Tutaj umieścimy największą liczbę
MAXA: DAT 0 ;zmienne pomocnicze dla procedury MAX
MAXB: DAT 0
MAX: LDA MAXA ;procedura MAX oblicza większą wartość z
SUB MAXB ;MAXA i MAXB. Wynik zwraca w akumulatorze
JMI #MAX1 ;jeśli MAXA > MAXB, to
LDA MAXA ;ACR <- MAXA
RTS #0 ;powrót
MAX1: LDA MAXB ;inaczej ACR <- MAXB
RTS #0 ;powrót
START: LDA A ;MAXA <- A
STA MAXA
LDA B ;MAXB <- B
STA MAXB
JSR #MAX ; ACR <- MAX(A,B)
STA MAXA ;MAXA <- MAX(A,B)
LDA C ;MAXB <- C
STA MAXB
JSR #MAX ;ACR <- MAX(MAX(A,B),C)
STA WYNIK ;WYNIK <- MAX(MAX(A,B),C)
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, LDA, STA, JMI, JSR, RTS, SUB |
Tablica jest zbiorem komórek leżących w spójnym obszarze pamięci i zawierających dane tego samego typu (np. literki napisu, ceny zakupionych towarów, itp.). Komórki te nazywać będziemy elementami tablicy. Każdy element tablicy ma przydzielony numer, zwany indeksem elementu. Numer ten określa położenie elementu w obszarze tablicy. Dostęp do elementu uzyskujemy na podstawie adresu początku tablicy oraz numeru elementu. Elementy numerowane są od indeksu 0, tzn. pierwszy element w tablicy posiada numer zero. Piąty element posiada numer indeksu cztery (zawsze o 1 mniej). Adres elementu obliczamy jako sumę:
adres elementu i ← adres tablicy + i
Następnie otrzymany adres wykorzystujemy przy dostępie do elementu tablicy. Przypisanie wartości elementowi tablicy zapisujemy symbolicznie jako:
tablica[i]
← wartość
i
- numer elementu.
Stosowane jest tutaj adresowanie pośrednie z postinkrementacją. W poniższym przykładzie umieszczamy wartość 15 w elemencie tablicy o indeksie 2 (trzeci element):
...
TABL1: DAT 65 ;element 0, pierwszy
DAT 1 ;element 1
DAT -3 ;element 2, tutaj trafi liczba 15
...
TPTR: DAT 0 ;tutaj umieszczamy adres elementu tablicy
...
LDA #TABL1 ;pobierz do ACR adres początku tablicy
ADD #2 ;oblicz adres elementu o indeksie 2
STA TPTR ;umieść adres we wskazaniu TPTR
LDA #15 ;załaduj 15 do akumulatora
STA (TPTR++) ;zapisz dane w elemencie TABL1[2]
...
Następny program sumuje zawartość dwóch komórek tablicy 5 elementowej o indeksach przechowywanych we wskazanych komórkach. Wynik sumowania umieszczany jest w oznaczonej komórce:
RUN START
TABL1: DAT 15 ;element 0, pierwszy
DAT 34 ;element 1
DAT 6 ;element 2
DAT 86 ;element 3
DAT -2 ;element 4, ostatni
INDX1: DAT 3 ;indeks elementu do sumowania
INDX2: DAT 1 ;indeks elementu do sumowania
SUMA: DAT 0 ;tutaj trafi suma dwóch elementów tablicy
EPTR1: DAT 0 ;adres elementu do sumowania
EPTR2: DAT 0 ;adres elementu do sumowania
START: LDA #TABL1 ;oblicz adres pierwszego elementu
ADD INDX1
STA EPTR1
LDA #TABL1 ;oblicz adres drugiego elementu
ADD INDX2
STA EPTR2
LDA (EPTR1++) ;pobierz pierwszy element
ADD (EPTR2++) ;dodaj drugi element
STA SUMA ;wynik umieść w komórce SUMA
Zobacz na:etykieta, zmienna, liczba, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, tryb pośredni z postinkrementacją, LDA, STA, ADD |
Program wykonuje operację:
SUMA ← TABL1[INDX1] + TABL1[INDX2]
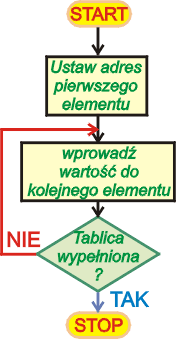
Operacja wypełniania wykonywana jest w pętli iteracyjnej, która wykonuje się
tyle obiegów, ile elementów ma tablica. Przed wejściem do pętli obliczamy adres
pierwszego elementu, następnie stosujemy
adresowanie pośrednie z postinkrementacją do umieszczania zadanej wartości w
kolejnych komórkach tablicy. Poniższy program wypełnia
RUN START
TAB: DAT 0 ;kolejne elementy tablicy
DAT 0
DAT 0
DAT 0
DAT 0
DAT 0
DAT 0
DAT 0
DAT 0
DAT 0
TPTR: DAT TAB ;adres pierwszego elementu tablicy
N: DAT 23 ;wartość do wypełnienia tablicy
I: DAT 10 ;liczba elementów do wypełnienia
START: LDA N ;umieszczamy zawartość zmiennej N
STA (TPTR++) ;w kolejnych komórkach tablicy
LDA I ;zmniejszamy licznik o 1
SUB #1
STA I
JZR #0 ;koniec?
JMP #START ;nie, następny element
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, tryb pośredni z postinkrementacją, LDA, STA, JMP, JZR, SUB |
Wstawienie elementu na pozycji i-tej tablicy wykonane zostanie w dwóch etapach:
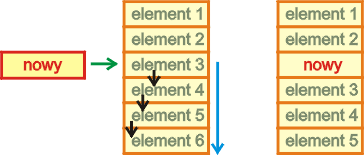
Zwróć uwagę, iż operacja ta powoduje utratę zawartości ostatniego elementu w tablicy - dla niego zabraknie już w tablicy miejsca po wykonaniu rozsunięcia. Poniższy program wstawia do tablicy TAB wartość ze zmiennej EVAL na pozycję o numerze przechowywanym w zmiennej ENUM.
RUN START
ENUM: DAT 3 ;zawiera numer pozycji do wstawienia
EVAL: DAT -1 ;zawiera wartość elementu do wstawienia
TAB: DAT 5 ;element 0
DAT 10 ;element 1
DAT 15 ;element 2
DAT 20 ;element 3
DAT 25 ;element 4
DAT 30 ;element 5
DAT 35 ;element 6
DAT 40 ;element 7
DAT 45 ;element 8
DAT 50 ;element 9
TABEND: ;adres poza końcem tablicy
TP1: DAT 0 ;używane do adresowania elementów tablicy
TP2: DAT 0 ;używane do adresowania elementów tablicy
I: DAT 0 ;zmienna wykorzystywana jako licznik pętli
START: LDA #TABEND ;ustawiamy wskazanie TP2 na koniec tablicy
STA TP2
SUB #1 ;a TP1 na ostatni element
STA TP1
LDA #9 ;obliczamy liczbę elementów do przesunięcia
SUB ENUM
STA I
LP1: LDA I ;sprawdzamy, czy został element do przesunięcia
JZR #INS1 ;jeśli nie, to wprowadzamy element
SUB #1 ;zmniejszamy liczbę elementów
STA I
LDA (--TP1) ;przesuwamy element na wyższą pozycję
STA (--TP2)
JMP #LP1 ;do kolejnego obiegu
INS1: LDA EVAL ;umieszczamy element w tablicy
STA (TP1++)
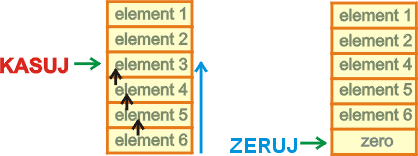
Usunięcie elementu polega na przeniesieniu wszystkich elementów o indeksie większym o jedną pozycję w dół. Na końcu tablicy dopisujemy wartość zero. Prezentowany poniżej przykład usuwa z tablicy TAB element z pozycji o numerze w zmiennej ENUM.
RUN START
ENUM: DAT 3 ;zawiera numer pozycji do usunięcia
TAB: DAT 5 ;element 0
DAT 10 ;element 1
DAT 15 ;element 2
DAT 20 ;element 3
DAT 25 ;element 4
DAT 30 ;element 5
DAT 35 ;element 6
DAT 40 ;element 7
DAT 45 ;element 8
DAT 50 ;element 9
TP1: DAT 0 ;używane do adresowania elementów tablicy
TP2: DAT 0 ;używane do adresowania elementów tablicy
I: DAT 0 ;zmienna wykorzystywana jako licznik pętli
START: LDA #9 ;obliczamy liczbę elementów do przeniesienia
SUB ENUM
STA I
LDA #TAB ;obliczamy adres elementu
ADD ENUM
STA TP2
ADD #1 ;oraz adres elementu następnego
STA TP1
LP1: LDA I ;koniec?
JZR #DEL1
SUB #1 ;zmniejszamy licznik o 1
STA I
LDA (TP1++) ;przesuwamy następny element w dół
STA (TP2++)
JMP #LP1 ;i kontynuujemy pętlę
DEL1: LDA #0 ;zerujemy ostatni element w tablicy
STA (TP2++)
Zobacz na:etykieta, zmienna, liczba, liczba bez znaku, liczba ze znakiem, tryb natychmiastowy, tryb bezpośredni, tryb pośredni z postinkrementacją, LDA, STA, JMP, JZR, ADD, SUB |
| Zespół Przedmiotowy Chemii-Fizyki-Informatyki w I Liceum Ogólnokształcącym im. Kazimierza Brodzińskiego w Tarnowie ul. Piłsudskiego 4 ©2024 mgr Jerzy Wałaszek |
Materiały tylko do użytku dydaktycznego. Ich kopiowanie i powielanie jest dozwolone
pod warunkiem podania źródła oraz niepobierania za to pieniędzy.
Pytania proszę przesyłać na adres email:
Serwis wykorzystuje pliki cookies. Jeśli nie chcesz ich otrzymywać, zablokuj je w swojej przeglądarce.
Informacje dodatkowe.